 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Event Recognition with Automatic Album Detection based on Sequential Processing, Neural Attention and Image Captioning
Jan 15, 2020
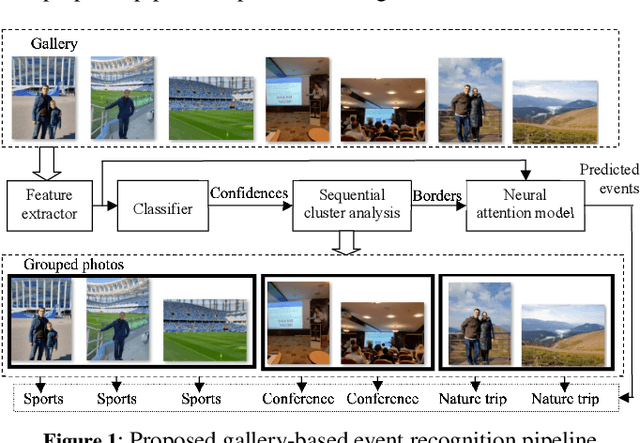
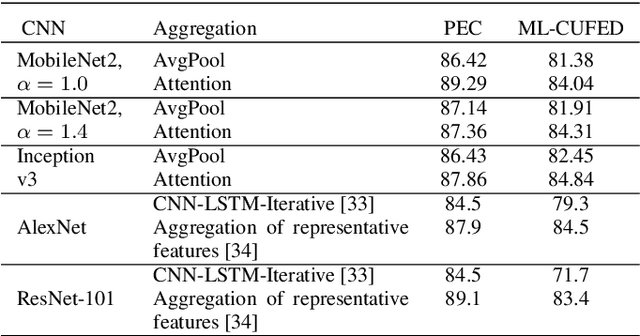
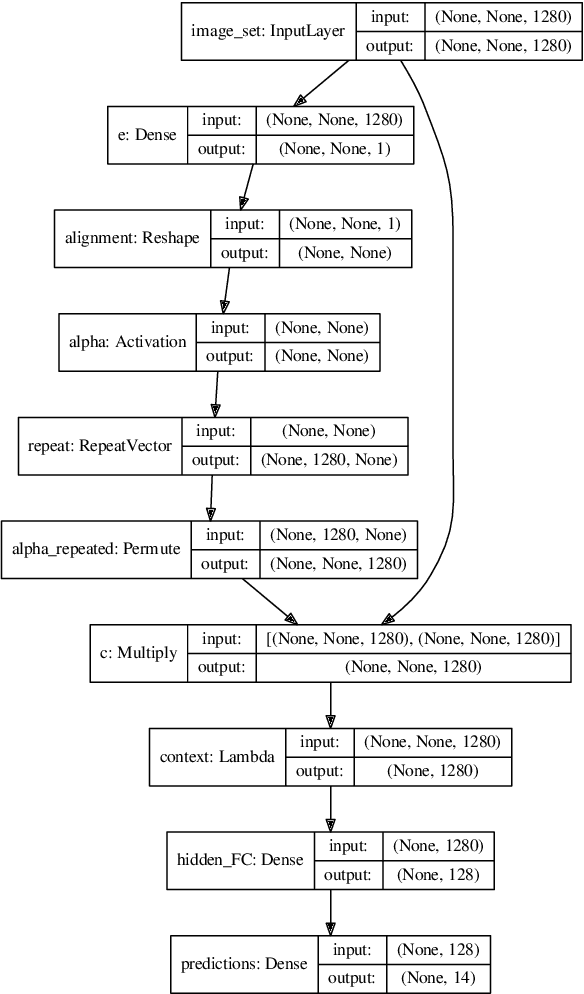
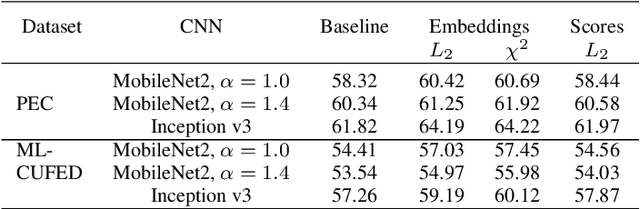
In this paper a new formulation of event recognition task is examined: it is required to predict event categories in a gallery of images, for which albums (groups of photos corresponding to a single event) are unknown. We propose the novel two-stage approach. At first, features are extracted in each photo using the pre-trained convolutional neural network. These features are classified individually. The scores of the classifier are used to group sequential photos into several clusters. Finally, the features of photos in each group are aggregated into a single descriptor using neural attention mechanism. This algorithm is optionally extended to improve the accuracy for classification of each image in an album. In contrast to conventional fine-tuning of convolutional neural networks (CNN) we proposed to use image captioning, i.e., generative model that converts images to textual descriptions. They are one-hot encoded and summarized into sparse feature vector suitable for learning of arbitrary classifier. Experimental study with Photo Event Collection and Multi-Label Curation of Flickr Events Dataset demonstrates that our approach is 9-20% more accurate than event recognition on single photos. Moreover, proposed method has 13-16% lower error rate than classification of groups of photos obtained with hierarchical clustering. It is experimentally shown that the image captions trained on Conceptual Captions dataset can be classified more accurately than the features from object detector, though they both are obviously not as rich as the CNN-based features. However, it is possible to combine our approach with conventional CNNs in an ensemble to provide the state-of-the-art results for several event datasets.
