 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedScribe: Clinically Grounded CT Reporting through Agentic Workflows
May 03, 2026Vision-language models (VLMs) have shown potential for automated radiology report generation, yet existing approaches rely on global embedding compression of volumetric data, often leading to hallucinated findings and limited anatomical grounding in 3D CT imaging. We introduce MedScribe, a hypothesis-driven framework that reformulates report generation as an iterative evidence acquisition process rather than a single-pass encoding task. MedScribe models reporting as a sequential decision process in which a large language model dynamically invokes pathology-specific diagnostic tools to extract localized volumetric features. These structured features are used to query a multidimensional retrieval space aligned with pathology-specific textual evidence. By explicitly accumulating quantitative evidence prior to synthesis, the framework enforces fine-grained grounding and reduces unsupported claims. Without task-specific fine-tuning, MedScribe improves clinical accuracy, factual consistency, and interpretability on CT-RATE and RadChestCT compared to state-of-the-art 2D and 3D VLMs, demonstrating the value of hypothesis-driven reasoning for reliable medical image reporting.
The MAMA-MIA Challenge: Advancing Generalizability and Fairness in Breast MRI Tumor Segmentation and Treatment Response Prediction
Mar 01, 2026Breast cancer is the most frequently diagnosed malignancy among women worldwide and a leading cause of cancer-related mortality. Dynamic contrast-enhanced magnetic resonance imaging plays a central role in tumor characterization and treatment monitoring, particularly in patients receiving neoadjuvant chemotherapy. However, existing artificial intelligence models for breast magnetic resonance imaging are often developed using single-center data and evaluated using aggregate performance metrics, limiting their generalizability and obscuring potential performance disparities across demographic subgroups. The MAMA-MIA Challenge was designed to address these limitations by introducing a large-scale benchmark that jointly evaluates primary tumor segmentation and prediction of pathologic complete response using pre-treatment magnetic resonance imaging only. The training cohort comprised 1,506 patients from multiple institutions in the United States, while evaluation was conducted on an external test set of 574 patients from three independent European centers to assess cross-continental and cross-institutional generalization. A unified scoring framework combined predictive performance with subgroup consistency across age, menopausal status, and breast density. Twenty-six international teams participated in the final evaluation phase. Results demonstrate substantial performance variability under external testing and reveal trade-offs between overall accuracy and subgroup fairness. The challenge provides standardized datasets, evaluation protocols, and public resources to promote the development of robust and equitable artificial intelligence systems for breast cancer imaging.
Diffusion-Based Quality Control of Medical Image Segmentations across Organs
Nov 12, 2025



Medical image segmentation using deep learning (DL) has enabled the development of automated analysis pipelines for large-scale population studies. However, state-of-the-art DL methods are prone to hallucinations, which can result in anatomically implausible segmentations. With manual correction impractical at scale, automated quality control (QC) techniques have to address the challenge. While promising, existing QC methods are organ-specific, limiting their generalizability and usability beyond their original intended task. To overcome this limitation, we propose no-new Quality Control (nnQC), a robust QC framework based on a diffusion-generative paradigm that self-adapts to any input organ dataset. Central to nnQC is a novel Team of Experts (ToE) architecture, where two specialized experts independently encode 3D spatial awareness, represented by the relative spatial position of an axial slice, and anatomical information derived from visual features from the original image. A weighted conditional module dynamically combines the pair of independent embeddings, or opinions to condition the sampling mechanism within a diffusion process, enabling the generation of a spatially aware pseudo-ground truth for predicting QC scores. Within its framework, nnQC integrates fingerprint adaptation to ensure adaptability across organs, datasets, and imaging modalities. We evaluated nnQC on seven organs using twelve publicly available datasets. Our results demonstrate that nnQC consistently outperforms state-of-the-art methods across all experiments, including cases where segmentation masks are highly degraded or completely missing, confirming its versatility and effectiveness across different organs.
