 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Kanerva++: extending The Kanerva Machine with differentiable, locally block allocated latent memory
Mar 16, 2021
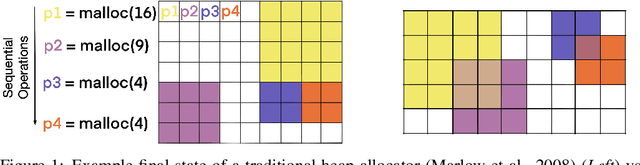
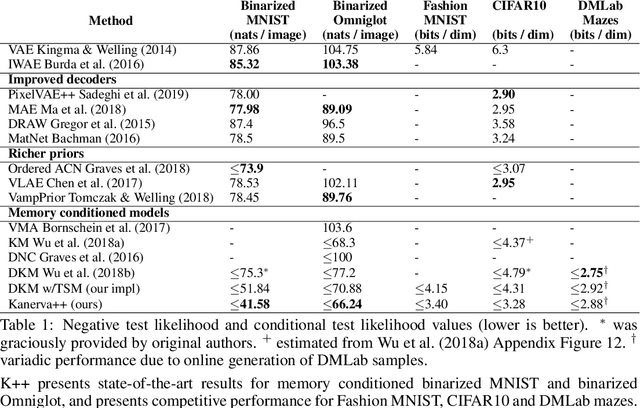
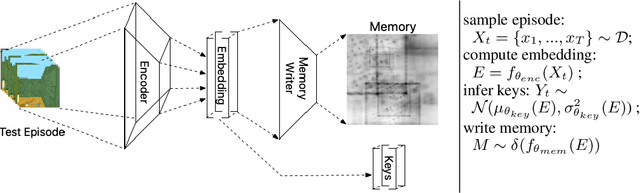
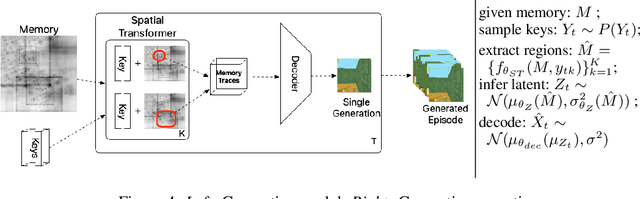
Episodic and semantic memory are critical components of the human memory model. The theory of complementary learning systems (McClelland et al., 1995) suggests that the compressed representation produced by a serial event (episodic memory) is later restructured to build a more generalized form of reusable knowledge (semantic memory). In this work we develop a new principled Bayesian memory allocation scheme that bridges the gap between episodic and semantic memory via a hierarchical latent variable model. We take inspiration from traditional heap allocation and extend the idea of locally contiguous memory to the Kanerva Machine, enabling a novel differentiable block allocated latent memory. In contrast to the Kanerva Machine, we simplify the process of memory writing by treating it as a fully feed forward deterministic process, relying on the stochasticity of the read key distribution to disperse information within the memory. We demonstrate that this allocation scheme improves performance in memory conditional image generation, resulting in new state-of-the-art conditional likelihood values on binarized MNIST (<=41.58 nats/image) , binarized Omniglot (<=66.24 nats/image), as well as presenting competitive performance on CIFAR10, DMLab Mazes, Celeb-A and ImageNet32x32.
