 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Universal Adversarial Perturbations Through the Lens of Deep Steganography: Towards A Fourier Perspective
Feb 12, 2021
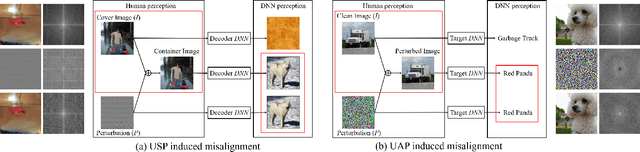

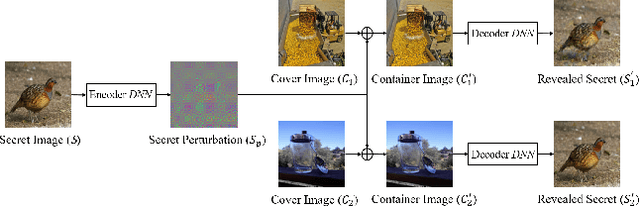
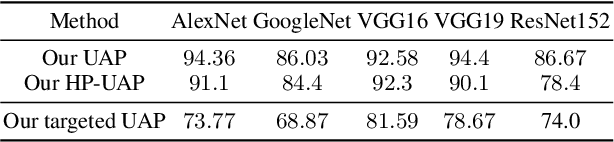
The booming interest in adversarial attacks stems from a misalignment between human vision and a deep neural network (DNN), i.e. a human imperceptible perturbation fools the DNN. Moreover, a single perturbation, often called universal adversarial perturbation (UAP), can be generated to fool the DNN for most images. A similar misalignment phenomenon has recently also been observed in the deep steganography task, where a decoder network can retrieve a secret image back from a slightly perturbed cover image. We attempt explaining the success of both in a unified manner from the Fourier perspective. We perform task-specific and joint analysis and reveal that (a) frequency is a key factor that influences their performance based on the proposed entropy metric for quantifying the frequency distribution; (b) their success can be attributed to a DNN being highly sensitive to high-frequency content. We also perform feature layer analysis for providing deep insight on model generalization and robustness. Additionally, we propose two new variants of universal perturbations: (1) Universal Secret Adversarial Perturbation (USAP) that simultaneously achieves attack and hiding; (2) high-pass UAP (HP-UAP) that is less visible to the human eye.
Dense Haze: A benchmark for image dehazing with dense-haze and haze-free images
Apr 05, 2019

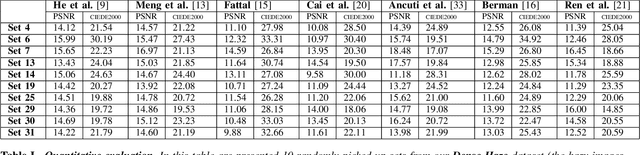

Single image dehazing is an ill-posed problem that has recently drawn important attention. Despite the significant increase in interest shown for dehazing over the past few years, the validation of the dehazing methods remains largely unsatisfactory, due to the lack of pairs of real hazy and corresponding haze-free reference images. To address this limitation, we introduce Dense-Haze - a novel dehazing dataset. Characterized by dense and homogeneous hazy scenes, Dense-Haze contains 33 pairs of real hazy and corresponding haze-free images of various outdoor scenes. The hazy scenes have been recorded by introducing real haze, generated by professional haze machines. The hazy and haze-free corresponding scenes contain the same visual content captured under the same illumination parameters. Dense-Haze dataset aims to push significantly the state-of-the-art in single-image dehazing by promoting robust methods for real and various hazy scenes. We also provide a comprehensive qualitative and quantitative evaluation of state-of-the-art single image dehazing techniques based on the Dense-Haze dataset. Not surprisingly, our study reveals that the existing dehazing techniques perform poorly for dense homogeneous hazy scenes and that there is still much room for improvement.
