 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A probabilistic patch based image representation using Conditional Random Field model for image classification
Oct 05, 2016
In this paper we proposed an ordered patch based method using Conditional Random Field (CRF) in order to encode local properties and their spatial relationship in images to address texture classification, face recognition, and scene classification problems. Typical image classification approaches work without considering spatial causality among distinctive properties of an image for image representation in feature space. In this method first, each image is encoded as a sequence of ordered patches, including local properties. Second, the sequence of these ordered patches is modeled as a probabilistic feature vector by CRF to model spatial relationship of these local properties. And finally, image classification is performed on such probabilistic image representation. Experimental results on several standard image datasets indicate that proposed method outperforms some of existing image classification methods.
Maximal function pooling with applications
Mar 01, 2021

Inspired by the Hardy-Littlewood maximal function, we propose a novel pooling strategy which is called maxfun pooling. It is presented both as a viable alternative to some of the most popular pooling functions, such as max pooling and average pooling, and as a way of interpolating between these two algorithms. We demonstrate the features of maxfun pooling with two applications: first in the context of convolutional sparse coding, and then for image classification.
Early Convolutions Help Transformers See Better
Jun 28, 2021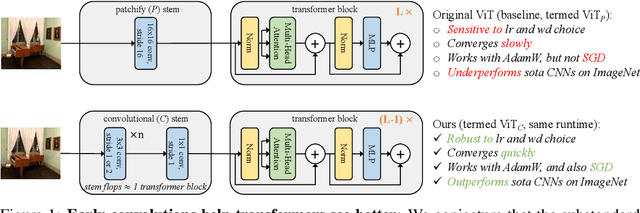

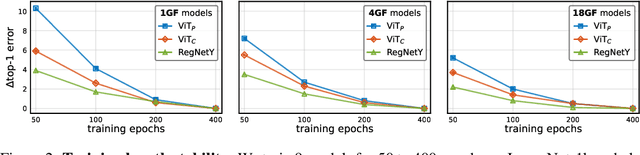
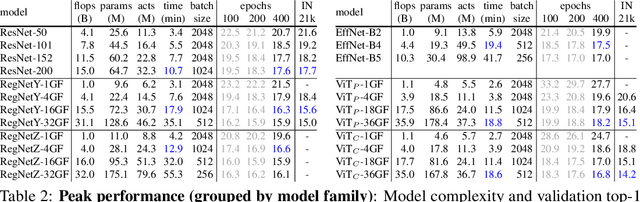
Vision transformer (ViT) models exhibit substandard optimizability. In particular, they are sensitive to the choice of optimizer (AdamW vs. SGD), optimizer hyperparameters, and training schedule length. In comparison, modern convolutional neural networks are far easier to optimize. Why is this the case? In this work, we conjecture that the issue lies with the patchify stem of ViT models, which is implemented by a stride-p pxp convolution (p=16 by default) applied to the input image. This large-kernel plus large-stride convolution runs counter to typical design choices of convolutional layers in neural networks. To test whether this atypical design choice causes an issue, we analyze the optimization behavior of ViT models with their original patchify stem versus a simple counterpart where we replace the ViT stem by a small number of stacked stride-two 3x3 convolutions. While the vast majority of computation in the two ViT designs is identical, we find that this small change in early visual processing results in markedly different training behavior in terms of the sensitivity to optimization settings as well as the final model accuracy. Using a convolutional stem in ViT dramatically increases optimization stability and also improves peak performance (by ~1-2% top-1 accuracy on ImageNet-1k), while maintaining flops and runtime. The improvement can be observed across the wide spectrum of model complexities (from 1G to 36G flops) and dataset scales (from ImageNet-1k to ImageNet-21k). These findings lead us to recommend using a standard, lightweight convolutional stem for ViT models as a more robust architectural choice compared to the original ViT model design.
