 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransFG: A Transformer Architecture for Fine-grained Recognition
Paper and Code
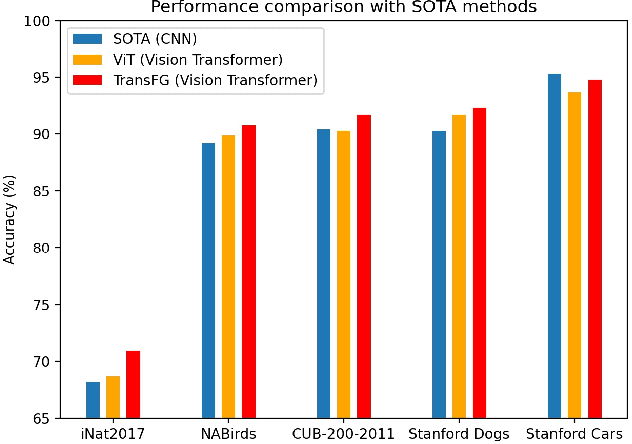
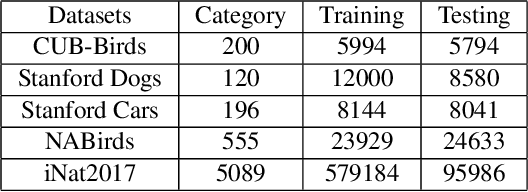
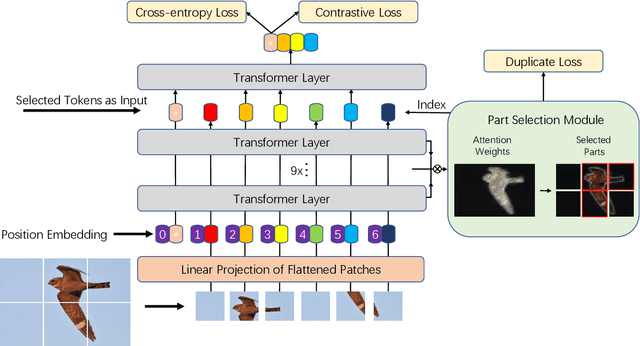
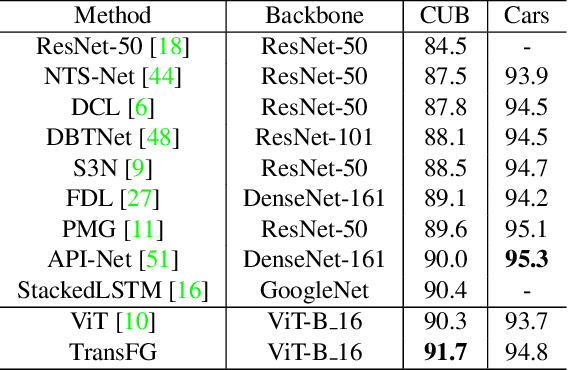
Fine-grained visual classification (FGVC) which aims at recognizing objects from subcategories is a very challenging task due to the inherently subtle inter-class differences. Recent works mainly tackle this problem by focusing on how to locate the most discriminative image regions and rely on them to improve the capability of networks to capture subtle variances. Most of these works achieve this by re-using the backbone network to extract features of selected regions. However, this strategy inevitably complicates the pipeline and pushes the proposed regions to contain most parts of the objects. Recently, vision transformer (ViT) shows its strong performance in the traditional classification task. The self-attention mechanism of the transformer links every patch token to the classification token. The strength of the attention link can be intuitively considered as an indicator of the importance of tokens. In this work, we propose a novel transformer-based framework TransFG where we integrate all raw attention weights of the transformer into an attention map for guiding the network to effectively and accurately select discriminative image patches and compute their relations. A contrastive loss is applied to further enlarge the distance between feature representations of similar sub-classes. We demonstrate the value of TransFG by conducting experiments on five popular fine-grained benchmarks: CUB-200-2011, Stanford Cars, Stanford Dogs, NABirds and iNat2017 where we achieve state-of-the-art performance. Qualitative results are presented for better understanding of our model. Code is available at https://github.com/TACJu/TransFG.