 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cross-Modal Retrieval Augmentation for Multi-Modal Classification
Apr 16, 2021

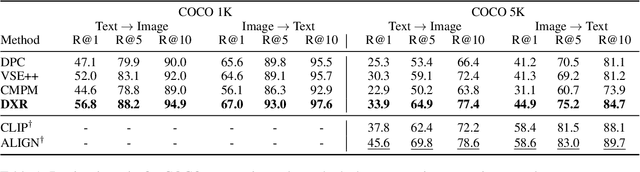
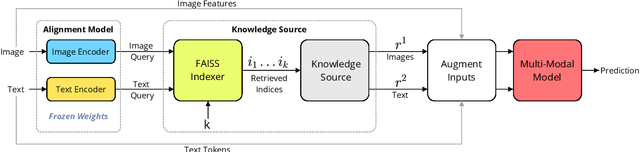
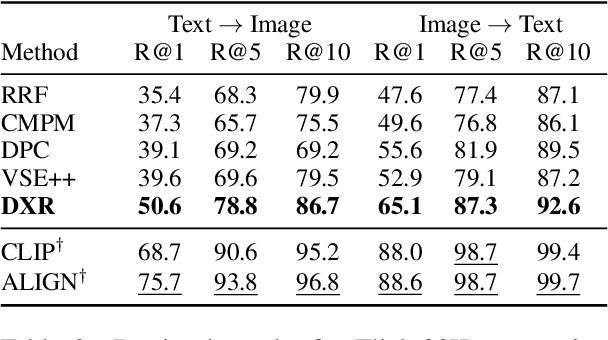
Recent advances in using retrieval components over external knowledge sources have shown impressive results for a variety of downstream tasks in natural language processing. Here, we explore the use of unstructured external knowledge sources of images and their corresponding captions for improving visual question answering (VQA). First, we train a novel alignment model for embedding images and captions in the same space, which achieves substantial improvement in performance on image-caption retrieval w.r.t. similar methods. Second, we show that retrieval-augmented multi-modal transformers using the trained alignment model improve results on VQA over strong baselines. We further conduct extensive experiments to establish the promise of this approach, and examine novel applications for inference time such as hot-swapping indices.
PIM-DRAM:Accelerating Machine Learning Workloads using Processing in Memory based on DRAM Technology
May 08, 2021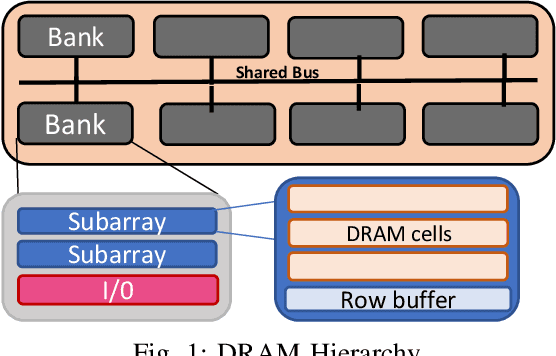
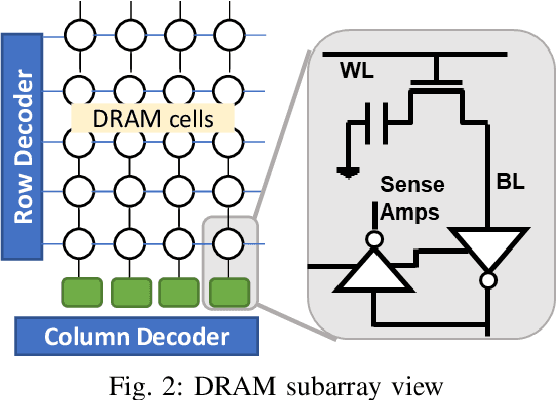
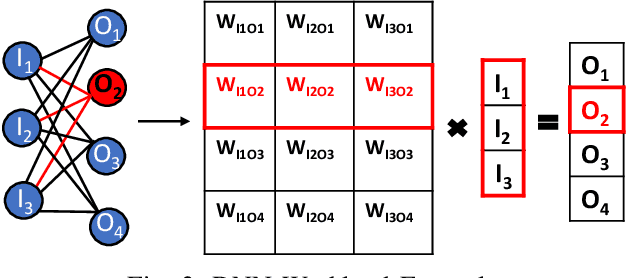
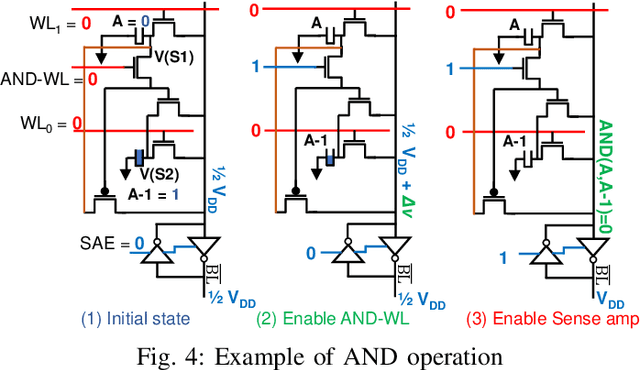
Deep Neural Networks (DNNs) have gained significant interest in the recent past for plethora of applications such as image and video analytics, language translation, and medical diagnosis. High memory bandwidth is required to keep up with the needs of data-intensive DNN applications when implemented on a von-Neumann hardware architecture as majority of the data resides in the main memory. Therefore, processing in memory can provide a promising solution for the memory wall bottleneck for ML workloads. In this work, we propose a DRAM-based processing-in-memory (PIM) multiplication primitive coupled with intra-bank accumulation to accelerate matrix vector operations in ML