 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Text Image Super-Resolution in the Wild
Paper and Code

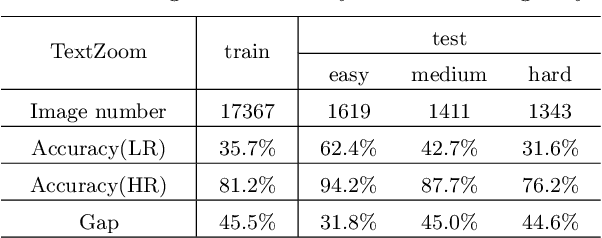
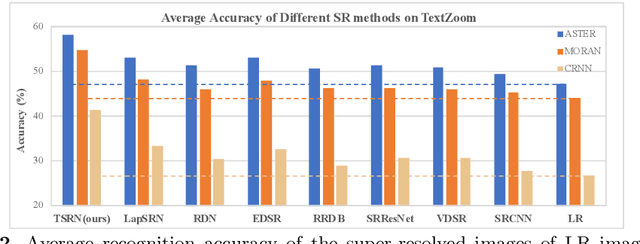
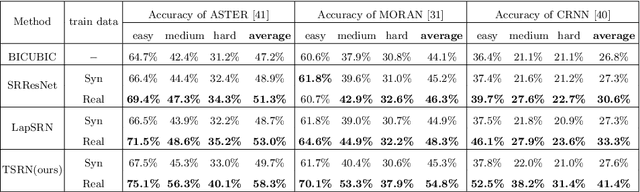
Low-resolution text images are often seen in natural scenes such as documents captured by mobile phones. Recognizing low-resolution text images is challenging because they lose detailed content information, leading to poor recognition accuracy. An intuitive solution is to introduce super-resolution (SR) techniques as pre-processing. However, previous single image super-resolution (SISR) methods are trained on synthetic low-resolution images (e.g.Bicubic down-sampling), which is simple and not suitable for real low-resolution text recognition. To this end, we pro-pose a real scene text SR dataset, termed TextZoom. It contains paired real low-resolution and high-resolution images which are captured by cameras with different focal length in the wild. It is more authentic and challenging than synthetic data, as shown in Fig. 1. We argue improv-ing the recognition accuracy is the ultimate goal for Scene Text SR. In this purpose, a new Text Super-Resolution Network termed TSRN, with three novel modules is developed. (1) A sequential residual block is proposed to extract the sequential information of the text images. (2) A boundary-aware loss is designed to sharpen the character boundaries. (3) A central alignment module is proposed to relieve the misalignment problem in TextZoom. Extensive experiments on TextZoom demonstrate that our TSRN largely improves the recognition accuracy by over 13%of CRNN, and by nearly 9.0% of ASTER and MORAN compared to synthetic SR data. Furthermore, our TSRN clearly outperforms 7 state-of-the-art SR methods in boosting the recognition accuracy of LR images in TextZoom. For example, it outperforms LapSRN by over 5% and 8%on the recognition accuracy of ASTER and CRNN. Our results suggest that low-resolution text recognition in the wild is far from being solved, thus more research effort is needed.