 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mitigating the Curse of Dimensionality for Certified Robustness via Dual Randomized Smoothing
Apr 15, 2024
Randomized Smoothing (RS) has been proven a promising method for endowing an arbitrary image classifier with certified robustness. However, the substantial uncertainty inherent in the high-dimensional isotropic Gaussian noise imposes the curse of dimensionality on RS. Specifically, the upper bound of ${\ell_2}$ certified robustness radius provided by RS exhibits a diminishing trend with the expansion of the input dimension $d$, proportionally decreasing at a rate of $1/\sqrt{d}$. This paper explores the feasibility of providing ${\ell_2}$ certified robustness for high-dimensional input through the utilization of dual smoothing in the lower-dimensional space. The proposed Dual Randomized Smoothing (DRS) down-samples the input image into two sub-images and smooths the two sub-images in lower dimensions. Theoretically, we prove that DRS guarantees a tight ${\ell_2}$ certified robustness radius for the original input and reveal that DRS attains a superior upper bound on the ${\ell_2}$ robustness radius, which decreases proportionally at a rate of $(1/\sqrt m + 1/\sqrt n )$ with $m+n=d$. Extensive experiments demonstrate the generalizability and effectiveness of DRS, which exhibits a notable capability to integrate with established methodologies, yielding substantial improvements in both accuracy and ${\ell_2}$ certified robustness baselines of RS on the CIFAR-10 and ImageNet datasets. Code is available at https://github.com/xiasong0501/DRS.
Salient Object-Aware Background Generation using Text-Guided Diffusion Models
Apr 15, 2024Generating background scenes for salient objects plays a crucial role across various domains including creative design and e-commerce, as it enhances the presentation and context of subjects by integrating them into tailored environments. Background generation can be framed as a task of text-conditioned outpainting, where the goal is to extend image content beyond a salient object's boundaries on a blank background. Although popular diffusion models for text-guided inpainting can also be used for outpainting by mask inversion, they are trained to fill in missing parts of an image rather than to place an object into a scene. Consequently, when used for background creation, inpainting models frequently extend the salient object's boundaries and thereby change the object's identity, which is a phenomenon we call "object expansion." This paper introduces a model for adapting inpainting diffusion models to the salient object outpainting task using Stable Diffusion and ControlNet architectures. We present a series of qualitative and quantitative results across models and datasets, including a newly proposed metric to measure object expansion that does not require any human labeling. Compared to Stable Diffusion 2.0 Inpainting, our proposed approach reduces object expansion by 3.6x on average with no degradation in standard visual metrics across multiple datasets.
