 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsyncMDE: Real-Time Monocular Depth Estimation via Asynchronous Spatial Memory
Mar 11, 2026Foundation-model-based monocular depth estimation offers a viable alternative to active sensors for robot perception, yet its computational cost often prohibits deployment on edge platforms. Existing methods perform independent per-frame inference, wasting the substantial computational redundancy between adjacent viewpoints in continuous robot operation. This paper presents AsyncMDE, an asynchronous depth perception system consisting of a foundation model and a lightweight model that amortizes the foundation model's computational cost over time. The foundation model produces high-quality spatial features in the background, while the lightweight model runs asynchronously in the foreground, fusing cached memory with current observations through complementary fusion, outputting depth estimates, and autoregressively updating the memory. This enables cross-frame feature reuse with bounded accuracy degradation. At a mere 3.83M parameters, it operates at 237 FPS on an RTX 4090, recovering 77% of the accuracy gap to the foundation model while achieving a 25X parameter reduction. Validated across indoor static, dynamic, and synthetic extreme-motion benchmarks, AsyncMDE degrades gracefully between refreshes and achieves 161FPS on a Jetson AGX Orin with TensorRT, clearly demonstrating its feasibility for real-time edge deployment.
MeshSegmenter: Zero-Shot Mesh Semantic Segmentation via Texture Synthesis
Jul 18, 2024



We present MeshSegmenter, a simple yet effective framework designed for zero-shot 3D semantic segmentation. This model successfully extends the powerful capabilities of 2D segmentation models to 3D meshes, delivering accurate 3D segmentation across diverse meshes and segment descriptions. Specifically, our model leverages the Segment Anything Model (SAM) model to segment the target regions from images rendered from the 3D shape. In light of the importance of the texture for segmentation, we also leverage the pretrained stable diffusion model to generate images with textures from 3D shape, and leverage SAM to segment the target regions from images with textures. Textures supplement the shape for segmentation and facilitate accurate 3D segmentation even in geometrically non-prominent areas, such as segmenting a car door within a car mesh. To achieve the 3D segments, we render 2D images from different views and conduct segmentation for both textured and untextured images. Lastly, we develop a multi-view revoting scheme that integrates 2D segmentation results and confidence scores from various views onto the 3D mesh, ensuring the 3D consistency of segmentation results and eliminating inaccuracies from specific perspectives. Through these innovations, MeshSegmenter offers stable and reliable 3D segmentation results both quantitatively and qualitatively, highlighting its potential as a transformative tool in the field of 3D zero-shot segmentation. The code is available at \url{https://github.com/zimingzhong/MeshSegmenter}.
Amodal Segmentation Based on Visible Region Segmentation and Shape Prior
Dec 19, 2020

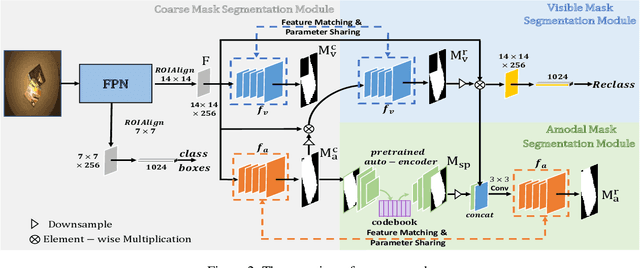

Almost all existing amodal segmentation methods make the inferences of occluded regions by using features corresponding to the whole image. This is against the human's amodal perception, where human uses the visible part and the shape prior knowledge of the target to infer the occluded region. To mimic the behavior of human and solve the ambiguity in the learning, we propose a framework, it firstly estimates a coarse visible mask and a coarse amodal mask. Then based on the coarse prediction, our model infers the amodal mask by concentrating on the visible region and utilizing the shape prior in the memory. In this way, features corresponding to background and occlusion can be suppressed for amodal mask estimation. Consequently, the amodal mask would not be affected by what the occlusion is given the same visible regions. The leverage of shape prior makes the amodal mask estimation more robust and reasonable. Our proposed model is evaluated on three datasets. Experiments show that our proposed model outperforms existing state-of-the-art methods. The visualization of shape prior indicates that the category-specific feature in the codebook has certain interpretability.