 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics
Apr 22, 2026Autonomous medical robots hold promise to improve patient outcomes, reduce provider workload, democratize access to care, and enable superhuman precision. However, autonomous medical robotics has been limited by a fundamental data problem: existing medical robotic datasets are small, single-embodiment, and rarely shared openly, restricting the development of foundation models that the field needs to advance. We introduce Open-H-Embodiment, the largest open dataset of medical robotic video with synchronized kinematics to date, spanning more than 49 institutions and multiple robotic platforms including the CMR Versius, Intuitive Surgical's da Vinci, da Vinci Research Kit (dVRK), Rob Surgical BiTrack, Virtual Incision's MIRA, Moon Surgical Maestro, and a variety of custom systems, spanning surgical manipulation, robotic ultrasound, and endoscopy procedures. We demonstrate the research enabled by this dataset through two foundation models. GR00T-H is the first open foundation vision-language-action model for medical robotics, which is the only evaluated model to achieve full end-to-end task completion on a structured suturing benchmark (25% of trials vs. 0% for all others) and achieves 64% average success across a 29-step ex vivo suturing sequence. We also train Cosmos-H-Surgical-Simulator, the first action-conditioned world model to enable multi-embodiment surgical simulation from a single checkpoint, spanning nine robotic platforms and supporting in silico policy evaluation and synthetic data generation for the medical domain. These results suggest that open, large-scale medical robot data collection can serve as critical infrastructure for the research community, enabling advances in robot learning, world modeling, and beyond.
LightFormer: A lightweight and efficient decoder for remote sensing image segmentation
Apr 15, 2025



Deep learning techniques have achieved remarkable success in the semantic segmentation of remote sensing images and in land-use change detection. Nevertheless, their real-time deployment on edge platforms remains constrained by decoder complexity. Herein, we introduce LightFormer, a lightweight decoder for time-critical tasks that involve unstructured targets, such as disaster assessment, unmanned aerial vehicle search-and-rescue, and cultural heritage monitoring. LightFormer employs a feature-fusion and refinement module built on channel processing and a learnable gating mechanism to aggregate multi-scale, multi-range information efficiently, which drastically curtails model complexity. Furthermore, we propose a spatial information selection module (SISM) that integrates long-range attention with a detail preservation branch to capture spatial dependencies across multiple scales, thereby substantially improving the recognition of unstructured targets in complex scenes. On the ISPRS Vaihingen benchmark, LightFormer attains 99.9% of GLFFNet's mIoU (83.9% vs. 84.0%) while requiring only 14.7% of its FLOPs and 15.9% of its parameters, thus achieving an excellent accuracy-efficiency trade-off. Consistent results on LoveDA, ISPRS Potsdam, RescueNet, and FloodNet further demonstrate its robustness and superior perception of unstructured objects. These findings highlight LightFormer as a practical solution for remote sensing applications where both computational economy and high-precision segmentation are imperative.
Building Coverage Estimation with Low-resolution Remote Sensing Imagery
Jan 05, 2023



Building coverage statistics provide crucial insights into the urbanization, infrastructure, and poverty level of a region, facilitating efforts towards alleviating poverty, building sustainable cities, and allocating infrastructure investments and public service provision. Global mapping of buildings has been made more efficient with the incorporation of deep learning models into the pipeline. However, these models typically rely on high-resolution satellite imagery which are expensive to collect and infrequently updated. As a result, building coverage data are not updated timely especially in developing regions where the built environment is changing quickly. In this paper, we propose a method for estimating building coverage using only publicly available low-resolution satellite imagery that is more frequently updated. We show that having a multi-node quantile regression layer greatly improves the model's spatial and temporal generalization. Our model achieves a coefficient of determination ($R^2$) as high as 0.968 on predicting building coverage in regions of different levels of development around the world. We demonstrate that the proposed model accurately predicts the building coverage from raw input images and generalizes well to unseen countries and continents, suggesting the possibility of estimating global building coverage using only low-resolution remote sensing data.