TransFG: A Transformer Architecture for Fine-grained Recognition
Mar 17, 2021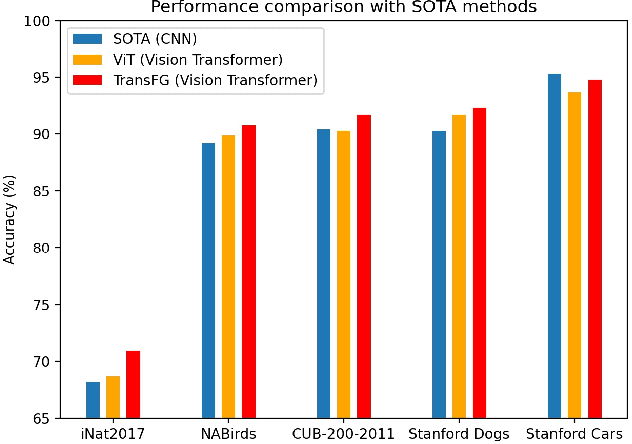
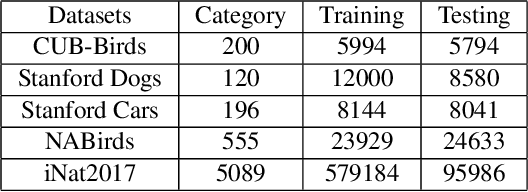
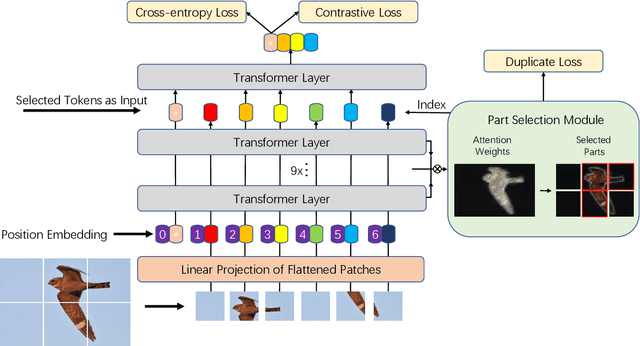
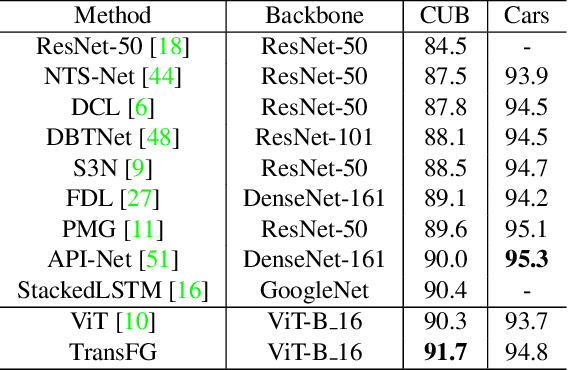
Fine-grained visual classification (FGVC) which aims at recognizing objects from subcategories is a very challenging task due to the inherently subtle inter-class differences. Recent works mainly tackle this problem by focusing on how to locate the most discriminative image regions and rely on them to improve the capability of networks to capture subtle variances. Most of these works achieve this by re-using the backbone network to extract features of selected regions. However, this strategy inevitably complicates the pipeline and pushes the proposed regions to contain most parts of the objects. Recently, vision transformer (ViT) shows its strong performance in the traditional classification task. The self-attention mechanism of the transformer links every patch token to the classification token. The strength of the attention link can be intuitively considered as an indicator of the importance of tokens. In this work, we propose a novel transformer-based framework TransFG where we integrate all raw attention weights of the transformer into an attention map for guiding the network to effectively and accurately select discriminative image patches and compute their relations. A contrastive loss is applied to further enlarge the distance between feature representations of similar sub-classes. We demonstrate the value of TransFG by conducting experiments on five popular fine-grained benchmarks: CUB-200-2011, Stanford Cars, Stanford Dogs, NABirds and iNat2017 where we achieve state-of-the-art performance. Qualitative results are presented for better understanding of our model.