AGD-Autoencoder: Attention Gated Deep Convolutional Autoencoder for Brain Tumor Segmentation
Jul 07, 2021Brain tumor segmentation is a challenging problem in medical image analysis. The endpoint is to generate the salient masks that accurately identify brain tumor regions in an fMRI screening. In this paper, we propose a novel attention gate (AG model) for brain tumor segmentation that utilizes both the edge detecting unit and the attention gated network to highlight and segment the salient regions from fMRI images. This feature enables us to eliminate the necessity of having to explicitly point towards the damaged area(external tissue localization) and classify(classification) as per classical computer vision techniques. AGs can easily be integrated within the deep convolutional neural networks(CNNs). Minimal computional overhead is required while the AGs increase the sensitivity scores significantly. We show that the edge detector along with an attention gated mechanism provide a sufficient enough method for brain segmentation reaching an IOU of 0.78
System Matrix based Reconstruction for Pulsed Sequences in Magnetic Particle Imaging
Aug 23, 2021
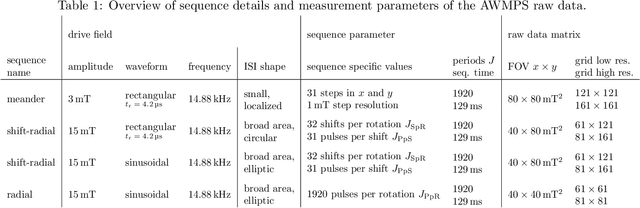
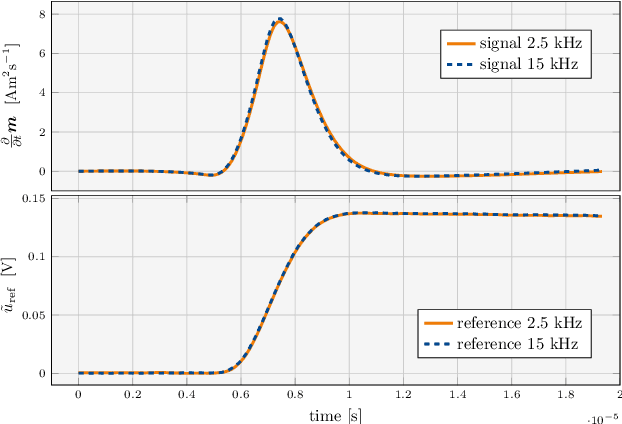
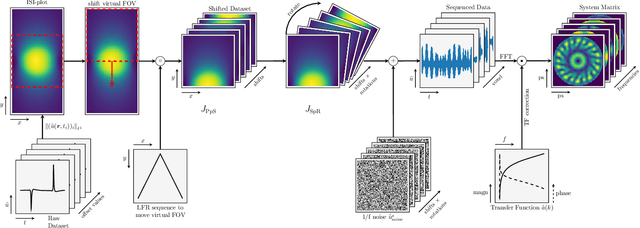
Improving resolution and sensitivity will widen possible medical applications of magnetic particle imaging in its clinical application. Pulsed excitation promises such benefits, at the cost of more complex hardware solutions and restrictions on drive field amplitude and frequency. In this work, a sequence is proposed, that combines high drive-field amplitudes and high frequency rectangular excitation. State of the art systems utilize a sinusoidal excitation to drive superparamagnetic nanoparticles into the non-linear part of their magnetization curve, which creates a spectrum with a clear separation of direct feed-through and higher harmonics caused by the particles response. One challenge for rectangular excitation is the discrimination of particle and excitation signals, both broad-band. Another is the drive-field sequence itself, as particles that are not placed at the same spatial position, may react simultaneously and are not separable by their signals phase or signal shape. This loss of information in spatial encoding is overcome in this work by utilizing a superposition of shifting fields and drive-field rotations. The software framework developed for this work processes measured data from an Arbitrary Waveform Magnetic Particle Spectrometer, which is calibrated to guarantee device independence. Multiple sequence types and waveforms are compared, based on frequency space image reconstruction from emulated signals, that are derived from these measured particle responses. A resolution of 1.0 mT (0.8 mm for a gradient of (-1.25,-1.25,2.5) T/m) in x- and y-direction was achieved and a superior sensitivity was detected on the basis of reference phantoms for the proposed sequence in this work.
