 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHSEmotion Team at ABAW-10 Competition: Facial Expression Recognition, Valence-Arousal Estimation, Action Unit Detection and Fine-Grained Violence Classification
Mar 13, 2026This article presents our results for the 10th Affective Behavior Analysis in-the-Wild (ABAW) competition. For frame-wise facial emotion understanding tasks (frame-wise facial expression recognition, valence-arousal estimation, action unit detection), we propose a fast approach based on facial embedding extraction with pre-trained EfficientNet-based emotion recognition models. If the latter model's confidence exceeds a threshold, its prediction is used. Otherwise, we feed embeddings into a simple multi-layered perceptron trained on the AffWild2 dataset. Estimated class-level scores are smoothed in a sliding window of fixed size to mitigate noise in frame-wise predictions. For the fine-grained violence detection task, we examine several pre-trained architectures for frame embeddings and their aggregation for video classification. Experimental results on four tasks from the ABAW challenge demonstrate that our approach significantly improves validation metrics over existing baselines.
eSASRec: Enhancing Transformer-based Recommendations in a Modular Fashion
Aug 08, 2025Since their introduction, Transformer-based models, such as SASRec and BERT4Rec, have become common baselines for sequential recommendations, surpassing earlier neural and non-neural methods. A number of following publications have shown that the effectiveness of these models can be improved by, for example, slightly updating the architecture of the Transformer layers, using better training objectives, and employing improved loss functions. However, the additivity of these modular improvements has not been systematically benchmarked - this is the gap we aim to close in this paper. Through our experiments, we identify a very strong model that uses SASRec's training objective, LiGR Transformer layers, and Sampled Softmax Loss. We call this combination eSASRec (Enhanced SASRec). While we primarily focus on realistic, production-like evaluation, in our preliminarily study we find that common academic benchmarks show eSASRec to be 23% more effective compared to the most recent state-of-the-art models, such as ActionPiece. In our main production-like benchmark, eSASRec resides on the Pareto frontier in terms of the accuracy-coverage tradeoff (alongside the recent industrial models HSTU and FuXi. As the modifications compared to the original SASRec are relatively straightforward and no extra features are needed (such as timestamps in HSTU), we believe that eSASRec can be easily integrated into existing recommendation pipelines and can can serve as a strong yet very simple baseline for emerging complicated algorithms. To facilitate this, we provide the open-source implementations for our models and benchmarks in repository https://github.com/blondered/transformer_benchmark
HSEmotion Team at ABAW-8 Competition: Audiovisual Ambivalence/Hesitancy, Emotional Mimicry Intensity and Facial Expression Recognition
Mar 13, 2025This article presents our results for the eighth Affective Behavior Analysis in-the-Wild (ABAW) competition. We combine facial emotional descriptors extracted by pre-trained models, namely, our EmotiEffLib library, with acoustic features and embeddings of texts recognized from speech. The frame-level features are aggregated and fed into simple classifiers, e.g., multi-layered perceptron (feed-forward neural network with one hidden layer), to predict ambivalence/hesitancy and facial expressions. In the latter case, we also use the pre-trained facial expression recognition model to select high-score video frames and prevent their processing with a domain-specific video classifier. The video-level prediction of emotional mimicry intensity is implemented by simply aggregating frame-level features and training a multi-layered perceptron. Experimental results for three tasks from the ABAW challenge demonstrate that our approach significantly increases validation metrics compared to existing baselines.
Neural Click Models for Recommender Systems
Sep 30, 2024We develop and evaluate neural architectures to model the user behavior in recommender systems (RS) inspired by click models for Web search but going beyond standard click models. Proposed architectures include recurrent networks, Transformer-based models that alleviate the quadratic complexity of self-attention, adversarial and hierarchical architectures. Our models outperform baselines on the ContentWise and RL4RS datasets and can be used in RS simulators to model user response for RS evaluation and pretraining.
HSEmotion Team at the 7th ABAW Challenge: Multi-Task Learning and Compound Facial Expression Recognition
Jul 18, 2024



In this paper, we describe the results of the HSEmotion team in two tasks of the seventh Affective Behavior Analysis in-the-wild (ABAW) competition, namely, multi-task learning for simultaneous prediction of facial expression, valence, arousal, and detection of action units, and compound expression recognition. We propose an efficient pipeline based on frame-level facial feature extractors pre-trained in multi-task settings to estimate valence-arousal and basic facial expressions given a facial photo. We ensure the privacy-awareness of our techniques by using the lightweight architectures of neural networks, such as MT-EmotiDDAMFN, MT-EmotiEffNet, and MT-EmotiMobileFaceNet, that can run even on a mobile device without the need to send facial video to a remote server. It was demonstrated that a significant step in improving the overall accuracy is the smoothing of neural network output scores using Gaussian or box filters. It was experimentally demonstrated that such a simple post-processing of predictions from simple blending of two top visual models improves the F1-score of facial expression recognition up to 7%. At the same time, the mean Concordance Correlation Coefficient (CCC) of valence and arousal is increased by up to 1.25 times compared to each model's frame-level predictions. As a result, our final performance score on the validation set from the multi-task learning challenge is 4.5 times higher than the baseline (1.494 vs 0.32).