Dilated Deep Residual Network for Image Denoising
Sep 27, 2017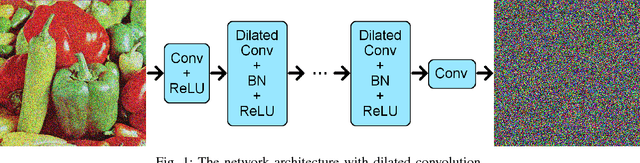
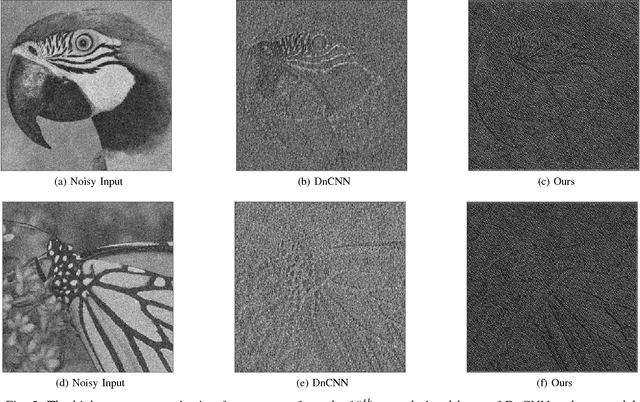


Variations of deep neural networks such as convolutional neural network (CNN) have been successfully applied to image denoising. The goal is to automatically learn a mapping from a noisy image to a clean image given training data consisting of pairs of noisy and clean images. Most existing CNN models for image denoising have many layers. In such cases, the models involve a large amount of parameters and are computationally expensive to train. In this paper, we develop a dilated residual CNN for Gaussian image denoising. Compared with the recently proposed residual denoiser, our method can achieve comparable performance with less computational cost. Specifically, we enlarge receptive field by adopting dilated convolution in residual network, and the dilation factor is set to a certain value. We utilize appropriate zero padding to make the dimension of the output the same as the input. It has been proven that the expansion of receptive field can boost the CNN performance in image classification, and we further demonstrate that it can also lead to competitive performance for denoising problem. Moreover, we present a formula to calculate receptive field size when dilated convolution is incorporated. Thus, the change of receptive field can be interpreted mathematically. To validate the efficacy of our approach, we conduct extensive experiments for both gray and color image denoising with specific or randomized noise levels. Both of the quantitative measurements and the visual results of denoising are promising comparing with state-of-the-art baselines.
Context-Aware Visual Policy Network for Sequence-Level Image Captioning
Aug 22, 2018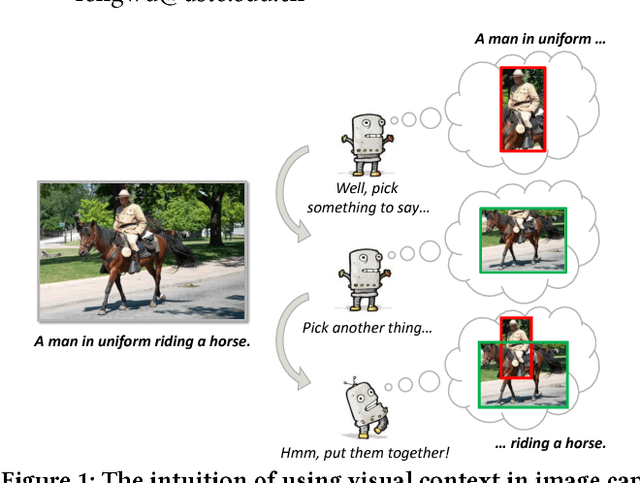
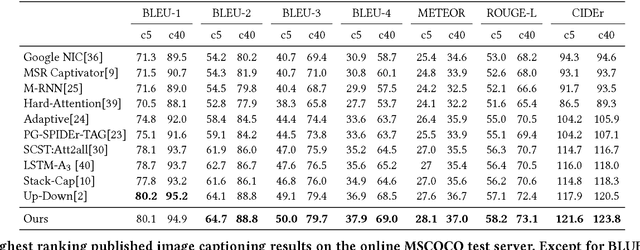
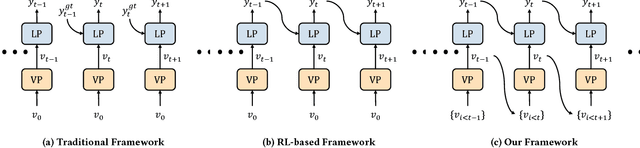
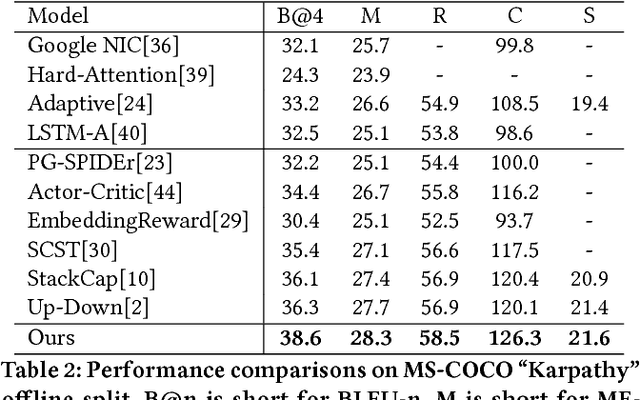