Evaluation of Retinal Image Quality Assessment Networks in Different Color-spaces
Jul 18, 2019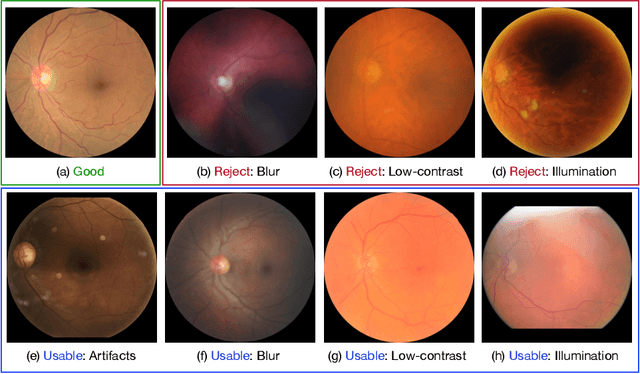
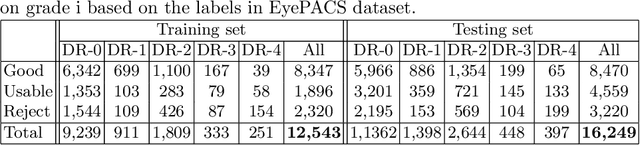
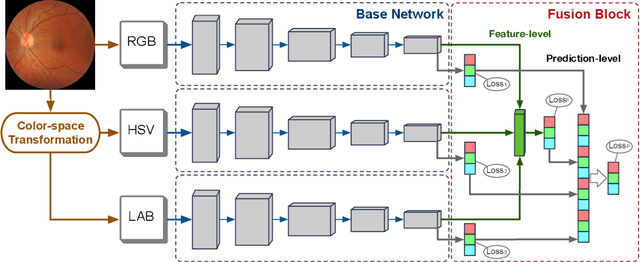
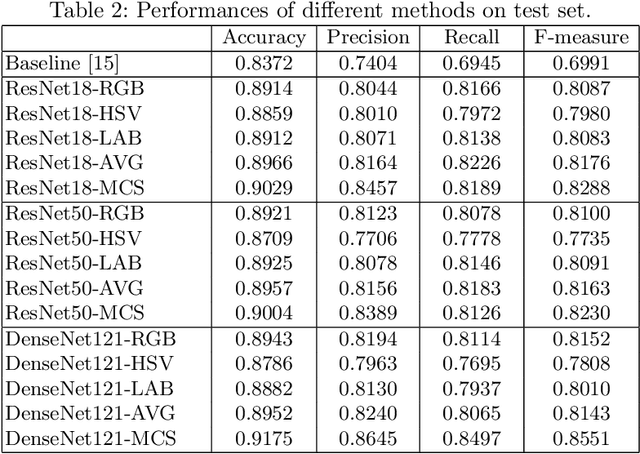
Retinal image quality assessment (RIQA) is essential for controlling the quality of retinal imaging and guaranteeing the reliability of diagnoses by ophthalmologists or automated analysis systems. Existing RIQA methods focus on the RGB color-space and are developed based on small datasets with binary quality labels (i.e., `Accept' and `Reject'). In this paper, we first re-annotate an Eye-Quality (EyeQ) dataset with 28,792 retinal images from the EyePACS dataset, based on a three-level quality grading system (i.e., `Good', `Usable' and `Reject') for evaluating RIQA methods. Our RIQA dataset is characterized by its large-scale size, multi-level grading, and multi-modality. Then, we analyze the influences on RIQA of different color-spaces, and propose a simple yet efficient deep network, named Multiple Color-space Fusion Network (MCF-Net), which integrates the different color-space representations at both a feature-level and prediction-level to predict image quality grades. Experiments on our EyeQ dataset show that our MCF-Net obtains a state-of-the-art performance, outperforming the other deep learning methods. Furthermore, we also evaluate diabetic retinopathy (DR) detection methods on images of different quality, and demonstrate that the performances of automated diagnostic systems are highly dependent on image quality.
Improving Global Adversarial Robustness Generalization With Adversarially Trained GAN
Mar 08, 2021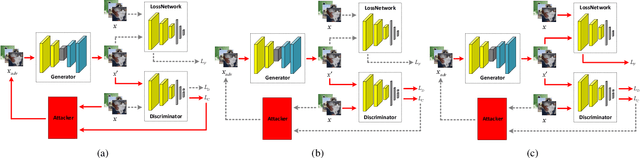
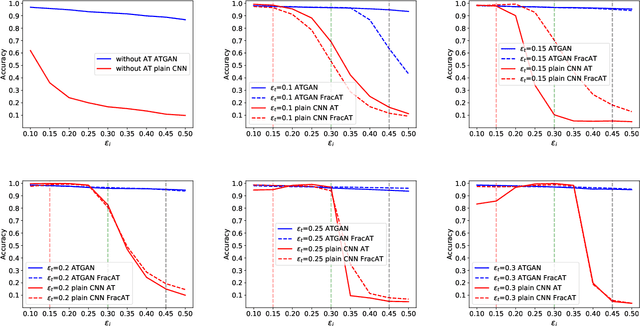

Convolutional neural networks (CNNs) have achieved beyond human-level accuracy in the image classification task and are widely deployed in real-world environments. However, CNNs show vulnerability to adversarial perturbations that are well-designed noises aiming to mislead the classification models. In order to defend against the adversarial perturbations, adversarially trained GAN (ATGAN) is proposed to improve the adversarial robustness generalization of the state-of-the-art CNNs trained by adversarial training. ATGAN incorporates adversarial training into standard GAN training procedure to remove obfuscated gradients which can lead to a false sense in defending against the adversarial perturbations and are commonly observed in existing GANs-based adversarial defense methods. Moreover, ATGAN adopts the image-to-image generator as data augmentation to increase the sample complexity needed for adversarial robustness generalization in adversarial training. Experimental results in MNIST SVHN and CIFAR-10 datasets show that the proposed method doesn't rely on obfuscated gradients and achieves better global adversarial robustness generalization performance than the adversarially trained state-of-the-art CNNs.