StegoGAN: Leveraging Steganography for Non-Bijective Image-to-Image Translation
Mar 29, 2024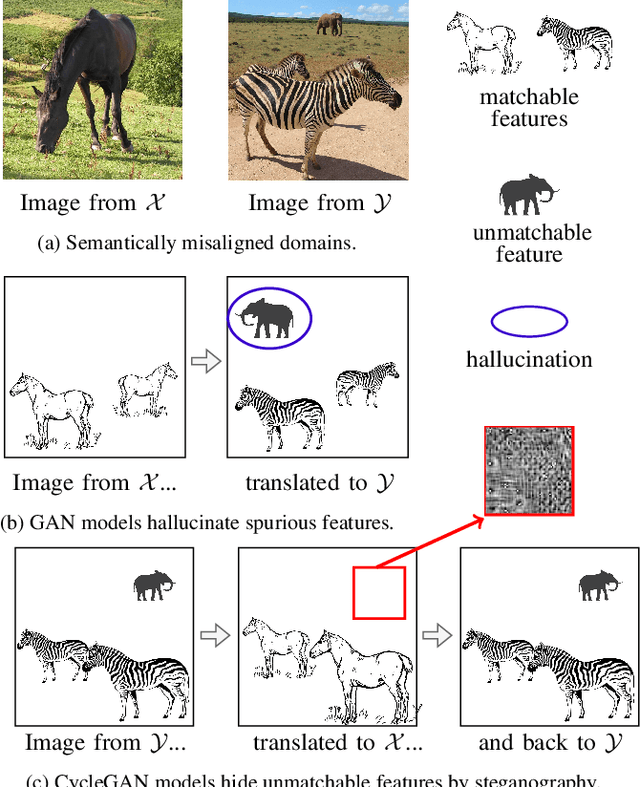
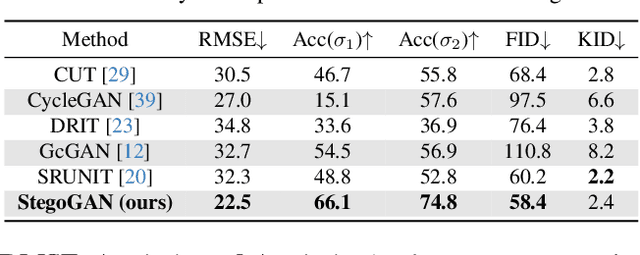
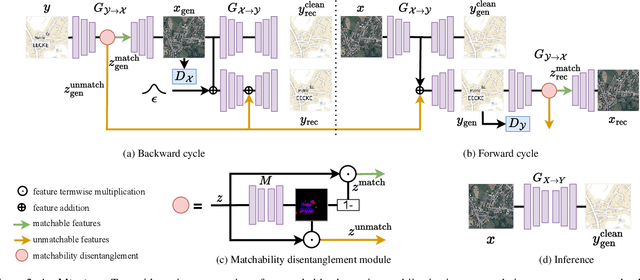
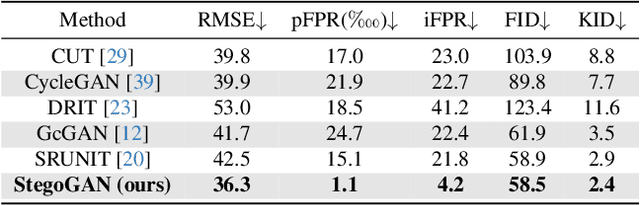
Most image-to-image translation models postulate that a unique correspondence exists between the semantic classes of the source and target domains. However, this assumption does not always hold in real-world scenarios due to divergent distributions, different class sets, and asymmetrical information representation. As conventional GANs attempt to generate images that match the distribution of the target domain, they may hallucinate spurious instances of classes absent from the source domain, thereby diminishing the usefulness and reliability of translated images. CycleGAN-based methods are also known to hide the mismatched information in the generated images to bypass cycle consistency objectives, a process known as steganography. In response to the challenge of non-bijective image translation, we introduce StegoGAN, a novel model that leverages steganography to prevent spurious features in generated images. Our approach enhances the semantic consistency of the translated images without requiring additional postprocessing or supervision. Our experimental evaluations demonstrate that StegoGAN outperforms existing GAN-based models across various non-bijective image-to-image translation tasks, both qualitatively and quantitatively. Our code and pretrained models are accessible at https://github.com/sian-wusidi/StegoGAN.
On the Scalability of Diffusion-based Text-to-Image Generation
Apr 03, 2024Scaling up model and data size has been quite successful for the evolution of LLMs. However, the scaling law for the diffusion based text-to-image (T2I) models is not fully explored. It is also unclear how to efficiently scale the model for better performance at reduced cost. The different training settings and expensive training cost make a fair model comparison extremely difficult. In this work, we empirically study the scaling properties of diffusion based T2I models by performing extensive and rigours ablations on scaling both denoising backbones and training set, including training scaled UNet and Transformer variants ranging from 0.4B to 4B parameters on datasets upto 600M images. For model scaling, we find the location and amount of cross attention distinguishes the performance of existing UNet designs. And increasing the transformer blocks is more parameter-efficient for improving text-image alignment than increasing channel numbers. We then identify an efficient UNet variant, which is 45% smaller and 28% faster than SDXL's UNet. On the data scaling side, we show the quality and diversity of the training set matters more than simply dataset size. Increasing caption density and diversity improves text-image alignment performance and the learning efficiency. Finally, we provide scaling functions to predict the text-image alignment performance as functions of the scale of model size, compute and dataset size.