Multi-Domain Brain Vessel Segmentation Through Feature Disentanglement
Oct 02, 2025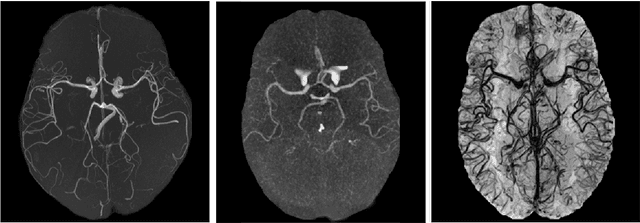


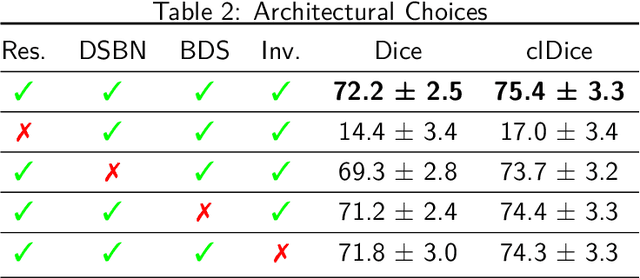
The intricate morphology of brain vessels poses significant challenges for automatic segmentation models, which usually focus on a single imaging modality. However, accurately treating brain-related conditions requires a comprehensive understanding of the cerebrovascular tree, regardless of the specific acquisition procedure. Our framework effectively segments brain arteries and veins in various datasets through image-to-image translation while avoiding domain-specific model design and data harmonization between the source and the target domain. This is accomplished by employing disentanglement techniques to independently manipulate different image properties, allowing them to move from one domain to another in a label-preserving manner. Specifically, we focus on manipulating vessel appearances during adaptation while preserving spatial information, such as shapes and locations, which are crucial for correct segmentation. Our evaluation effectively bridges large and varied domain gaps across medical centers, image modalities, and vessel types. Additionally, we conduct ablation studies on the optimal number of required annotations and other architectural choices. The results highlight our framework's robustness and versatility, demonstrating the potential of domain adaptation methodologies to perform cerebrovascular image segmentation in multiple scenarios accurately. Our code is available at https://github.com/i-vesseg/MultiVesSeg.
* 19 pages, 7 figures, 3 tables. Joint first authors: Francesco Galati and Daniele Falcetta. Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2025:021. Code available at https://github.com/i-vesseg/MultiVesSeg
In the Picture: Medical Imaging Datasets, Artifacts, and their Living Review
Jan 18, 2025


Datasets play a critical role in medical imaging research, yet issues such as label quality, shortcuts, and metadata are often overlooked. This lack of attention may harm the generalizability of algorithms and, consequently, negatively impact patient outcomes. While existing medical imaging literature reviews mostly focus on machine learning (ML) methods, with only a few focusing on datasets for specific applications, these reviews remain static -- they are published once and not updated thereafter. This fails to account for emerging evidence, such as biases, shortcuts, and additional annotations that other researchers may contribute after the dataset is published. We refer to these newly discovered findings of datasets as research artifacts. To address this gap, we propose a living review that continuously tracks public datasets and their associated research artifacts across multiple medical imaging applications. Our approach includes a framework for the living review to monitor data documentation artifacts, and an SQL database to visualize the citation relationships between research artifact and dataset. Lastly, we discuss key considerations for creating medical imaging datasets, review best practices for data annotation, discuss the significance of shortcuts and demographic diversity, and emphasize the importance of managing datasets throughout their entire lifecycle. Our demo is publicly available at http://130.226.140.142.