Many vision-language tasks can be reduced to the problem of sequence prediction for natural language output. In particular, recent advances in image captioning use deep reinforcement learning (RL) to alleviate the "exposure bias" during training: ground-truth subsequence is exposed in every step prediction, which introduces bias in test when only predicted subsequence is seen. However, existing RL-based image captioning methods only focus on the language policy while not the visual policy (e.g., visual attention), and thus fail to capture the visual context that are crucial for compositional reasoning such as visual relationships (e.g., "man riding horse") and comparisons (e.g., "smaller cat"). To fill the gap, we propose a Context-Aware Visual Policy network (CAVP) for sequence-level image captioning. At every time step, CAVP explicitly accounts for the previous visual attentions as the context, and then decides whether the context is helpful for the current word generation given the current visual attention. Compared against traditional visual attention that only fixes a single image region at every step, CAVP can attend to complex visual compositions over time. The whole image captioning model --- CAVP and its subsequent language policy network --- can be efficiently optimized end-to-end by using an actor-critic policy gradient method with respect to any caption evaluation metric. We demonstrate the effectiveness of CAVP by state-of-the-art performances on MS-COCO offline split and online server, using various metrics and sensible visualizations of qualitative visual context. The code is available at https://github.com/daqingliu/CAVP
Cognitive Visual Inspection Service for LCD Manufacturing Industry
Jan 11, 2021
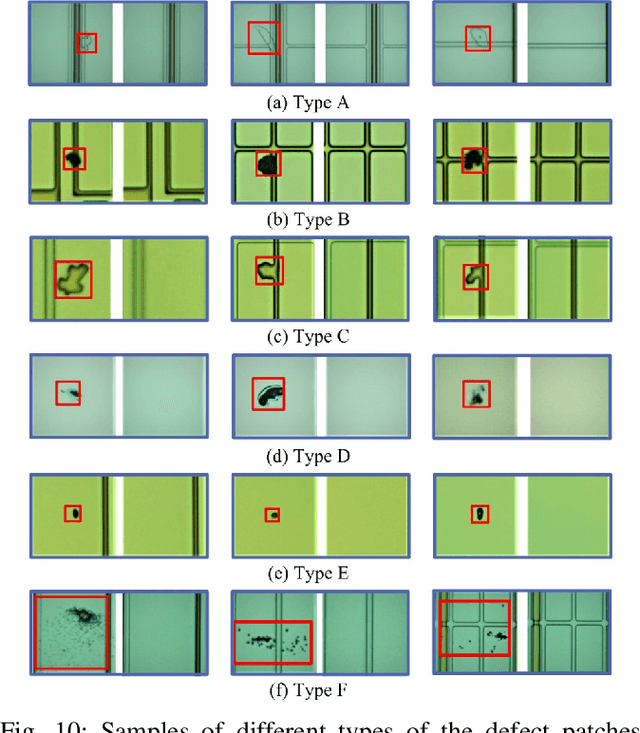
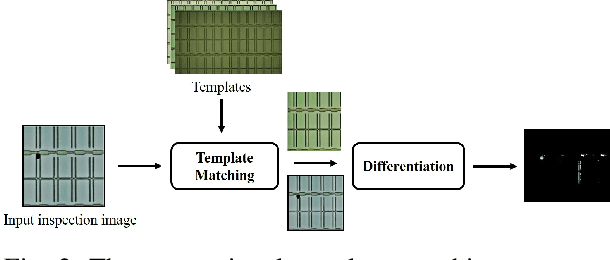
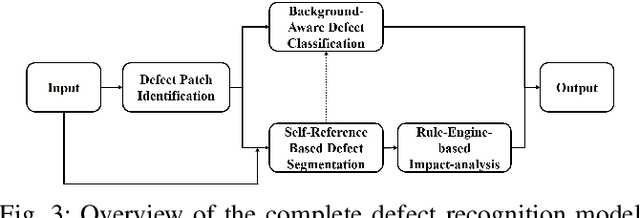
With the rapid growth of display devices, quality inspection via machine vision technology has become increasingly important for flat-panel displays (FPD) industry. This paper discloses a novel visual inspection system for liquid crystal display (LCD), which is currently a dominant type in the FPD industry. The system is based on two cornerstones: robust/high-performance defect recognition model and cognitive visual inspection service architecture. A hybrid application of conventional computer vision technique and the latest deep convolutional neural network (DCNN) leads to an integrated