 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat-Where Transformer: A Slot-Centric Visual Backbone for Concurrent Representation and Localization
May 12, 2026Many image understanding tasks involve identifying what is present and where it appears. However, tasks that address where, such as object discovery, detection, and segmentation, are often considerably more complex than image classification, which primarily focuses on what. One possible reason is that classification-oriented backbones tend to emphasize semantic information about what, while implicitly entangling or suppressing information about where. In this work, we focus on an inductive bias termed what-where separation, which encourages models to represent object appearance and spatial location in a decomposed manner. To incorporate this bias throughout an attentive backbone in the style of Vision Transformer (ViT), we propose the What-Where Transformer (WWT). Our method introduces two key novel designs: (1) it treats tokens as representations of what and attention maps as representations of where, and processes them in concurrent feed-forward modules via a multi-stream, slot-based architecture; (2) it reuses both the final-layer tokens and attention maps for downstream tasks, and directly exposes them to gradients derived from task losses, thereby facilitating more effective and explicit learning of localization. We demonstrate that even under standard single-label classification-based supervision on ImageNet, WWT exhibits emergent multiple object discovery directly from raw attention maps, rather than via additional postprocessing such as token clustering. Furthermore, WWT achieves superior performance compared to ViT-based methods on zero-shot object discovery and weakly supervised semantic segmentation, and it is transferable to various localization setups with minimal modifications. Code will be published after acceptance.
Teacher-Guided Routing for Sparse Vision Mixture-of-Experts
Apr 23, 2026Recent progress in deep learning has been driven by increasingly large-scale models, but the resulting computational cost has become a critical bottleneck. Sparse Mixture of Experts (MoE) offers an effective solution by activating only a small subset of experts for each input, achieving high scalability without sacrificing inference speed. Although effective, sparse MoE training exhibits characteristic optimization difficulties. Because the router receives informative gradients only through the experts selected in the forward pass, it suffers from gradient blocking and obtains little information from unselected routes. This limited, highly localized feedback makes it difficult for the router to learn appropriate expert-selection scores and often leads to unstable routing dynamics, such as fluctuating expert assignments during training. To address this issue, we propose TGR-MoE: Teacher-Guided Routing for Sparse Vision Mixture-of-Experts, a simple yet effective method that stabilizes router learning using supervision derived from a pretrained dense teacher model. TGR-MoE constructs a teacher router from the teacher's intermediate representations and uses its routing outputs as pseudo-supervision for the student router, suppressing frequent routing fluctuations during training and enabling knowledge-guided expert selection from the early stages of training. Extensive experiments on ImageNet-1K and CIFAR-100 demonstrate that TGR consistently improves both accuracy and routing consistency, while maintaining stable training even under highly sparse configurations.
VASCAR: Content-Aware Layout Generation via Visual-Aware Self-Correction
Dec 05, 2024



Large language models (LLMs) have proven effective for layout generation due to their ability to produce structure-description languages, such as HTML or JSON, even without access to visual information. Recently, LLM providers have evolved these models into large vision-language models (LVLM), which shows prominent multi-modal understanding capabilities. Then, how can we leverage this multi-modal power for layout generation? To answer this, we propose Visual-Aware Self-Correction LAyout GeneRation (VASCAR) for LVLM-based content-aware layout generation. In our method, LVLMs iteratively refine their outputs with reference to rendered layout images, which are visualized as colored bounding boxes on poster backgrounds. In experiments, we demonstrate that our method combined with the Gemini. Without any additional training, VASCAR achieves state-of-the-art (SOTA) layout generation quality outperforming both existing layout-specific generative models and other LLM-based methods.
Constant Rate Schedule: Constant-Rate Distributional Change for Efficient Training and Sampling in Diffusion Models
Nov 19, 2024



We propose a noise schedule that ensures a constant rate of change in the probability distribution of diffused data throughout the diffusion process. To obtain this noise schedule, we measure the rate of change in the probability distribution of the forward process and use it to determine the noise schedule before training diffusion models. The functional form of the noise schedule is automatically determined and tailored to each dataset and type of diffusion model. We evaluate the effectiveness of our noise schedule on unconditional and class-conditional image generation tasks using the LSUN (bedroom/church/cat/horse), ImageNet, and FFHQ datasets. Through extensive experiments, we confirmed that our noise schedule broadly improves the performance of the diffusion models regardless of the dataset, sampler, number of function evaluations, or type of diffusion model.