Fuzziness-based Spatial-Spectral Class Discriminant Information Preserving Active Learning for Hyperspectral Image Classification
May 28, 2020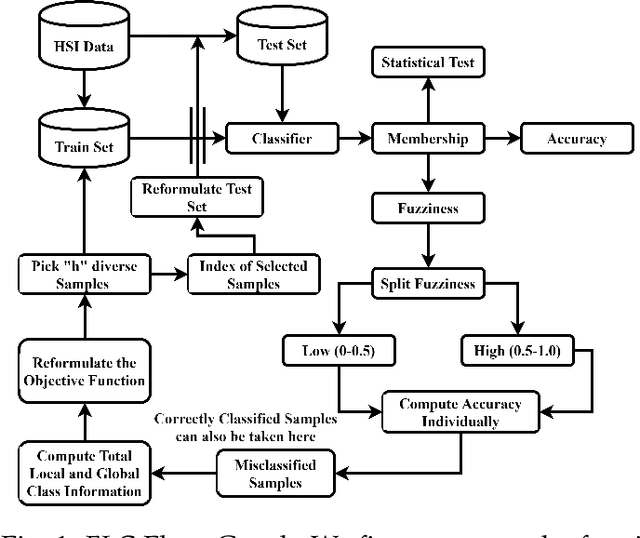
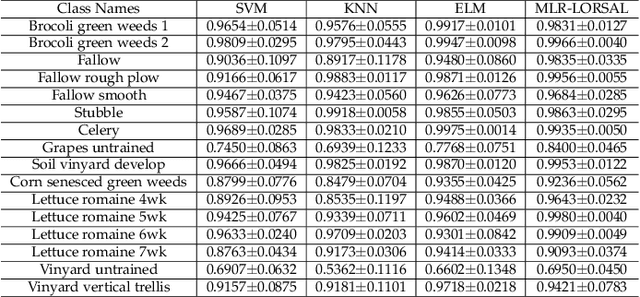
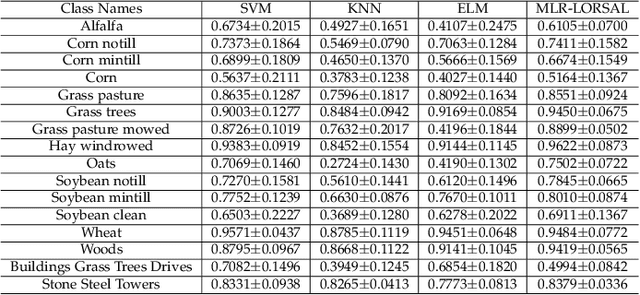
Traditional Active/Self/Interactive Learning for Hyperspectral Image Classification (HSIC) increases the size of the training set without considering the class scatters and randomness among the existing and new samples. Second, very limited research has been carried out on joint spectral-spatial information and finally, a minor but still worth mentioning is the stopping criteria which not being much considered by the community. Therefore, this work proposes a novel fuzziness-based spatial-spectral within and between for both local and global class discriminant information preserving (FLG) method. We first investigate a spatial prior fuzziness-based misclassified sample information. We then compute the total local and global for both within and between class information and formulate it in a fine-grained manner. Later this information is fed to a discriminative objective function to query the heterogeneous samples which eliminate the randomness among the training samples. Experimental results on benchmark HSI datasets demonstrate the effectiveness of the FLG method on Generative, Extreme Learning Machine and Sparse Multinomial Logistic Regression (SMLR)-LORSAL classifiers.
