 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Attention-based fusion of semantic boundary and non-boundary information to improve semantic segmentation
Aug 05, 2021
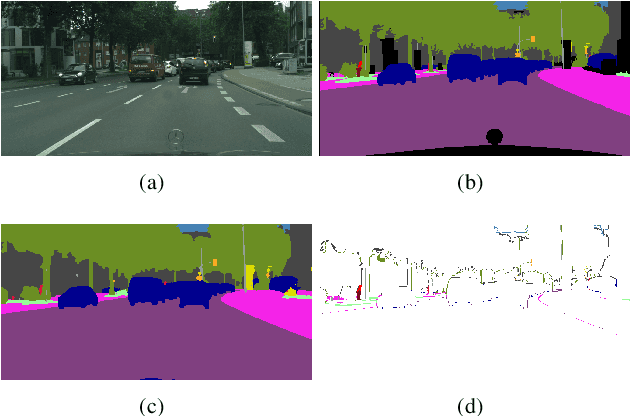
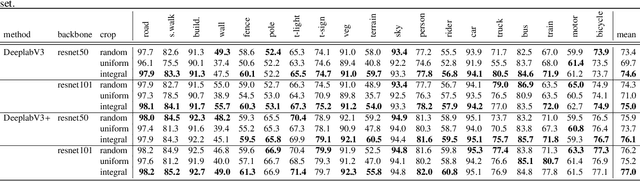
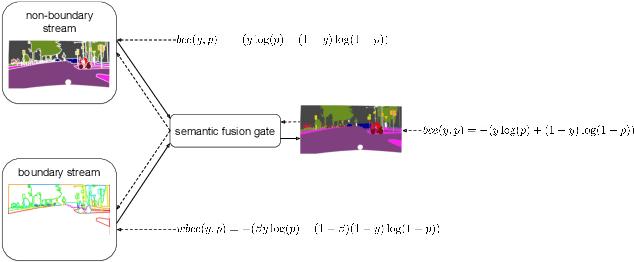

This paper introduces a method for image semantic segmentation grounded on a novel fusion scheme, which takes place inside a deep convolutional neural network. The main goal of our proposal is to explore object boundary information to improve the overall segmentation performance. Unlike previous works that combine boundary and segmentation features, or those that use boundary information to regularize semantic segmentation, we instead propose a novel approach that embodies boundary information onto segmentation. For that, our semantic segmentation method uses two streams, which are combined through an attention gate, forming an end-to-end Y-model. To the best of our knowledge, ours is the first work to show that boundary detection can improve semantic segmentation when fused through a semantic fusion gate (attention model). We performed an extensive evaluation of our method over public data sets. We found competitive results on all data sets after comparing our proposed model with other twelve state-of-the-art segmenters, considering the same training conditions. Our proposed model achieved the best mIoU on the CityScapes, CamVid, and Pascal Context data sets, and the second best on Mapillary Vistas.
Evaluating CLIP: Towards Characterization of Broader Capabilities and Downstream Implications
Aug 05, 2021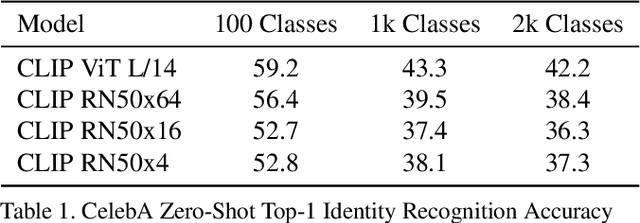
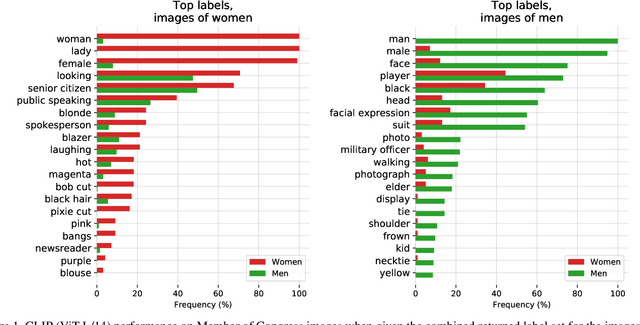


Recently, there have been breakthroughs in computer vision ("CV") models that are more generalizable with the advent of models such as CLIP and ALIGN. In this paper, we analyze CLIP and highlight some of the challenges such models pose. CLIP reduces the need for task specific training data, potentially opening up many niche tasks to automation. CLIP also allows its users to flexibly specify image classification classes in natural language, which we find can shift how biases manifest. Additionally, through some preliminary probes we find that CLIP can inherit biases found in prior computer vision systems. Given the wide and unpredictable domain of uses for such models, this raises questions regarding what sufficiently safe behaviour for such systems may look like. These results add evidence to the growing body of work calling for a change in the notion of a 'better' model--to move beyond simply looking at higher accuracy at task-oriented capability evaluations, and towards a broader 'better' that takes into account deployment-critical features such as different use contexts, and people who interact with the model when thinking about model deployment.