Attention as Annotation: Generating Images and Pseudo-masks for Weakly Supervised Semantic Segmentation with Diffusion
Sep 04, 2023Although recent advancements in diffusion models enabled high-fidelity and diverse image generation, training of discriminative models largely depends on collections of massive real images and their manual annotation. Here, we present a training method for semantic segmentation that neither relies on real images nor manual annotation. The proposed method {\it attn2mask} utilizes images generated by a text-to-image diffusion model in combination with its internal text-to-image cross-attention as supervisory pseudo-masks. Since the text-to-image generator is trained with image-caption pairs but without pixel-wise labels, attn2mask can be regarded as a weakly supervised segmentation method overall. Experiments show that attn2mask achieves promising results in PASCAL VOC for not using real training data for segmentation at all, and it is also useful to scale up segmentation to a more-class scenario, i.e., ImageNet segmentation. It also shows adaptation ability with LoRA-based fine-tuning, which enables the transfer to a distant domain i.e., Cityscapes.
Ladder Siamese Network: a Method and Insights for Multi-level Self-Supervised Learning
Nov 25, 2022



Siamese-network-based self-supervised learning (SSL) suffers from slow convergence and instability in training. To alleviate this, we propose a framework to exploit intermediate self-supervisions in each stage of deep nets, called the Ladder Siamese Network. Our self-supervised losses encourage the intermediate layers to be consistent with different data augmentations to single samples, which facilitates training progress and enhances the discriminative ability of the intermediate layers themselves. While some existing work has already utilized multi-level self supervisions in SSL, ours is different in that 1) we reveal its usefulness with non-contrastive Siamese frameworks in both theoretical and empirical viewpoints, and 2) ours improves image-level classification, instance-level detection, and pixel-level segmentation simultaneously. Experiments show that the proposed framework can improve BYOL baselines by 1.0% points in ImageNet linear classification, 1.2% points in COCO detection, and 3.1% points in PASCAL VOC segmentation. In comparison with the state-of-the-art methods, our Ladder-based model achieves competitive and balanced performances in all tested benchmarks without causing large degradation in one.
Context-Free TextSpotter for Real-Time and Mobile End-to-End Text Detection and Recognition
Jun 10, 2021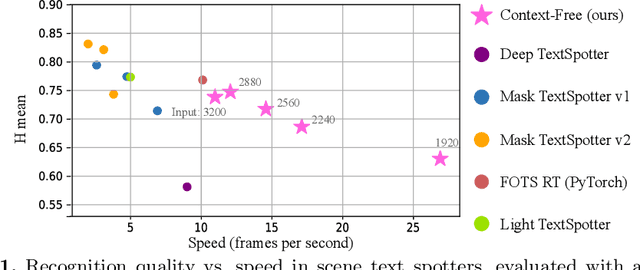
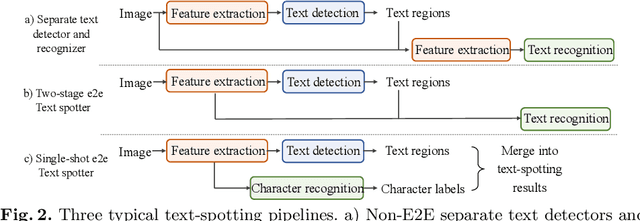
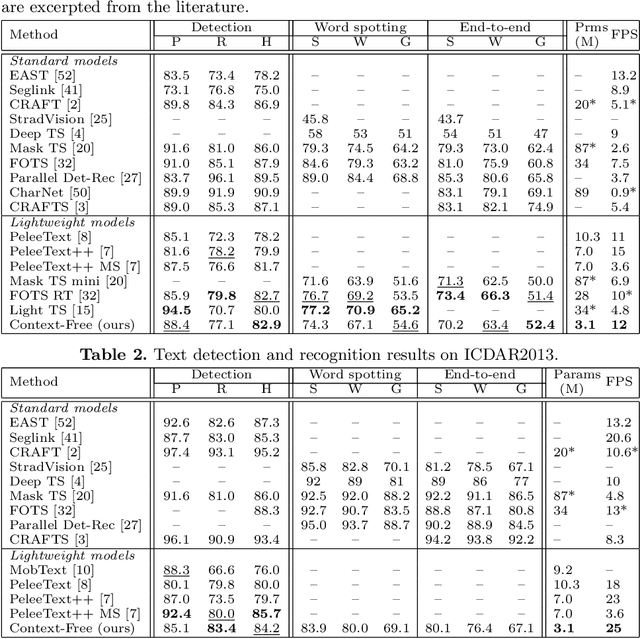
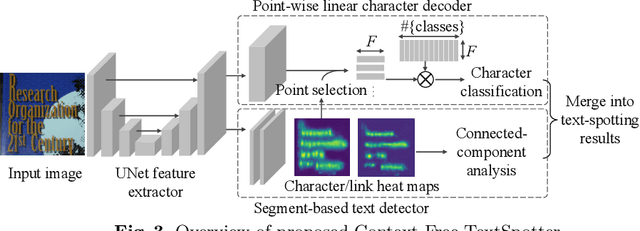
