 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Inception Generative Network for Cognitive Image Inpainting
Dec 01, 2018

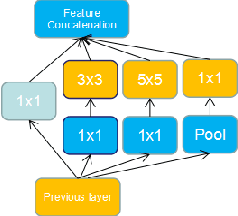
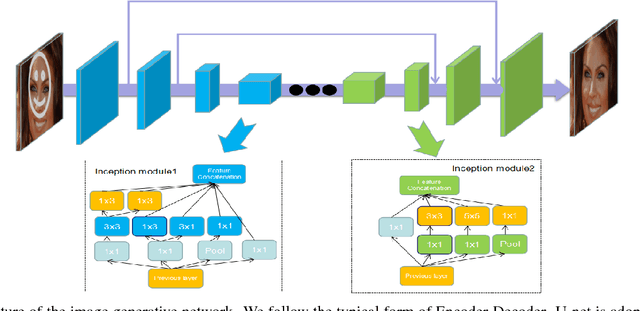

Recent advances in deep learning have shown exciting promise in filling large holes and lead to another orientation for image inpainting. However, existing learning-based methods often create artifacts and fallacious textures because of insufficient cognition understanding. Previous generative networks are limited with single receptive type and give up pooling in consideration of detail sharpness. Human cognition is constant regardless of the target attribute. As multiple receptive fields improve the ability of abstract image characterization and pooling can keep feature invariant, specifically, deep inception learning is adopted to promote high-level feature representation and enhance model learning capacity for local patches. Moreover, approaches for generating diverse mask images are introduced and a random mask dataset is created. We benchmark our methods on ImageNet, Places2 dataset, and CelebA-HQ. Experiments for regular, irregular, and custom regions completion are all performed and free-style image inpainting is also presented. Quantitative comparisons with previous state-of-the-art methods show that ours obtain much more natural image completions.
Simultaneous Fidelity and Regularization Learning for Image Restoration
Oct 16, 2018



Most existing non-blind restoration methods are based on the assumption that a precise degradation model is known. As the degradation process can only partially known or inaccurately modeled, images may not be well restored. Rain streak removal and image deconvolution with inaccurate blur kernels are two representative examples of such tasks. For rain streak removal, although an input image can be decomposed into a scene layer and a rain streak layer, there exists no explicit formulation for modeling rain streaks and the composition with scene layer. For blind deconvolution, as estimation error of blur kernel is usually introduced, the subsequent non-blind deconvolution process does not restore the latent image well. In this paper, we propose a principled algorithm within the maximum a posterior framework to tackle image restoration with a partially known or inaccurate degradation model. Specifically, the residual caused by a partially known or inaccurate degradation model is spatially dependent and complexly distributed. With a training set of degraded and ground-truth image pairs, we parameterize and learn the fidelity term for a degradation model in a task-driven manner. Furthermore, the regularization term can also be learned along with the fidelity term, thereby forming a simultaneous fidelity and regularization learning model. Extensive experimental results demonstrate the effectiveness of the proposed model for image deconvolution with inaccurate blur kernels and rain streak removal. Furthermore, for image restoration with precise degradation process, e.g., Gaussian denoising, the proposed model can be applied to learn the proper fidelity term for optimal performance based on visual perception metrics.
Beyond pixel-wise supervision for segmentation: A few global shape descriptors might be surprisingly good!
