 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantization of Deep Neural Networks for Accurate EdgeComputing
Paper and Code
Apr 25, 2021


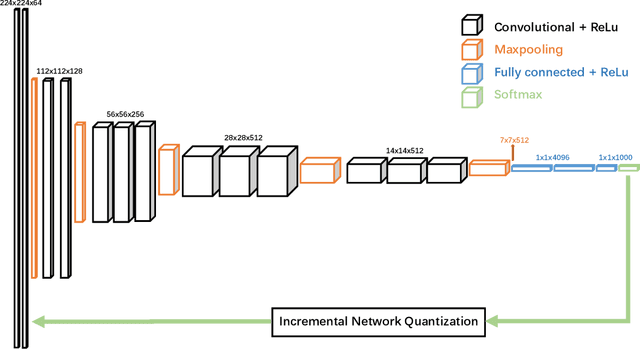
Deep neural networks (DNNs) have demonstrated their great potential in recent years, exceeding the per-formance of human experts in a wide range of applications. Due to their large sizes, however, compressiontechniques such as weight quantization and pruning are usually applied before they can be accommodated onthe edge. It is generally believed that quantization leads to performance degradation, and plenty of existingworks have explored quantization strategies aiming at minimum accuracy loss. In this paper, we argue thatquantization, which essentially imposes regularization on weight representations, can sometimes help toimprove accuracy. We conduct comprehensive experiments on three widely used applications: fully con-nected network (FCN) for biomedical image segmentation, convolutional neural network (CNN) for imageclassification on ImageNet, and recurrent neural network (RNN) for automatic speech recognition, and experi-mental results show that quantization can improve the accuracy by 1%, 1.95%, 4.23% on the three applicationsrespectively with 3.5x-6.4x memory reduction.