 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Stop Throwing Away Discriminators! Re-using Adversaries for Test-Time Training
Aug 26, 2021


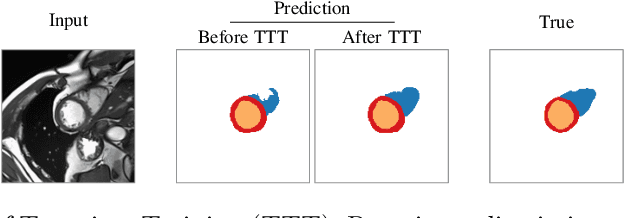

Thanks to their ability to learn data distributions without requiring paired data, Generative Adversarial Networks (GANs) have become an integral part of many computer vision methods, including those developed for medical image segmentation. These methods jointly train a segmentor and an adversarial mask discriminator, which provides a data-driven shape prior. At inference, the discriminator is discarded, and only the segmentor is used to predict label maps on test images. But should we discard the discriminator? Here, we argue that the life cycle of adversarial discriminators should not end after training. On the contrary, training stable GANs produces powerful shape priors that we can use to correct segmentor mistakes at inference. To achieve this, we develop stable mask discriminators that do not overfit or catastrophically forget. At test time, we fine-tune the segmentor on each individual test instance until it satisfies the learned shape prior. Our method is simple to implement and increases model performance. Moreover, it opens new directions for re-using mask discriminators at inference. We release the code used for the experiments at https://vios-s.github.io/adversarial-test-time-training.
Blind image deblurring using class-adapted image priors
Sep 06, 2017
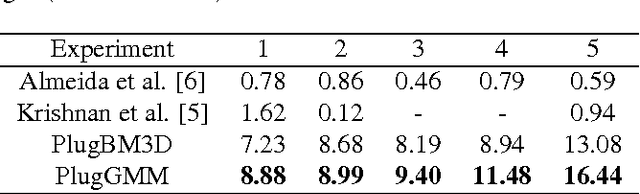

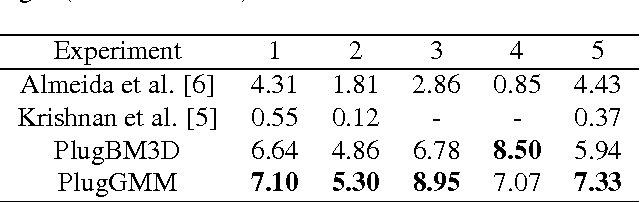
Blind image deblurring (BID) is an ill-posed inverse problem, usually addressed by imposing prior knowledge on the (unknown) image and on the blurring filter. Most of the work on BID has focused on natural images, using image priors based on statistical properties of generic natural images. However, in many applications, it is known that the image being recovered belongs to some specific class (e.g., text, face, fingerprints), and exploiting this knowledge allows obtaining more accurate priors. In this work, we propose a method where a Gaussian mixture model (GMM) is used to learn a class-adapted prior, by training on a dataset of clean images of that class. Experiments show the competitiveness of the proposed method in terms of restoration quality when dealing with images containing text, faces, or fingerprints. Additionally, experiments show that the proposed method is able to handle text images at high noise levels, outperforming state-of-the-art methods specifically designed for BID of text images.