May 03, 2021

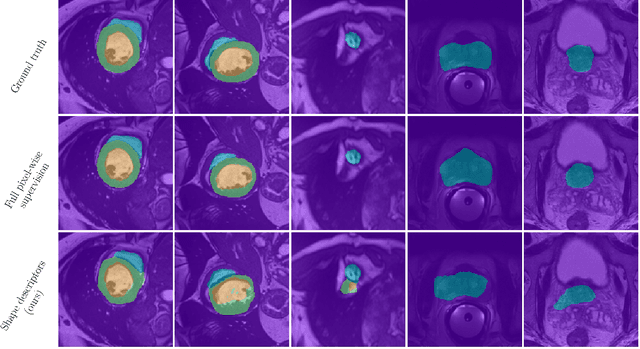
Standard losses for training deep segmentation networks could be seen as individual classifications of pixels, instead of supervising the global shape of the predicted segmentations. While effective, they require exact knowledge of the label of each pixel in an image. This study investigates how effective global geometric shape descriptors could be, when used on their own as segmentation losses for training deep networks. Not only interesting theoretically, there exist deeper motivations to posing segmentation problems as a reconstruction of shape descriptors: Annotations to obtain approximations of low-order shape moments could be much less cumbersome than their full-mask counterparts, and anatomical priors could be readily encoded into invariant shape descriptions, which might alleviate the annotation burden. Also, and most importantly, we hypothesize that, given a task, certain shape descriptions might be invariant across image acquisition protocols/modalities and subject populations, which might open interesting research avenues for generalization in medical image segmentation. We introduce and formulate a few shape descriptors in the context of deep segmentation, and evaluate their potential as standalone losses on two different challenging tasks. Inspired by recent works in constrained optimization for deep networks, we propose a way to use those descriptors to supervise segmentation, without any pixel-level label. Very surprisingly, as little as 4 descriptors values per class can approach the performance of a segmentation mask with 65k individual discrete labels. We also found that shape descriptors can be a valid way to encode anatomical priors about the task, enabling to leverage expert knowledge without additional annotations. Our implementation is publicly available and can be easily extended to other tasks and descriptors: https://github.com/hkervadec/shape_descriptors
Noise Entangled GAN For Low-Dose CT Simulation
Feb 18, 2021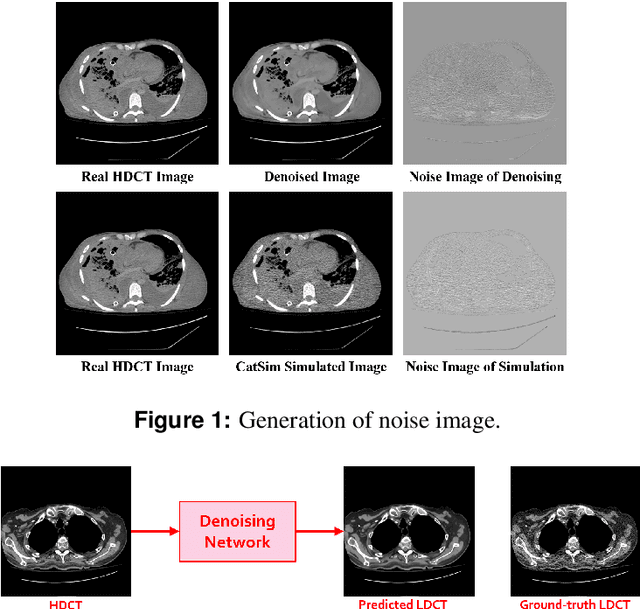
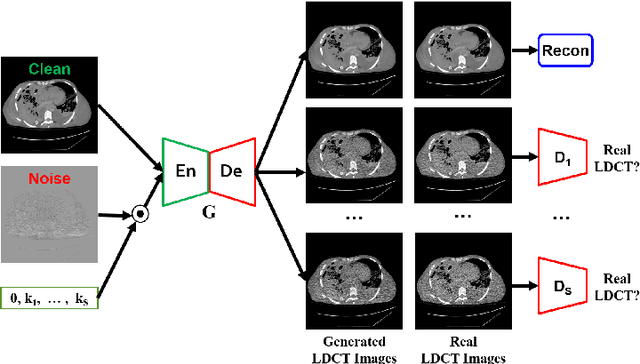
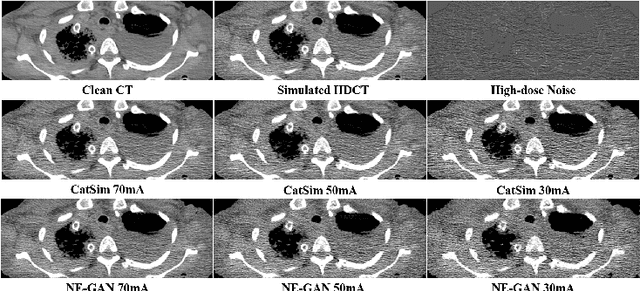
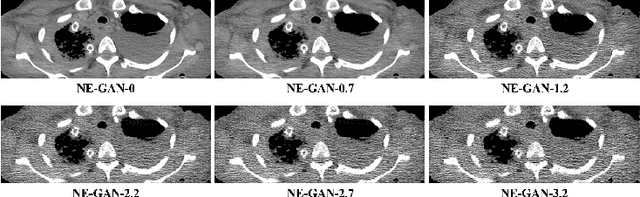
We propose a Noise Entangled GAN (NE-GAN) for simulating low-dose computed tomography (CT) images from a higher dose CT image. First, we present two schemes to generate a clean CT image and a noise image from the high-dose CT image. Then, given these generated images, an NE-GAN is proposed to simulate different levels of low-dose CT images, where the level of generated noise can be continuously controlled by a noise factor. NE-GAN consists of a generator and a set of discriminators, and the number of discriminators is determined by the number of noise levels during training. Compared with the traditional methods based on the projection data that are usually unavailable in real applications, NE-GAN can directly learn from the real and/or simulated CT images and may create low-dose CT images quickly without the need of raw data or other proprietary CT scanner information. The experimental results show that the proposed method has the potential to simulate realistic low-dose CT images.