Detecting and Correcting Adversarial Images Using Image Processing Operations
Dec 30, 2019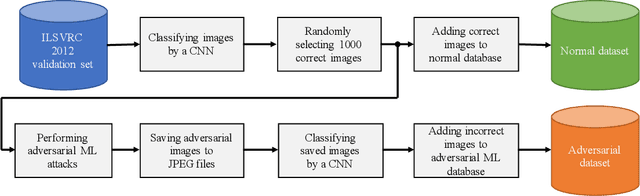
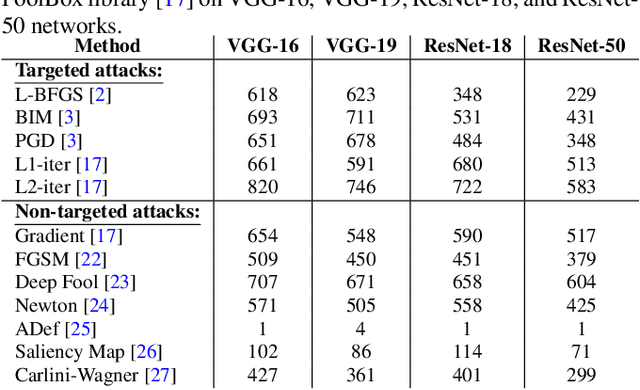

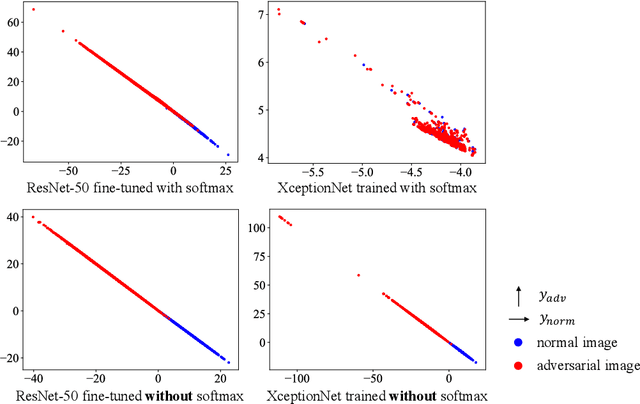
Deep neural networks (DNNs) have achieved excellent performance on several tasks and have been widely applied in both academia and industry. However, DNNs are vulnerable to adversarial machine learning attacks, in which noise is added to the input to change the network output. We have devised an image-processing-based method to detect adversarial images based on our observation that adversarial noise is reduced after applying these operations while the normal images almost remain unaffected. In addition to detection, this method can be used to restore the adversarial images' original labels, which is crucial to restoring the normal functionalities of DNN-based systems. Testing using an adversarial machine learning database we created for generating several types of attack using images from the ImageNet Large Scale Visual Recognition Challenge database demonstrated the efficiency of our proposed method for both detection and correction.
