 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
UnCommon Objects in 3D
Jan 13, 2025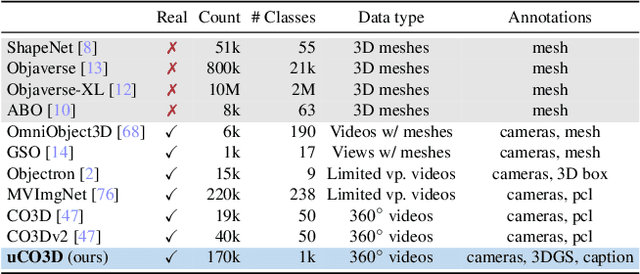
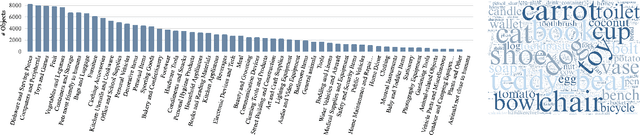


We introduce Uncommon Objects in 3D (uCO3D), a new object-centric dataset for 3D deep learning and 3D generative AI. uCO3D is the largest publicly-available collection of high-resolution videos of objects with 3D annotations that ensures full-360$^{\circ}$ coverage. uCO3D is significantly more diverse than MVImgNet and CO3Dv2, covering more than 1,000 object categories. It is also of higher quality, due to extensive quality checks of both the collected videos and the 3D annotations. Similar to analogous datasets, uCO3D contains annotations for 3D camera poses, depth maps and sparse point clouds. In addition, each object is equipped with a caption and a 3D Gaussian Splat reconstruction. We train several large 3D models on MVImgNet, CO3Dv2, and uCO3D and obtain superior results using the latter, showing that uCO3D is better for learning applications.
CoTracker3: Simpler and Better Point Tracking by Pseudo-Labelling Real Videos
Oct 15, 2024Most state-of-the-art point trackers are trained on synthetic data due to the difficulty of annotating real videos for this task. However, this can result in suboptimal performance due to the statistical gap between synthetic and real videos. In order to understand these issues better, we introduce CoTracker3, comprising a new tracking model and a new semi-supervised training recipe. This allows real videos without annotations to be used during training by generating pseudo-labels using off-the-shelf teachers. The new model eliminates or simplifies components from previous trackers, resulting in a simpler and often smaller architecture. This training scheme is much simpler than prior work and achieves better results using 1,000 times less data. We further study the scaling behaviour to understand the impact of using more real unsupervised data in point tracking. The model is available in online and offline variants and reliably tracks visible and occluded points.
Meta 3D AssetGen: Text-to-Mesh Generation with High-Quality Geometry, Texture, and PBR Materials
Jul 02, 2024



We present Meta 3D AssetGen (AssetGen), a significant advancement in text-to-3D generation which produces faithful, high-quality meshes with texture and material control. Compared to works that bake shading in the 3D object's appearance, AssetGen outputs physically-based rendering (PBR) materials, supporting realistic relighting. AssetGen generates first several views of the object with factored shaded and albedo appearance channels, and then reconstructs colours, metalness and roughness in 3D, using a deferred shading loss for efficient supervision. It also uses a sign-distance function to represent 3D shape more reliably and introduces a corresponding loss for direct shape supervision. This is implemented using fused kernels for high memory efficiency. After mesh extraction, a texture refinement transformer operating in UV space significantly improves sharpness and details. AssetGen achieves 17% improvement in Chamfer Distance and 40% in LPIPS over the best concurrent work for few-view reconstruction, and a human preference of 72% over the best industry competitors of comparable speed, including those that support PBR. Project page with generated assets: https://assetgen.github.io
Meta 3D TextureGen: Fast and Consistent Texture Generation for 3D Objects
Jul 02, 2024



The recent availability and adaptability of text-to-image models has sparked a new era in many related domains that benefit from the learned text priors as well as high-quality and fast generation capabilities, one of which is texture generation for 3D objects. Although recent texture generation methods achieve impressive results by using text-to-image networks, the combination of global consistency, quality, and speed, which is crucial for advancing texture generation to real-world applications, remains elusive. To that end, we introduce Meta 3D TextureGen: a new feedforward method comprised of two sequential networks aimed at generating high-quality and globally consistent textures for arbitrary geometries of any complexity degree in less than 20 seconds. Our method achieves state-of-the-art results in quality and speed by conditioning a text-to-image model on 3D semantics in 2D space and fusing them into a complete and high-resolution UV texture map, as demonstrated by extensive qualitative and quantitative evaluations. In addition, we introduce a texture enhancement network that is capable of up-scaling any texture by an arbitrary ratio, producing 4k pixel resolution textures.
Meta 3D Gen
Jul 02, 2024



