 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ViBERTgrid: A Jointly Trained Multi-Modal 2D Document Representation for Key Information Extraction from Documents
May 25, 2021
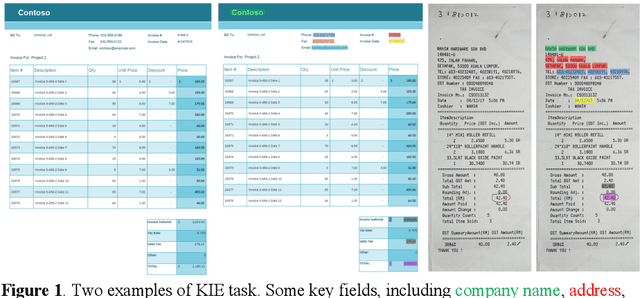
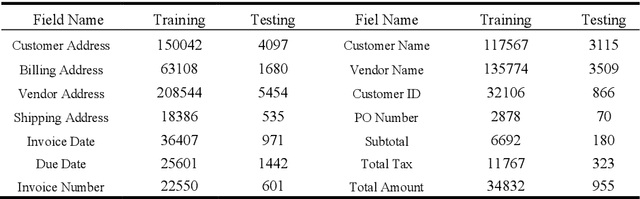
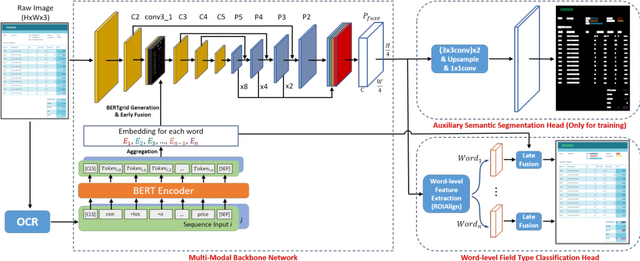
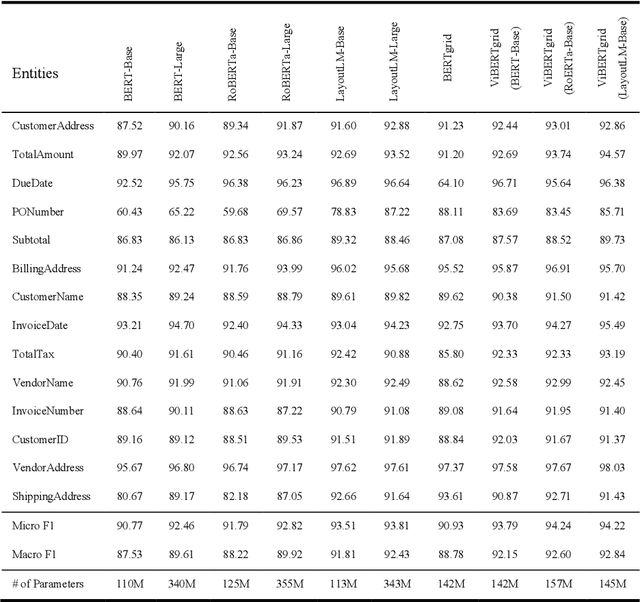
Recent grid-based document representations like BERTgrid allow the simultaneous encoding of the textual and layout information of a document in a 2D feature map so that state-of-the-art image segmentation and/or object detection models can be straightforwardly leveraged to extract key information from documents. However, such methods have not achieved comparable performance to state-of-the-art sequence- and graph-based methods such as LayoutLM and PICK yet. In this paper, we propose a new multi-modal backbone network by concatenating a BERTgrid to an intermediate layer of a CNN model, where the input of CNN is a document image and the BERTgrid is a grid of word embeddings, to generate a more powerful grid-based document representation, named ViBERTgrid. Unlike BERTgrid, the parameters of BERT and CNN in our multimodal backbone network are trained jointly. Our experimental results demonstrate that this joint training strategy improves significantly the representation ability of ViBERTgrid. Consequently, our ViBERTgrid-based key information extraction approach has achieved state-of-the-art performance on real-world datasets.