workloads. Moreover, we propose a processing-in-memory DRAM bank architecture, data mapping and dataflow based on the proposed primitive. System evaluations performed on networks like AlexNet, VGG16 and ResNet18 show that the proposed architecture, mapping, and data flow can provide up to 23x and 6.5x benefits over a GPU and an ideal conventional (non-PIM) baseline architecture with infinite compute bandwidth, respectively.
Generative Adversarial Transformers
Mar 02, 2021
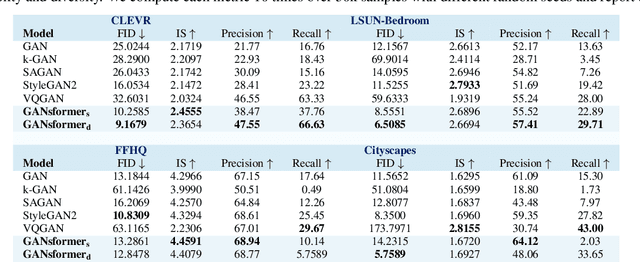
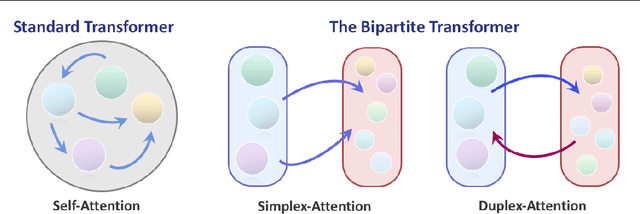
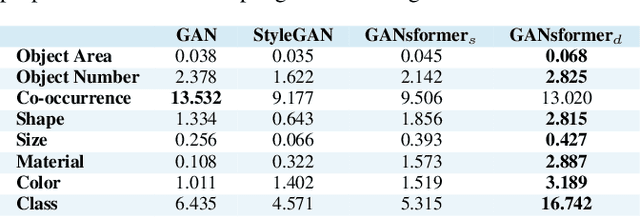
We introduce the GANsformer, a novel and efficient type of transformer, and explore it for the task of visual generative modeling. The network employs a bipartite structure that enables long-range interactions across the image, while maintaining computation of linearly efficiency, that can readily scale to high-resolution synthesis. It iteratively propagates information from a set of latent variables to the evolving visual features and vice versa, to support the refinement of each in light of the other and encourage the emergence of compositional representations of objects and scenes. In contrast to the classic transformer architecture, it utilizes multiplicative integration that allows flexible region-based modulation, and can thus be seen as a generalization of the successful StyleGAN network. We demonstrate the model's strength and robustness through a careful evaluation over a range of datasets, from simulated multi-object environments to rich real-world indoor and outdoor scenes, showing it achieves state-of-the-art results in terms of image quality and diversity, while enjoying fast learning and better data-efficiency. Further qualitative and quantitative experiments offer us an insight into the model's inner workings, revealing improved interpretability and stronger disentanglement, and illustrating the benefits and efficacy of our approach. An implementation of the model is available at https://github.com/dorarad/gansformer.