CE-Net: Context Encoder Network for 2D Medical Image Segmentation
Mar 07, 2019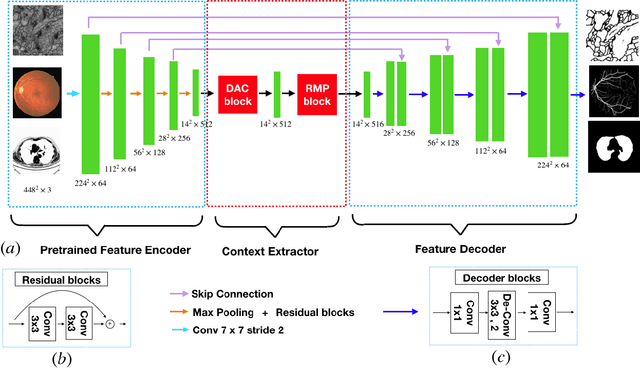
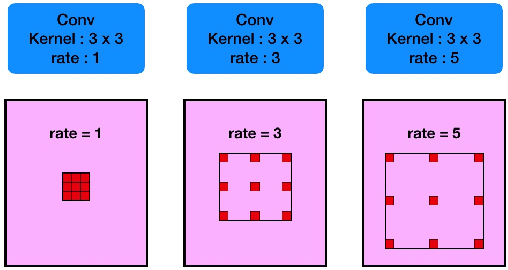
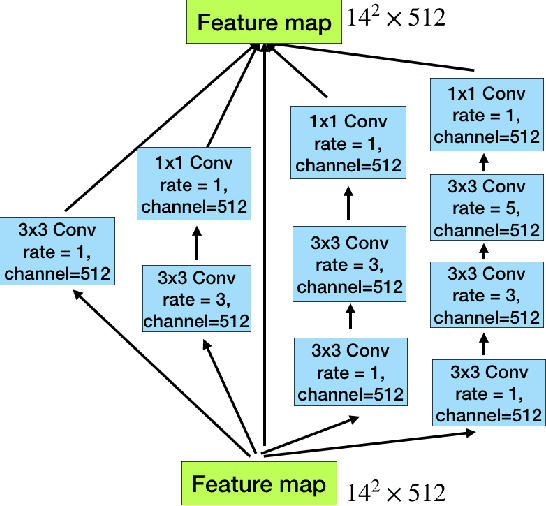
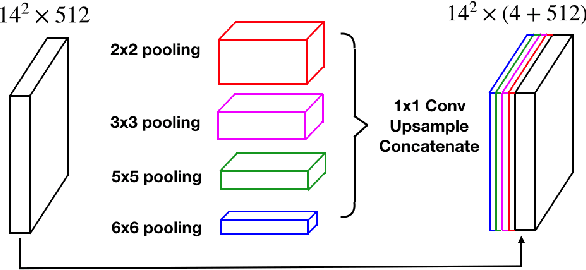
Medical image segmentation is an important step in medical image analysis. With the rapid development of convolutional neural network in image processing, deep learning has been used for medical image segmentation, such as optic disc segmentation, blood vessel detection, lung segmentation, cell segmentation, etc. Previously, U-net based approaches have been proposed. However, the consecutive pooling and strided convolutional operations lead to the loss of some spatial information. In this paper, we propose a context encoder network (referred to as CE-Net) to capture more high-level information and preserve spatial information for 2D medical image segmentation. CE-Net mainly contains three major components: a feature encoder module, a context extractor and a feature decoder module. We use pretrained ResNet block as the fixed feature extractor. The context extractor module is formed by a newly proposed dense atrous convolution (DAC) block and residual multi-kernel pooling (RMP) block. We applied the proposed CE-Net to different 2D medical image segmentation tasks. Comprehensive results show that the proposed method outperforms the original U-Net method and other state-of-the-art methods for optic disc segmentation, vessel detection, lung segmentation, cell contour segmentation and retinal optical coherence tomography layer segmentation.