Scene Text Image Super-Resolution in the Wild
May 07, 2020
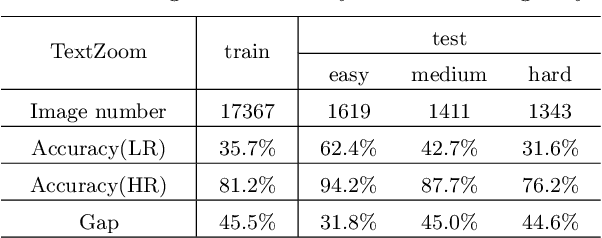
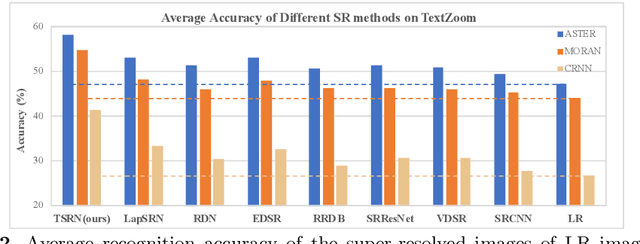
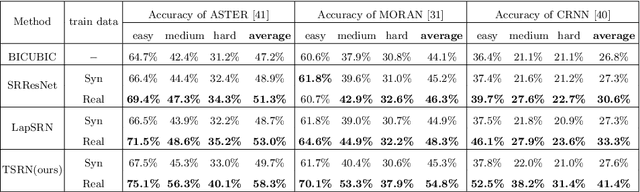
Low-resolution text images are often seen in natural scenes such as documents captured by mobile phones. Recognizing low-resolution text images is challenging because they lose detailed content information, leading to poor recognition accuracy. An intuitive solution is to introduce super-resolution (SR) techniques as pre-processing. However, previous single image super-resolution (SISR) methods are trained on synthetic low-resolution images (e.g.Bicubic down-sampling), which is simple and not suitable for real low-resolution text recognition. To this end, we pro-pose a real scene text SR dataset, termed TextZoom. It contains paired real low-resolution and high-resolution images which are captured by cameras with different focal length in the wild. It is more authentic and challenging than synthetic data, as shown in Fig. 1. We argue improv-ing the recognition accuracy is the ultimate goal for Scene Text SR. In this purpose, a new Text Super-Resolution Network termed TSRN, with three novel modules is developed. (1) A sequential residual block is proposed to extract the sequential information of the text images. (2) A boundary-aware loss is designed to sharpen the character boundaries. (3) A central alignment module is proposed to relieve the misalignment problem in TextZoom. Extensive experiments on TextZoom demonstrate that our TSRN largely improves the recognition accuracy by over 13%of CRNN, and by nearly 9.0% of ASTER and MORAN compared to synthetic SR data. Furthermore, our TSRN clearly outperforms 7 state-of-the-art SR methods in boosting the recognition accuracy of LR images in TextZoom. For example, it outperforms LapSRN by over 5% and 8%on the recognition accuracy of ASTER and CRNN. Our results suggest that low-resolution text recognition in the wild is far from being solved, thus more research effort is needed.
Training deep cross-modality conversion models with a small amount of data and its application to MVCT to kVCT conversion