AdaAttN: Revisit Attention Mechanism in Arbitrary Neural Style Transfer
Aug 11, 2021
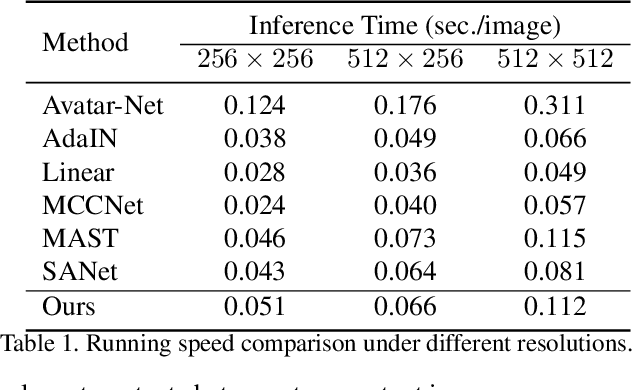
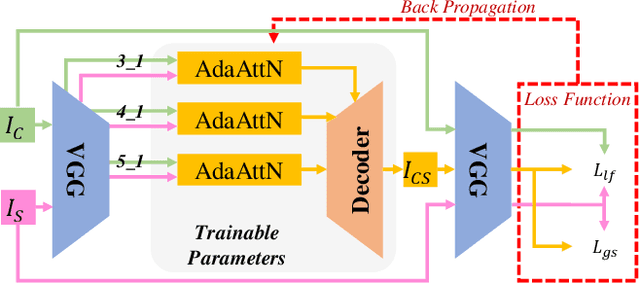

Fast arbitrary neural style transfer has attracted widespread attention from academic, industrial and art communities due to its flexibility in enabling various applications. Existing solutions either attentively fuse deep style feature into deep content feature without considering feature distributions, or adaptively normalize deep content feature according to the style such that their global statistics are matched. Although effective, leaving shallow feature unexplored and without locally considering feature statistics, they are prone to unnatural output with unpleasing local distortions. To alleviate this problem, in this paper, we propose a novel attention and normalization module, named Adaptive Attention Normalization (AdaAttN), to adaptively perform attentive normalization on per-point basis. Specifically, spatial attention score is learnt from both shallow and deep features of content and style images. Then per-point weighted statistics are calculated by regarding a style feature point as a distribution of attention-weighted output of all style feature points. Finally, the content feature is normalized so that they demonstrate the same local feature statistics as the calculated per-point weighted style feature statistics. Besides, a novel local feature loss is derived based on AdaAttN to enhance local visual quality. We also extend AdaAttN to be ready for video style transfer with slight modifications. Experiments demonstrate that our method achieves state-of-the-art arbitrary image/video style transfer. Codes and models are available.
Interactive Binary Image Segmentation with Edge Preservation
Sep 10, 2018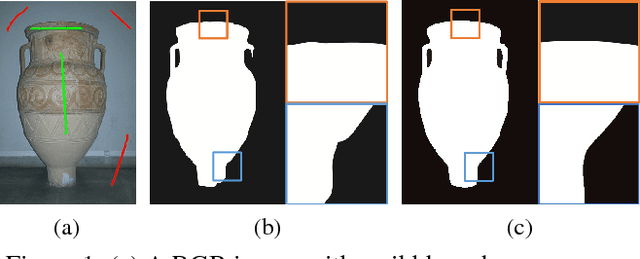
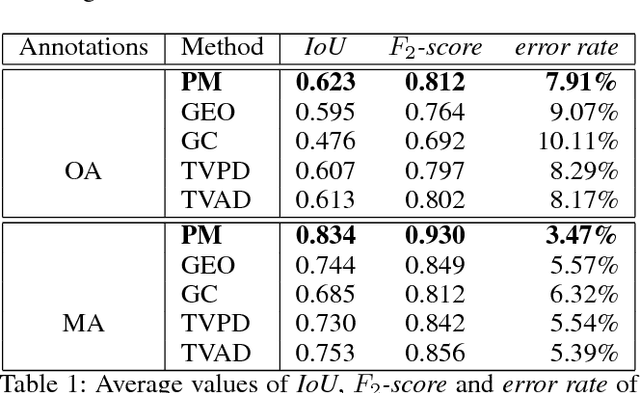

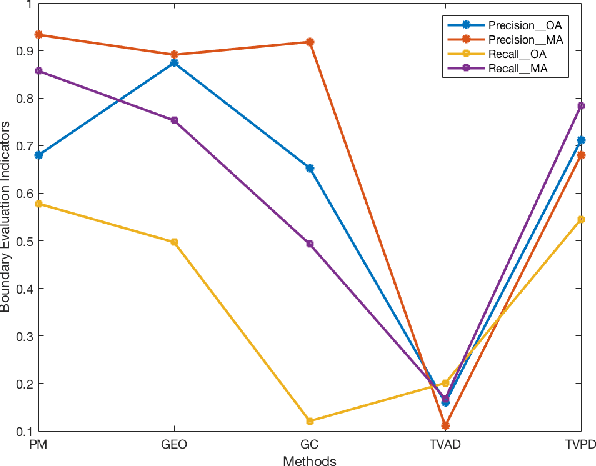
Binary image segmentation plays an important role in computer vision and has been widely used in many applications such as image and video editing, object extraction, and photo composition. In this paper, we propose a novel interactive binary image segmentation method based on the Markov Random Field (MRF) framework and the fast bilateral solver (FBS) technique. Specifically, we employ the geodesic distance component to build the unary term. To ensure both computation efficiency and effective