A Hitchhiker's Guide to Structural Similarity
Jan 16, 2021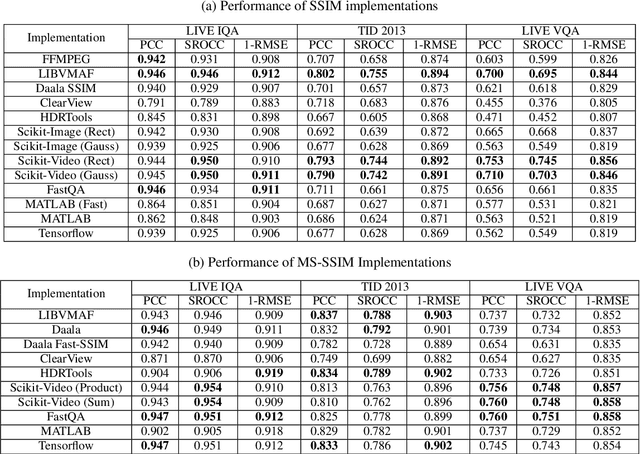
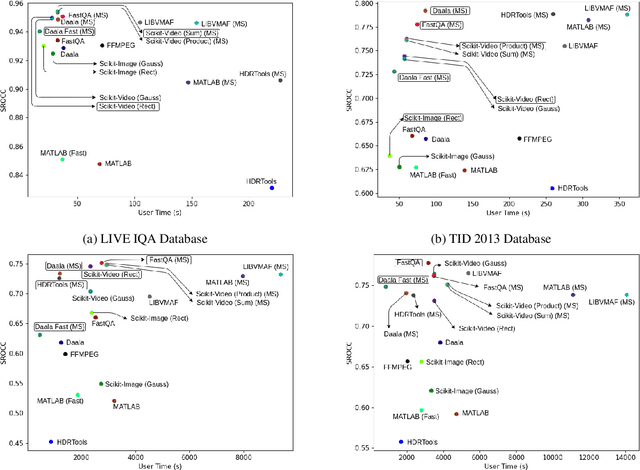
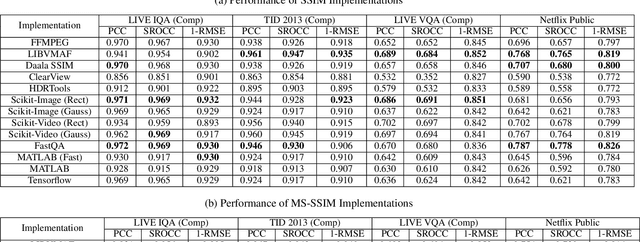
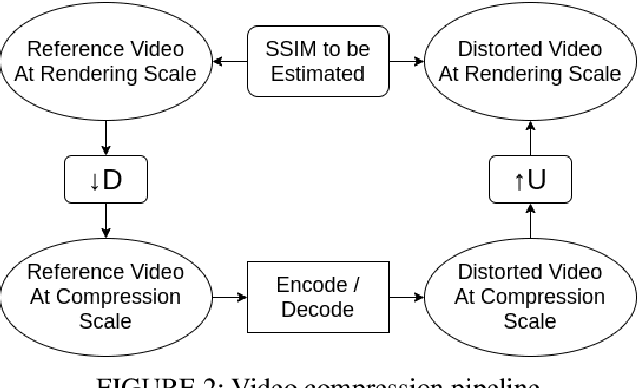
The Structural Similarity (SSIM) Index is a very widely used image/video quality model that continues to play an important role in the perceptual evaluation of compression algorithms, encoding recipes and numerous other image/video processing algorithms. Several public implementations of the SSIM and Multiscale-SSIM (MS-SSIM) algorithms have been developed, which differ in efficiency and performance. This "bendable ruler" makes the process of quality assessment of encoding algorithms unreliable. To address this situation, we studied and compared the functions and performances of popular and widely used implementations of SSIM, and we also considered a variety of design choices. Based on our studies and experiments, we have arrived at a collection of recommendations on how to use SSIM most effectively, including ways to reduce its computational burden.