Jul 12, 2021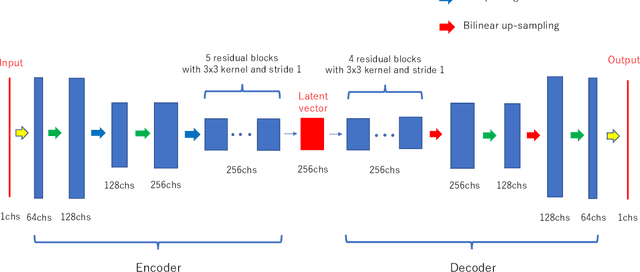
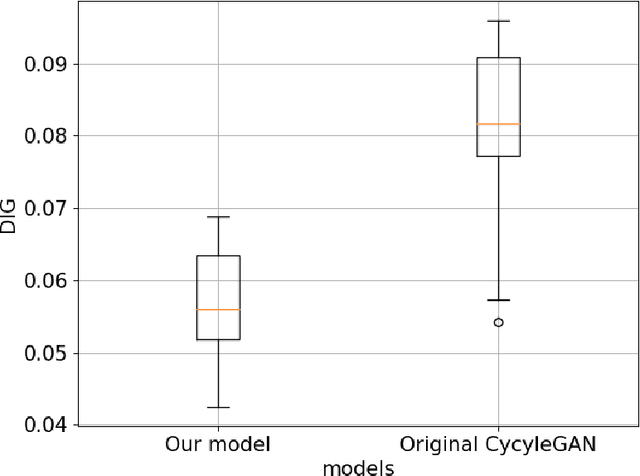
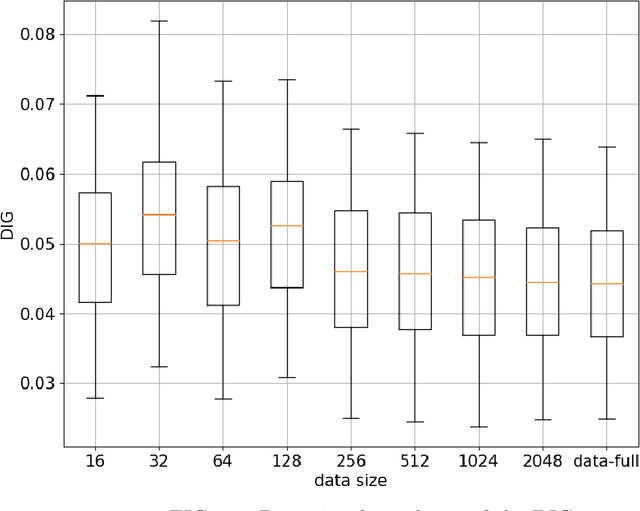
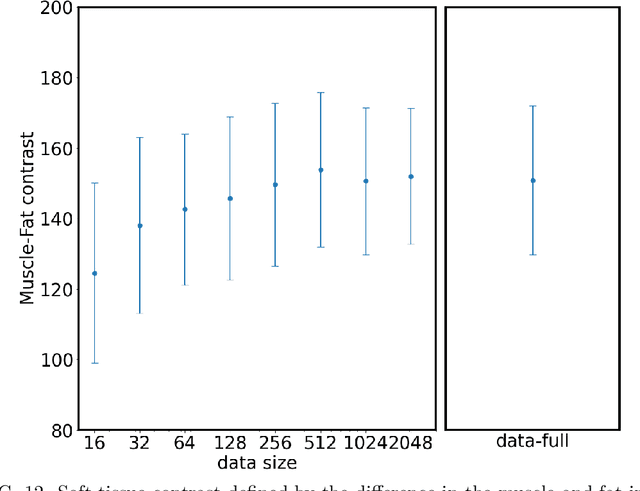
Deep-learning-based image processing has emerged as a valuable tool in recent years owing to its high performance. However, the quality of deep-learning-based methods relies heavily on the amount of training data, and the cost of acquiring a large amount of data is often prohibitive in medical fields. Therefore, we performed CT modality conversion based on deep learning requiring only a small number of unsupervised images. The proposed method is based on generative adversarial networks (GANs) with several extensions tailored for CT images. This method emphasizes the preservation of the structure in the processed images and reduction in the amount of training data. This method was applied to realize the conversion of mega-voltage computed tomography (MVCT) to kilo-voltage computed tomography (kVCT) images. Training was performed using several datasets acquired from patients with head and neck cancer. The size of the datasets ranged from 16 slices (for two patients) to 2745 slices (for 137 patients) of MVCT and 2824 slices of kVCT for 98 patients. The quality of the processed MVCT images was considerably enhanced, and the structural changes in the images were minimized. With an increase in the size of training data, the image quality exhibited a satisfactory convergence from a few hundred slices. In addition to statistical and visual evaluations, these results were clinically evaluated by medical doctors in terms of the accuracy of contouring. We developed an MVCT to kVCT conversion model based on deep learning, which can be trained using a few hundred unpaired images. The stability of the model against the change in the data size was demonstrated. This research promotes the reliable use of deep learning in clinical medicine by partially answering the commonly asked questions: "Is our data enough? How much data must we prepare?"
