 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated alignment is harder than you think
May 07, 2026A leading proposal for aligning artificial superintelligence (ASI) is to use AI agents to automate an increasing fraction of alignment research as capabilities improve. We argue that, even when research agents are not scheming to deliberately sabotage alignment work, this plan could produce compelling but catastrophically misleading safety assessments resulting in the unintentional deployment of misaligned AI. This could happen because alignment research involves many hard-to-supervise fuzzy tasks (tasks without clear evaluation criteria, for which human judgement is systematically flawed). Consequently, research outputs will contain systematic, undetected errors, and even correct outputs could be incorrectly aggregated into overconfident safety assessments. This problem is likely to be worse for automated alignment research than for human-generated alignment research for several reasons: 1) optimisation pressure means agent-generated mistakes are concentrated among those that human reviewers are least likely to catch; 2) agents are likely to produce errors that do not resemble human mistakes; 3) AI-generated alignment solutions may involve arguments humans cannot evaluate; and 4) shared weights, data and training processes may make AI outputs more correlated than human equivalents. Therefore, agents must be trained to reliably perform hard-to-supervise fuzzy tasks. Generalisation and scalable oversight are the leading candidates for achieving this but both face novel challenges in the context of automated alignment.
An alignment safety case sketch based on debate
May 08, 2025If AI systems match or exceed human capabilities on a wide range of tasks, it may become difficult for humans to efficiently judge their actions -- making it hard to use human feedback to steer them towards desirable traits. One proposed solution is to leverage another superhuman system to point out flaws in the system's outputs via a debate. This paper outlines the value of debate for AI safety, as well as the assumptions and further research required to make debate work. It does so by sketching an ``alignment safety case'' -- an argument that an AI system will not autonomously take actions which could lead to egregious harm, despite being able to do so. The sketch focuses on the risk of an AI R\&D agent inside an AI company sabotaging research, for example by producing false results. To prevent this, the agent is trained via debate, subject to exploration guarantees, to teach the system to be honest. Honesty is maintained throughout deployment via online training. The safety case rests on four key claims: (1) the agent has become good at the debate game, (2) good performance in the debate game implies that the system is mostly honest, (3) the system will not become significantly less honest during deployment, and (4) the deployment context is tolerant of some errors. We identify open research problems that, if solved, could render this a compelling argument that an AI system is safe.
Taking AI Welfare Seriously
Nov 04, 2024In this report, we argue that there is a realistic possibility that some AI systems will be conscious and/or robustly agentic in the near future. That means that the prospect of AI welfare and moral patienthood, i.e. of AI systems with their own interests and moral significance, is no longer an issue only for sci-fi or the distant future. It is an issue for the near future, and AI companies and other actors have a responsibility to start taking it seriously. We also recommend three early steps that AI companies and other actors can take: They can (1) acknowledge that AI welfare is an important and difficult issue (and ensure that language model outputs do the same), (2) start assessing AI systems for evidence of consciousness and robust agency, and (3) prepare policies and procedures for treating AI systems with an appropriate level of moral concern. To be clear, our argument in this report is not that AI systems definitely are, or will be, conscious, robustly agentic, or otherwise morally significant. Instead, our argument is that there is substantial uncertainty about these possibilities, and so we need to improve our understanding of AI welfare and our ability to make wise decisions about this issue. Otherwise there is a significant risk that we will mishandle decisions about AI welfare, mistakenly harming AI systems that matter morally and/or mistakenly caring for AI systems that do not.
Steering Without Side Effects: Improving Post-Deployment Control of Language Models
Jun 21, 2024Language models (LMs) have been shown to behave unexpectedly post-deployment. For example, new jailbreaks continually arise, allowing model misuse, despite extensive red-teaming and adversarial training from developers. Given most model queries are unproblematic and frequent retraining results in unstable user experience, methods for mitigation of worst-case behavior should be targeted. One such method is classifying inputs as potentially problematic, then selectively applying steering vectors on these problematic inputs, i.e. adding particular vectors to model hidden states. However, steering vectors can also negatively affect model performance, which will be an issue on cases where the classifier was incorrect. We present KL-then-steer (KTS), a technique that decreases the side effects of steering while retaining its benefits, by first training a model to minimize Kullback-Leibler (KL) divergence between a steered and unsteered model on benign inputs, then steering the model that has undergone this training. Our best method prevents 44% of jailbreak attacks compared to the original Llama-2-chat-7B model while maintaining helpfulness (as measured by MT-Bench) on benign requests almost on par with the original LM. To demonstrate the generality and transferability of our method beyond jailbreaks, we show that our KTS model can be steered to reduce bias towards user-suggested answers on TruthfulQA. Code is available: https://github.com/AsaCooperStickland/kl-then-steer.
Let's Think Dot by Dot: Hidden Computation in Transformer Language Models
Apr 24, 2024Chain-of-thought responses from language models improve performance across most benchmarks. However, it remains unclear to what extent these performance gains can be attributed to human-like task decomposition or simply the greater computation that additional tokens allow. We show that transformers can use meaningless filler tokens (e.g., '......') in place of a chain of thought to solve two hard algorithmic tasks they could not solve when responding without intermediate tokens. However, we find empirically that learning to use filler tokens is difficult and requires specific, dense supervision to converge. We also provide a theoretical characterization of the class of problems where filler tokens are useful in terms of the quantifier depth of a first-order formula. For problems satisfying this characterization, chain-of-thought tokens need not provide information about the intermediate computational steps involved in multi-token computations. In summary, our results show that additional tokens can provide computational benefits independent of token choice. The fact that intermediate tokens can act as filler tokens raises concerns about large language models engaging in unauditable, hidden computations that are increasingly detached from the observed chain-of-thought tokens.
Self-Consistency of Large Language Models under Ambiguity
Oct 20, 2023