Reproducible radiomics through automated machine learning validated on twelve clinical applications
Aug 19, 2021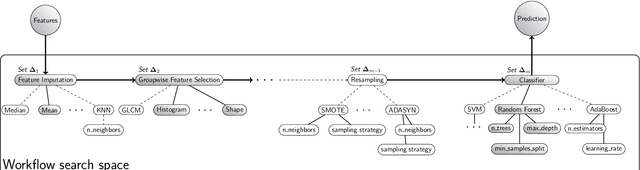
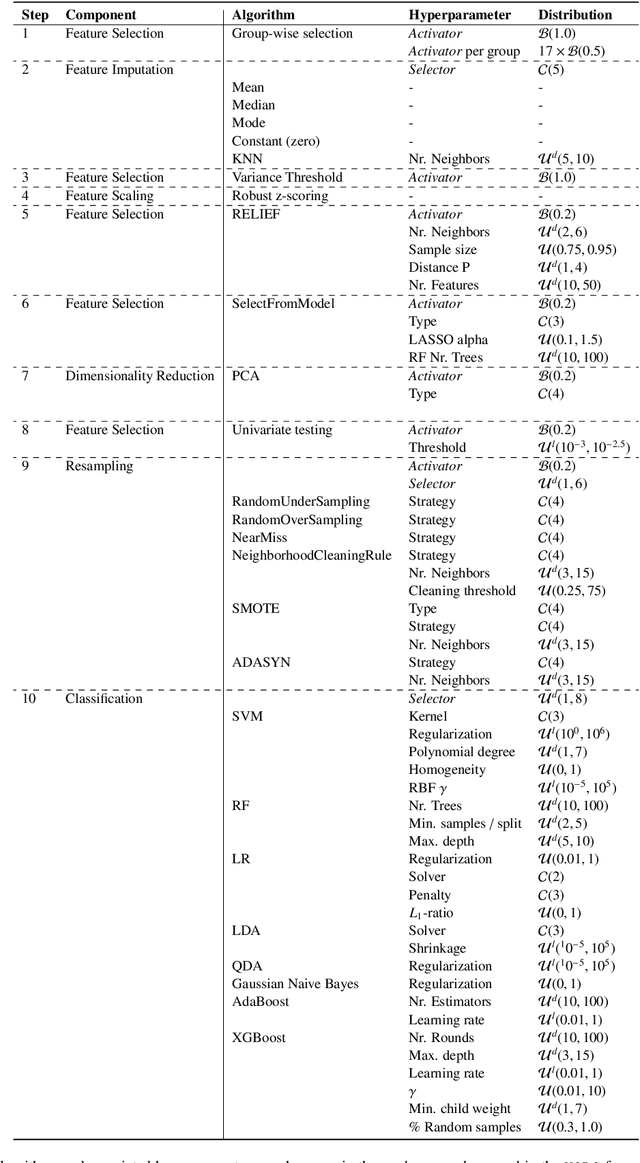
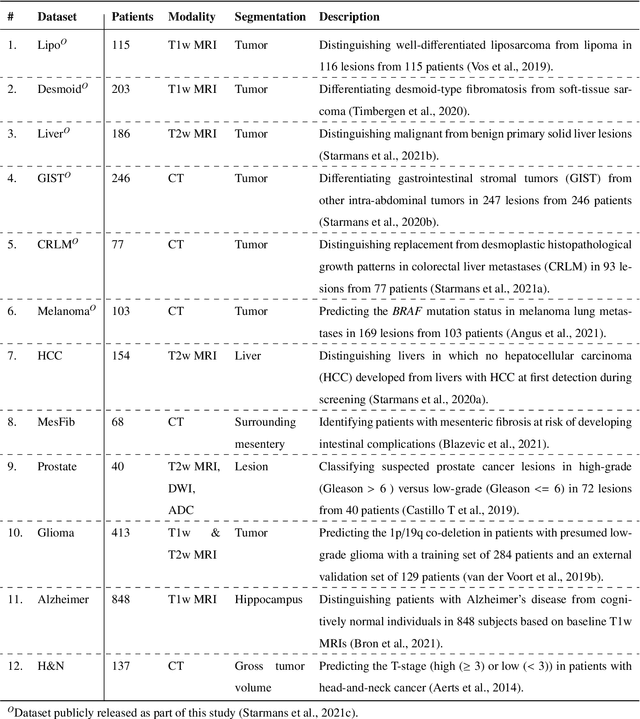
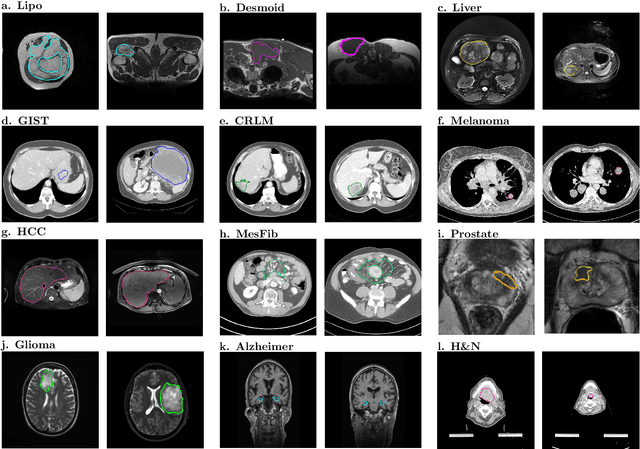
Radiomics uses quantitative medical imaging features to predict clinical outcomes. While many radiomics methods have been described in the literature, these are generally designed for a single application. The aim of this study is to generalize radiomics across applications by proposing a framework to automatically construct and optimize the radiomics workflow per application. To this end, we formulate radiomics as a modular workflow, consisting of several components: image and segmentation preprocessing, feature extraction, feature and sample preprocessing, and machine learning. For each component, a collection of common algorithms is included. To optimize the workflow per application, we employ automated machine learning using a random search and ensembling. We evaluate our method in twelve different clinical applications, resulting in the following area under the curves: 1) liposarcoma (0.83); 2) desmoid-type fibromatosis (0.82); 3) primary liver tumors (0.81); 4) gastrointestinal stromal tumors (0.77); 5) colorectal liver metastases (0.68); 6) melanoma metastases (0.51); 7) hepatocellular carcinoma (0.75); 8) mesenteric fibrosis (0.81); 9) prostate cancer (0.72); 10) glioma (0.70); 11) Alzheimer's disease (0.87); and 12) head and neck cancer (0.84). Concluding, our method fully automatically constructs and optimizes the radiomics workflow, thereby streamlining the search for radiomics biomarkers in new applications. To facilitate reproducibility and future research, we publicly release six datasets, the software implementation of our framework (open-source), and the code to reproduce this study.