HSEmotion Team at the 6th ABAW Competition: Facial Expressions, Valence-Arousal and Emotion Intensity Prediction
Mar 18, 2024



This article presents our results for the sixth Affective Behavior Analysis in-the-wild (ABAW) competition. To improve the trustworthiness of facial analysis, we study the possibility of using pre-trained deep models that extract reliable emotional features without the need to fine-tune the neural networks for a downstream task. In particular, we introduce several lightweight models based on MobileViT, MobileFaceNet, EfficientNet, and DDAMFN architectures trained in multi-task scenarios to recognize facial expressions, valence, and arousal on static photos. These neural networks extract frame-level features fed into a simple classifier, e.g., linear feed-forward neural network, to predict emotion intensity, compound expressions, action units, facial expressions, and valence/arousal. Experimental results for five tasks from the sixth ABAW challenge demonstrate that our approach lets us significantly improve quality metrics on validation sets compared to existing non-ensemble techniques.
EmotiEffNet Facial Features in Uni-task Emotion Recognition in Video at ABAW-5 competition
Mar 16, 2023



In this article, the results of our team for the fifth Affective Behavior Analysis in-the-wild (ABAW) competition are presented. The usage of the pre-trained convolutional networks from the EmotiEffNet family for frame-level feature extraction is studied. In particular, we propose an ensemble of a multi-layered perceptron and the LightAutoML-based classifier. The post-processing by smoothing the results for sequential frames is implemented. Experimental results for the large-scale Aff-Wild2 database demonstrate that our model achieves a much greater macro-averaged F1-score for facial expression recognition and action unit detection and concordance correlation coefficients for valence/arousal estimation when compared to baseline.
HSE-NN Team at the 4th ABAW Competition: Multi-task Emotion Recognition and Learning from Synthetic Images
Jul 21, 2022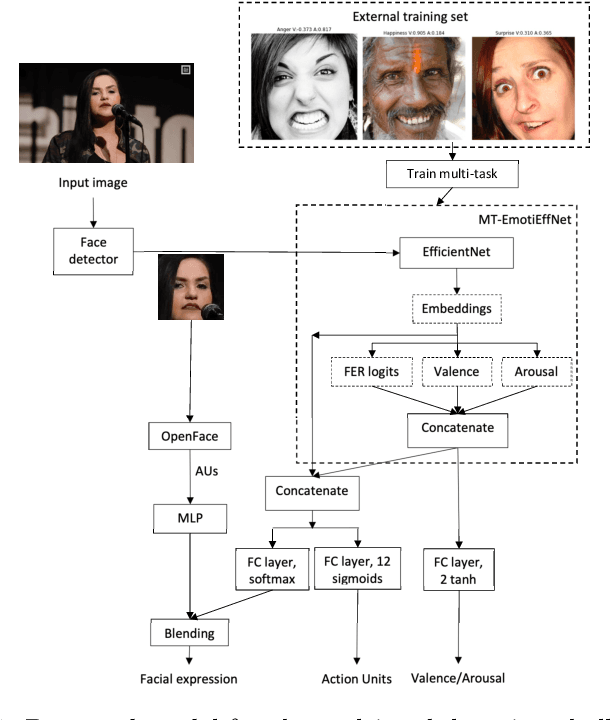
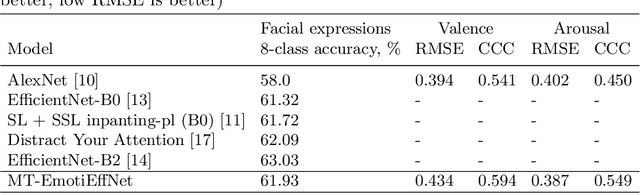
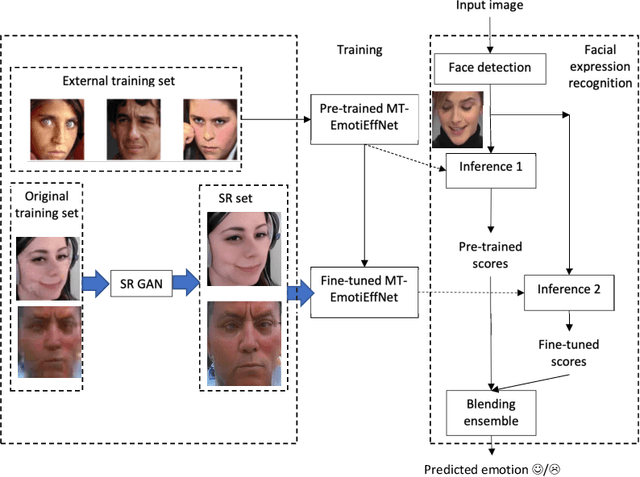
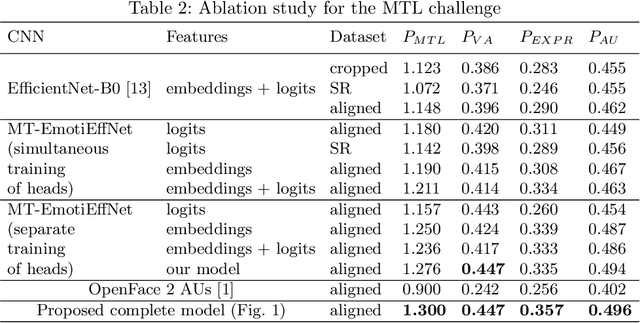