defect detection, classfication and impact evaluation model that can be economically trained with only image-level class annotations to achieve a high inspection accuracy. In addition, the properly trained model is robust to the variation of the image qulity, significantly alleviating the dependency between the model prediction performance and the image aquisition environment. This in turn justifies the decoupling of the defect recognition functions from the front-end device to the back-end serivce, motivating the design and realization of the cognitive visual inspection service architecture. Empirical case study is performed on a large-scale real-world LCD dataset from a manufacturing line with different layers and products, which shows the promising utility of our system, which has been deployed in a real-world LCD manufacturing line from a major player in the world.
PI-REC: Progressive Image Reconstruction Network With Edge and Color Domain
Mar 25, 2019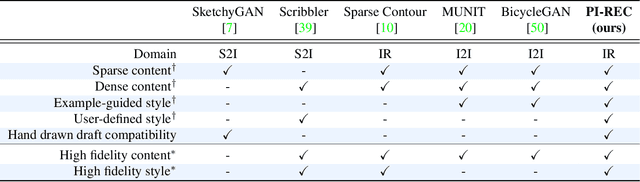
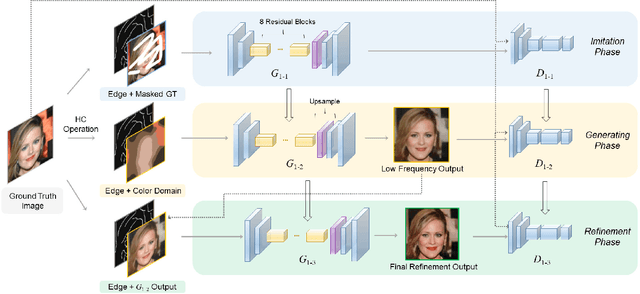
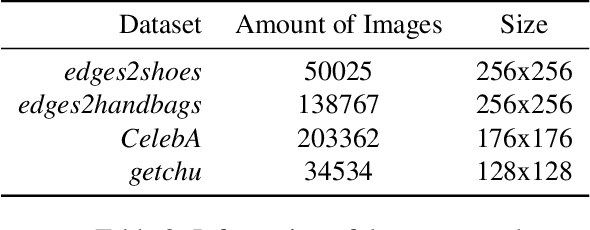

We propose a universal image reconstruction method to represent detailed images purely from binary sparse edge and flat color domain. Inspired by the procedures of painting, our framework, based on generative adversarial network, consists of three phases: Imitation Phase aims at initializing networks, followed by Generating Phase to reconstruct preliminary images. Moreover, Refinement Phase is utilized to fine-tune preliminary images into final outputs with details. This framework allows our model generating abundant high frequency details from sparse input information. We also explore the defects of disentangling style latent space implicitly from images, and demonstrate that explicit color domain in our model performs better on controllability and interpretability. In our experiments, we achieve outstanding results on reconstructing realistic images and translating hand drawn drafts into satisfactory paintings. Besides, within the domain of edge-to-image translation, our model PI-REC outperforms existing state-of-the-art methods on evaluations of realism and accuracy, both quantitatively and qualitatively.