Event Cameras Meet SPADs for High-Speed, Low-Bandwidth Imaging
Apr 17, 2024Traditional cameras face a trade-off between low-light performance and high-speed imaging: longer exposure times to capture sufficient light results in motion blur, whereas shorter exposures result in Poisson-corrupted noisy images. While burst photography techniques help mitigate this tradeoff, conventional cameras are fundamentally limited in their sensor noise characteristics. Event cameras and single-photon avalanche diode (SPAD) sensors have emerged as promising alternatives to conventional cameras due to their desirable properties. SPADs are capable of single-photon sensitivity with microsecond temporal resolution, and event cameras can measure brightness changes up to 1 MHz with low bandwidth requirements. We show that these properties are complementary, and can help achieve low-light, high-speed image reconstruction with low bandwidth requirements. We introduce a sensor fusion framework to combine SPADs with event cameras to improves the reconstruction of high-speed, low-light scenes while reducing the high bandwidth cost associated with using every SPAD frame. Our evaluation, on both synthetic and real sensor data, demonstrates significant enhancements ( > 5 dB PSNR) in reconstructing low-light scenes at high temporal resolution (100 kHz) compared to conventional cameras. Event-SPAD fusion shows great promise for real-world applications, such as robotics or medical imaging.
Digging into contrastive learning for robust depth estimation with diffusion models
Apr 17, 2024Recently, diffusion-based depth estimation methods have drawn widespread attention due to their elegant denoising patterns and promising performance. However, they are typically unreliable under adverse conditions prevalent in real-world scenarios, such as rainy, snowy, etc. In this paper, we propose a novel robust depth estimation method called D4RD, featuring a custom contrastive learning mode tailored for diffusion models to mitigate performance degradation in complex environments. Concretely, we integrate the strength of knowledge distillation into contrastive learning, building the `trinity' contrastive scheme. This scheme utilizes the sampled noise of the forward diffusion process as a natural reference, guiding the predicted noise in diverse scenes toward a more stable and precise optimum. Moreover, we extend noise-level trinity to encompass more generic feature and image levels, establishing a multi-level contrast to distribute the burden of robust perception across the overall network. Before addressing complex scenarios, we enhance the stability of the baseline diffusion model with three straightforward yet effective improvements, which facilitate convergence and remove depth outliers. Extensive experiments demonstrate that D4RD surpasses existing state-of-the-art solutions on synthetic corruption datasets and real-world weather conditions. The code for D4RD will be made available for further exploration and adoption.
EucliDreamer: Fast and High-Quality Texturing for 3D Models with Depth-Conditioned Stable Diffusion
Apr 16, 2024We present EucliDreamer, a simple and effective method to generate textures for 3D models given text prompts and meshes. The texture is parametrized as an implicit function on the 3D surface, which is optimized with the Score Distillation Sampling (SDS) process and differentiable rendering. To generate high-quality textures, we leverage a depth-conditioned Stable Diffusion model guided by the depth image rendered from the mesh. We test our approach on 3D models in Objaverse and conducted a user study, which shows its superior quality compared to existing texturing methods like Text2Tex. In addition, our method converges 2 times faster than DreamFusion. Through text prompting, textures of diverse art styles can be produced. We hope Euclidreamer proides a viable solution to automate a labor-intensive stage in 3D content creation.
On Speculative Decoding for Multimodal Large Language Models
Apr 13, 2024Inference with Multimodal Large Language Models (MLLMs) is slow due to their large-language-model backbone which suffers from memory bandwidth bottleneck and generates tokens auto-regressively. In this paper, we explore the application of speculative decoding to enhance the inference efficiency of MLLMs, specifically the LLaVA 7B model. We show that a language-only model can serve as a good draft model for speculative decoding with LLaVA 7B, bypassing the need for image tokens and their associated processing components from the draft model. Our experiments across three different tasks show that speculative decoding can achieve a memory-bound speedup of up to 2.37$\times$ using a 115M parameter language model that we trained from scratch. Additionally, we introduce a compact LLaVA draft model incorporating an image adapter, which shows marginal performance gains in image captioning while maintaining comparable results in other tasks.
Overcoming Scene Context Constraints for Object Detection in wild using Defilters
Apr 12, 2024This paper focuses on improving object detection performance by addressing the issue of image distortions, commonly encountered in uncontrolled acquisition environments. High-level computer vision tasks such as object detection, recognition, and segmentation are particularly sensitive to image distortion. To address this issue, we propose a novel approach employing an image defilter to rectify image distortion prior to object detection. This method enhances object detection accuracy, as models perform optimally when trained on non-distorted images. Our experiments demonstrate that utilizing defiltered images significantly improves mean average precision compared to training object detection models on distorted images. Consequently, our proposed method offers considerable benefits for real-world applications plagued by image distortion. To our knowledge, the contribution lies in employing distortion-removal paradigm for object detection on images captured in natural settings. We achieved an improvement of 0.562 and 0.564 of mean Average precision on validation and test data.