Plot2API: Recommending Graphic API from Plot via Semantic Parsing Guided Neural Network
Apr 02, 2021
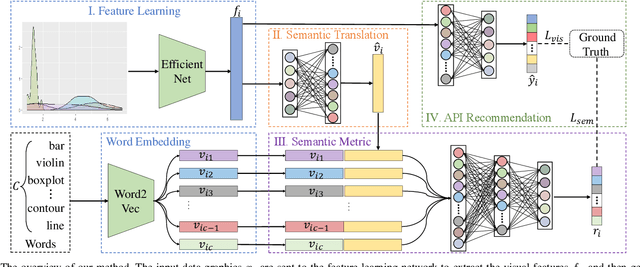
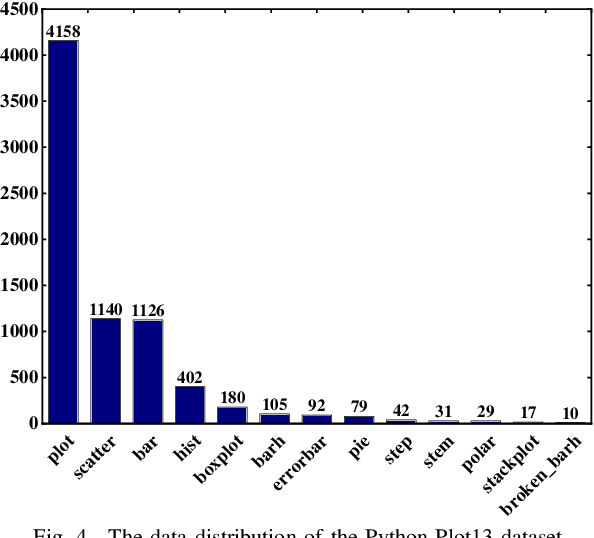
Plot-based Graphic API recommendation (Plot2API) is an unstudied but meaningful issue, which has several important applications in the context of software engineering and data visualization, such as the plotting guidance of the beginner, graphic API correlation analysis, and code conversion for plotting. Plot2API is a very challenging task, since each plot is often associated with multiple APIs and the appearances of the graphics drawn by the same API can be extremely varied due to the different settings of the parameters. Additionally, the samples of different APIs also suffer from extremely imbalanced. Considering the lack of technologies in Plot2API, we present a novel deep multi-task learning approach named Semantic Parsing Guided Neural Network (SPGNN) which translates the Plot2API issue as a multi-label image classification and an image semantic parsing tasks for the solution. In SPGNN, the recently advanced Convolutional Neural Network (CNN) named EfficientNet is employed as the backbone network for API recommendation. Meanwhile, a semantic parsing module is complemented to exploit the semantic relevant visual information in feature learning and eliminate the appearance-relevant visual information which may confuse the visual-information-based API recommendation. Moreover, the recent data augmentation technique named random erasing is also applied for alleviating the imbalance of API categories. We collect plots with the graphic APIs used to drawn them from Stack Overflow, and release three new Plot2API datasets corresponding to the graphic APIs of R and Python programming languages for evaluating the effectiveness of Plot2API techniques. Extensive experimental results not only demonstrate the superiority of our method over the recent deep learning baselines but also show the practicability of our method in the recommendation of graphic APIs.
DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification
Jun 03, 2021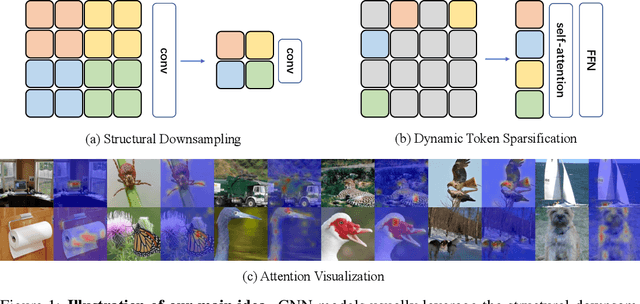
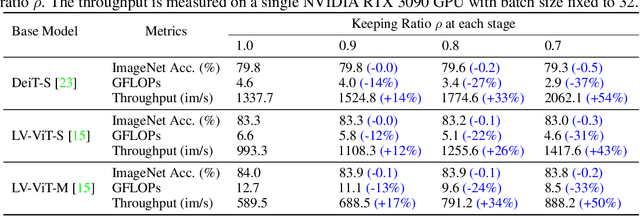
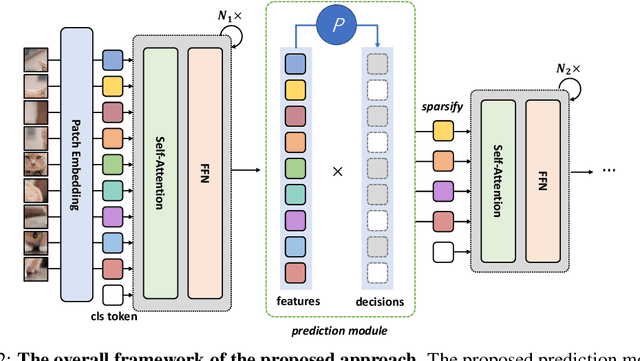
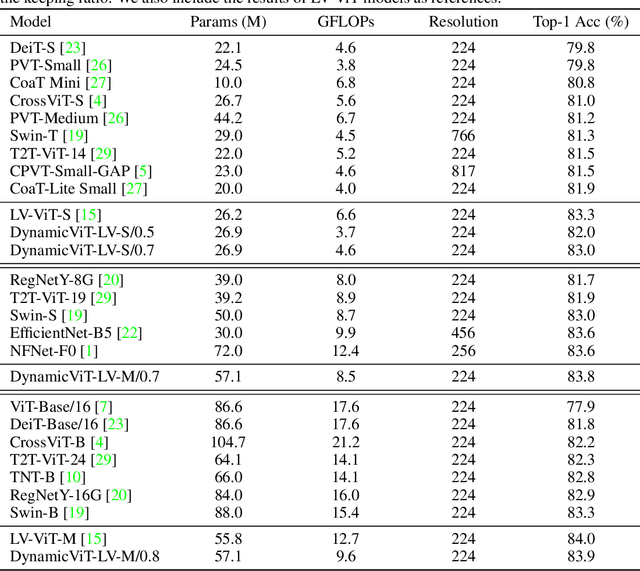
Attention is sparse in vision transformers. We observe the final prediction in vision transformers is only based on a subset of most informative tokens, which is sufficient for accurate image recognition. Based on this observation, we propose a dynamic token sparsification framework to prune redundant tokens progressively and dynamically based on the input. Specifically, we devise a lightweight prediction module to estimate the importance score of each token given the current features. The module is added to different layers to prune redundant tokens hierarchically. To optimize the prediction module in an end-to-end manner, we propose an attention masking strategy to differentiably prune a token by blocking its interactions with other tokens. Benefiting from the nature of self-attention, the unstructured sparse tokens are still hardware friendly, which makes our framework easy to achieve actual speed-up. By hierarchically pruning 66% of the input tokens, our method greatly reduces 31%~37% FLOPs and improves the throughput by over 40% while the drop of accuracy is within 0.5% for various vision transformers. Equipped with the dynamic token sparsification framework, DynamicViT models can achieve very competitive complexity/accuracy trade-offs compared to state-of-the-art CNNs and vision transformers on ImageNet. Code is available at https://github.com/raoyongming/DynamicViT
Low Resolution Information Also Matters: Learning Multi-Resolution Representations for Person Re-Identification
May 26, 2021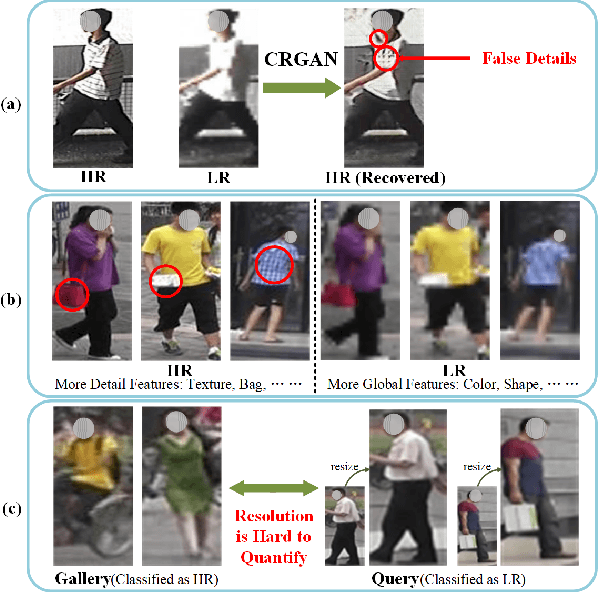
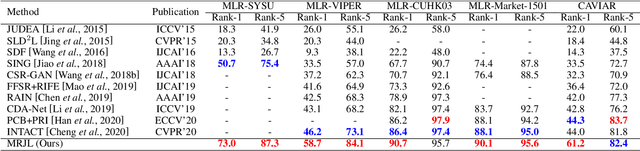
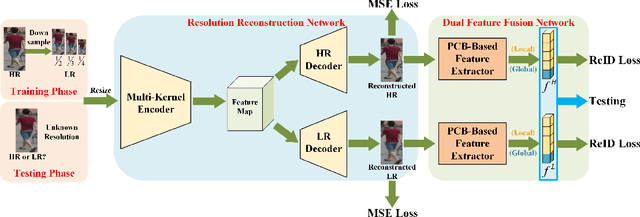
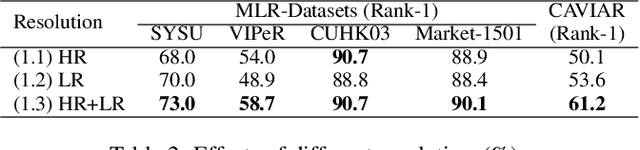
As a prevailing task in video surveillance and forensics field, person re-identification (re-ID) aims to match person images captured from non-overlapped cameras. In unconstrained scenarios, person images often suffer from the resolution mismatch problem, i.e., \emph{Cross-Resolution Person Re-ID}. To overcome this problem, most existing methods restore low resolution (LR) images to high resolution (HR) by super-resolution (SR). However, they only focus on the HR feature extraction and ignore the valid information from original LR images. In