Improving Vision-and-Language Navigation with Image-Text Pairs from the Web
Apr 30, 2020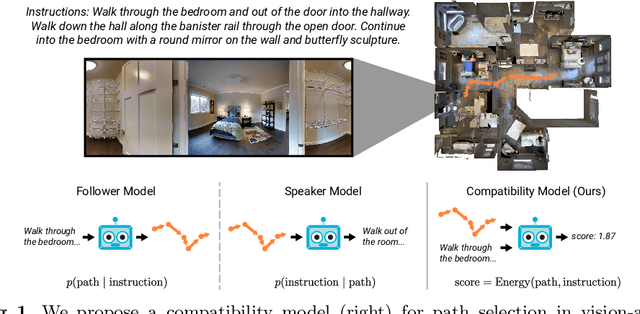
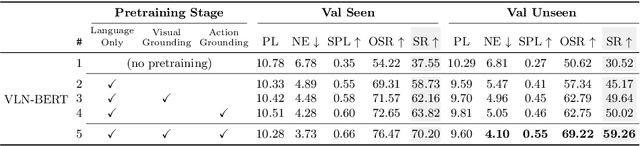

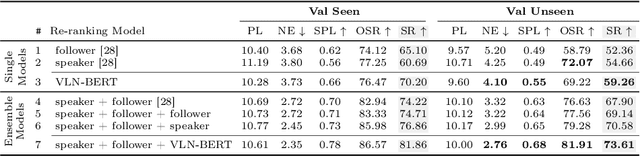
Following a navigation instruction such as 'Walk down the stairs and stop at the brown sofa' requires embodied AI agents to ground scene elements referenced via language (e.g. 'stairs') to visual content in the environment (pixels corresponding to 'stairs'). We ask the following question -- can we leverage abundant 'disembodied' web-scraped vision-and-language corpora (e.g. Conceptual Captions) to learn visual groundings (what do 'stairs' look like?) that improve performance on a relatively data-starved embodied perception task (Vision-and-Language Navigation)? Specifically, we develop VLN-BERT, a visiolinguistic transformer-based model for scoring the compatibility between an instruction ('...stop at the brown sofa') and a sequence of panoramic RGB images captured by the agent. We demonstrate that pretraining VLN-BERT on image-text pairs from the web before fine-tuning on embodied path-instruction data significantly improves performance on VLN -- outperforming the prior state-of-the-art in the fully-observed setting by 4 absolute percentage points on success rate. Ablations of our pretraining curriculum show each stage to be impactful -- with their combination resulting in further positive synergistic effects.