Paint Transformer: Feed Forward Neural Painting with Stroke Prediction
Aug 11, 2021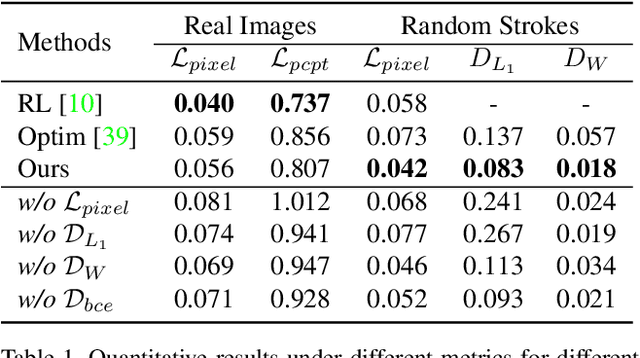
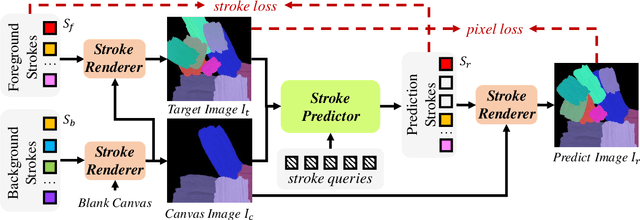
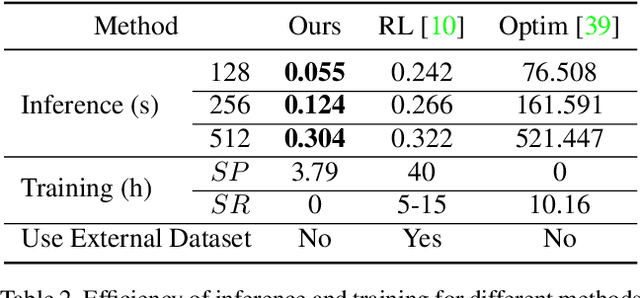
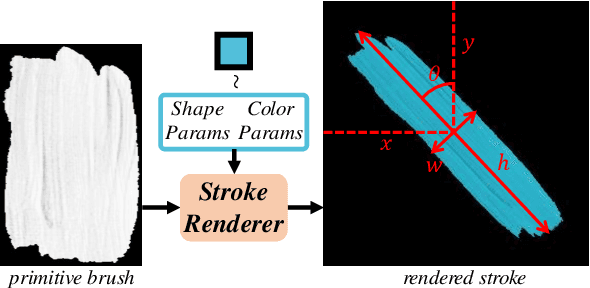
Neural painting refers to the procedure of producing a series of strokes for a given image and non-photo-realistically recreating it using neural networks. While reinforcement learning (RL) based agents can generate a stroke sequence step by step for this task, it is not easy to train a stable RL agent. On the other hand, stroke optimization methods search for a set of stroke parameters iteratively in a large search space; such low efficiency significantly limits their prevalence and practicality. Different from previous methods, in this paper, we formulate the task as a set prediction problem and propose a novel Transformer-based framework, dubbed Paint Transformer, to predict the parameters of a stroke set with a feed forward network. This way, our model can generate a set of strokes in parallel and obtain the final painting of size 512 * 512 in near real time. More importantly, since there is no dataset available for training the Paint Transformer, we devise a self-training pipeline such that it can be trained without any off-the-shelf dataset while still achieving excellent generalization capability. Experiments demonstrate that our method achieves better painting performance than previous ones with cheaper training and inference costs. Codes and models are available.