In this paper, we present the results of the HSE-NN team in the 4th competition on Affective Behavior Analysis in-the-wild (ABAW). The novel multi-task EfficientNet model is trained for simultaneous recognition of facial expressions and prediction of valence and arousal on static photos. The resulting MT-EmotiEffNet extracts visual features that are fed into simple feed-forward neural networks in the multi-task learning challenge. We obtain performance measure 1.3 on the validation set, which is significantly greater when compared to either performance of baseline (0.3) or existing models that are trained only on the s-Aff-Wild2 database. In the learning from synthetic data challenge, the quality of the original synthetic training set is increased by using the super-resolution techniques, such as Real-ESRGAN. Next, the MT-EmotiEffNet is fine-tuned on the new training set. The final prediction is a simple blending ensemble of pre-trained and fine-tuned MT-EmotiEffNets. Our average validation F1 score is 18% greater than the baseline convolutional neural network.
Frame-level Prediction of Facial Expressions, Valence, Arousal and Action Units for Mobile Devices
Mar 25, 2022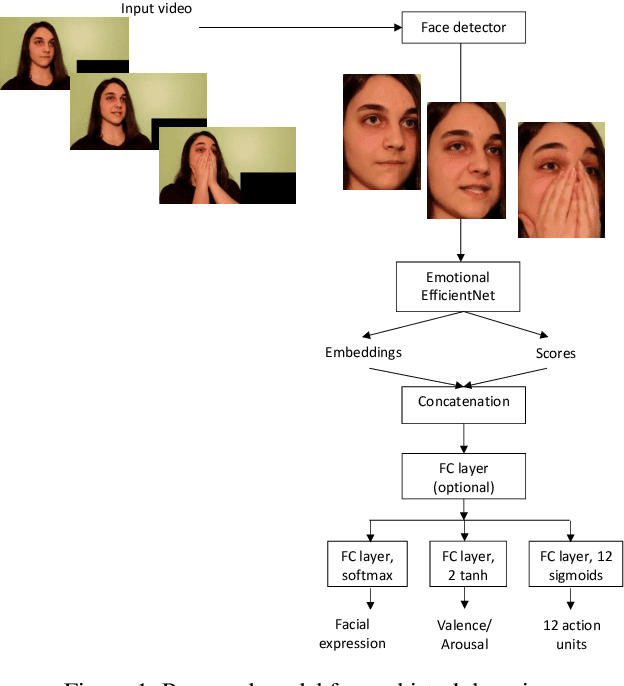
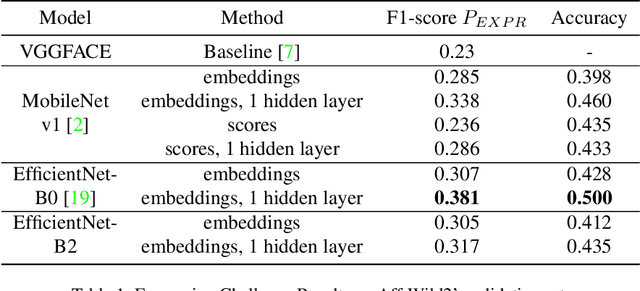

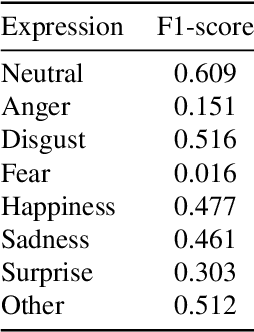
In this paper, we consider the problem of real-time video-based facial emotion analytics, namely, facial expression recognition, prediction of valence and arousal and detection of action unit points. We propose the novel frame-level emotion recognition algorithm by extracting facial features with the single EfficientNet model pre-trained on AffectNet. As a result, our approach may be implemented even for video analytics on mobile devices. Experimental results for the large scale Aff-Wild2 database from the third Affective Behavior Analysis in-the-wild (ABAW) Competition demonstrate that our simple model is significantly better when compared to the VggFace baseline. In particular, our method is characterized by 0.15-0.2 higher performance measures for validation sets in uni-task Expression Classification, Valence-Arousal Estimation and Expression Classification. Due to simplicity, our approach may be considered as a new baseline for all four sub-challenges.