In the deployment of scene-text spotting systems on mobile platforms, lightweight models with low computation are preferable. In concept, end-to-end (E2E) text spotting is suitable for such purposes because it performs text detection and recognition in a single model. However, current state-of-the-art E2E methods rely on heavy feature extractors, recurrent sequence modellings, and complex shape aligners to pursue accuracy, which means their computations are still heavy. We explore the opposite direction: How far can we go without bells and whistles in E2E text spotting? To this end, we propose a text-spotting method that consists of simple convolutions and a few post-processes, named Context-Free TextSpotter. Experiments using standard benchmarks show that Context-Free TextSpotter achieves real-time text spotting on a GPU with only three million parameters, which is the smallest and fastest among existing deep text spotters, with an acceptable transcription quality degradation compared to heavier ones. Further, we demonstrate that our text spotter can run on a smartphone with affordable latency, which is valuable for building stand-alone OCR applications.
Finding a Needle in a Haystack: Tiny Flying Object Detection in 4K Videos using a Joint Detection-and-Tracking Approach
May 18, 2021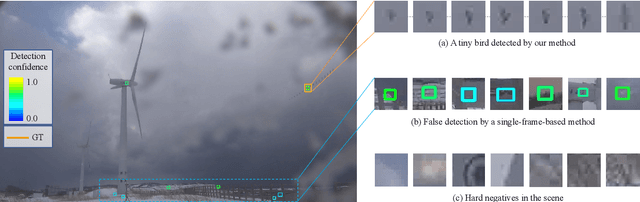
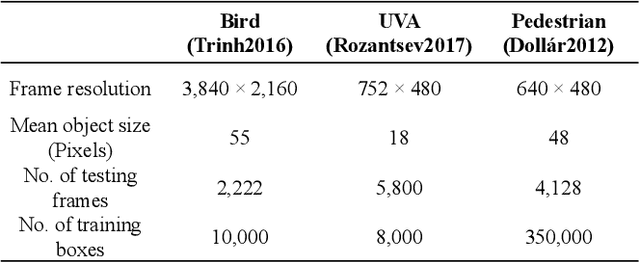

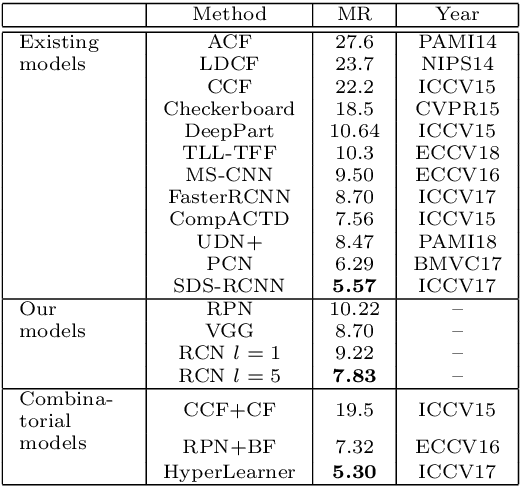
Detecting tiny objects in a high-resolution video is challenging because the visual information is little and unreliable. Specifically, the challenge includes very low resolution of the objects, MPEG artifacts due to compression and a large searching area with many hard negatives. Tracking is equally difficult because of the unreliable appearance, and the unreliable motion estimation. Luckily, we found that by combining this two challenging tasks together, there will be mutual benefits. Following the idea, in this paper, we present a neural network model called the Recurrent Correlational Network, where detection and tracking are jointly performed over a multi-frame representation learned through a single, trainable, and end-to-end network. The framework exploits a convolutional long short-term memory network for learning informative appearance changes for detection, while the learned representation is shared in tracking for enhancing its performance. In experiments with datasets containing images of scenes with small flying objects, such as birds and unmanned aerial vehicles, the proposed method yielded consistent improvements in detection performance over deep single-frame detectors and existing motion-based detectors. Furthermore, our network performs as well as state-of-the-art generic object trackers when it was evaluated as a tracker on a bird image dataset.