Multi-scale Dynamic Graph Convolutional Network for Hyperspectral Image Classification
May 14, 2019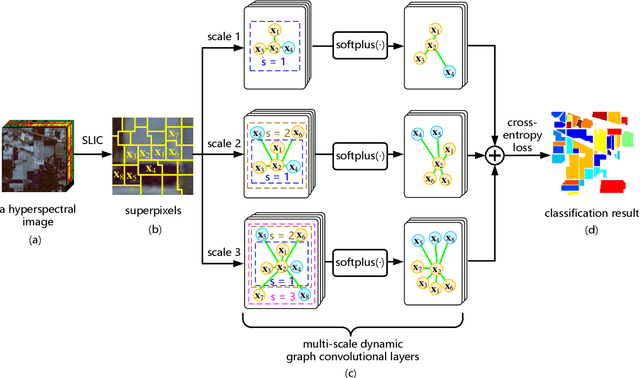
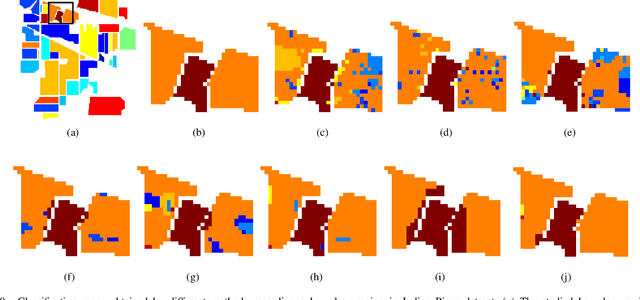
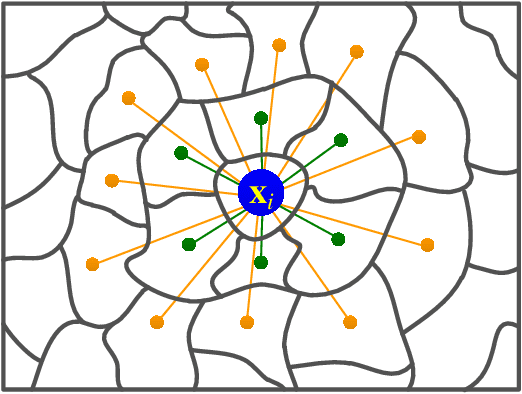
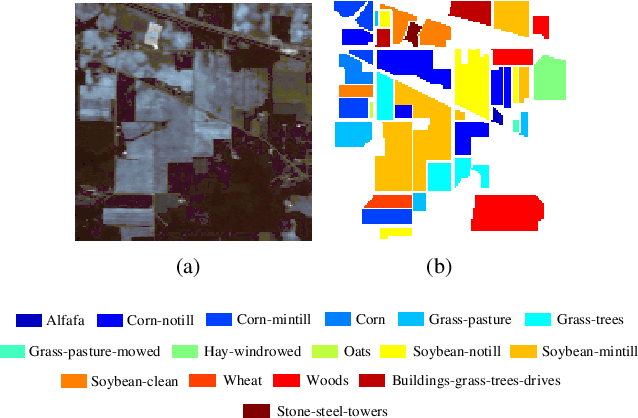
Convolutional Neural Network (CNN) has demonstrated impressive ability to represent hyperspectral images and to achieve promising results in hyperspectral image classification. However, traditional CNN models can only operate convolution on regular square image regions with fixed size and weights, so they cannot universally adapt to the distinct local regions with various object distributions and geometric appearances. Therefore, their classification performances are still to be improved, especially in class boundaries. To alleviate this shortcoming, we consider employing the recently proposed Graph Convolutional Network (GCN) for hyperspectral image classification, as it can conduct the convolution on arbitrarily structured non-Euclidean data and is applicable to the irregular image regions represented by graph topological information. Different from the commonly used GCN models which work on a fixed graph, we enable the graph to be dynamically updated along with the graph convolution process, so that these two steps can be benefited from each other to gradually produce the discriminative embedded features as well as a refined graph. Moreover, to comprehensively deploy the multi-scale information inherited by hyperspectral images, we establish multiple input graphs with different neighborhood scales to extensively exploit the diversified spectral-spatial correlations at multiple scales. Therefore, our method is termed 'Multi-scale Dynamic Graph Convolutional Network' (MDGCN). The experimental results on three typical benchmark datasets firmly demonstrate the superiority of the proposed MDGCN to other state-of-the-art methods in both qualitative and quantitative aspects.