Model-based 3D Hand Reconstruction via Self-Supervised Learning
Mar 22, 2021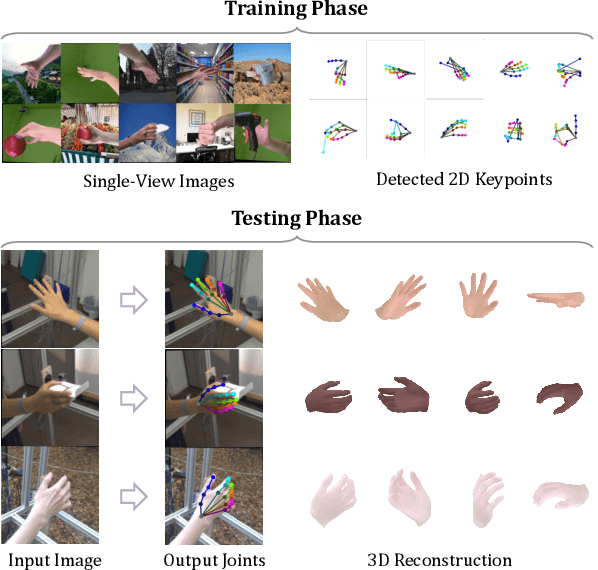
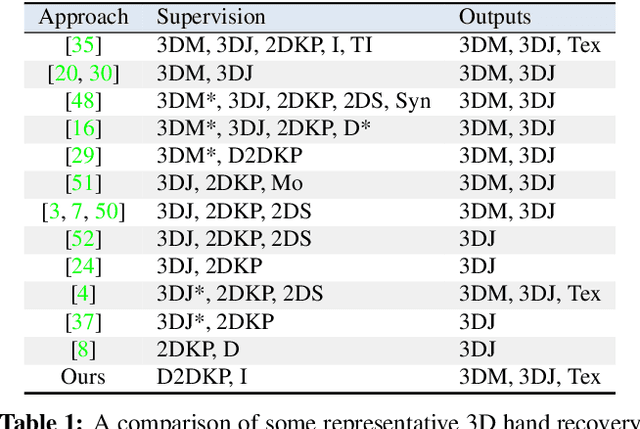
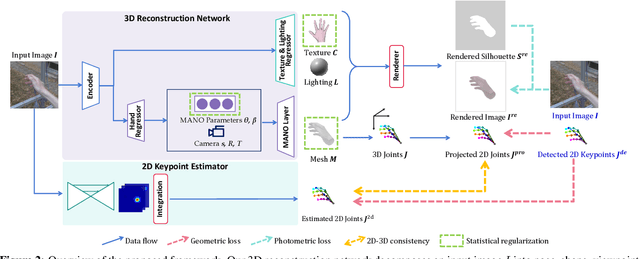
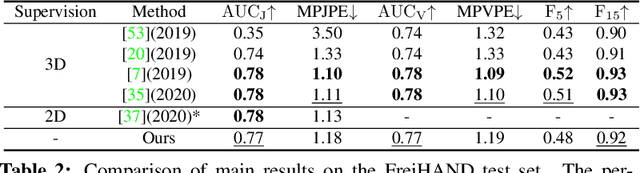
Reconstructing a 3D hand from a single-view RGB image is challenging due to various hand configurations and depth ambiguity. To reliably reconstruct a 3D hand from a monocular image, most state-of-the-art methods heavily rely on 3D annotations at the training stage, but obtaining 3D annotations is expensive. To alleviate reliance on labeled training data, we propose S2HAND, a self-supervised 3D hand reconstruction network that can jointly estimate pose, shape, texture, and the camera viewpoint. Specifically, we obtain geometric cues from the input image through easily accessible 2D detected keypoints. To learn an accurate hand reconstruction model from these noisy geometric cues, we utilize the consistency between 2D and 3D representations and propose a set of novel losses to rationalize outputs of the neural network. For the first time, we demonstrate the feasibility of training an accurate 3D hand reconstruction network without relying on manual annotations. Our experiments show that the proposed method achieves comparable performance with recent fully-supervised methods while using fewer supervision data.