The Influence of Age and Gender Information on the Diagnosis of Diabetic Retinopathy: Based on Neural Networks
Aug 06, 2021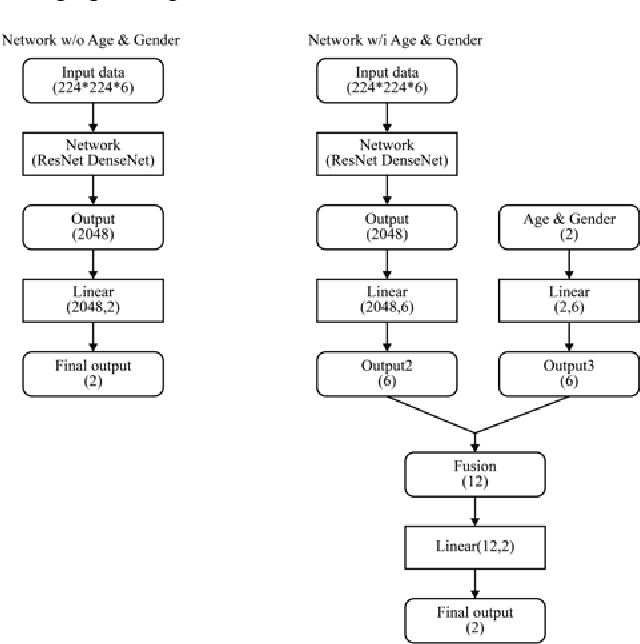
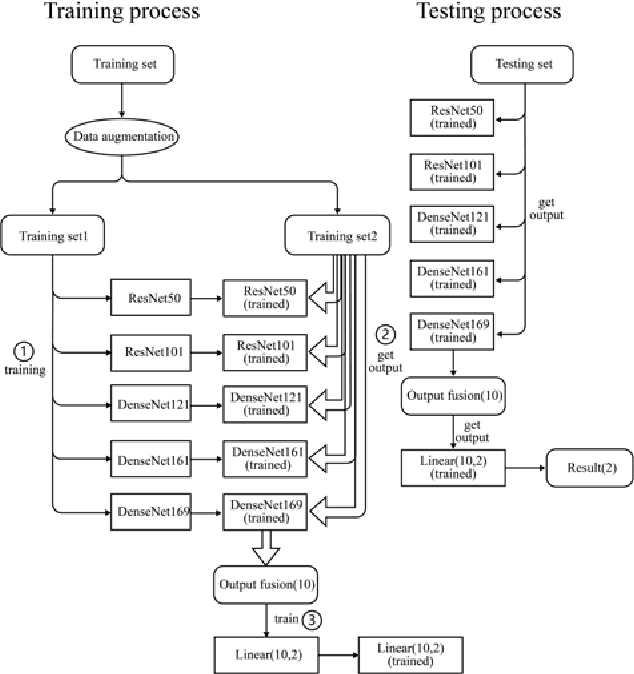
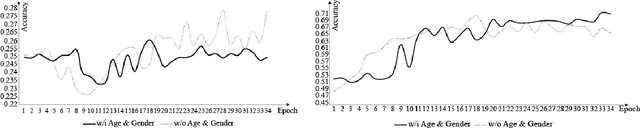
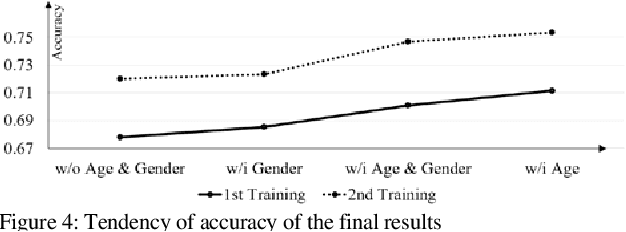
This paper proposes the importance of age and gender information in the diagnosis of diabetic retinopathy. We utilized Deep Residual Neural Networks (ResNet) and Densely Connected Convolutional Networks (DenseNet), which are proven effective on image classification problems and the diagnosis of diabetic retinopathy using the retinal fundus images. We used the ensemble of several classical networks and decentralized the training so that the network was simple and avoided overfitting. To observe whether the age and gender information could help enhance the performance, we added the information before the dense layer and compared the results with the results that did not add age and gender information. We found that the test accuracy of the network with age and gender information was 2.67% higher than that of the network without age and gender information. Meanwhile, compared with gender information, age information had a better help for the results.