We introduce Meta 3D Gen (3DGen), a new state-of-the-art, fast pipeline for text-to-3D asset generation. 3DGen offers 3D asset creation with high prompt fidelity and high-quality 3D shapes and textures in under a minute. It supports physically-based rendering (PBR), necessary for 3D asset relighting in real-world applications. Additionally, 3DGen supports generative retexturing of previously generated (or artist-created) 3D shapes using additional textual inputs provided by the user. 3DGen integrates key technical components, Meta 3D AssetGen and Meta 3D TextureGen, that we developed for text-to-3D and text-to-texture generation, respectively. By combining their strengths, 3DGen represents 3D objects simultaneously in three ways: in view space, in volumetric space, and in UV (or texture) space. The integration of these two techniques achieves a win rate of 68% with respect to the single-stage model. We compare 3DGen to numerous industry baselines, and show that it outperforms them in terms of prompt fidelity and visual quality for complex textual prompts, while being significantly faster.
IM-3D: Iterative Multiview Diffusion and Reconstruction for High-Quality 3D Generation
Feb 13, 2024



Most text-to-3D generators build upon off-the-shelf text-to-image models trained on billions of images. They use variants of Score Distillation Sampling (SDS), which is slow, somewhat unstable, and prone to artifacts. A mitigation is to fine-tune the 2D generator to be multi-view aware, which can help distillation or can be combined with reconstruction networks to output 3D objects directly. In this paper, we further explore the design space of text-to-3D models. We significantly improve multi-view generation by considering video instead of image generators. Combined with a 3D reconstruction algorithm which, by using Gaussian splatting, can optimize a robust image-based loss, we directly produce high-quality 3D outputs from the generated views. Our new method, IM-3D, reduces the number of evaluations of the 2D generator network 10-100x, resulting in a much more efficient pipeline, better quality, fewer geometric inconsistencies, and higher yield of usable 3D assets.
Mosaic-SDF for 3D Generative Models
Dec 14, 2023



Current diffusion or flow-based generative models for 3D shapes divide to two: distilling pre-trained 2D image diffusion models, and training directly on 3D shapes. When training a diffusion or flow models on 3D shapes a crucial design choice is the shape representation. An effective shape representation needs to adhere three design principles: it should allow an efficient conversion of large 3D datasets to the representation form; it should provide a good tradeoff of approximation power versus number of parameters; and it should have a simple tensorial form that is compatible with existing powerful neural architectures. While standard 3D shape representations such as volumetric grids and point clouds do not adhere to all these principles simultaneously, we advocate in this paper a new representation that does. We introduce Mosaic-SDF (M-SDF): a simple 3D shape representation that approximates the Signed Distance Function (SDF) of a given shape by using a set of local grids spread near the shape's boundary. The M-SDF representation is fast to compute for each shape individually making it readily parallelizable; it is parameter efficient as it only covers the space around the shape's boundary; and it has a simple matrix form, compatible with Transformer-based architectures. We demonstrate the efficacy of the M-SDF representation by using it to train a 3D generative flow model including class-conditioned generation with the 3D Warehouse dataset, and text-to-3D generation using a dataset of about 600k caption-shape pairs.
Replay: Multi-modal Multi-view Acted Videos for Casual Holography
Jul 22, 2023We introduce Replay, a collection of multi-view, multi-modal videos of humans interacting socially. Each scene is filmed in high production quality, from different viewpoints with several static cameras, as well as wearable action cameras, and recorded with a large array of microphones at different positions in the room. Overall, the dataset contains over 4000 minutes of footage and over 7 million timestamped high-resolution frames annotated with camera poses and partially with foreground masks. The Replay dataset has many potential applications, such as novel-view synthesis, 3D reconstruction, novel-view acoustic synthesis, human body and face analysis, and training generative models. We provide a benchmark for training and evaluating novel-view synthesis, with two scenarios of different difficulty. Finally, we evaluate several baseline state-of-the-art methods on the new benchmark.
CoTracker: It is Better to Track Together
Jul 14, 2023



Methods for video motion prediction either estimate jointly the instantaneous motion of all points in a given video frame using optical flow or independently track the motion of individual points throughout the video. The latter is true even for powerful deep-learning methods that can track points through occlusions. Tracking points individually ignores the strong correlation that can exist between the points, for instance, because they belong to the same physical object, potentially harming performance. In this paper, we thus propose CoTracker, an architecture that jointly tracks multiple points throughout an entire video. This architecture combines several ideas from the optical flow and tracking literature in a new, flexible and powerful design. It is based on a transformer network that models the correlation of different points in time via specialised attention layers. The transformer iteratively updates an estimate of several trajectories. It can be applied in a sliding-window manner to very long videos, for which we engineer an unrolled training loop. It can track from one to several points jointly and supports adding new points to track at any time. The result is a flexible and powerful tracking algorithm that outperforms state-of-the-art methods in almost all benchmarks.