Catching Out-of-Context Misinformation with Self-supervised Learning
Jan 27, 2021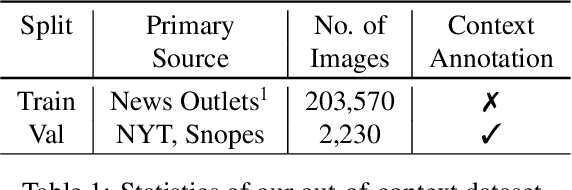

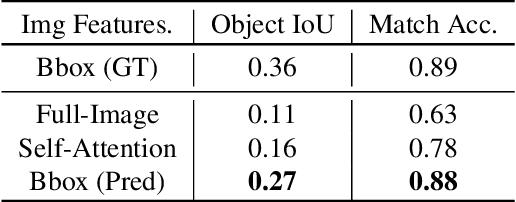
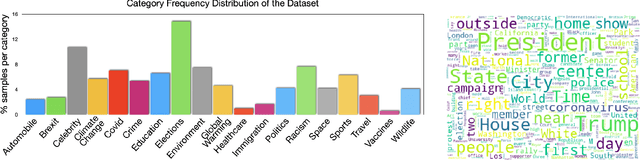
Despite the recent attention to DeepFakes and other forms of image manipulations, one of the most prevalent ways to mislead audiences is the use of unaltered images in a new but false context. To address these challenges and support fact-checkers, we propose a new method that automatically detects out-of-context image and text pairs. Our core idea is a self-supervised training strategy where we only need images with matching (and non-matching) captions from different sources. At train time, our method learns to selectively align individual objects in an image with textual claims, without explicit supervision. At test time, we check for a given text pair if both texts correspond to same object(s) in the image but semantically convey different descriptions, which allows us to make fairly accurate out-of-context predictions. Our method achieves 82% out-of-context detection accuracy. To facilitate training our method, we created a large-scale dataset of 200K images which we match with 450K textual captions from a variety of news websites, blogs, and social media posts; i.e., for each image, we obtained several captions.
Recursive Chaining of Reversible Image-to-image Translators For Face Aging
Aug 06, 2018

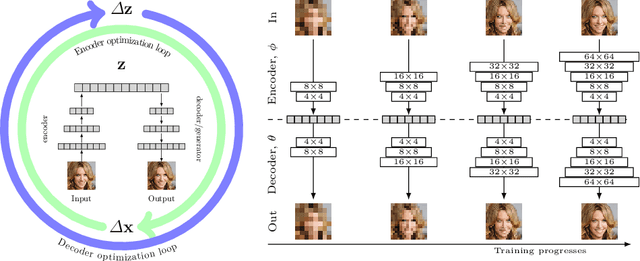

This paper addresses the modeling and simulation of progressive changes over time, such as human face aging. By treating the age phases as a sequence of image domains, we construct a chain of transformers that map images from one age domain to the next. Leveraging recent adversarial image translation methods, our approach requires no training samples of the same individual at different ages. Here, the model must be flexible enough to translate a child face to a young adult, and all the way through the adulthood to old age. We find that some transformers in the chain can be recursively applied on their own output to cover multiple phases, compressing the chain. The structure of the chain also unearths information about the underlying physical process. We demonstrate the performance of our method with precise and intuitive metrics, and visually match with the face aging state-of-the-art.