Robust Semantic Interpretability: Revisiting Concept Activation Vectors
Apr 06, 2021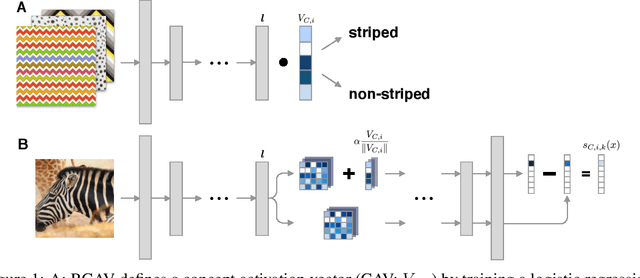
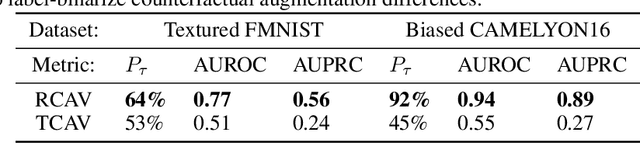
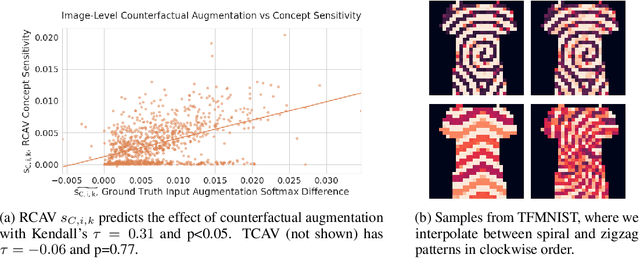

Interpretability methods for image classification assess model trustworthiness by attempting to expose whether the model is systematically biased or attending to the same cues as a human would. Saliency methods for feature attribution dominate the interpretability literature, but these methods do not address semantic concepts such as the textures, colors, or genders of objects within an image. Our proposed Robust Concept Activation Vectors (RCAV) quantifies the effects of semantic concepts on individual model predictions and on model behavior as a whole. RCAV calculates a concept gradient and takes a gradient ascent step to assess model sensitivity to the given concept. By generalizing previous work on concept activation vectors to account for model non-linearity, and by introducing stricter hypothesis testing, we show that RCAV yields interpretations which are both more accurate at the image level and robust at the dataset level. RCAV, like saliency methods, supports the interpretation of individual predictions. To evaluate the practical use of interpretability methods as debugging tools, and the scientific use of interpretability methods for identifying inductive biases (e.g. texture over shape), we construct two datasets and accompanying metrics for realistic benchmarking of semantic interpretability methods. Our benchmarks expose the importance of counterfactual augmentation and negative controls for quantifying the practical usability of interpretability methods.