Hybrid Loss for Learning Single-Image-based HDR Reconstruction
Dec 18, 2018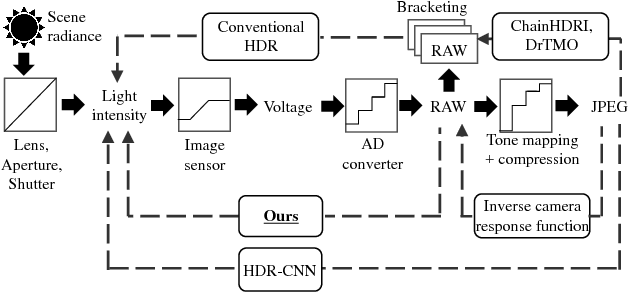
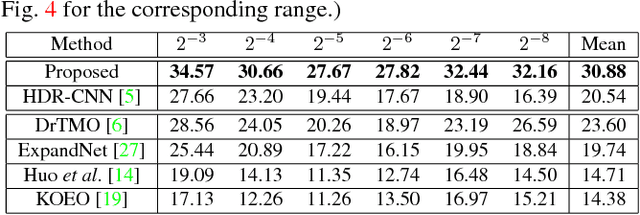
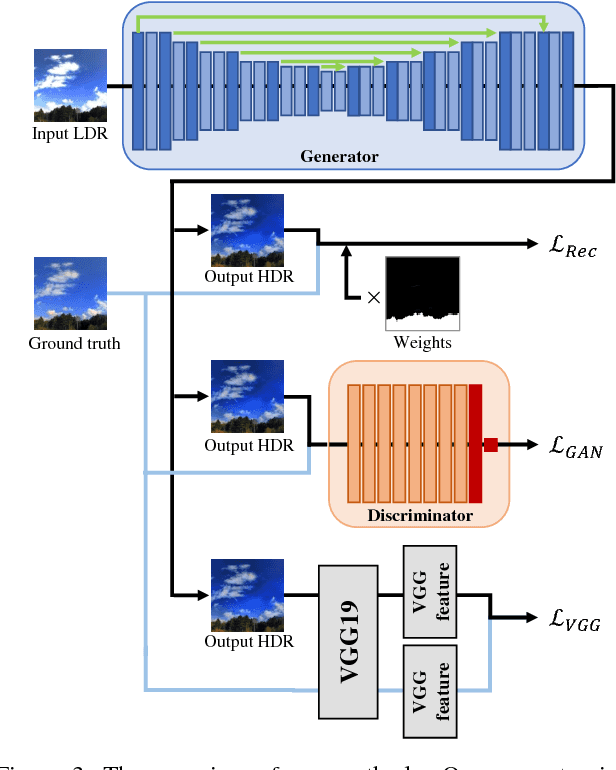
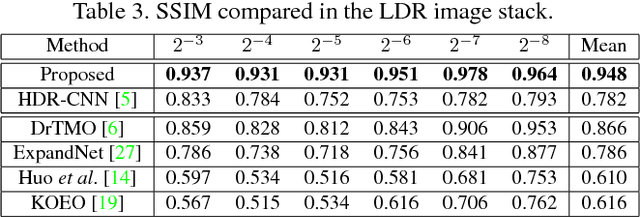
This paper tackles high-dynamic-range (HDR) image reconstruction given only a single low-dynamic-range (LDR) image as input. While the existing methods focus on minimizing the mean-squared-error (MSE) between the target and reconstructed images, we minimize a hybrid loss that consists of perceptual and adversarial losses in addition to HDR-reconstruction loss. The reconstruction loss instead of MSE is more suitable for HDR since it puts more weight on both over- and under- exposed areas. It makes the reconstruction faithful to the input. Perceptual loss enables the networks to utilize knowledge about objects and image structure for recovering the intensity gradients of saturated and grossly quantized areas. Adversarial loss helps to select the most plausible appearance from multiple solutions. The hybrid loss that combines all the three losses is calculated in logarithmic space of image intensity so that the outputs retain a large dynamic range and meanwhile the learning becomes tractable. Comparative experiments conducted with other state-of-the-art methods demonstrated that our method produces a leap in image quality.