Patient-specific Conditional Joint Models of Shape, Image Features and Clinical Indicators
Jul 17, 2019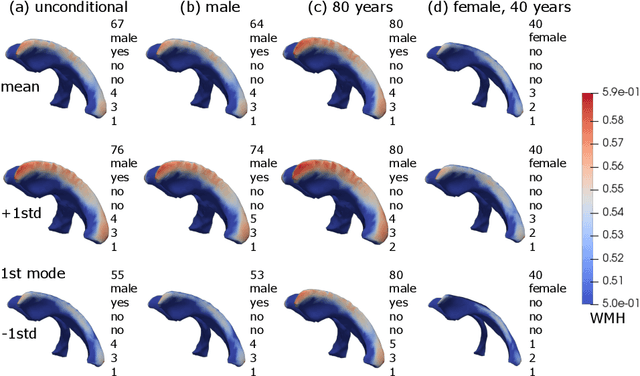


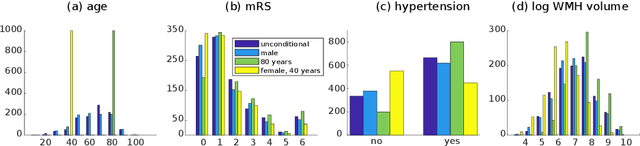
We propose and demonstrate a joint model of anatomical shapes, image features and clinical indicators for statistical shape modeling and medical image analysis. The key idea is to employ a copula model to separate the joint dependency structure from the marginal distributions of variables of interest. This separation provides flexibility on the assumptions made during the modeling process. The proposed method can handle binary, discrete, ordinal and continuous variables. We demonstrate a simple and efficient way to include binary, discrete and ordinal variables into the modeling. We build Bayesian conditional models based on observed partial clinical indicators, features or shape based on Gaussian processes capturing the dependency structure. We apply the proposed method on a stroke dataset to jointly model the shape of the lateral ventricles, the spatial distribution of the white matter hyperintensity associated with periventricular white matter disease, and clinical indicators. The proposed method yields interpretable joint models for data exploration and patient-specific statistical shape models for medical image analysis.
* Supplementary material: https://www.youtube.com/watch?v=gPoHP_iFQIA
Generative Art Using Neural Visual Grammars and Dual Encoders
May 04, 2021


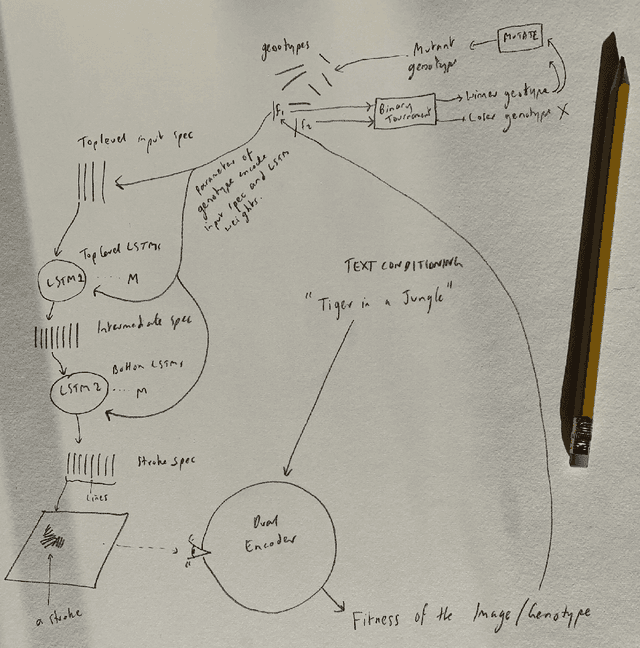
Whilst there are perhaps only a few scientific methods, there seem to be almost as many artistic methods as there are artists. Artistic processes appear to inhabit the highest order of open-endedness. To begin to understand some of the processes of art making it is helpful to try to automate them even partially. In this paper, a novel algorithm for producing generative art is described which allows a user to input a text string, and which in a creative response to this string, outputs an image which interprets that string. It does so by evolving images using a hierarchical neural Lindenmeyer system, and evaluating these images along the way using an image text dual encoder trained on billions of images and their associated text from the internet. In doing so we have access to and control over an instance of an artistic process, allowing analysis of which aspects of the artistic process become the task of the algorithm, and which elements remain the responsibility of the artist.