this work, we explore the influence of resolutions on feature extraction and develop a novel method for cross-resolution person re-ID called \emph{\textbf{M}ulti-Resolution \textbf{R}epresentations \textbf{J}oint \textbf{L}earning} (\textbf{MRJL}). Our method consists of a Resolution Reconstruction Network (RRN) and a Dual Feature Fusion Network (DFFN). The RRN uses an input image to construct a HR version and a LR version with an encoder and two decoders, while the DFFN adopts a dual-branch structure to generate person representations from multi-resolution images. Comprehensive experiments on five benchmarks verify the superiority of the proposed MRJL over the relevent state-of-the-art methods.
Planetary UAV localization based on Multi-modal Registration with Pre-existing Digital Terrain Model
Jun 24, 2021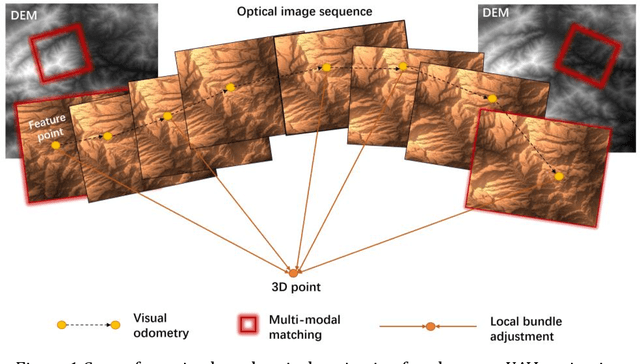



The autonomous real-time optical navigation of planetary UAV is of the key technologies to ensure the success of the exploration. In such a GPS denied environment, vision-based localization is an optimal approach. In this paper, we proposed a multi-modal registration based SLAM algorithm, which estimates the location of a planet UAV using a nadir view camera on the UAV compared with pre-existing digital terrain model. To overcome the scale and appearance difference between on-board UAV images and pre-installed digital terrain model, a theoretical model is proposed to prove that topographic features of UAV image and DEM can be correlated in frequency domain via cross power spectrum. To provide the six-DOF of the UAV, we also developed an optimization approach which fuses the geo-referencing result into a SLAM system via LBA (Local Bundle Adjustment) to achieve robust and accurate vision-based navigation even in featureless planetary areas. To test the robustness and effectiveness of the proposed localization algorithm, a new cross-source drone-based localization dataset for planetary exploration is proposed. The proposed dataset includes 40200 synthetic drone images taken from nine planetary scenes with related DEM query images. Comparison experiments carried out demonstrate that over the flight distance of 33.8km, the proposed method achieved average localization error of 0.45 meters, compared to 1.31 meters by ORB-SLAM, with the processing speed of 12hz which will ensure a real-time performance. We will make our datasets available to encourage further work on this promising topic.