Large language models (LLMs) that do not give consistent answers across contexts are problematic when used for tasks with expectations of consistency, e.g., question-answering, explanations, etc. Our work presents an evaluation benchmark for self-consistency in cases of under-specification where two or more answers can be correct. We conduct a series of behavioral experiments on the OpenAI model suite using an ambiguous integer sequence completion task. We find that average consistency ranges from 67\% to 82\%, far higher than would be predicted if a model's consistency was random, and increases as model capability improves. Furthermore, we show that models tend to maintain self-consistency across a series of robustness checks, including prompting speaker changes and sequence length changes. These results suggest that self-consistency arises as an emergent capability without specifically training for it. Despite this, we find that models are uncalibrated when judging their own consistency, with models displaying both over- and under-confidence. We also propose a nonparametric test for determining from token output distribution whether a model assigns non-trivial probability to alternative answers. Using this test, we find that despite increases in self-consistency, models usually place significant weight on alternative, inconsistent answers. This distribution of probability mass provides evidence that even highly self-consistent models internally compute multiple possible responses.
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Jul 27, 2023



Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing its flaws. In this paper, we (1) survey open problems and fundamental limitations of RLHF and related methods; (2) overview techniques to understand, improve, and complement RLHF in practice; and (3) propose auditing and disclosure standards to improve societal oversight of RLHF systems. Our work emphasizes the limitations of RLHF and highlights the importance of a multi-faceted approach to the development of safer AI systems.
Objective Robustness in Deep Reinforcement Learning
Jun 08, 2021