Multiple Pretext-Task for Self-Supervised Learning via Mixing Multiple Image Transformations
Dec 25, 2019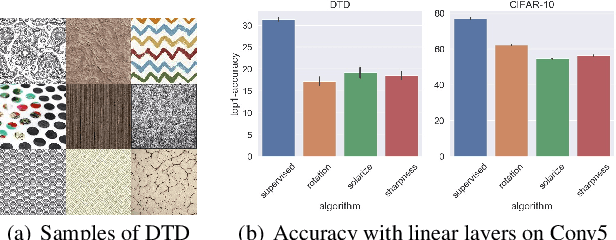


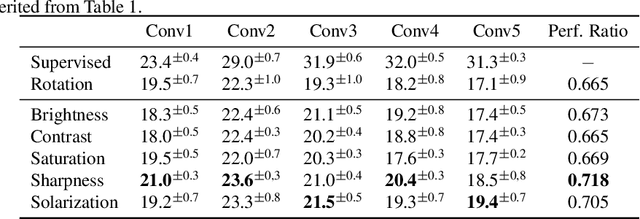
Self-supervised learning is one of the most promising approaches to learn representations capturing semantic features in images without any manual annotation cost. To learn useful representations, a self-supervised model solves a pretext-task, which is defined by data itself. Among a number of pretext-tasks, the rotation prediction task (Rotation) achieves better representations for solving various target tasks despite its simplicity of the implementation. However, we found that Rotation can fail to capture semantic features related to image textures and colors. To tackle this problem, we introduce a learning technique called multiple pretext-task for self-supervised learning (MP-SSL), which solves multiple pretext-task in addition to Rotation simultaneously. In order to capture features of textures and colors, we employ the transformations of image enhancements (e.g., sharpening and solarizing) as the additional pretext-tasks. MP-SSL efficiently trains a model by leveraging a Frank-Wolfe based multi-task training algorithm. Our experimental results show MP-SSL models outperform Rotation on multiple standard benchmarks and achieve state-of-the-art performance on Places-205.
Robust Mitosis Detection Using a Cascade Mask-RCNN Approach With Domain-Specific Residual Cycle-GAN Data Augmentation
Sep 04, 2021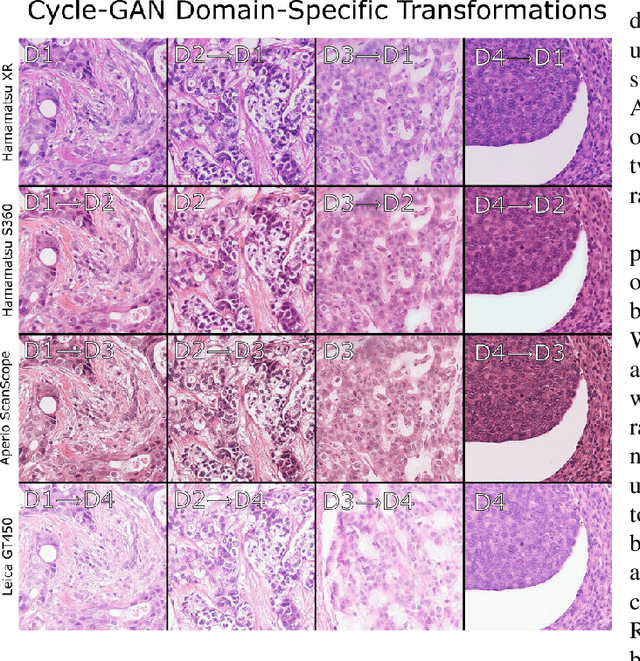
For the MIDOG mitosis detection challenge, we created a cascade algorithm consisting of a Mask-RCNN detector, followed by a classification ensemble consisting of ResNet50 and DenseNet201 to refine detected mitotic candidates. The MIDOG training data consists of 200 frames originating from four scanners, three of which are annotated for mitotic instances with centroid annotations. Our main algorithmic choices are as follows: first, to enhance the generalizability of our detector and classification networks, we use a state-of-the-art residual Cycle-GAN to transform each scanner domain to every other scanner domain. During training, we then randomly load, for each image, one of the four domains. In this way, our networks can learn from the fourth non-annotated scanner domain even if we don't have annotations for it. Second, for training the detector network, rather than using centroid-based fixed-size bounding boxes, we create mitosis-specific bounding boxes. We do this by manually annotating a small selection of mitoses, training a Mask-RCNN on this small dataset, and applying it to the rest of the data to obtain full annotations. We trained the follow-up classification ensemble using only the challenge-provided positive and hard-negative examples. On the preliminary test set, the algorithm scores an F1 score of 0.7578, putting us as the second-place team on the leaderboard.