Multi-Stage Pathological Image Classification using Semantic Segmentation
Oct 10, 2019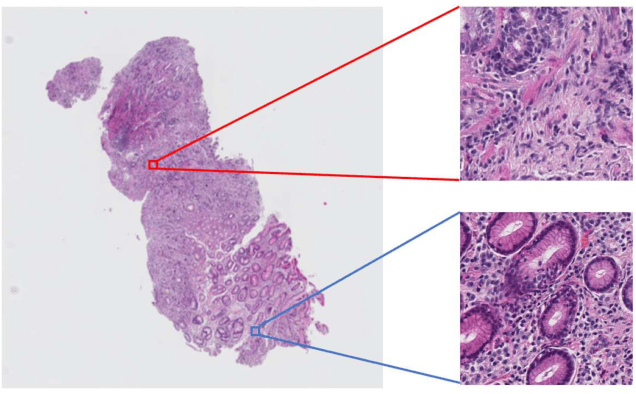
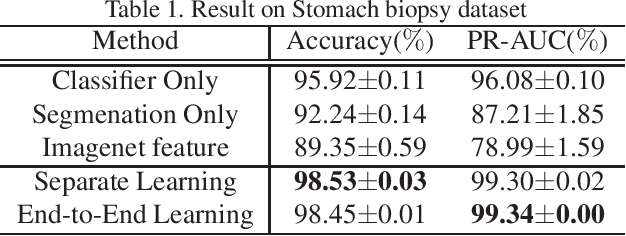
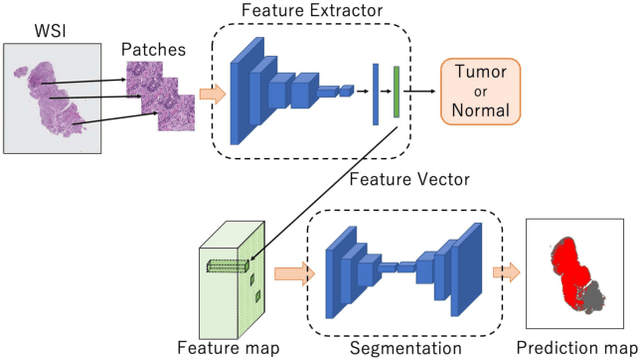
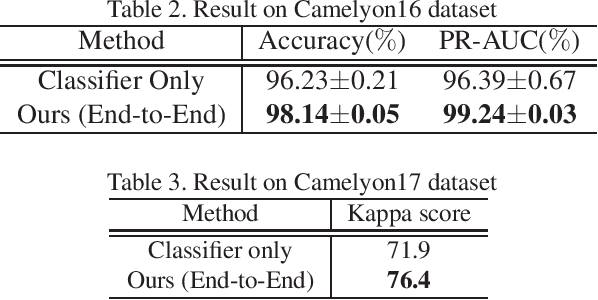
Histopathological image analysis is an essential process for the discovery of diseases such as cancer. However, it is challenging to train CNN on whole slide images (WSIs) of gigapixel resolution considering the available memory capacity. Most of the previous works divide high resolution WSIs into small image patches and separately input them into the model to classify it as a tumor or a normal tissue. However, patch-based classification uses only patch-scale local information but ignores the relationship between neighboring patches. If we consider the relationship of neighboring patches and global features, we can improve the classification performance. In this paper, we propose a new model structure combining the patch-based classification model and whole slide-scale segmentation model in order to improve the prediction performance of automatic pathological diagnosis. We extract patch features from the classification model and input them into the segmentation model to obtain a whole slide tumor probability heatmap. The classification model considers patch-scale local features, and the segmentation model can take global information into account. We also propose a new optimization method that retains gradient information and trains the model partially for end-to-end learning with limited GPU memory capacity. We apply our method to the tumor/normal prediction on WSIs and the classification performance is improved compared with the conventional patch-based method.
Learning to Find Common Objects Across Image Collections
Apr 29, 2019
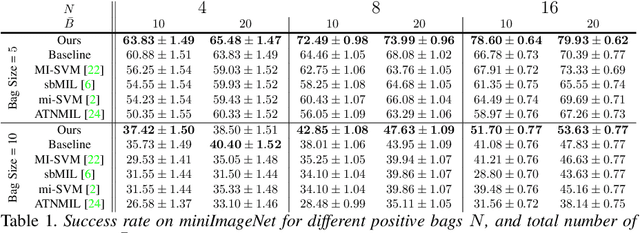
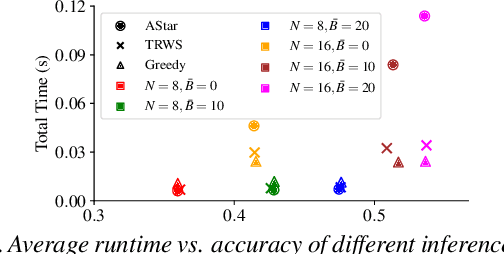
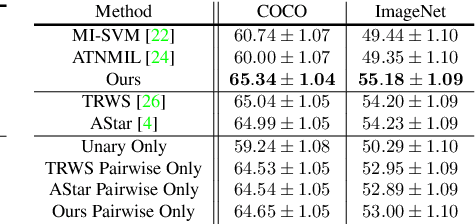
We address the problem of finding a set of images containing a common, but unknown, object category from a collection of image proposals. Our formulation assumes that we are given a collection of bags where each bag is a set of image proposals. Our goal is to select one image from each bag such that the selected images are of the same object category. We model the selection as an energy minimization problem with unary and pairwise potential functions. Inspired by recent few-shot learning algorithms, we propose an approach to learn the potential functions directly from the data. Furthermore, we propose a fast and simple greedy inference algorithm for energy minimization. We evaluate our approach on few-shot common object recognition and object co-localization tasks. Our experiments show that learning the pairwise and unary terms greatly improves the performance of the model over several well-known methods for these tasks. The proposed greedy optimization algorithm achieves performance comparable to state-of-the-art structured inference algorithms while being ~10 times faster. The code is publicly available on https://github.com/haamoon/finding_common_object.