Hybrid Loss for Learning Single-Image-based HDR Reconstruction
Dec 18, 2018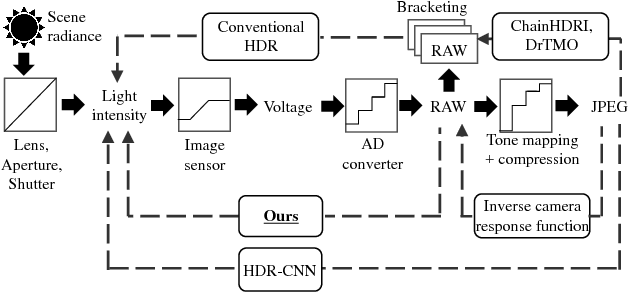
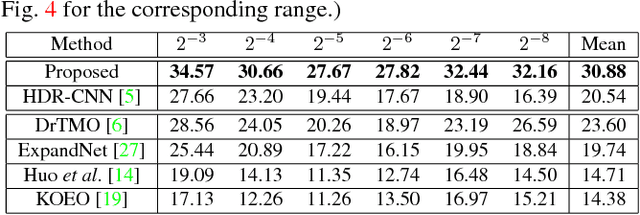
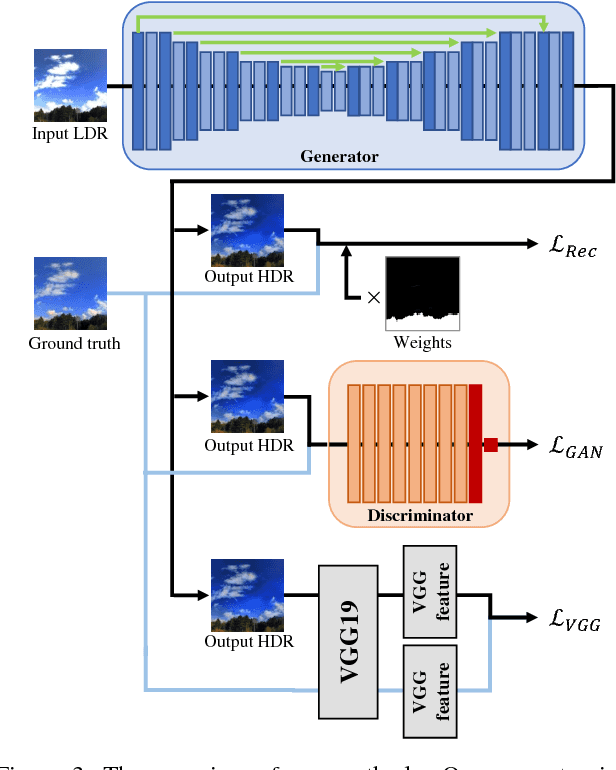
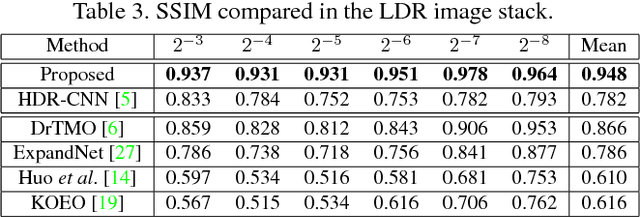
This paper tackles high-dynamic-range (HDR) image reconstruction given only a single low-dynamic-range (LDR) image as input. While the existing methods focus on minimizing the mean-squared-error (MSE) between the target and reconstructed images, we minimize a hybrid loss that consists of perceptual and adversarial losses in addition to HDR-reconstruction loss. The reconstruction loss instead of MSE is more suitable for HDR since it puts more weight on both over- and under- exposed areas. It makes the reconstruction faithful to the input. Perceptual loss enables the networks to utilize knowledge about objects and image structure for recovering the intensity gradients of saturated and grossly quantized areas. Adversarial loss helps to select the most plausible appearance from multiple solutions. The hybrid loss that combines all the three losses is calculated in logarithmic space of image intensity so that the outputs retain a large dynamic range and meanwhile the learning becomes tractable. Comparative experiments conducted with other state-of-the-art methods demonstrated that our method produces a leap in image quality.