Deep Sketch-Based Modeling: Tips and Tricks
Nov 12, 2020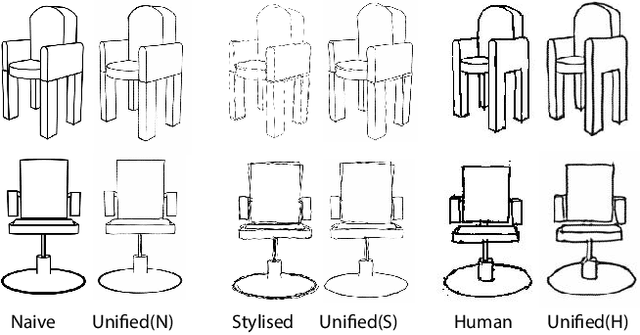
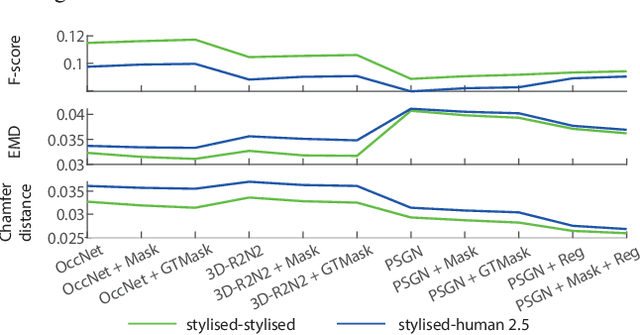

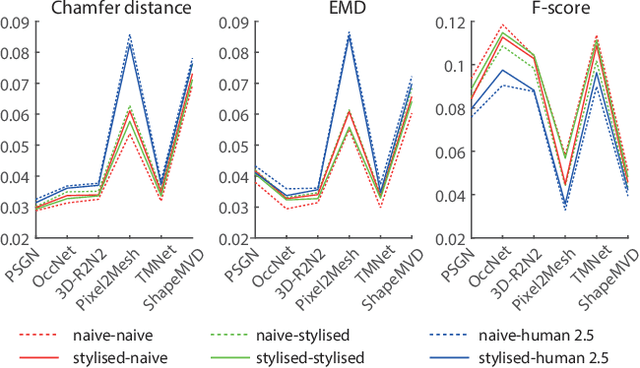
Deep image-based modeling received lots of attention in recent years, yet the parallel problem of sketch-based modeling has only been briefly studied, often as a potential application. In this work, for the first time, we identify the main differences between sketch and image inputs: (i) style variance, (ii) imprecise perspective, and (iii) sparsity. We discuss why each of these differences can pose a challenge, and even make a certain class of image-based methods inapplicable. We study alternative solutions to address each of the difference. By doing so, we drive out a few important insights: (i) sparsity commonly results in an incorrect prediction of foreground versus background, (ii) diversity of human styles, if not taken into account, can lead to very poor generalization properties, and finally (iii) unless a dedicated sketching interface is used, one can not expect sketches to match a perspective of a fixed viewpoint. Finally, we compare a set of representative deep single-image modeling solutions and show how their performance can be improved to tackle sketch input by taking into consideration the identified critical differences.