AIP: Adversarial Iterative Pruning Based on Knowledge Transfer for Convolutional Neural Networks
Aug 31, 2021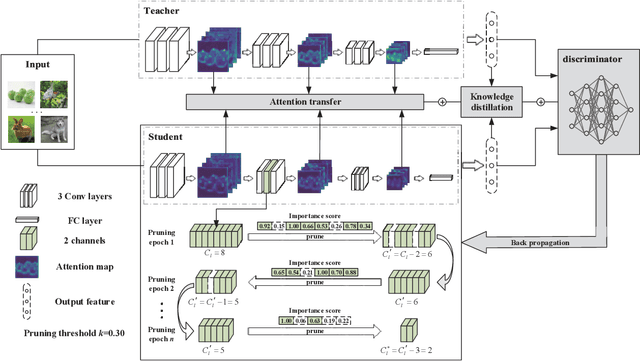
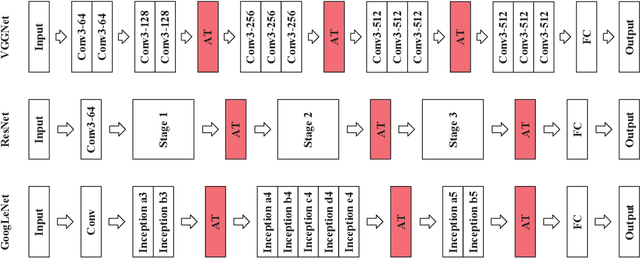
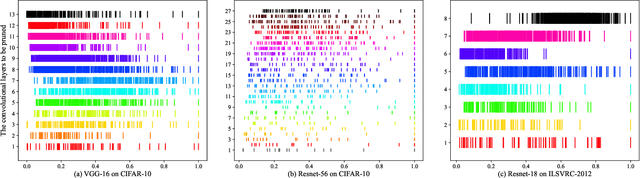
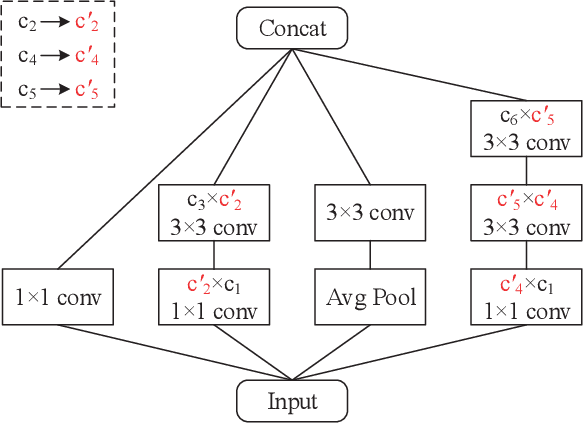
With the increase of structure complexity, convolutional neural networks (CNNs) take a fair amount of computation cost. Meanwhile, existing research reveals the salient parameter redundancy in CNNs. The current pruning methods can compress CNNs with little performance drop, but when the pruning ratio increases, the accuracy loss is more serious. Moreover, some iterative pruning methods are difficult to accurately identify and delete unimportant parameters due to the accuracy drop during pruning. We propose a novel adversarial iterative pruning method (AIP) for CNNs based on knowledge transfer. The original network is regarded as the teacher while the compressed network is the student. We apply attention maps and output features to transfer information from the teacher to the student. Then, a shallow fully-connected network is designed as the discriminator to allow the output of two networks to play an adversarial game, thereby it can quickly recover the pruned accuracy among pruning intervals. Finally, an iterative pruning scheme based on the importance of channels is proposed. We conduct extensive experiments on the image classification tasks CIFAR-10, CIFAR-100, and ILSVRC-2012 to verify our pruning method can achieve efficient compression for CNNs even without accuracy loss. On the ILSVRC-2012, when removing 36.78% parameters and 45.55% floating-point operations (FLOPs) of ResNet-18, the Top-1 accuracy drop are only 0.66%. Our method is superior to some state-of-the-art pruning schemes in terms of compressing rate and accuracy. Moreover, we further demonstrate that AIP has good generalization on the object detection task PASCAL VOC.