2-bit Model Compression of Deep Convolutional Neural Network on ASIC Engine for Image Retrieval
May 08, 2019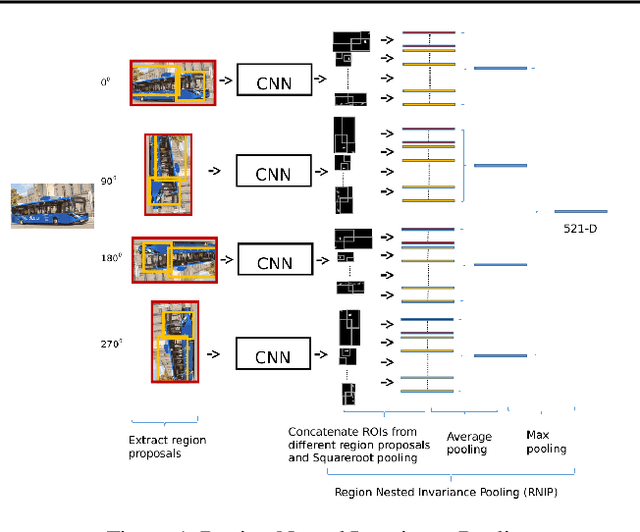
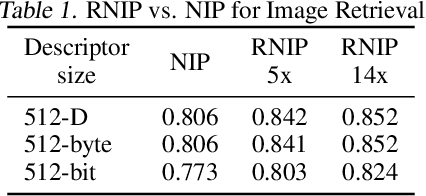
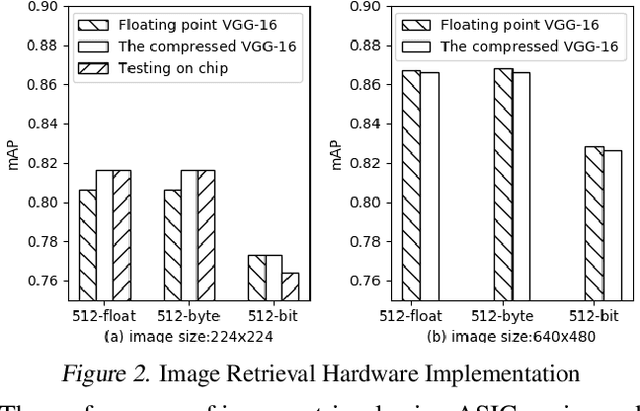

Image retrieval utilizes image descriptors to retrieve the most similar images to a given query image. Convolutional neural network (CNN) is becoming the dominant approach to extract image descriptors for image retrieval. For low-power hardware implementation of image retrieval, the drawback of CNN-based feature descriptor is that it requires hundreds of megabytes of storage. To address this problem, this paper applies deep model quantization and compression to CNN in ASIC chip for image retrieval. It is demonstrated that the CNN-based features descriptor can be extracted using as few as 2-bit weights quantization to deliver a similar performance as floating-point model for image retrieval. In addition, to implement CNN in ASIC, especially for large scale images, the limited buffer size of chips should be considered. To retrieve large scale images, we propose an improved pooling strategy, region nested invariance pooling (RNIP), which uses cropped sub-images for CNN. Testing results on chip show that integrating RNIP with the proposed 2-bit CNN model compression approach is capable of retrieving large scale images.
3D Dense Separated Convolution Module for Volumetric Image Analysis
May 14, 2019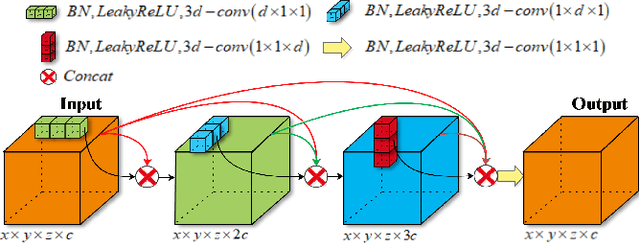
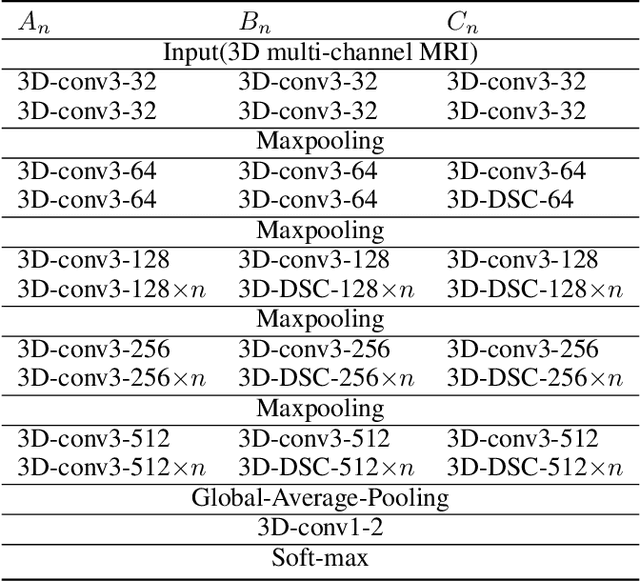
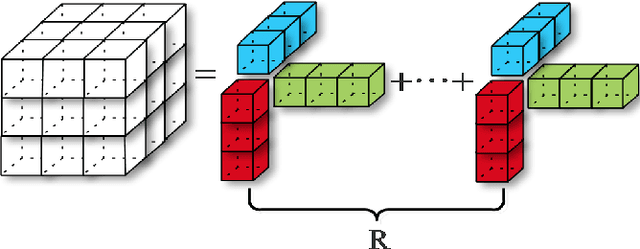
With the thriving of deep learning, 3D Convolutional Neural Networks have become a popular choice in volumetric image analysis due to their impressive 3D contexts mining ability. However, the 3D convolutional kernels will introduce a significant increase in the amount of trainable parameters. Considering the training data is often limited in