Neighbourhood-guided Feature Reconstruction for Occluded Person Re-Identification
May 16, 2021
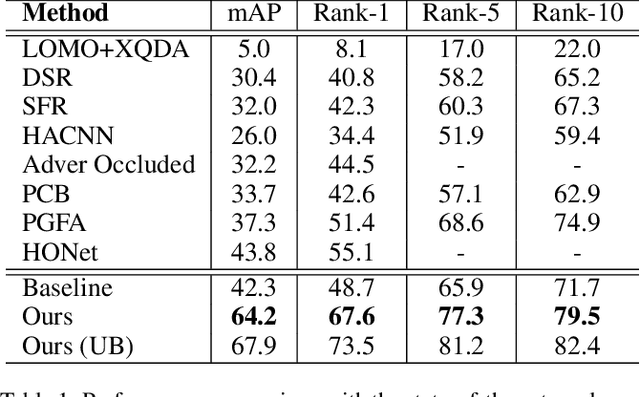
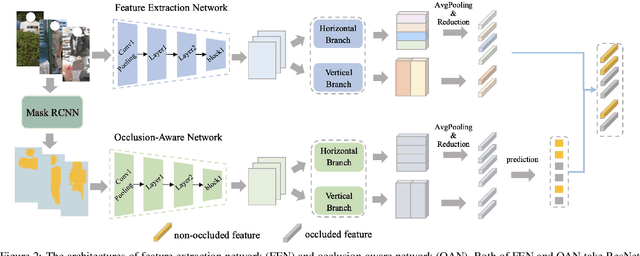
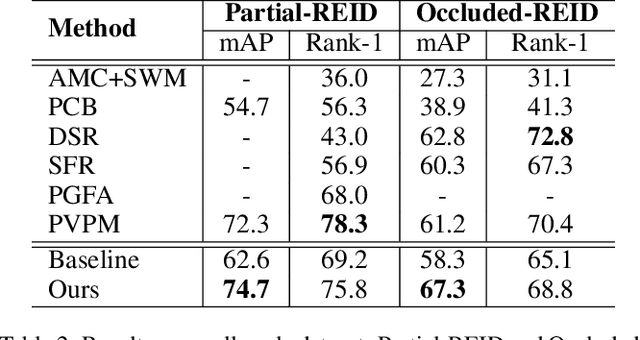
Person images captured by surveillance cameras are often occluded by various obstacles, which lead to defective feature representation and harm person re-identification (Re-ID) performance. To tackle this challenge, we propose to reconstruct the feature representation of occluded parts by fully exploiting the information of its neighborhood in a gallery image set. Specifically, we first introduce a visible part-based feature by body mask for each person image. Then we identify its neighboring samples using the visible features and reconstruct the representation of the full body by an outlier-removable graph neural network with all the neighboring samples as input. Extensive experiments show that the proposed approach obtains significant improvements. In the large-scale Occluded-DukeMTMC benchmark, our approach achieves 64.2% mAP and 67.6% rank-1 accuracy which outperforms the state-of-the-art approaches by large margins, i.e.,20.4% and 12.5%, respectively, indicating the effectiveness of our method on occluded Re-ID problem.
Real-time Detection of Practical Universal Adversarial Perturbations
May 16, 2021

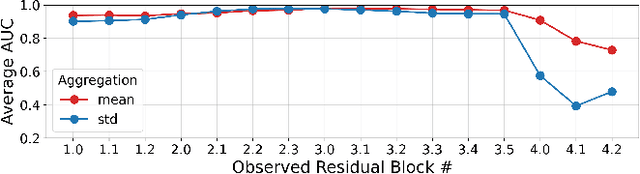
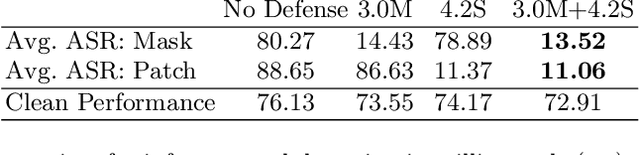
Universal Adversarial Perturbations (UAPs) are a prominent class of adversarial examples that exploit the systemic vulnerabilities and enable physically realizable and robust attacks against Deep Neural Networks (DNNs). UAPs generalize across many different inputs; this leads to realistic and effective attacks that can be applied at scale. In this paper we propose HyperNeuron, an efficient and scalable algorithm that allows for the real-time detection of UAPs by identifying suspicious neuron hyper-activations. Our results show the effectiveness of HyperNeuron on multiple tasks (image classification, object detection), against a wide variety of universal attacks, and in realistic scenarios, like perceptual ad-blocking and adversarial patches. HyperNeuron is able to simultaneously detect both adversarial mask and patch UAPs with comparable or better performance than existing UAP defenses whilst introducing a significantly reduced latency of only 0.86 milliseconds per image. This suggests that many realistic and practical universal attacks can be reliably mitigated in real-time, which shows promise for the robust deployment of machine learning systems.