Classification-Reconstruction Learning for Open-Set Recognition
Dec 17, 2018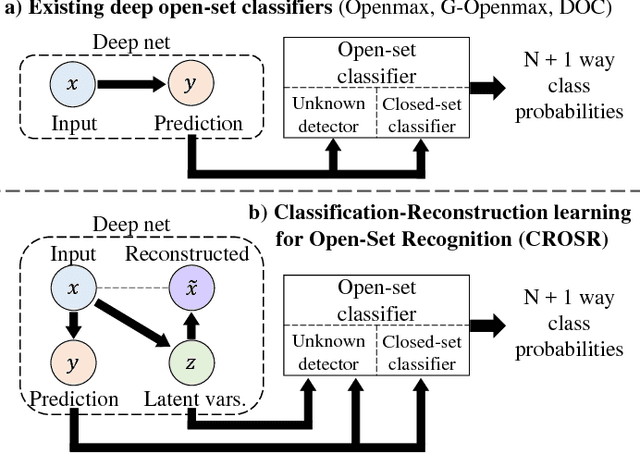
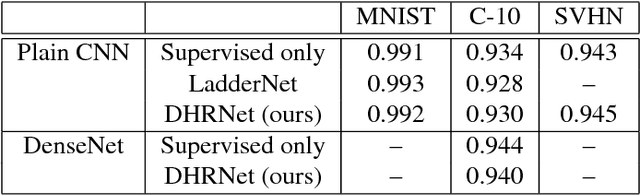
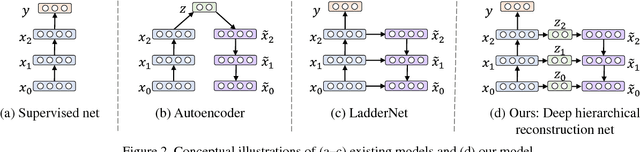
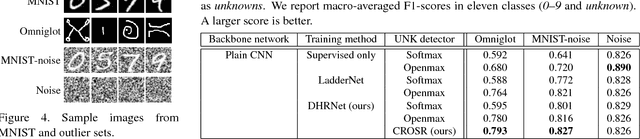
Open-set classification is a problem of handling `unknown' classes that are not contained in the training dataset, whereas traditional classifiers assume that only known classes appear in the test environment. Existing open-set classifiers rely on deep networks trained in a supervised manner on known classes in the training set; this causes specialization of learned representations to known classes and makes it hard to distinguish unknowns from knowns. In contrast, we train networks for joint classification and reconstruction of input data. This enhances the learned representation so as to preserve information useful for separating unknowns from knowns, as well as to discriminate classes of knowns. Our novel Classification-Reconstruction learning for Open-Set Recognition (CROSR) utilizes latent representations for reconstruction and enables robust unknown detection without harming the known-class classification accuracy. Extensive experiments reveal that the proposed method outperforms existing deep open-set classifiers in multiple standard datasets and is robust to diverse outliers.