Image Quality Transfer Enhances Contrast and Resolution of Low-Field Brain MRI in African Paediatric Epilepsy Patients
Mar 16, 2020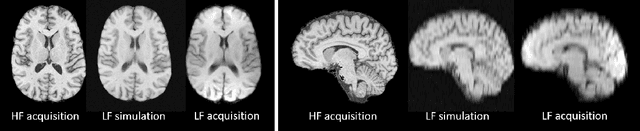
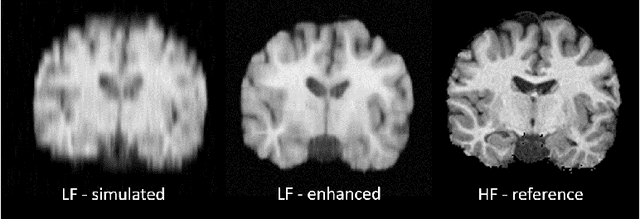
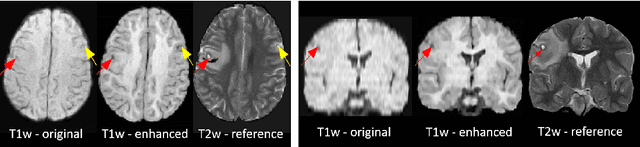
1.5T or 3T scanners are the current standard for clinical MRI, but low-field (<1T) scanners are still common in many lower- and middle-income countries for reasons of cost and robustness to power failures. Compared to modern high-field scanners, low-field scanners provide images with lower signal-to-noise ratio at equivalent resolution, leaving practitioners to compensate by using large slice thickness and incomplete spatial coverage. Furthermore, the contrast between different types of brain tissue may be substantially reduced even at equal signal-to-noise ratio, which limits diagnostic value. Recently the paradigm of Image Quality Transfer has been applied to enhance 0.36T structural images aiming to approximate the resolution, spatial coverage, and contrast of typical 1.5T or 3T images. A variant of the neural network U-Net was trained using low-field images simulated from the publicly available 3T Human Connectome Project dataset. Here we present qualitative results from real and simulated clinical low-field brain images showing the potential value of IQT to enhance the clinical utility of readily accessible low-field MRIs in the management of epilepsy.
On training deep networks for satellite image super-resolution
Jun 16, 2019

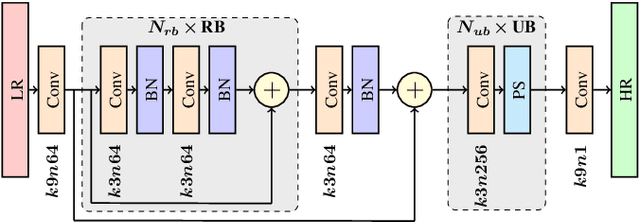
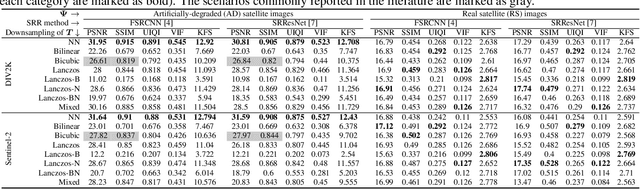
The capabilities of super-resolution reconstruction (SRR)---techniques for enhancing image spatial resolution---have been recently improved significantly by the use of deep convolutional neural networks. Commonly, such networks are learned using huge training sets composed of original images alongside their low-resolution counterparts, obtained with bicubic downsampling. In this paper, we investigate how the SRR performance is influenced by the way such low-resolution training data are obtained, which has not been explored up to date. Our extensive experimental study indicates that the training data characteristics have a large impact on the reconstruction accuracy, and the widely-adopted approach is not the most effective for dealing with satellite images. Overall, we argue that developing better training data preparation routines may be pivotal in making SRR suitable for real-world applications.
From Patch to Image Segmentation using Fully Convolutional Networks - Application to Retinal Images
Apr 08, 2019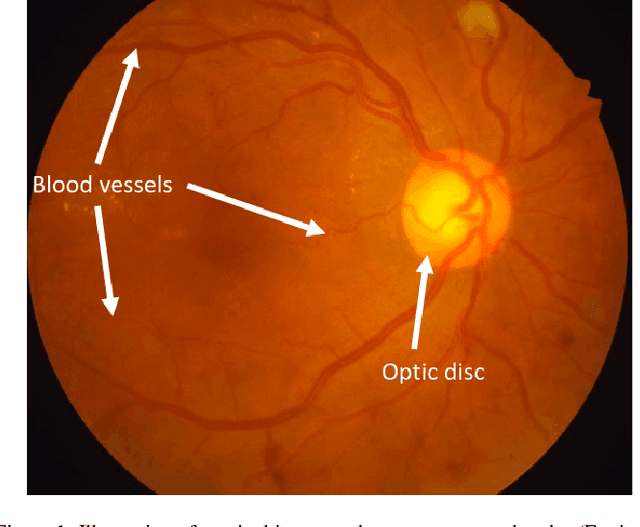
