 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJSSR: A Joint Synthesis, Segmentation, and Registration System for 3D Multi-Modal Image Alignment of Large-scale Pathological CT Scans
Paper and Code
May 27, 2020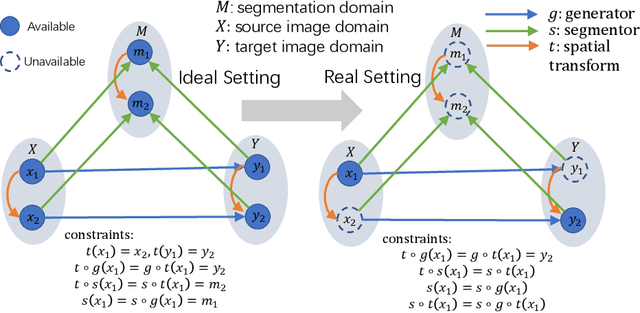
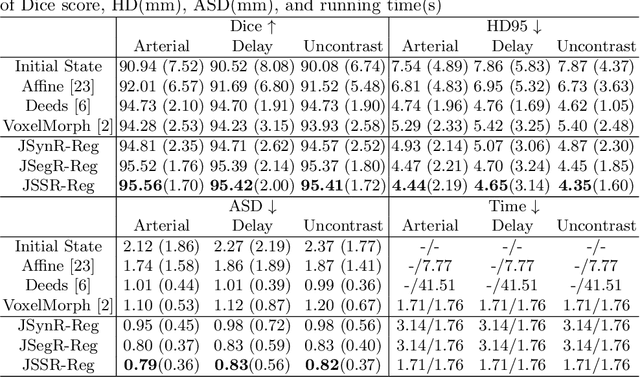
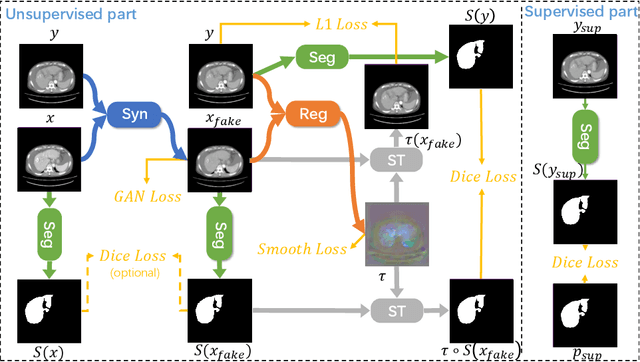
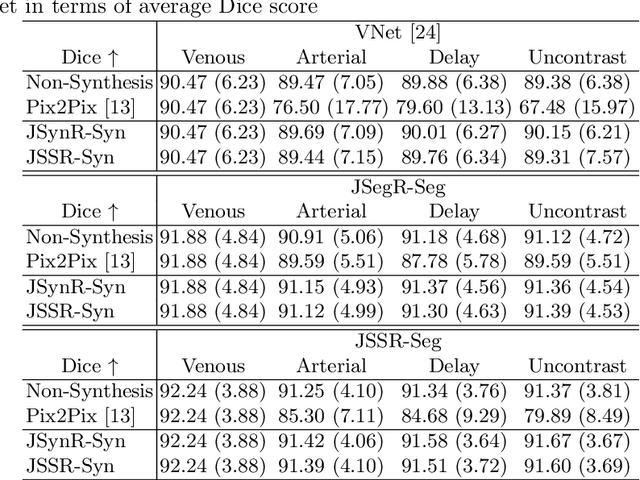
Multi-modal image registration is a challenging problem yet important clinical task in many real applications and scenarios. For medical imaging based diagnosis, deformable registration among different image modalities is often required in order to provide complementary visual information, as the first step. During the registration, the semantic information is the key to match homologous points and pixels. Nevertheless, many conventional registration methods are incapable to capture the high-level semantic anatomical dense correspondences. In this work, we propose a novel multi-task learning system, JSSR, based on an end-to-end 3D convolutional neural network that is composed of a generator, a register and a segmentor, for the tasks of synthesis, registration and segmentation, respectively. This system is optimized to satisfy the implicit constraints between different tasks unsupervisedly. It first synthesizes the source domain images into the target domain, then an intra-modal registration is applied on the synthesized images and target images. Then we can get the semantic segmentation by applying segmentors on the synthesized images and target images, which are aligned by the same deformation field generated by the registers. The supervision from another fully-annotated dataset is used to regularize the segmentors. We extensively evaluate our JSSR system on a large-scale medical image dataset containing 1,485 patient CT imaging studies of four different phases (i.e., 5,940 3D CT scans with pathological livers) on the registration, segmentation and synthesis tasks. The performance is improved after joint training on the registration and segmentation tasks by 0.9% and 1.9% respectively from a highly competitive and accurate baseline. The registration part also consistently outperforms the conventional state-of-the-art multi-modal registration methods.