Ancient Painting to Natural Image: A New Solution for Painting Processing
Jan 02, 2019
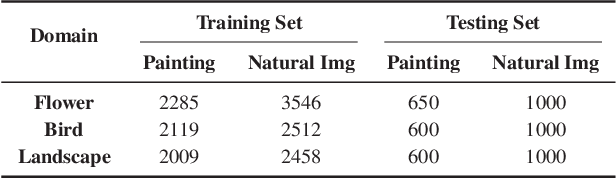

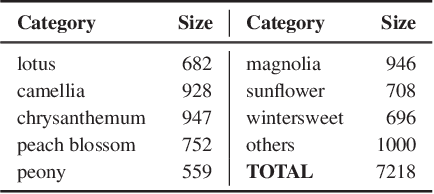
Collecting a large-scale and well-annotated dataset for image processing has become a common practice in computer vision. However, in the ancient painting area, this task is not practical as the number of paintings is limited and their style is greatly diverse. We, therefore, propose a novel solution for the problems that come with ancient painting processing. This is to use domain transfer to convert ancient paintings to photo-realistic natural images. By doing so, the ancient painting processing problems become natural image processing problems and models trained on natural images can be directly applied to the transferred paintings. Specifically, we focus on Chinese ancient flower, bird and landscape paintings in this work. A novel Domain Style Transfer Network (DSTN) is proposed to transfer ancient paintings to natural images which employ a compound loss to ensure that the transferred paintings still maintain the color composition and content of the input paintings. The experiment results show that the transferred paintings generated by the DSTN have a better performance in both the human perceptual test and other image processing tasks than other state-of-art methods, indicating the authenticity of the transferred paintings and the superiority of the proposed method.