RFN-Nest: An end-to-end residual fusion network for infrared and visible images
Mar 07, 2021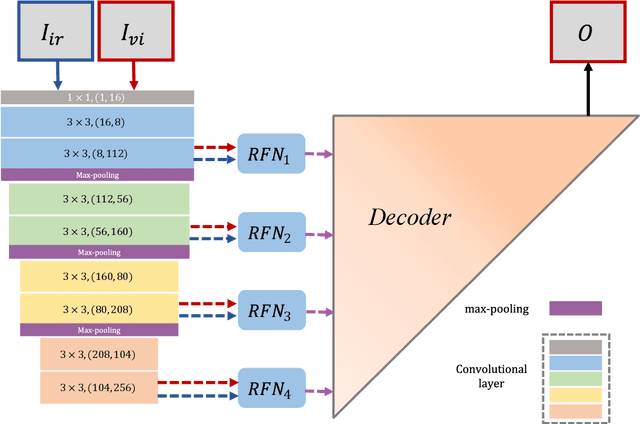
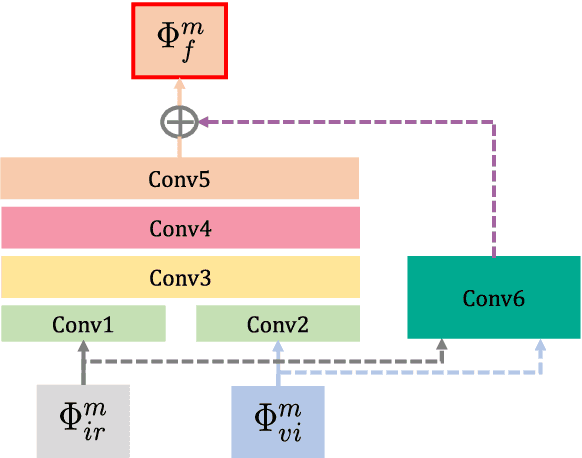

In the image fusion field, the design of deep learning-based fusion methods is far from routine. It is invariably fusion-task specific and requires a careful consideration. The most difficult part of the design is to choose an appropriate strategy to generate the fused image for a specific task in hand. Thus, devising learnable fusion strategy is a very challenging problem in the community of image fusion. To address this problem, a novel end-to-end fusion network architecture (RFN-Nest) is developed for infrared and visible image fusion. We propose a residual fusion network (RFN) which is based on a residual architecture to replace the traditional fusion approach. A novel detail-preserving loss function, and a feature enhancing loss function are proposed to train RFN. The fusion model learning is accomplished by a novel two-stage training strategy. In the first stage, we train an auto-encoder based on an innovative nest connection (Nest) concept. Next, the RFN is trained using the proposed loss functions. The experimental results on public domain data sets show that, compared with the existing methods, our end-to-end fusion network delivers a better performance than the state-of-the-art methods in both subjective and objective evaluation. The code of our fusion method is available at https://github.com/hli1221/imagefusion-rfn-nest
A Low Rank Promoting Prior for Unsupervised Contrastive Learning
Aug 05, 2021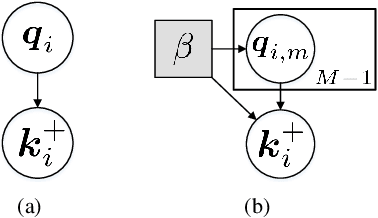
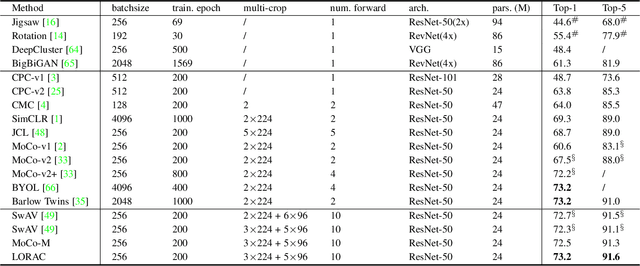
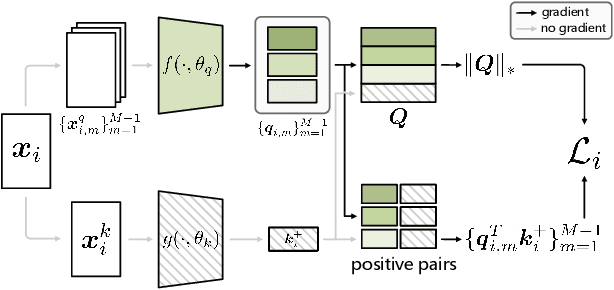

Unsupervised learning is just at a tipping point where it could really take off. Among these approaches, contrastive learning has seen tremendous progress and led to state-of-the-art performance. In this paper, we construct a novel probabilistic graphical model that effectively incorporates the low rank promoting prior into the framework of contrastive learning, referred to as LORAC. In contrast to the existing conventional self-supervised approaches that only considers independent learning, our hypothesis explicitly requires that all the samples belonging to the same instance class lie on the same subspace with small dimension. This heuristic poses particular joint learning constraints to reduce the degree of freedom of the problem during the search of the optimal network parameterization. Most importantly, we argue that the low rank prior employed here is not unique, and many different priors can be invoked in a similar probabilistic way, corresponding to different hypotheses about underlying truth behind the contrastive features. Empirical evidences show that the proposed algorithm clearly surpasses the state-of-the-art approaches on multiple benchmarks, including image classification, object detection, instance segmentation and keypoint detection.