Improved Transformer for High-Resolution GANs
Jun 14, 2021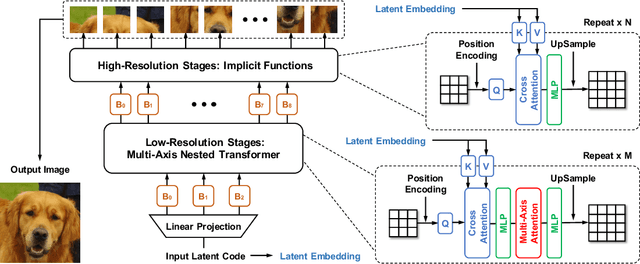
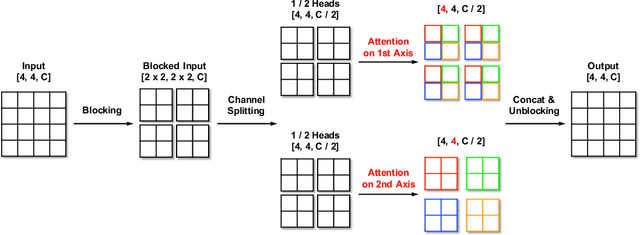
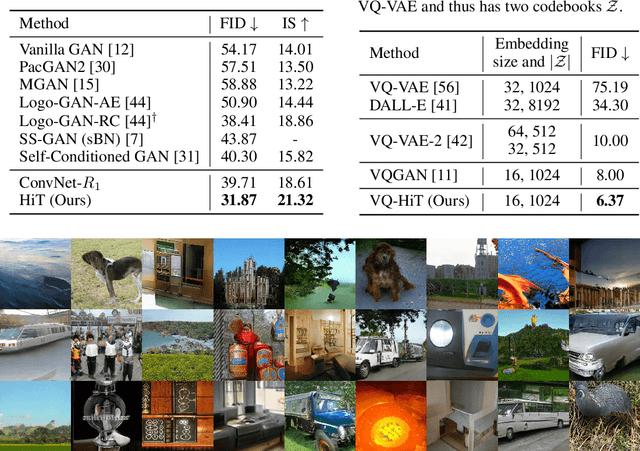

Attention-based models, exemplified by the Transformer, can effectively model long range dependency, but suffer from the quadratic complexity of self-attention operation, making them difficult to be adopted for high-resolution image generation based on Generative Adversarial Networks (GANs). In this paper, we introduce two key ingredients to Transformer to address this challenge. First, in low-resolution stages of the generative process, standard global self-attention is replaced with the proposed multi-axis blocked self-attention which allows efficient mixing of local and global attention. Second, in high-resolution stages, we drop self-attention while only keeping multi-layer perceptrons reminiscent of the implicit neural function. To further improve the performance, we introduce an additional self-modulation component based on cross-attention. The resulting model, denoted as HiT, has a linear computational complexity with respect to the image size and thus directly scales to synthesizing high definition images. We show in the experiments that the proposed HiT achieves state-of-the-art FID scores of 31.87 and 2.95 on unconditional ImageNet $128 \times 128$ and FFHQ $256 \times 256$, respectively, with a reasonable throughput. We believe the proposed HiT is an important milestone for generators in GANs which are completely free of convolutions.