Reinforcement Learning with Expert Trajectory For Quantitative Trading
May 09, 2021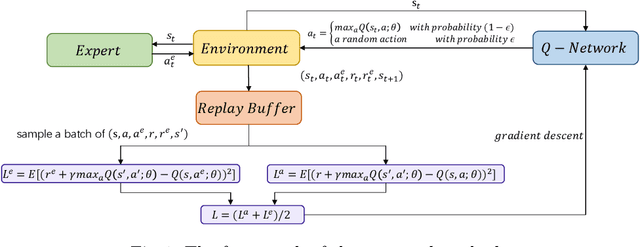
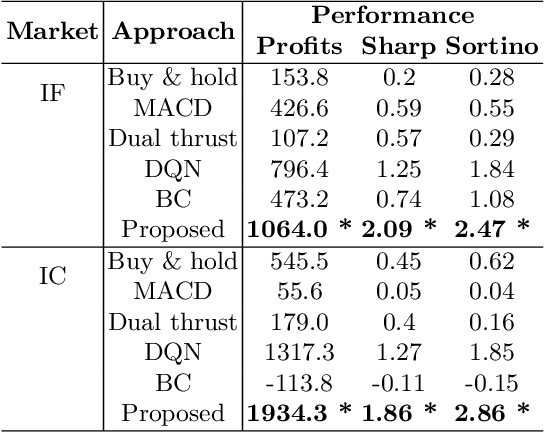
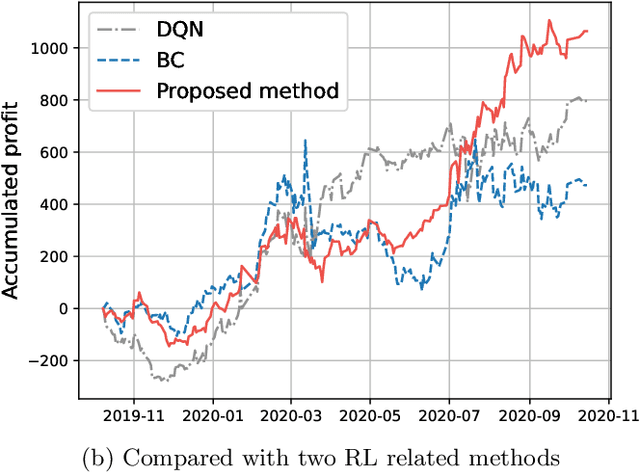
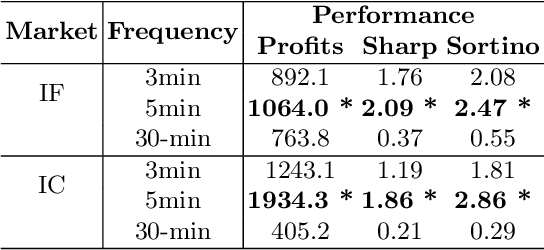
In recent years, quantitative investment methods combined with artificial intelligence have attracted more and more attention from investors and researchers. Existing related methods based on the supervised learning are not very suitable for learning problems with long-term goals and delayed rewards in real futures trading. In this paper, therefore, we model the price prediction problem as a Markov decision process (MDP), and optimize it by reinforcement learning with expert trajectory. In the proposed method, we employ more than 100 short-term alpha factors instead of price, volume and several technical factors in used existing methods to describe the states of MDP. Furthermore, unlike DQN (deep Q-learning) and BC (behavior cloning) in related methods, we introduce expert experience in training stage, and consider both the expert-environment interaction and the agent-environment interaction to design the temporal difference error so that the agents are more adaptable for inevitable noise in financial data. Experimental results evaluated on share price index futures in China, including IF (CSI 300) and IC (CSI 500), show that the advantages of the proposed method compared with three typical technical analysis and two deep leaning based methods.