Evaluating Text-to-Image Synthesis: Survey and Taxonomy of Image Quality Metrics
Mar 29, 2024
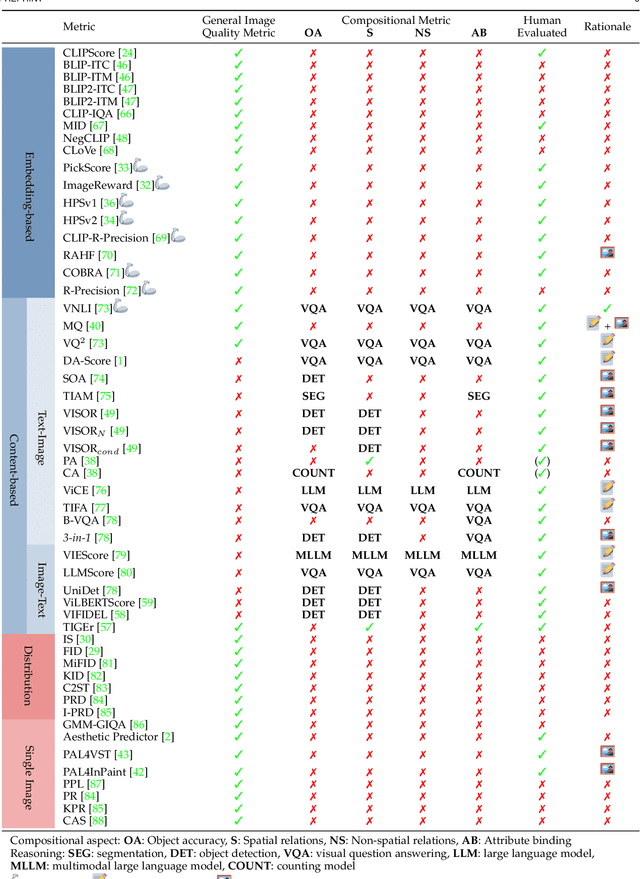
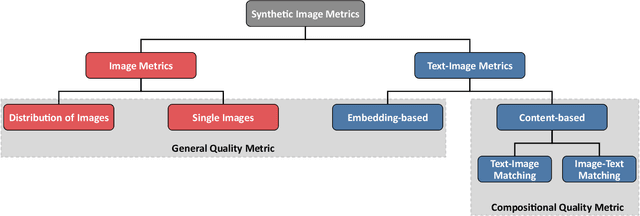
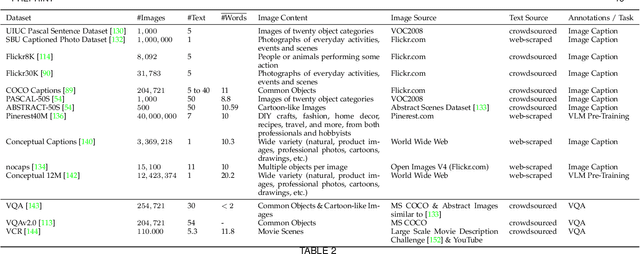
Recent advances in text-to-image synthesis enabled through a combination of language and vision foundation models have led to a proliferation of the tools available and an increased attention to the field. When conducting text-to-image synthesis, a central goal is to ensure that the content between text and image is aligned. As such, there exist numerous evaluation metrics that aim to mimic human judgement. However, it is often unclear which metric to use for evaluating text-to-image synthesis systems as their evaluation is highly nuanced. In this work, we provide a comprehensive overview of existing text-to-image evaluation metrics. Based on our findings, we propose a new taxonomy for categorizing these metrics. Our taxonomy is grounded in the assumption that there are two main quality criteria, namely compositionality and generality, which ideally map to human preferences. Ultimately, we derive guidelines for practitioners conducting text-to-image evaluation, discuss open challenges of evaluation mechanisms, and surface limitations of current metrics.