 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForgive or forget: Understanding the context of hate in audio retrieval systems
Jun 04, 2026Handling toxic retrieval in text-to-audio systems is challenging due to contextual dependencies. Existing strategies (e.g., rephrasing, summarization) risk altering intent or omitting details. We propose a post hoc causal debiasing framework with a sentiment-controlled mediator to preserve semantic relevance while suppressing harmful speech. Our approach is model-agnostic and integrates seamlessly with existing retrieval pipelines. We introduce two variants: Forgive, which re-ranks and filters toxic audio via logit adjustment, and Forget, which generates counterfactual toxic prompts to mitigate harmful retrievals. Experiments show consistent toxicity reduction with minimal loss in retrieval accuracy, improving both safety and reliability.
FORTE: FOL-guided Optimal Refinement for Text-audio rEtrieval
Jun 04, 2026Text-to-audio retrieval has made significant progress with shared embedding models such as CLAP and Pengi, yet they often struggle with fine-grained semantic alignment due to the inherent modality gap between text and audio. In this work, we propose FORTE, a unified framework that integrates structured logical reasoning with parameter-efficient cross-modal alignment to improve retrieval precision. Our approach first transforms queries into first-order logic and refines them via a constrained search that preserves semantic invariance while introducing discriminative attributes. The refined representation is then aligned with audio embeddings using a lightweight projection module, followed by a predicate-aware re-ranking step that enforces logical consistency at inference. Extensive experiments on AudioCaps and Clotho demonstrate consistent improvements over strong baselines, particularly in challenging fine-grained scenarios. Our results highlight the effectiveness of combining symbolic reasoning with representation learning for cross-modal retrieval.
RECIPER: A Dual-View Retrieval Pipeline for Procedure-Oriented Materials Question Answering
Apr 13, 2026Retrieving procedure-oriented evidence from materials science papers is difficult because key synthesis details are often scattered across long, context-heavy documents and are not well captured by paragraph-only dense retrieval. We present RECIPER, a dual-view retrieval pipeline that indexes both paragraph-level context and compact large language model-extracted procedural summaries, then combines the two candidate streams with lightweight lexical reranking. Across four dense retrieval backbones, RECIPER consistently improves early-rank retrieval over paragraph-only dense retrieval, achieving average gains of +3.73 in Recall@1, +2.85 in nDCG@10, and +3.13 in MRR. With BGE-large-en-v1.5, it reaches 86.82%, 97.07%, and 97.85% on Recall@1, Recall@5, and Recall@10, respectively. We further observe improved downstream question answering under automatic metrics, suggesting that procedural summaries can serve as a useful complementary retrieval signal for procedure-oriented materials question answering. Code and data are available at https://github.com/ReaganWu/RECIPER.
FLAG-4D: Flow-Guided Local-Global Dual-Deformation Model for 4D Reconstruction
Feb 09, 2026We introduce FLAG-4D, a novel framework for generating novel views of dynamic scenes by reconstructing how 3D Gaussian primitives evolve through space and time. Existing methods typically rely on a single Multilayer Perceptron (MLP) to model temporal deformations, and they often struggle to capture complex point motions and fine-grained dynamic details consistently over time, especially from sparse input views. Our approach, FLAG-4D, overcomes this by employing a dual-deformation network that dynamically warps a canonical set of 3D Gaussians over time into new positions and anisotropic shapes. This dual-deformation network consists of an Instantaneous Deformation Network (IDN) for modeling fine-grained, local deformations and a Global Motion Network (GMN) for capturing long-range dynamics, refined through mutual learning. To ensure these deformations are both accurate and temporally smooth, FLAG-4D incorporates dense motion features from a pretrained optical flow backbone. We fuse these motion cues from adjacent timeframes and use a deformation-guided attention mechanism to align this flow information with the current state of each evolving 3D Gaussian. Extensive experiments demonstrate that FLAG-4D achieves higher-fidelity and more temporally coherent reconstructions with finer detail preservation than state-of-the-art methods.