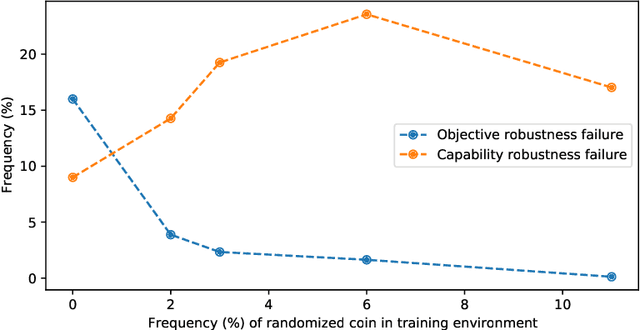

We study objective robustness failures, a type of out-of-distribution robustness failure in reinforcement learning (RL). Objective robustness failures occur when an RL agent retains its capabilities out-of-distribution yet pursues the wrong objective. This kind of failure presents different risks than the robustness problems usually considered in the literature, since it involves agents that leverage their capabilities to pursue the wrong objective rather than simply failing to do anything useful. We provide the first explicit empirical demonstrations of objective robustness failures and present a partial characterization of its causes.
Robust Semantic Interpretability: Revisiting Concept Activation Vectors
Apr 06, 2021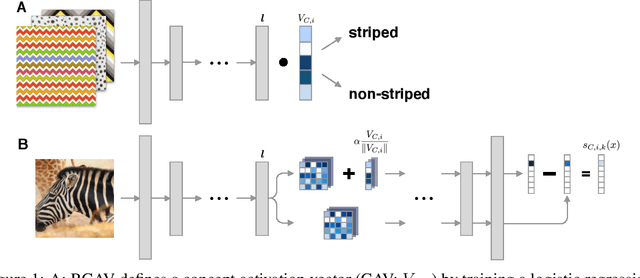
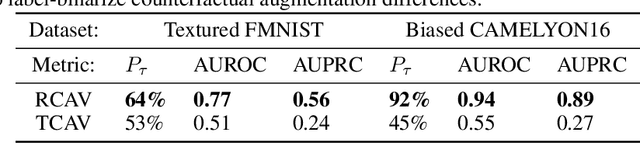
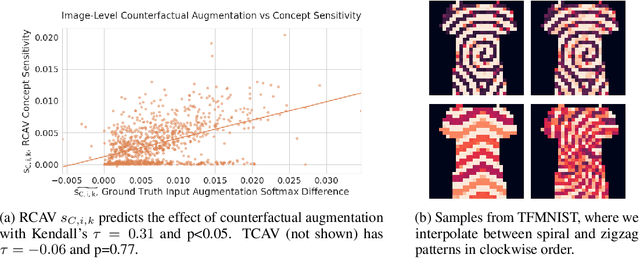

Interpretability methods for image classification assess model trustworthiness by attempting to expose whether the model is systematically biased or attending to the same cues as a human would. Saliency methods for feature attribution dominate the interpretability literature, but these methods do not address semantic concepts such as the textures, colors, or genders of objects within an image. Our proposed Robust Concept Activation Vectors (RCAV) quantifies the effects of semantic concepts on individual model predictions and on model behavior as a whole. RCAV calculates a concept gradient and takes a gradient ascent step to assess model sensitivity to the given concept. By generalizing previous work on concept activation vectors to account for model non-linearity, and by introducing stricter hypothesis testing, we show that RCAV yields interpretations which are both more accurate at the image level and robust at the dataset level. RCAV, like saliency methods, supports the interpretation of individual predictions. To evaluate the practical use of interpretability methods as debugging tools, and the scientific use of interpretability methods for identifying inductive biases (e.g. texture over shape), we construct two datasets and accompanying metrics for realistic benchmarking of semantic interpretability methods. Our benchmarks expose the importance of counterfactual augmentation and negative controls for quantifying the practical usability of interpretability methods.
Global Saliency: Aggregating Saliency Maps to Assess Dataset Artefact Bias
Oct 16, 2019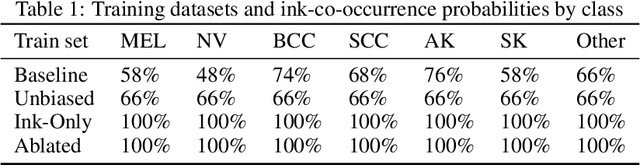
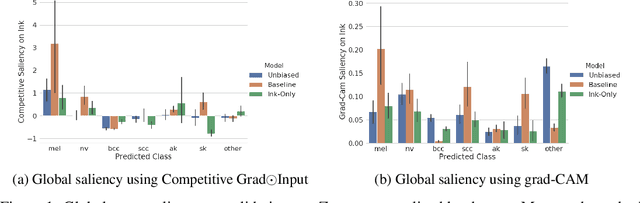
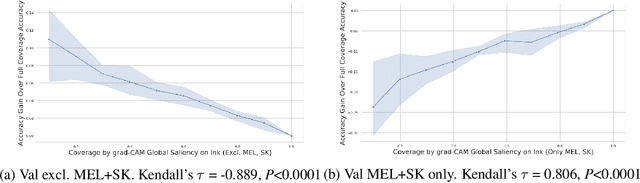
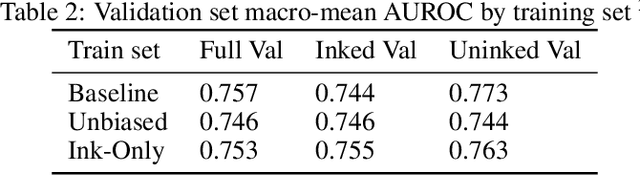
In high-stakes applications of machine learning models, interpretability methods provide guarantees that models are right for the right reasons. In medical imaging, saliency maps have become the standard tool for determining whether a neural model has learned relevant robust features, rather than artefactual noise. However, saliency maps are limited to local model explanation because they interpret predictions on an image-by-image basis. We propose aggregating saliency globally, using semantic segmentation masks, to provide quantitative measures of model bias across a dataset. To evaluate global saliency methods, we propose two metrics for quantifying the validity of saliency explanations. We apply the global saliency method to skin lesion diagnosis to determine the effect of artefacts, such as ink, on model bias.