The Influence of Age and Gender Information on the Diagnosis of Diabetic Retinopathy: Based on Neural Networks
Aug 06, 2021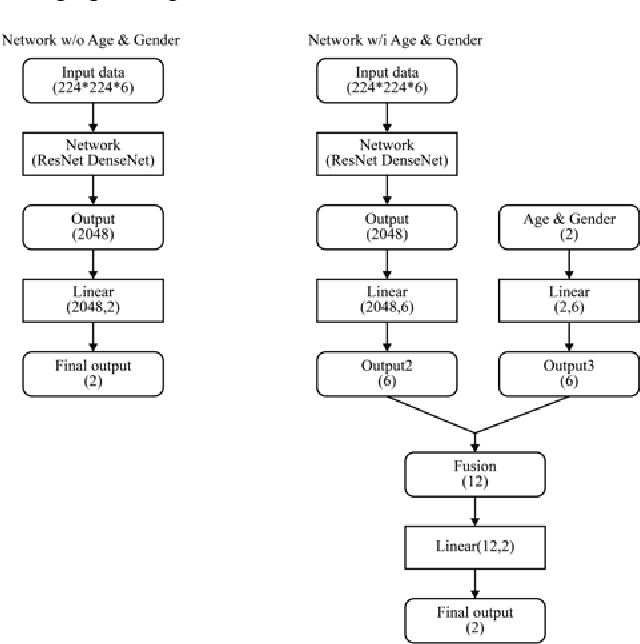
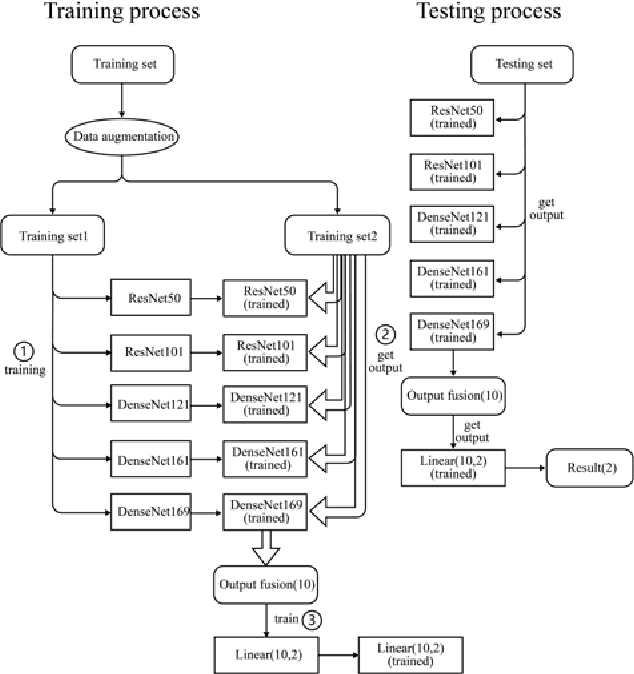
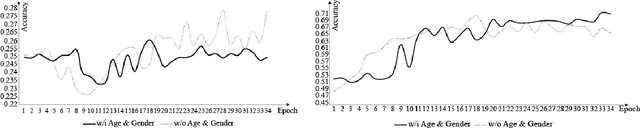
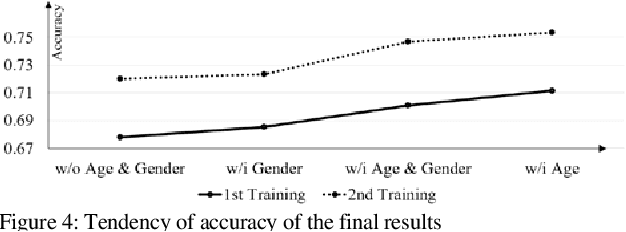
This paper proposes the importance of age and gender information in the diagnosis of diabetic retinopathy. We utilized Deep Residual Neural Networks (ResNet) and Densely Connected Convolutional Networks (DenseNet), which are proven effective on image classification problems and the diagnosis of diabetic retinopathy using the retinal fundus images. We used the ensemble of several classical networks and decentralized the training so that the network was simple and avoided overfitting. To observe whether the age and gender information could help enhance the performance, we added the information before the dense layer and compared the results with the results that did not add age and gender information. We found that the test accuracy of the network with age and gender information was 2.67% higher than that of the network without age and gender information. Meanwhile, compared with gender information, age information had a better help for the results.