Refer-it-in-RGBD: A Bottom-up Approach for 3D Visual Grounding in RGBD Images
Mar 16, 2021

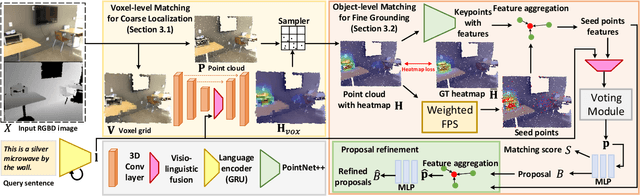
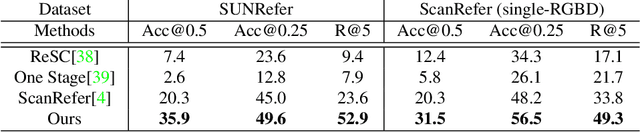
Grounding referring expressions in RGBD image has been an emerging field. We present a novel task of 3D visual grounding in single-view RGBD image where the referred objects are often only partially scanned due to occlusion. In contrast to previous works that directly generate object proposals for grounding in the 3D scenes, we propose a bottom-up approach to gradually aggregate context-aware information, effectively addressing the challenge posed by the partial geometry. Our approach first fuses the language and the visual features at the bottom level to generate a heatmap that coarsely localizes the relevant regions in the RGBD image. Then our approach conducts an adaptive feature learning based on the heatmap and performs the object-level matching with another visio-linguistic fusion to finally ground the referred object. We evaluate the proposed method by comparing to the state-of-the-art methods on both the RGBD images extracted from the ScanRefer dataset and our newly collected SUNRefer dataset. Experiments show that our method outperforms the previous methods by a large margin (by 11.2% and 15.6% Acc@0.5) on both datasets.
Duplex Contextual Relation Network for Polyp Segmentation
Mar 11, 2021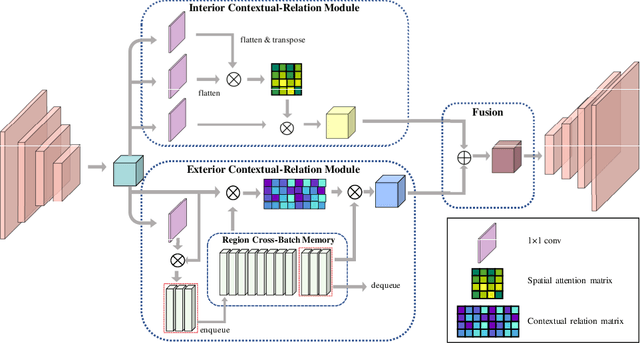
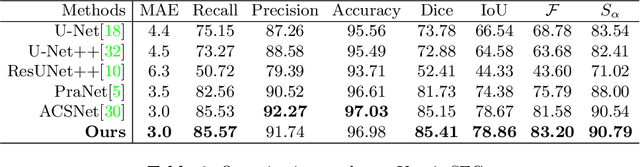
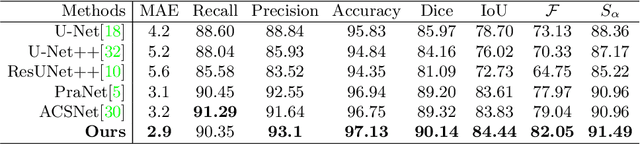
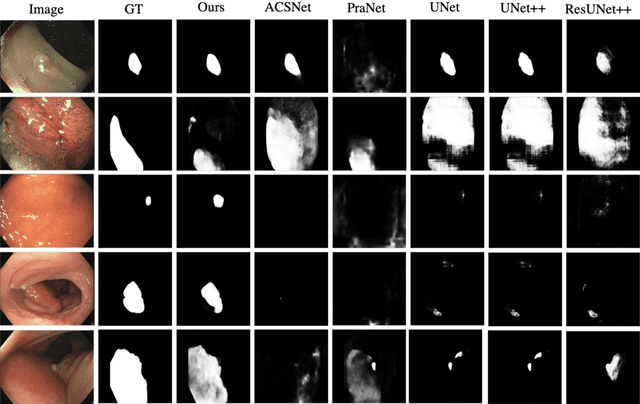
Polyp segmentation is of great importance in the early diagnosis and treatment of colorectal cancer. Since polyps vary in their shape, size, color, and texture, accurate polyp segmentation is very challenging. One promising way to mitigate the diversity of polyps is to model the contextual relation for each pixel such as using attention mechanism. However, previous methods only focus on learning the dependencies between the position within an individual image and ignore the contextual relation across different images. In this paper, we propose Duplex Contextual Relation Network (DCRNet) to capture both within-image and cross-image contextual relations. Specifically, we first design Interior Contextual-Relation Module to estimate the similarity between each position and all the positions within the same image. Then Exterior Contextual-Relation Module is incorporated to estimate the similarity between each position and the positions across different images. Based on the above two types of similarity, the feature at one position can be further enhanced by the contextual region embedding within and across images. To store the characteristic region embedding from all the images, a memory bank is designed and operates as a queue. Therefore, the proposed method can relate similar features even though they come from different images. We evaluate the proposed method on the EndoScene, Kvasir-SEG and the recently released large-scale PICCOLO dataset. Experimental results show that the proposed DCRNet outperforms the state-of-the-art methods in terms of the widely-used evaluation metrics.