Facial expression and attributes recognition based on multi-task learning of lightweight neural networks
Mar 31, 2021

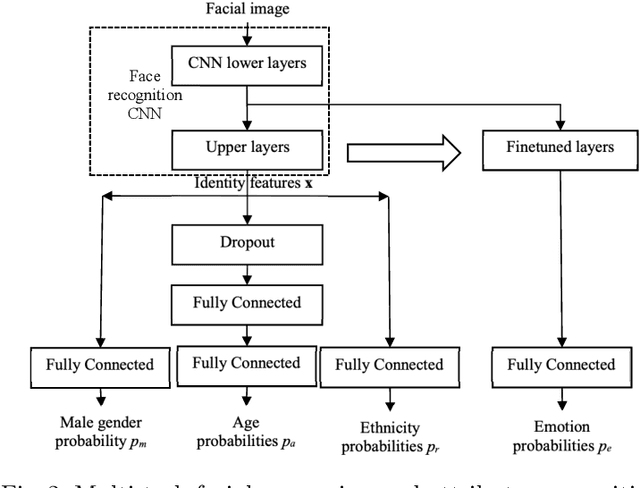
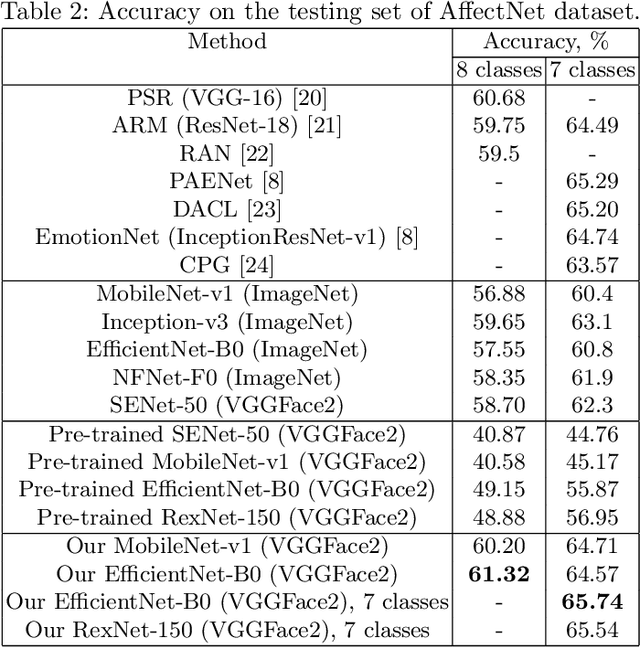
In this paper, we examine the multi-task training of lightweight convolutional neural networks for face identification and classification of facial attributes (age, gender, ethnicity) trained on cropped faces without margins. It is shown that it is still necessary to fine-tune these networks in order to predict facial expressions. Several models are presented based on MobileNet, EfficientNet and RexNet architectures. It was experimentally demonstrated that our models are characterized by the state-of-the-art emotion classification accuracy on AffectNet dataset and near state-of-the-art results in age, gender and race recognition for UTKFace dataset. Moreover, it is shown that the usage of our neural network as a feature extractor of facial regions in video frames and concatenation of several statistical functions (mean, max, etc.) leads to 4.5\% higher accuracy than the previously known state-of-the-art single models for AFEW and VGAF datasets from the EmotiW challenges. The models and source code are publicly available at https://github.com/HSE-asavchenko/face-emotion-recognition.