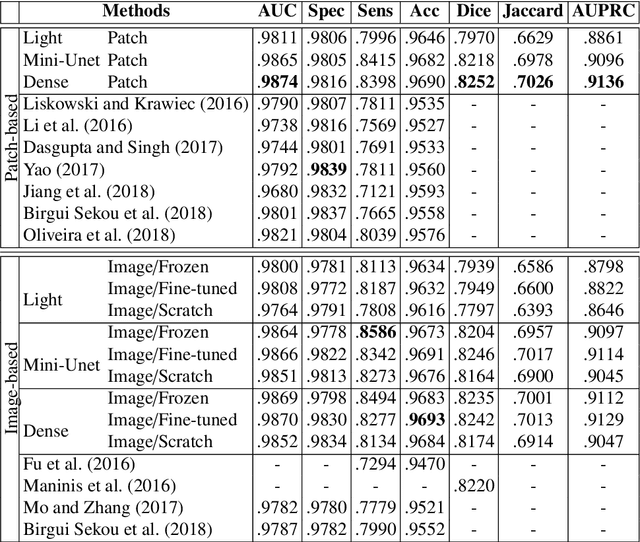
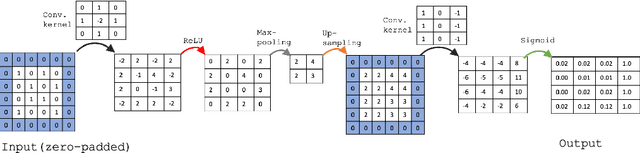
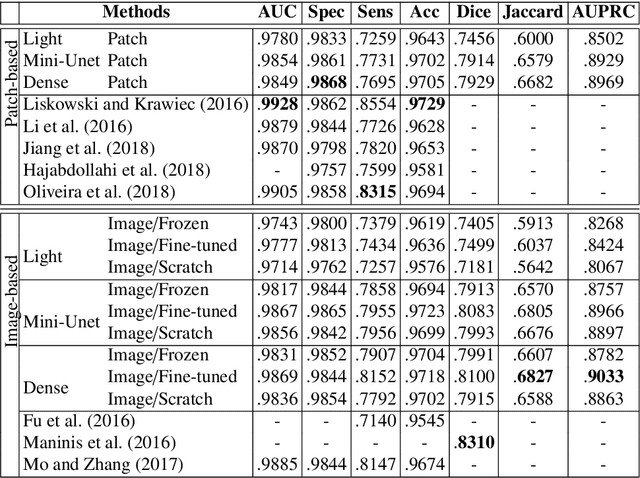
In general, deep learning based models require a tremendous amount of samples for appropriate training, which is difficult to satisfy in the medical field. This issue can usually be avoided with a proper initialization of the weights. On the task of medical image segmentation in general, two techniques are usually employed to tackle the training of a deep network $f_T$. The first one consists in reusing some weights of a network $f_S$ pre-trained on a large scale database ($e.g.$ ImageNet). This procedure, also known as \textit{transfer learning}, happens to reduce the flexibility when it comes to new network design since $f_T$ is constrained to match some parts of $f_S$. The second commonly used technique consists in working on image patches to benefit from the large number of available patches. This paper brings together these two techniques and propose to train arbitrarily designed networks, with a focus on relatively small databases, in two stages: patch pre-training and full sized image fine-tuning. An experimental work have been carried out on the tasks of retinal blood vessel segmentation and the optic disc one, using four publicly available databases. Furthermore, three types of network are considered, going from a very light weighted network to a densely connected one. The final results show the efficiency of the proposed framework along with state of the art results on all the databases.
Planar Geometry and Latest Scene Recovery from a Single Motion Blurred Image
Apr 15, 2019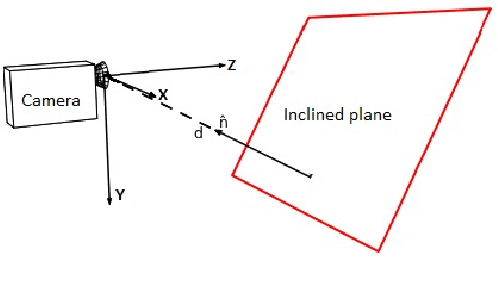



Existing works on motion deblurring either ignore the effects of depth-dependent blur or work with the assumption of a multi-layered scene wherein each layer is modeled in the form of fronto-parallel plane. In this work, we consider the case of 3D scenes with piecewise planar structure i.e., a scene that can be modeled as a combination of multiple planes with arbitrary orientations. We first propose an approach for estimation of normal of a planar scene from a single motion blurred observation. We then develop an algorithm for automatic recovery of a number of planes, the parameters corresponding to each plane, and camera motion from a single motion blurred image of a multiplanar 3D scene. Finally, we propose a first-of-its-kind approach to recover the planar geometry and latent image of the scene by adopting an alternating minimization framework built on our findings. Experiments on synthetic and real data reveal that our proposed method achieves state-of-the-art results.