responsiveness for interactive segmentation, superpixels are used in computing geodesic distances instead of pixels. Furthermore, we take a bilateral affinity approach for the pairwise term in order to preserve edge information and denoise. Through the alternating direction strategy, the MRF energy minimization problem is divided into two subproblems, which then can be easily solved by steepest gradient descent (SGD) and FBS respectively. Experimental results on the VGG interactive image segmentation dataset show that the proposed algorithm outperforms several state-of-the-art ones, and in particular, it can achieve satisfactory edge-smooth segmentation results even when the foreground and background color appearances are quite indistinctive.
A Deep Learning Framework for Unsupervised Affine and Deformable Image Registration
Sep 17, 2018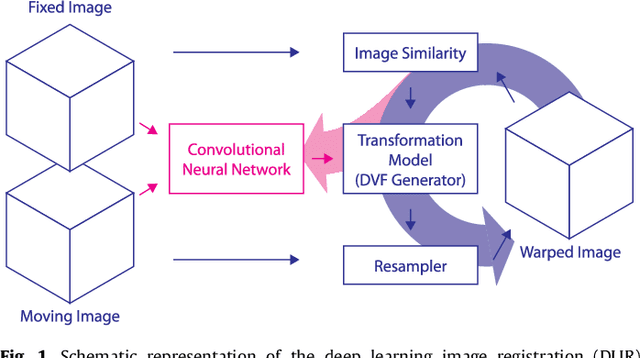
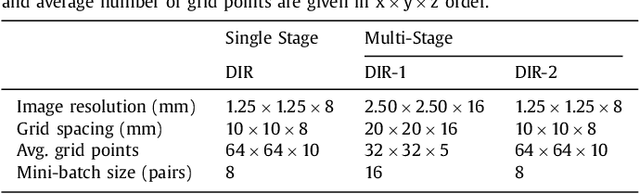
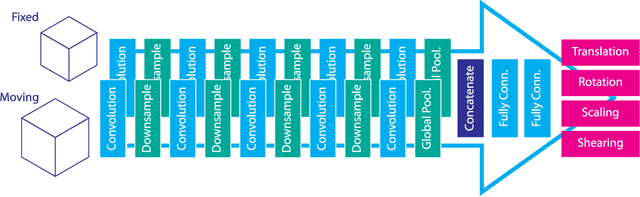
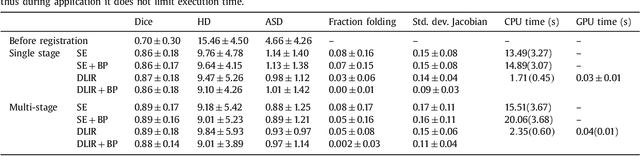
Image registration, the process of aligning two or more images, is the core technique of many (semi-)automatic medical image analysis tasks. Recent studies have shown that deep learning methods, notably convolutional neural networks (ConvNets), can be used for image registration. Thus far training of ConvNets for registration was supervised using predefined example registrations. However, obtaining example registrations is not trivial. To circumvent the need for predefined examples, and thereby to increase convenience of training ConvNets for image registration, we propose the Deep Learning Image Registration (DLIR) framework for \textit{unsupervised} affine and deformable image registration. In the DLIR framework ConvNets are trained for image registration by exploiting image similarity analogous to conventional intensity-based image registration. After a ConvNet has been trained with the DLIR framework, it can be used to register pairs of unseen images in one shot. We propose flexible ConvNets designs for affine image registration and for deformable image registration. By stacking multiple of these ConvNets into a larger architecture, we are able to perform coarse-to-fine image registration. We show for registration of cardiac cine MRI and registration of chest CT that performance of the DLIR framework is comparable to conventional image registration while being several orders of magnitude faster.