JSSR: A Joint Synthesis, Segmentation, and Registration System for 3D Multi-Modal Image Alignment of Large-scale Pathological CT Scans
May 25, 2020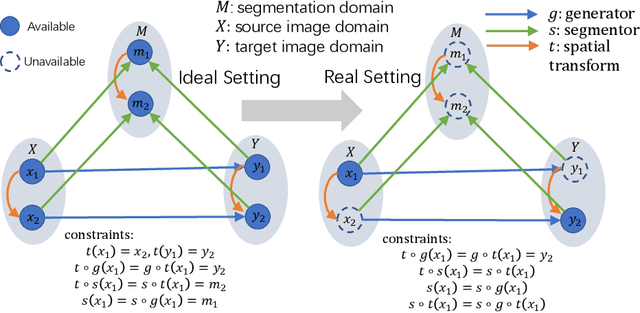
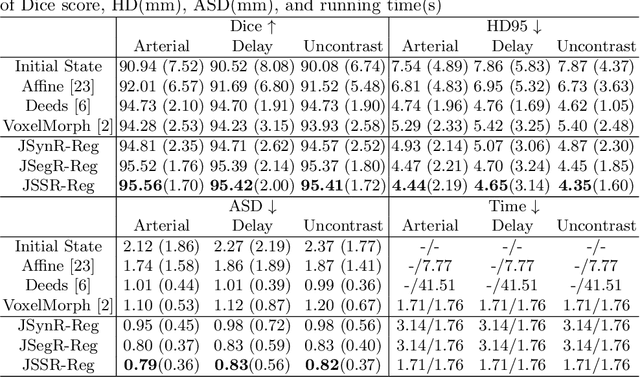
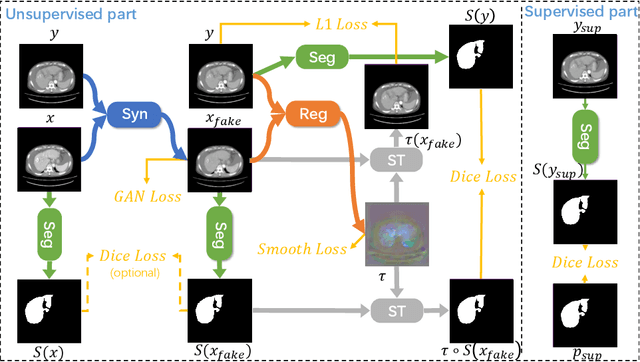
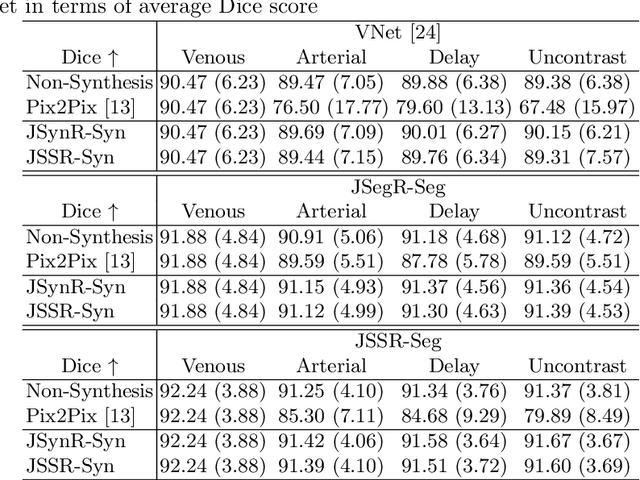
Multi-modal image registration is a challenging problem yet important clinical task in many real applications and scenarios. For medical imaging based diagnosis, deformable registration among different image modalities is often required in order to provide complementary visual information, as the first step. During the registration, the semantic information is the key to match homologous points and pixels. Nevertheless, many conventional registration methods are incapable to capture the high-level semantic anatomical dense correspondences. In this work, we propose a novel multi-task learning system, JSSR, based on an end-to-end 3D convolutional neural network that is composed of a generator, a register and a segmentor, for the tasks of synthesis, registration and segmentation, respectively. This system is optimized to satisfy the implicit constraints between different tasks unsupervisedly. It first synthesizes the source domain images into the target domain, then an intra-modal registration is applied on the synthesized images and target images. Then we can get the semantic segmentation by applying segmentors on the synthesized images and target images, which are aligned by the same deformation field generated by the registers. The supervision from another fully-annotated dataset is used to regularize the segmentors. We extensively evaluate our JSSR system on a large-scale medical image