Analysis and evaluation of Deep Learning based Super-Resolution algorithms to improve performance in Low-Resolution Face Recognition
Jan 19, 2021
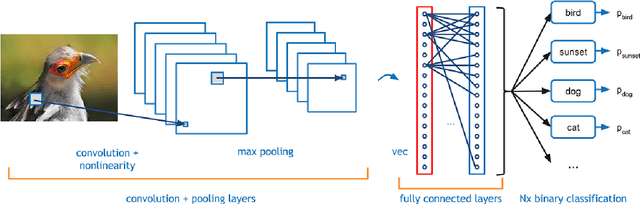
Surveillance scenarios are prone to several problems since they usually involve low-resolution footage, and there is no control of how far the subjects may be from the camera in the first place. This situation is suitable for the application of upsampling (super-resolution) algorithms since they may be able to recover the discriminant properties of the subjects involved. While general super-resolution approaches were proposed to enhance image quality for human-level perception, biometrics super-resolution methods seek the best "computer perception" version of the image since their focus is on improving automatic recognition performance. Convolutional neural networks and deep learning algorithms, in general, have been applied to computer vision tasks and are now state-of-the-art for several sub-domains, including image classification, restoration, and super-resolution. However, no work has evaluated the effects that the latest proposed super-resolution methods may have upon the accuracy and face verification performance in low-resolution "in-the-wild" data. This project aimed at evaluating and adapting different deep neural network architectures for the task of face super-resolution driven by face recognition performance in real-world low-resolution images. The experimental results in a real-world surveillance and attendance datasets showed that general super-resolution architectures might enhance face verification performance of deep neural networks trained on high-resolution faces. Also, since neural networks are function approximators and can be trained based on specific objective functions, the use of a customized loss function optimized for feature extraction showed promising results for recovering discriminant features in low-resolution face images.
Quantization of Deep Neural Networks for Accurate EdgeComputing
Apr 25, 2021


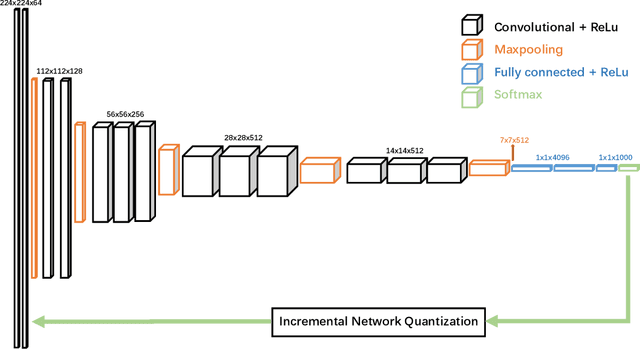
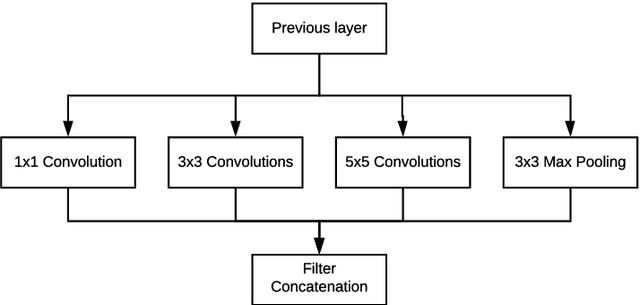
Deep neural networks (DNNs) have demonstrated their great potential in recent years, exceeding the per-formance of human experts in a wide range of applications. Due to their large sizes, however, compressiontechniques such as weight quantization and pruning are usually applied before they can be accommodated onthe edge. It is generally believed that quantization leads to performance degradation, and plenty of existingworks have explored quantization strategies aiming at minimum accuracy loss. In this paper, we argue thatquantization, which essentially imposes regularization on weight representations, can sometimes help toimprove accuracy. We conduct comprehensive experiments on three widely used applications: fully con-nected network (FCN) for biomedical image segmentation, convolutional neural network (CNN) for imageclassification on ImageNet, and recurrent neural network (RNN) for automatic speech recognition, and experi-mental results show that quantization can improve the accuracy by 1%, 1.95%, 4.23% on the three applicationsrespectively with 3.5x-6.4x memory reduction.