MVP: Multimodal Emotion Recognition based on Video and Physiological Signals
Jan 06, 2025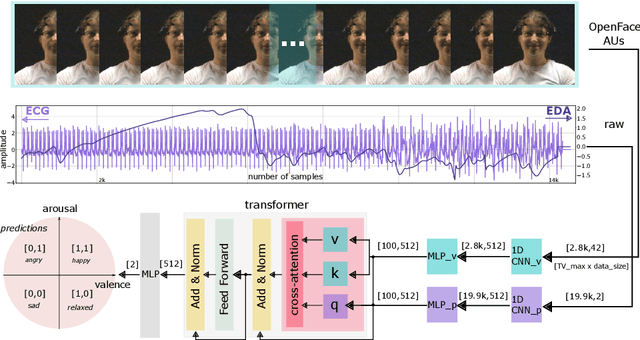
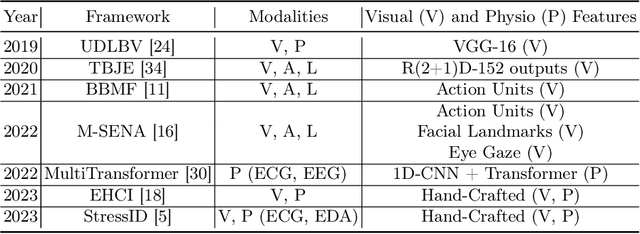
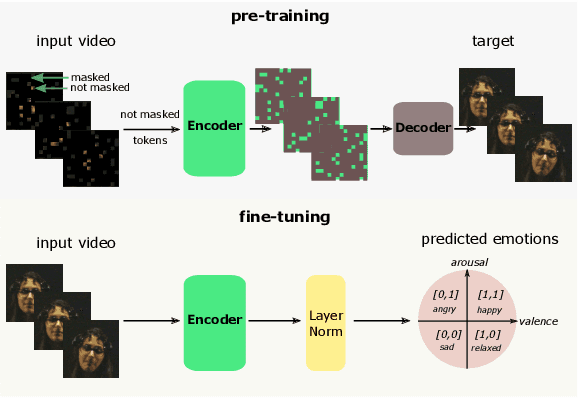
Human emotions entail a complex set of behavioral, physiological and cognitive changes. Current state-of-the-art models fuse the behavioral and physiological components using classic machine learning, rather than recent deep learning techniques. We propose to fill this gap, designing the Multimodal for Video and Physio (MVP) architecture, streamlined to fuse video and physiological signals. Differently then others approaches, MVP exploits the benefits of attention to enable the use of long input sequences (1-2 minutes). We have studied video and physiological backbones for inputting long sequences and evaluated our method with respect to the state-of-the-art. Our results show that MVP outperforms former methods for emotion recognition based on facial videos, EDA, and ECG/PPG.
SMILE-UHURA Challenge -- Small Vessel Segmentation at Mesoscopic Scale from Ultra-High Resolution 7T Magnetic Resonance Angiograms
Nov 14, 2024The human brain receives nutrients and oxygen through an intricate network of blood vessels. Pathology affecting small vessels, at the mesoscopic scale, represents a critical vulnerability within the cerebral blood supply and can lead to severe conditions, such as Cerebral Small Vessel Diseases. The advent of 7 Tesla MRI systems has enabled the acquisition of higher spatial resolution images, making it possible to visualise such vessels in the brain. However, the lack of publicly available annotated datasets has impeded the development of robust, machine learning-driven segmentation algorithms. To address this, the SMILE-UHURA challenge was organised. This challenge, held in conjunction with the ISBI 2023, in Cartagena de Indias, Colombia, aimed to provide a platform for researchers working on related topics. The SMILE-UHURA challenge addresses the gap in publicly available annotated datasets by providing an annotated dataset of Time-of-Flight angiography acquired with 7T MRI. This dataset was created through a combination of automated pre-segmentation and extensive manual refinement. In this manuscript, sixteen submitted methods and two baseline methods are compared both quantitatively and qualitatively on two different datasets: held-out test MRAs from the same dataset as the training data (with labels kept secret) and a separate 7T ToF MRA dataset where both input volumes and labels are kept secret. The results demonstrate that most of the submitted deep learning methods, trained on the provided training dataset, achieved reliable segmentation performance. Dice scores reached up to 0.838 $\pm$ 0.066 and 0.716 $\pm$ 0.125 on the respective datasets, with an average performance of up to 0.804 $\pm$ 0.15.