dataset containing 1,485 patient CT imaging studies of four different phases (i.e., 5,940 3D CT scans with pathological livers) on the registration, segmentation and synthesis tasks. The performance is improved after joint training on the registration and segmentation tasks by $0.9\%$ and $1.9\%$ respectively from a highly competitive and accurate baseline. The registration part also consistently outperforms the conventional state-of-the-art multi-modal registration methods.
Image Quality Assessment for Omnidirectional Cross-reference Stitching
Apr 10, 2019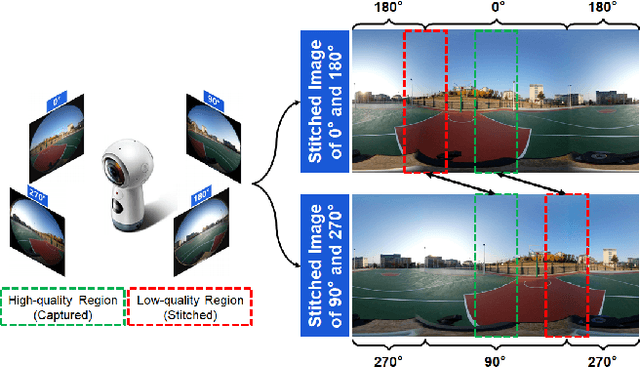
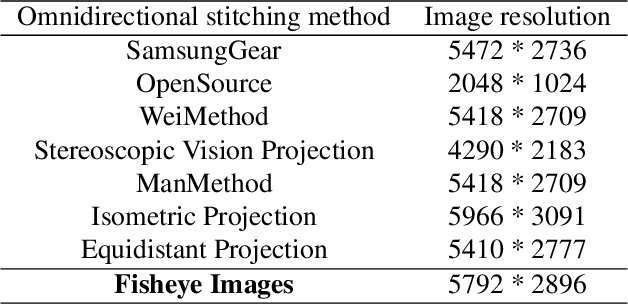

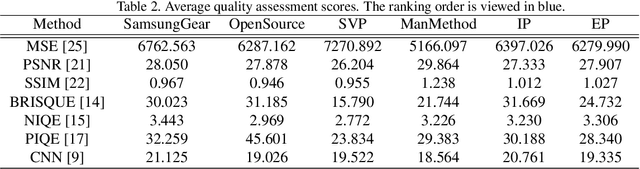
Along with the development of virtual reality (VR), omnidirectional images play an important role in producing multimedia content with immersive experience. However, despite various existing approaches for omnidirectional image stitching, how to quantitatively assess the quality of stitched images is still insufficiently explored. To address this problem, we establish a novel omnidirectional image dataset containing stitched images as well as dual-fisheye images captured from standard quarters of 0, 90, 180 and 270. In this manner, when evaluating the quality of an image stitched from a pair of fisheye images (e.g., 0 and 180), the other pair of fisheye images (e.g., 90 and 270) can be used as the cross-reference to provide ground-truth observations of the stitching regions. Based on this dataset, we further benchmark seven widely used stitching models with seven evaluation metrics for IQA. To the best of our knowledge, it is the first dataset that focuses on assessing the stitching quality of omnidirectional images.