Bridging Multi-Task Learning and Meta-Learning: Towards Efficient Training and Effective Adaptation
Jun 16, 2021
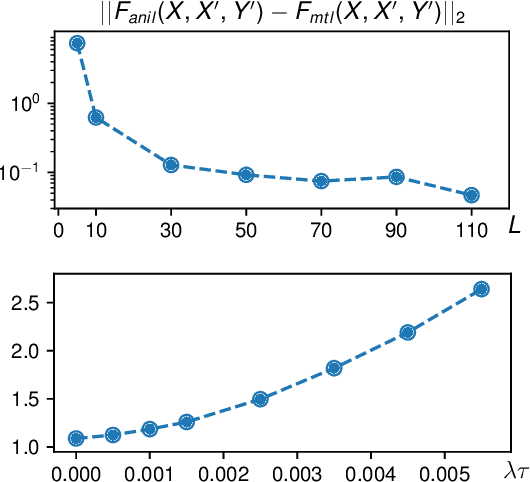

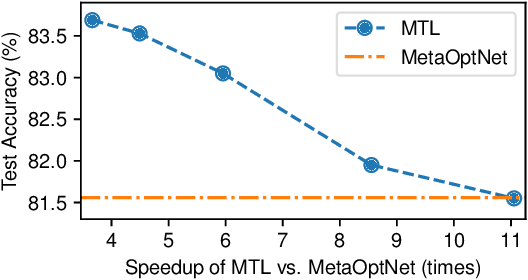
Multi-task learning (MTL) aims to improve the generalization of several related tasks by learning them jointly. As a comparison, in addition to the joint training scheme, modern meta-learning allows unseen tasks with limited labels during the test phase, in the hope of fast adaptation over them. Despite the subtle difference between MTL and meta-learning in the problem formulation, both learning paradigms share the same insight that the shared structure between existing training tasks could lead to better generalization and adaptation. In this paper, we take one important step further to understand the close connection between these two learning paradigms, through both theoretical analysis and empirical investigation. Theoretically, we first demonstrate that MTL shares the same optimization formulation with a class of gradient-based meta-learning (GBML) algorithms. We then prove that for over-parameterized neural networks with sufficient depth, the learned predictive functions of MTL and GBML are close. In particular, this result implies that the predictions given by these two models are similar over the same unseen task. Empirically, we corroborate our theoretical findings by showing that, with proper implementation, MTL is competitive against state-of-the-art GBML algorithms on a set of few-shot image classification benchmarks. Since existing GBML algorithms often involve costly second-order bi-level optimization, our first-order MTL method is an order of magnitude faster on large-scale datasets such as mini-ImageNet. We believe this work could help bridge the gap between these two learning paradigms, and provide a computationally efficient alternative to GBML that also supports fast task adaptation.
CoCon: Cooperative-Contrastive Learning
Apr 30, 2021

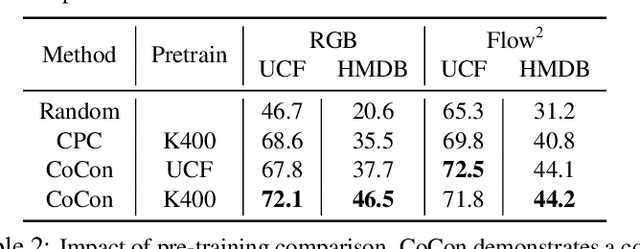
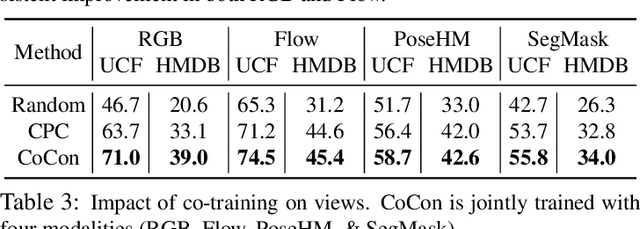
Labeling videos at scale is impractical. Consequently, self-supervised visual representation learning is key for efficient video analysis. Recent success in learning image representations suggests contrastive learning is a promising framework to tackle this challenge. However, when applied to real-world videos, contrastive learning may unknowingly lead to the separation of instances that contain semantically similar events. In our work, we introduce a cooperative variant of contrastive learning to utilize complementary information across views and address this issue. We use data-driven sampling to leverage implicit relationships between multiple input video views, whether observed (e.g. RGB) or inferred (e.g. flow, segmentation masks, poses). We are one of the firsts to explore exploiting inter-instance relationships to drive learning. We experimentally evaluate our representations on the downstream task of action recognition. Our method achieves competitive performance on standard benchmarks (UCF101, HMDB51, Kinetics400). Furthermore, qualitative experiments illustrate that our models can capture higher-order class relationships.