Representation Learning for Out-Of-Distribution Generalization in Reinforcement Learning
Jul 12, 2021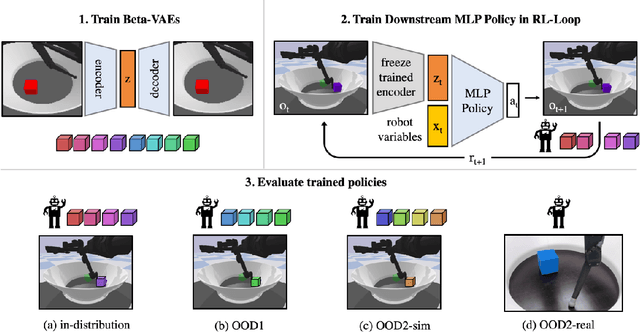
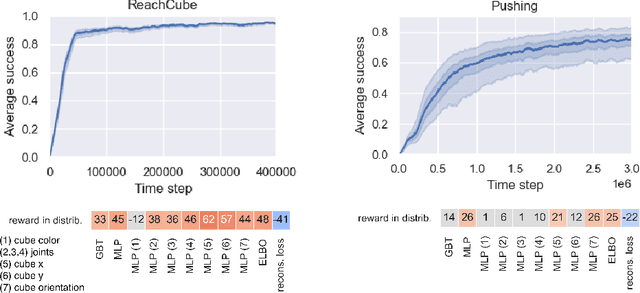
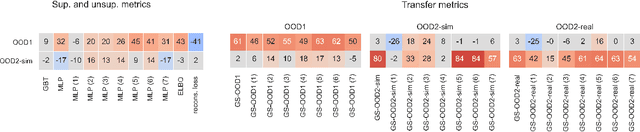
Learning data representations that are useful for various downstream tasks is a cornerstone of artificial intelligence. While existing methods are typically evaluated on downstream tasks such as classification or generative image quality, we propose to assess representations through their usefulness in downstream control tasks, such as reaching or pushing objects. By training over 10,000 reinforcement learning policies, we extensively evaluate to what extent different representation properties affect out-of-distribution (OOD) generalization. Finally, we demonstrate zero-shot transfer of these policies from simulation to the real world, without any domain randomization or fine-tuning. This paper aims to establish the first systematic characterization of the usefulness of learned representations for real-world OOD downstream tasks.
End-to-End Simultaneous Learning of Single-particle Orientation and 3D Map Reconstruction from Cryo-electron Microscopy Data
Jul 07, 2021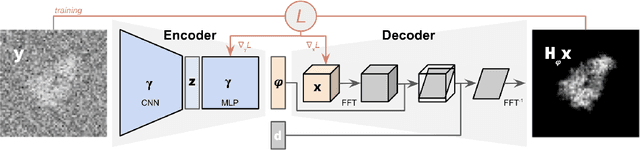
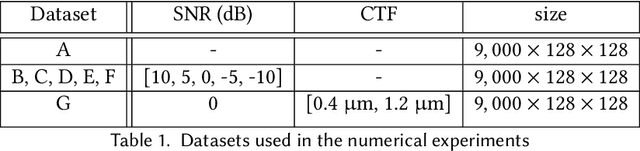
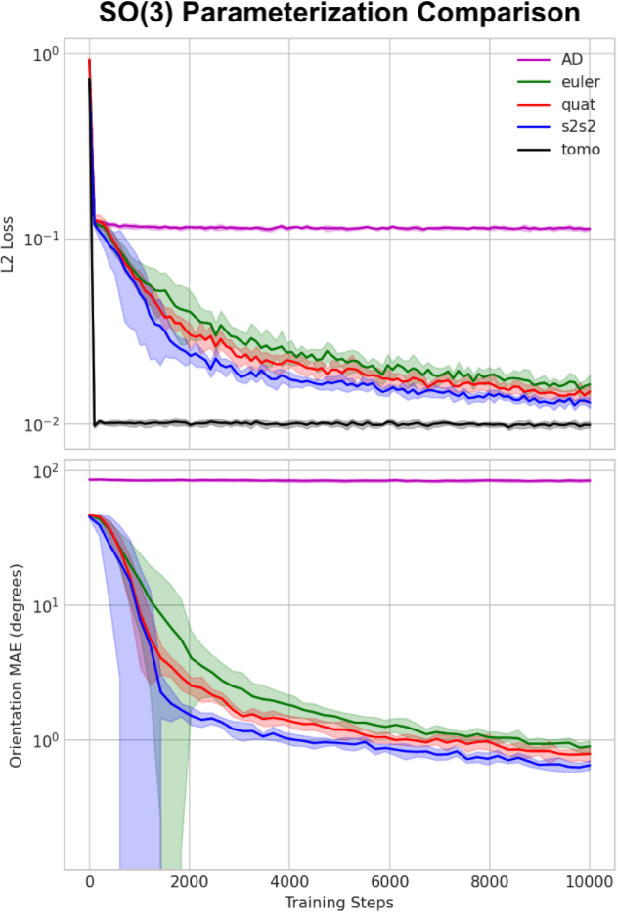
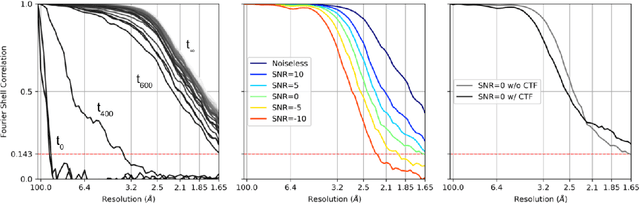
Cryogenic electron microscopy (cryo-EM) provides images from different copies of the same biomolecule in arbitrary orientations. Here, we present an end-to-end unsupervised approach that learns individual particle orientations from cryo-EM data while reconstructing the average 3D map of the biomolecule, starting from a random initialization. The approach relies on an auto-encoder architecture where the latent space is explicitly interpreted as orientations used by the decoder to form an image according to the linear projection model. We evaluate our method on simulated data and show that it is able to reconstruct 3D particle maps from noisy- and CTF-corrupted 2D projection images of unknown particle orientations.