OFEI: A Semi-black-box Android Adversarial Sample Attack Framework Against DLaaS
May 25, 2021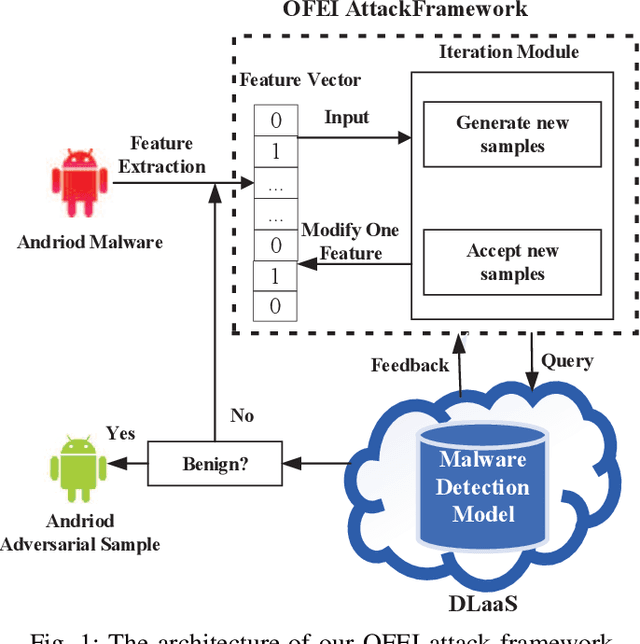
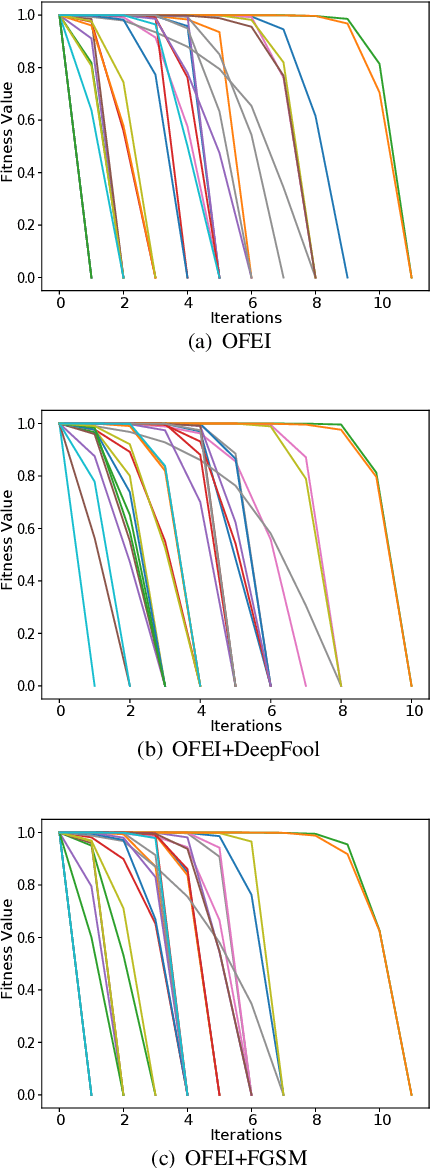
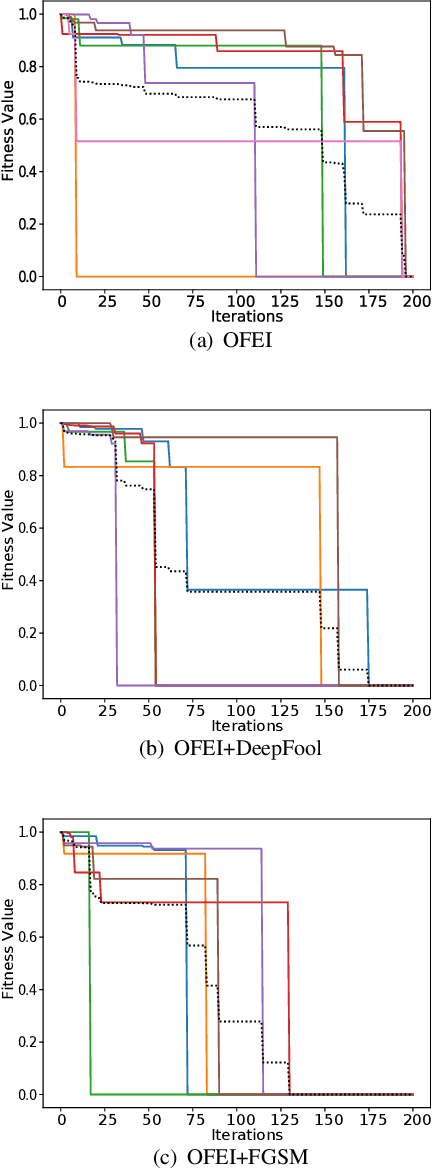
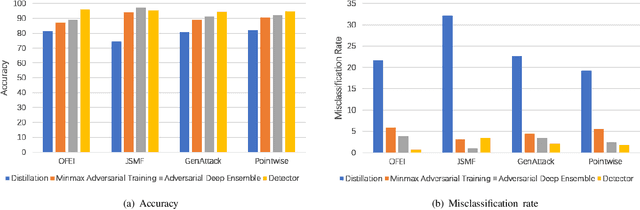
With the growing popularity of Android devices, Android malware is seriously threatening the safety of users. Although such threats can be detected by deep learning as a service (DLaaS), deep neural networks as the weakest part of DLaaS are often deceived by the adversarial samples elaborated by attackers. In this paper, we propose a new semi-black-box attack framework called one-feature-each-iteration (OFEI) to craft Android adversarial samples. This framework modifies as few features as possible and requires less classifier information to fool the classifier. We conduct a controlled experiment to evaluate our OFEI framework by comparing it with the benchmark methods JSMF, GenAttack and pointwise attack. The experimental results show that our OFEI has a higher misclassification rate of 98.25%. Furthermore, OFEI can extend the traditional white-box attack methods in the image field, such as fast gradient sign method (FGSM) and DeepFool, to craft adversarial samples for Android. Finally, to enhance the security of DLaaS, we use two uncertainties of the Bayesian neural network to construct the combined uncertainty, which is used to detect adversarial samples and achieves a high detection rate of 99.28%.