Follow Your Path: a Progressive Method for Knowledge Distillation
Jul 20, 2021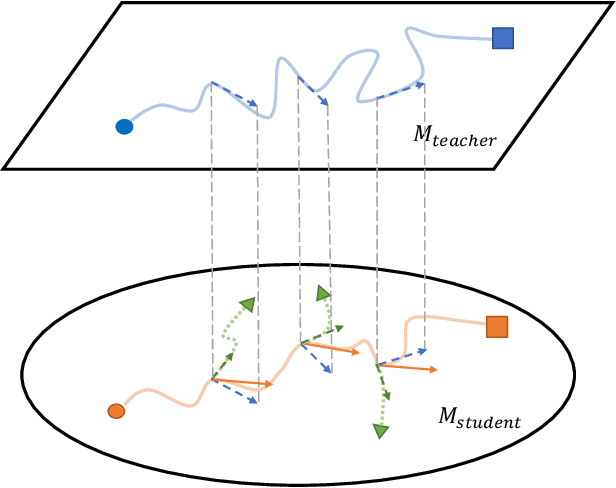
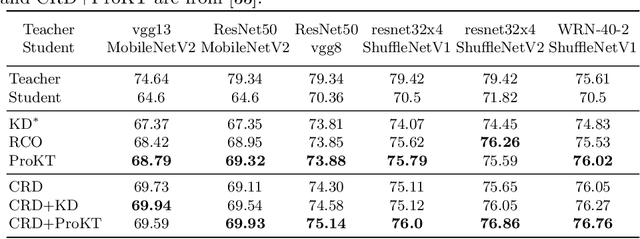
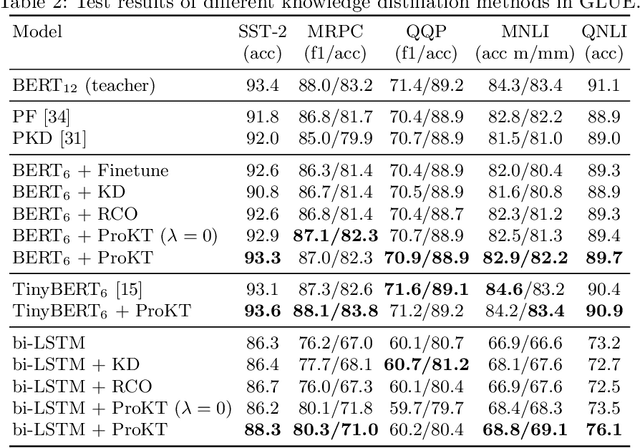
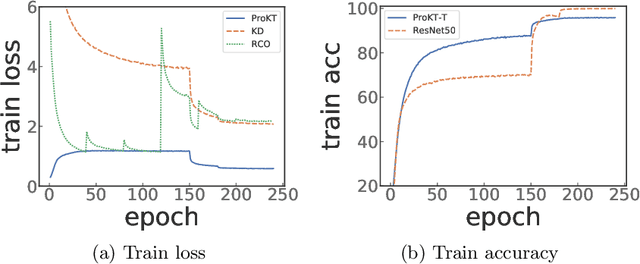
Deep neural networks often have a huge number of parameters, which posts challenges in deployment in application scenarios with limited memory and computation capacity. Knowledge distillation is one approach to derive compact models from bigger ones. However, it has been observed that a converged heavy teacher model is strongly constrained for learning a compact student network and could make the optimization subject to poor local optima. In this paper, we propose ProKT, a new model-agnostic method by projecting the supervision signals of a teacher model into the student's parameter space. Such projection is implemented by decomposing the training objective into local intermediate targets with an approximate mirror descent technique. The proposed method could be less sensitive with the quirks during optimization which could result in a better local optimum. Experiments on both image and text datasets show that our proposed ProKT consistently achieves superior performance compared to other existing knowledge distillation methods.