Constrained Linear Data-feature Mapping for Image Classification
Nov 23, 2019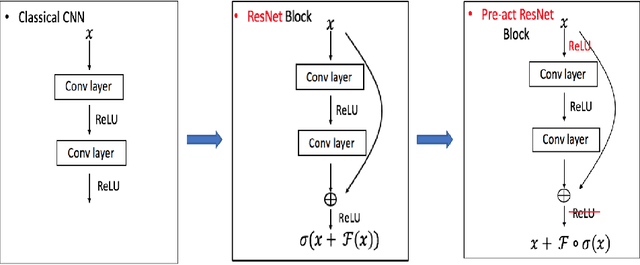
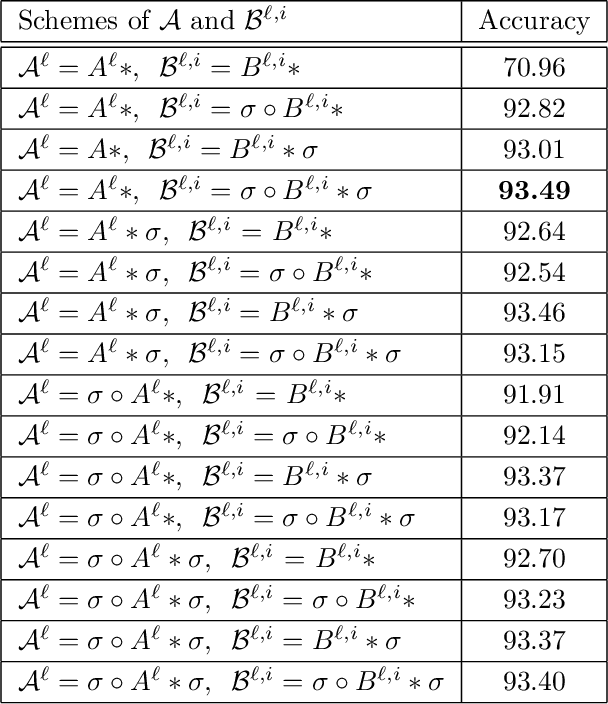
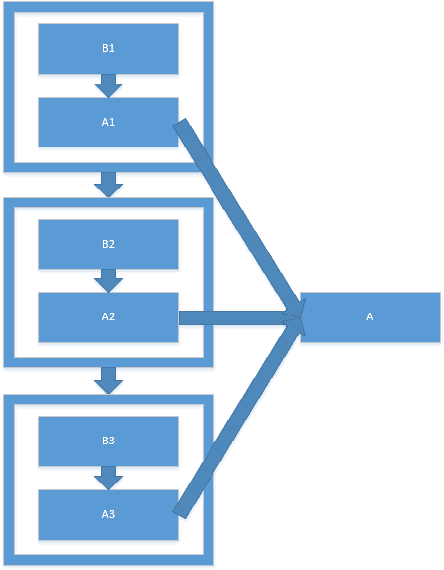
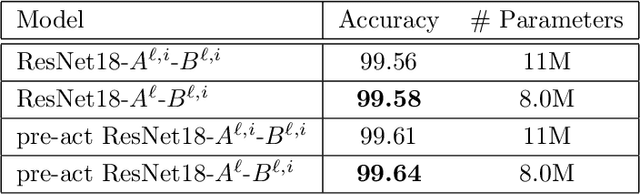
In this paper, we propose a constrained linear data-feature mapping model as an interpretable mathematical model for image classification using convolutional neural network (CNN) such as the ResNet. From this viewpoint, we establish the detailed connections in a technical level between the traditional iterative schemes for constrained linear system and the architecture for the basic block of ResNet. Under these connections, we propose some natural modifications of ResNet type models which will have less parameters but can keep almost the same accuracy as these original models. Some numerical experiments are shown to demonstrate the validity of this constrained learning data-feature mapping assumption.