biomedical tasks, a tradeoff has to be made between model size and its representational power. To address this concern, in this paper, we propose a novel 3D Dense Separated Convolution (3D-DSC) module to replace the original 3D convolutional kernels. The 3D-DSC module is constructed by a series of densely connected 1D filters. The decomposition of 3D kernel into 1D filters reduces the risk of over-fitting by removing the redundancy of 3D kernels in a topologically constrained manner, while providing the infrastructure for deepening the network. By further introducing nonlinear layers and dense connections between 1D filters, the network's representational power can be significantly improved while maintaining a compact architecture. We demonstrate the superiority of 3D-DSC on volumetric image classification and segmentation, which are two challenging tasks often encountered in biomedical image computing.
C4Synth: Cross-Caption Cycle-Consistent Text-to-Image Synthesis
Sep 20, 2018
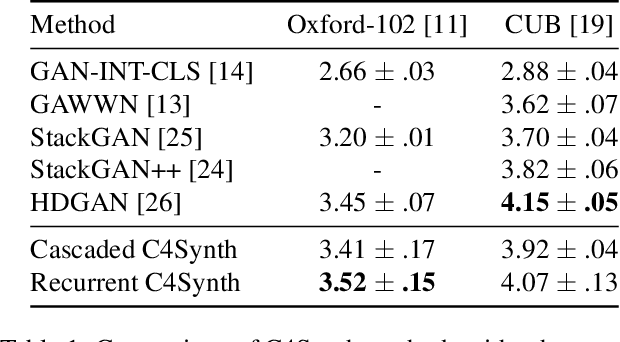
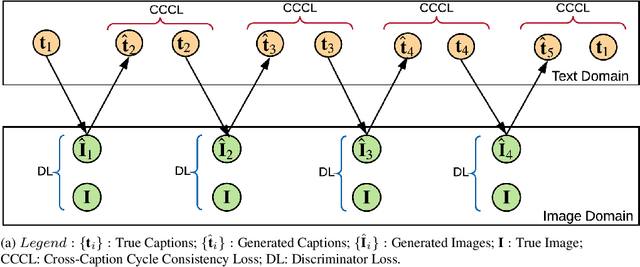
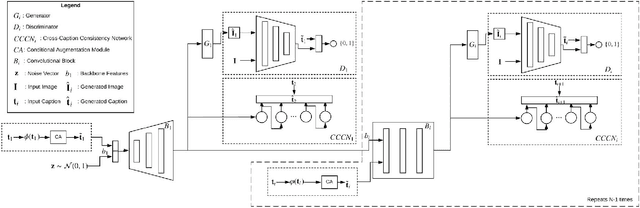
Generating an image from its description is a challenging task worth solving because of its numerous practical applications ranging from image editing to virtual reality. All existing methods use one single caption to generate a plausible image. A single caption by itself, can be limited, and may not be able to capture the variety of concepts and behavior that may be present in the image. We propose two deep generative models that generate an image by making use of multiple captions describing it. This is achieved by ensuring 'Cross-Caption Cycle Consistency' between the multiple captions and the generated image(s). We report quantitative and qualitative results on the standard Caltech-UCSD Birds (CUB) and Oxford-102 Flowers datasets to validate the efficacy of the proposed approach.