Causal-Ex: Causal Graph-based Micro and Macro Expression Spotting
Mar 12, 2025



Detecting concealed emotions within apparently normal expressions is crucial for identifying potential mental health issues and facilitating timely support and intervention. The task of spotting macro and micro-expressions involves predicting the emotional timeline within a video, accomplished by identifying the onset, apex, and offset frames of the displayed emotions. Utilizing foundational facial muscle movement cues, known as facial action units, boosts the accuracy. However, an overlooked challenge from previous research lies in the inadvertent integration of biases into the training model. These biases arising from datasets can spuriously link certain action unit movements to particular emotion classes. We tackle this issue by novel replacement of action unit adjacency information with the action unit causal graphs. This approach aims to identify and eliminate undesired spurious connections, retaining only unbiased information for classification. Our model, named Causal-Ex (Causal-based Expression spotting), employs a rapid causal inference algorithm to construct a causal graph of facial action units. This enables us to select causally relevant facial action units. Our work demonstrates improvement in overall F1-scores compared to state-of-the-art approaches with 0.388 on CAS(ME)^2 and 0.3701 on SAMM-Long Video datasets.
Denoising via Repainting: an image denoising method using layer wise medical image repainting
Mar 11, 2025



Medical image denoising is essential for improving the reliability of clinical diagnosis and guiding subsequent image-based tasks. In this paper, we propose a multi-scale approach that integrates anisotropic Gaussian filtering with progressive Bezier-path redrawing. Our method constructs a scale-space pyramid to mitigate noise while preserving critical structural details. Starting at the coarsest scale, we segment partially denoised images into coherent components and redraw each using a parametric Bezier path with representative color. Through iterative refinements at finer scales, small and intricate structures are accurately reconstructed, while large homogeneous regions remain robustly smoothed. We employ both mean square error and self-intersection constraints to maintain shape coherence during path optimization. Empirical results on multiple MRI datasets demonstrate consistent improvements in PSNR and SSIM over competing methods. This coarse-to-fine framework offers a robust, data-efficient solution for cross-domain denoising, reinforcing its potential clinical utility and versatility. Future work extends this technique to three-dimensional data.
C4Synth: Cross-Caption Cycle-Consistent Text-to-Image Synthesis
Sep 20, 2018
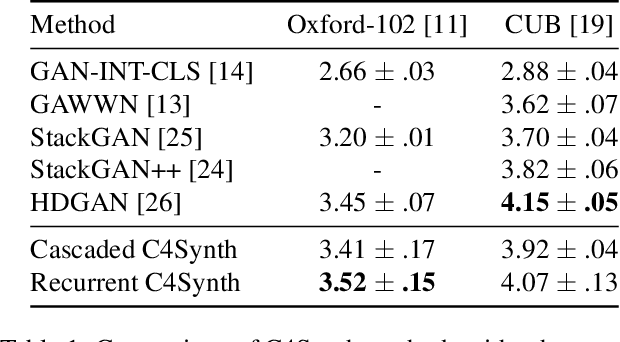
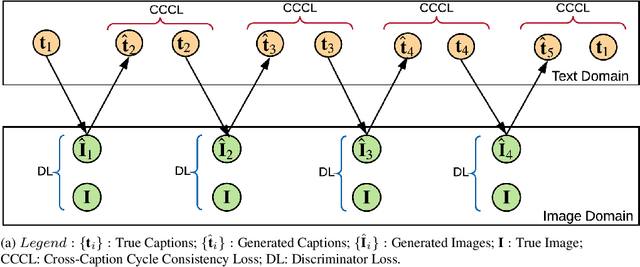
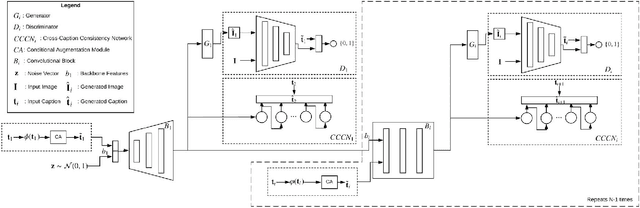
Generating an image from its description is a challenging task worth solving because of its numerous practical applications ranging from image editing to virtual reality. All existing methods use one single caption to generate a plausible image. A single caption by itself, can be limited, and may not be able to capture the variety of concepts and behavior that may be present in the image. We propose two deep generative models that generate an image by making use of multiple captions describing it. This is achieved by ensuring 'Cross-Caption Cycle Consistency' between the multiple captions and the generated image(s). We report quantitative and qualitative results on the standard Caltech-UCSD Birds (CUB) and Oxford-102 Flowers datasets to validate the efficacy of the proposed approach.