OSSR-PID: One-Shot Symbol Recognition in P&ID Sheets using Path Sampling and GCN
Sep 08, 2021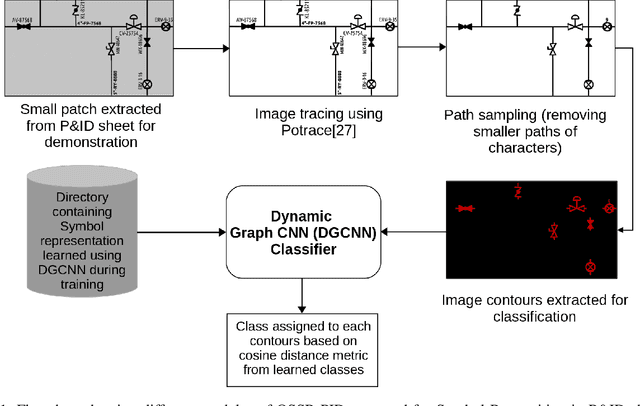
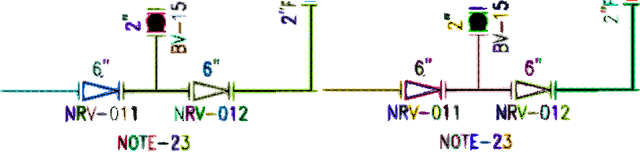

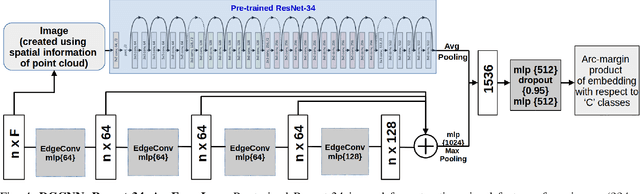
Piping and Instrumentation Diagrams (P&ID) are ubiquitous in several manufacturing, oil and gas enterprises for representing engineering schematics and equipment layout. There is an urgent need to extract and digitize information from P&IDs without the cost of annotating a varying set of symbols for each new use case. A robust one-shot learning approach for symbol recognition i.e., localization followed by classification, would therefore go a long way towards this goal. Our method works by sampling pixels sequentially along the different contour boundaries in the image. These sampled points form paths which are used in the prototypical line diagram to construct a graph that captures the structure of the contours. Subsequently, the prototypical graphs are fed into a Dynamic Graph Convolutional Neural Network (DGCNN) which is trained to classify graphs into one of the given symbol classes. Further, we append embeddings from a Resnet-34 network which is trained on symbol images containing sampled points to make the classification network more robust. Since, many symbols in P&ID are structurally very similar to each other, we utilize Arcface loss during DGCNN training which helps in maximizing symbol class separability by producing highly discriminative embeddings. The images consist of components attached on the pipeline (straight line). The sampled points segregated around the symbol regions are used for the classification task. The proposed pipeline, named OSSR-PID, is fast and gives outstanding performance for recognition of symbols on a synthetic dataset of 100 P&ID diagrams. We also compare our method against prior-work on a real-world private dataset of 12 P&ID sheets and obtain comparable/superior results. Remarkably, it is able to achieve such excellent performance using only one prototypical example per symbol.