HyperMM : Robust Multimodal Learning with Varying-sized Inputs
Jul 30, 2024



Combining multiple modalities carrying complementary information through multimodal learning (MML) has shown considerable benefits for diagnosing multiple pathologies. However, the robustness of multimodal models to missing modalities is often overlooked. Most works assume modality completeness in the input data, while in clinical practice, it is common to have incomplete modalities. Existing solutions that address this issue rely on modality imputation strategies before using supervised learning models. These strategies, however, are complex, computationally costly and can strongly impact subsequent prediction models. Hence, they should be used with parsimony in sensitive applications such as healthcare. We propose HyperMM, an end-to-end framework designed for learning with varying-sized inputs. Specifically, we focus on the task of supervised MML with missing imaging modalities without using imputation before training. We introduce a novel strategy for training a universal feature extractor using a conditional hypernetwork, and propose a permutation-invariant neural network that can handle inputs of varying dimensions to process the extracted features, in a two-phase task-agnostic framework. We experimentally demonstrate the advantages of our method in two tasks: Alzheimer's disease detection and breast cancer classification. We demonstrate that our strategy is robust to high rates of missing data and that its flexibility allows it to handle varying-sized datasets beyond the scenario of missing modalities.
Benchmarking the CoW with the TopCoW Challenge: Topology-Aware Anatomical Segmentation of the Circle of Willis for CTA and MRA
Dec 29, 2023



The Circle of Willis (CoW) is an important network of arteries connecting major circulations of the brain. Its vascular architecture is believed to affect the risk, severity, and clinical outcome of serious neuro-vascular diseases. However, characterizing the highly variable CoW anatomy is still a manual and time-consuming expert task. The CoW is usually imaged by two angiographic imaging modalities, magnetic resonance angiography (MRA) and computed tomography angiography (CTA), but there exist limited public datasets with annotations on CoW anatomy, especially for CTA. Therefore we organized the TopCoW Challenge in 2023 with the release of an annotated CoW dataset and invited submissions worldwide for the CoW segmentation task, which attracted over 140 registered participants from four continents. TopCoW dataset was the first public dataset with voxel-level annotations for CoW's 13 vessel components, made possible by virtual-reality (VR) technology. It was also the first dataset with paired MRA and CTA from the same patients. TopCoW challenge aimed to tackle the CoW characterization problem as a multiclass anatomical segmentation task with an emphasis on topological metrics. The top performing teams managed to segment many CoW components to Dice scores around 90%, but with lower scores for communicating arteries and rare variants. There were also topological mistakes for predictions with high Dice scores. Additional topological analysis revealed further areas for improvement in detecting certain CoW components and matching CoW variant's topology accurately. TopCoW represented a first attempt at benchmarking the CoW anatomical segmentation task for MRA and CTA, both morphologically and topologically.
A2V: A Semi-Supervised Domain Adaptation Framework for Brain Vessel Segmentation via Two-Phase Training Angiography-to-Venography Translation
Sep 12, 2023



We present a semi-supervised domain adaptation framework for brain vessel segmentation from different image modalities. Existing state-of-the-art methods focus on a single modality, despite the wide range of available cerebrovascular imaging techniques. This can lead to significant distribution shifts that negatively impact the generalization across modalities. By relying on annotated angiographies and a limited number of annotated venographies, our framework accomplishes image-to-image translation and semantic segmentation, leveraging a disentangled and semantically rich latent space to represent heterogeneous data and perform image-level adaptation from source to target domains. Moreover, we reduce the typical complexity of cycle-based architectures and minimize the use of adversarial training, which allows us to build an efficient and intuitive model with stable training. We evaluate our method on magnetic resonance angiographies and venographies. While achieving state-of-the-art performance in the source domain, our method attains a Dice score coefficient in the target domain that is only 8.9% lower, highlighting its promising potential for robust cerebrovascular image segmentation across different modalities.