Exploiting Computation Power of Blockchain for Biomedical Image Segmentation
Apr 15, 2019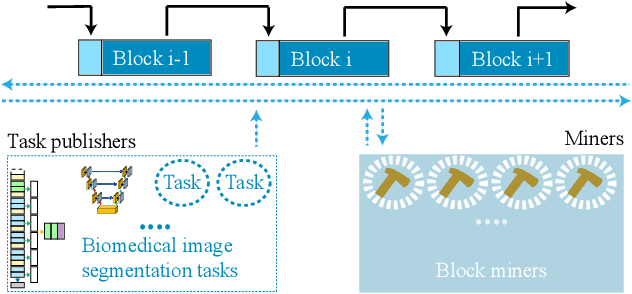
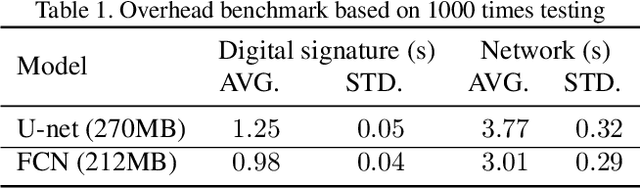
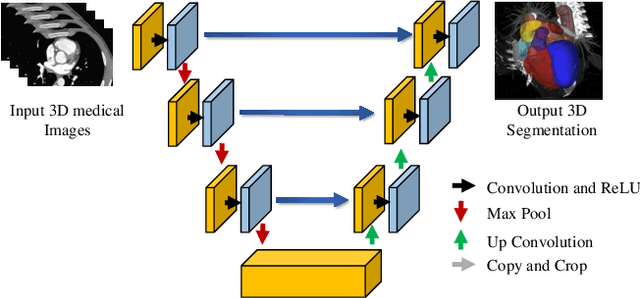
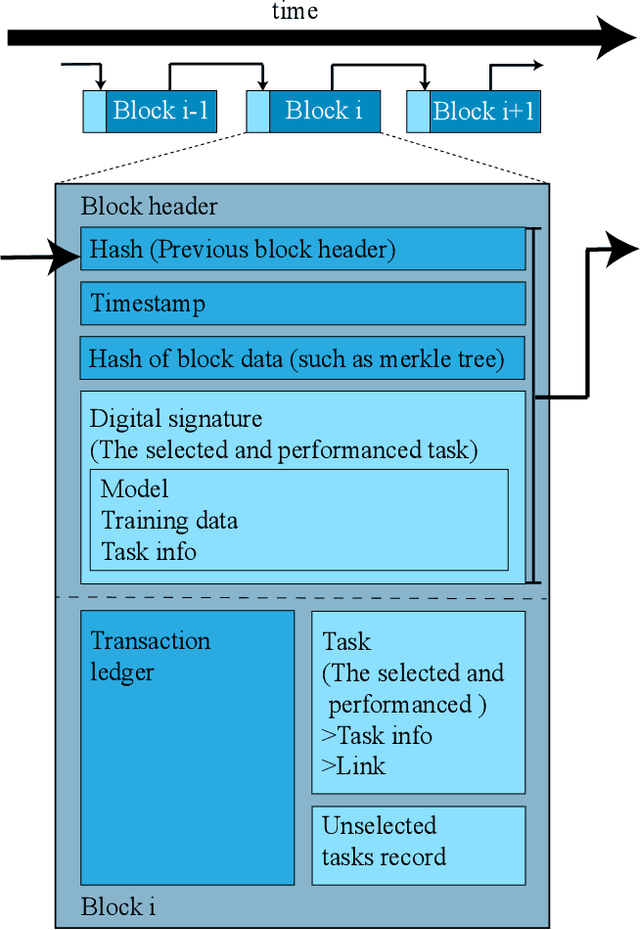
Biomedical image segmentation based on Deep neuralnetwork (DNN) is a promising approach that assists clin-ical diagnosis. This approach demands enormous com-putation power because these DNN models are compli-cated, and the size of the training data is usually very huge.As blockchain technology based on Proof-of-Work (PoW)has been widely used, an immense amount of computationpower is consumed to maintain the PoW consensus. Inthis paper, we propose a design to exploit the computationpower of blockchain miners for biomedical image segmen-tation, which lets miners perform image segmentation as theProof-of-Useful-Work (PoUW) instead of calculating use-less hash values. This work distinguishes itself from otherPoUW by addressing various limitations of related others.As the overhead evaluation shown in Section 5 indicates,for U-net and FCN, the average overhead of digital sig-nature is 1.25 seconds and 0.98 seconds, respectively, andthe average overhead of network is 3.77 seconds and 3.01seconds, respectively. These quantitative experiment resultsprove that the overhead of the digital signature and networkis small and comparable to other existing PoUW designs.