Scaling Laws for Deep Learning
Aug 17, 2021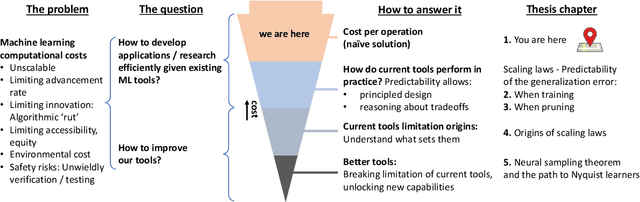
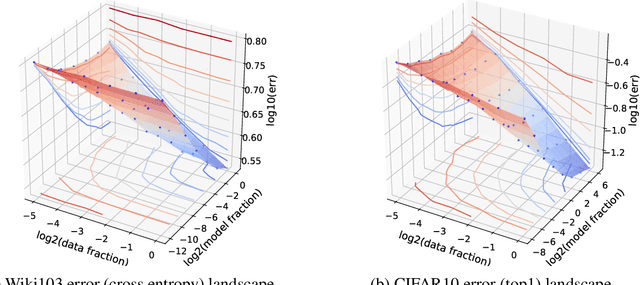
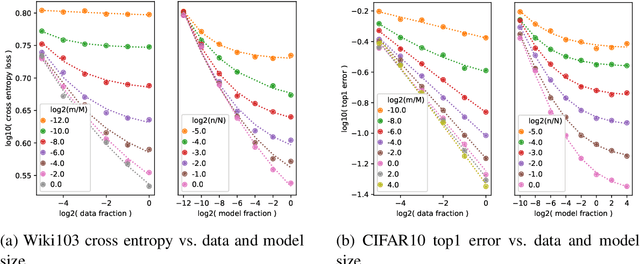
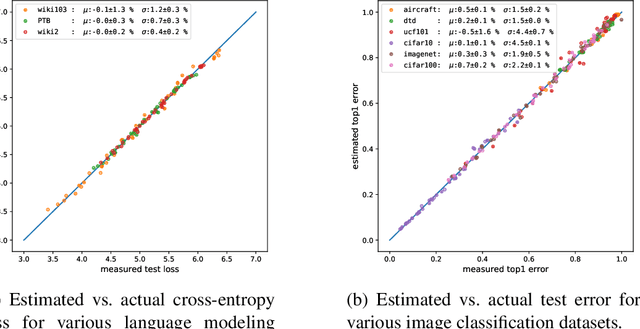
Running faster will only get you so far -- it is generally advisable to first understand where the roads lead, then get a car ... The renaissance of machine learning (ML) and deep learning (DL) over the last decade is accompanied by an unscalable computational cost, limiting its advancement and weighing on the field in practice. In this thesis we take a systematic approach to address the algorithmic and methodological limitations at the root of these costs. We first demonstrate that DL training and pruning are predictable and governed by scaling laws -- for state of the art models and tasks, spanning image classification and language modeling, as well as for state of the art model compression via iterative pruning. Predictability, via the establishment of these scaling laws, provides the path for principled design and trade-off reasoning, currently largely lacking in the field. We then continue to analyze the sources of the scaling laws, offering an approximation-theoretic view and showing through the exploration of a noiseless realizable case that DL is in fact dominated by error sources very far from the lower error limit. We conclude by building on the gained theoretical understanding of the scaling laws' origins. We present a conjectural path to eliminate one of the current dominant error sources -- through a data bandwidth limiting hypothesis and the introduction of Nyquist learners -- which can, in principle, reach the generalization error lower limit (e.g. 0 in the noiseless case), at finite dataset size.