An Image-based Approach of Task-driven Driving Scene Categorization
Mar 10, 2021

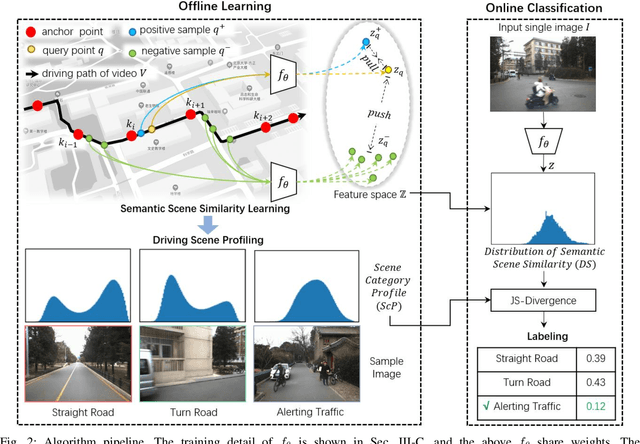
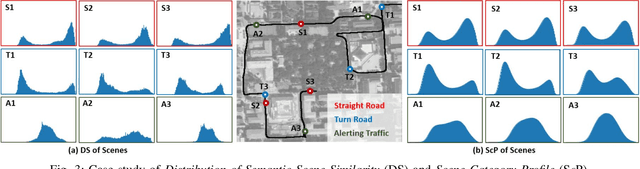
Categorizing driving scenes via visual perception is a key technology for safe driving and the downstream tasks of autonomous vehicles. Traditional methods infer scene category by detecting scene-related objects or using a classifier that is trained on large datasets of fine-labeled scene images. Whereas at cluttered dynamic scenes such as campus or park, human activities are not strongly confined by rules, and the functional attributes of places are not strongly correlated with objects. So how to define, model and infer scene categories is crucial to make the technique really helpful in assisting a robot to pass through the scene. This paper proposes a method of task-driven driving scene categorization using weakly supervised data. Given a front-view video of a driving scene, a set of anchor points is marked by following the decision making of a human driver, where an anchor point is not a semantic label but an indicator meaning the semantic attribute of the scene is different from that of the previous one. A measure is learned to discriminate the scenes of different semantic attributes via contrastive learning, and a driving scene profiling and categorization method is developed based on that measure. Experiments are conducted on a front-view video that is recorded when a vehicle passed through the cluttered dynamic campus of Peking University. The scenes are categorized into straight road, turn road and alerting traffic. The results of semantic scene similarity learning and driving scene categorization are extensively studied, and positive result of scene categorization is 97.17 \% on the learning video and 85.44\% on the video of new scenes.