Exploiting Temporal Dependencies for Cross-Modal Music Piece Identification
May 26, 2021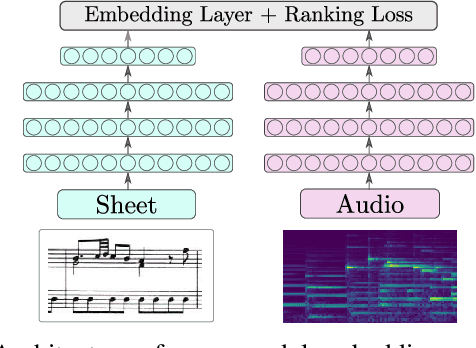
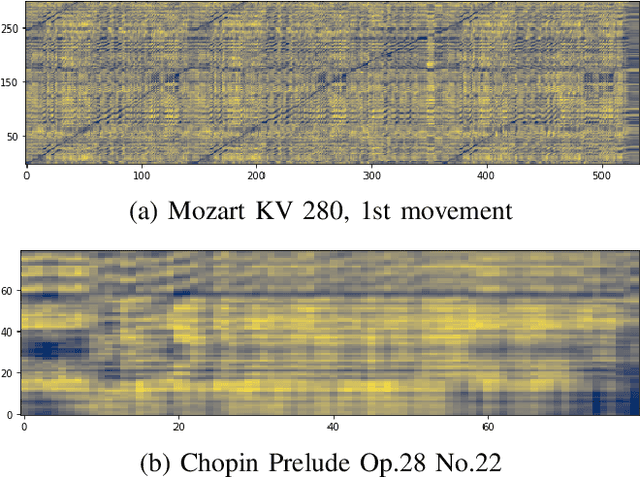
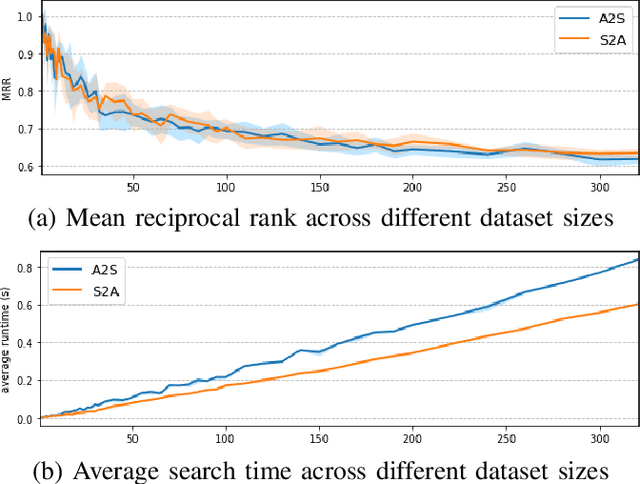
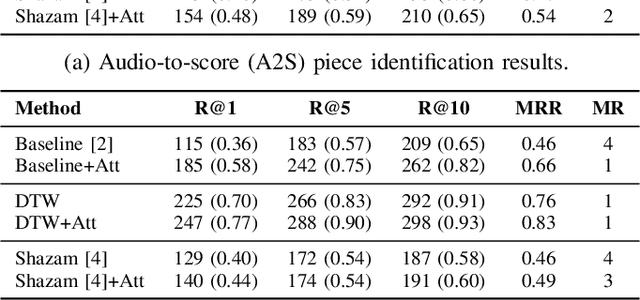
This paper addresses the problem of cross-modal musical piece identification and retrieval: finding the appropriate recording(s) from a database given a sheet music query, and vice versa, working directly with audio and scanned sheet music images. The fundamental approach to this is to learn a cross-modal embedding space with a suitable similarity structure for audio and sheet image snippets, using a deep neural network, and identifying candidate pieces by cross-modal near neighbour search in this space. However, this method is oblivious of temporal aspects of music. In this paper, we introduce two strategies that address this shortcoming. First, we present a strategy that aligns sequences of embeddings learned from sheet music scans and audio snippets. A series of experiments on whole piece and fragment-level retrieval on 24 hours worth of classical piano recordings demonstrates significant improvement. Second, we show that the retrieval can be further improved by introducing an attention mechanism to the embedding learning model that reduces the effects of tempo variations in music. To conclude, we assess the scalability of our method and discuss potential measures to make it suitable for truly large-scale applications.
* 5 pages, 3 figures