 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SHARP: Shape-Aware Reconstruction of People In Loose Clothing
Jun 17, 2021
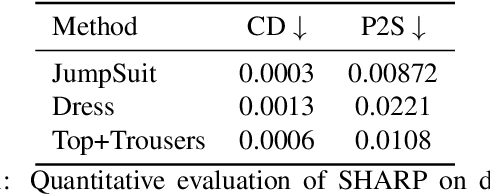
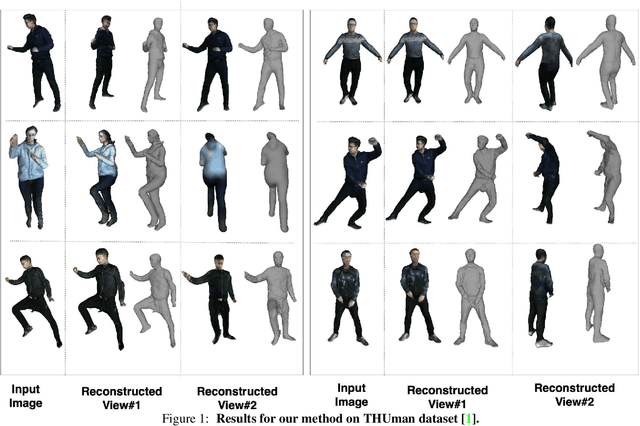
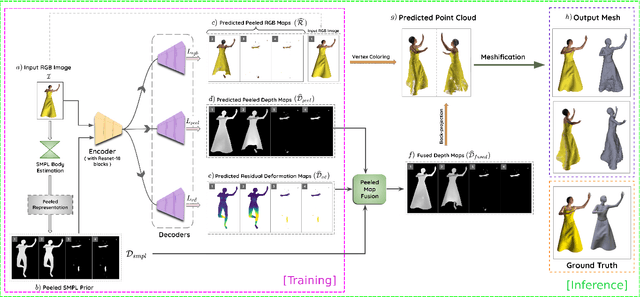
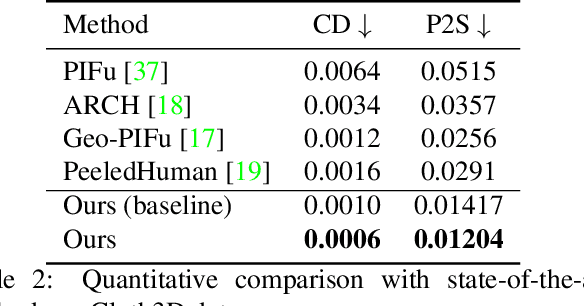
3D human body reconstruction from monocular images is an interesting and ill-posed problem in computer vision with wider applications in multiple domains. In this paper, we propose SHARP, a novel end-to-end trainable network that accurately recovers the detailed geometry and appearance of 3D people in loose clothing from a monocular image. We propose a sparse and efficient fusion of a parametric body prior with a non-parametric peeled depth map representation of clothed models. The parametric body prior constraints our model in two ways: first, the network retains geometrically consistent body parts that are not occluded by clothing, and second, it provides a body shape context that improves prediction of the peeled depth maps. This enables SHARP to recover fine-grained 3D geometrical details with just L1 losses on the 2D maps, given an input image. We evaluate SHARP on publicly available Cloth3D and THuman datasets and report superior performance to state-of-the-art approaches.
Space-adaptive anisotropic bivariate Laplacian regularization for image restoration
Aug 02, 2019

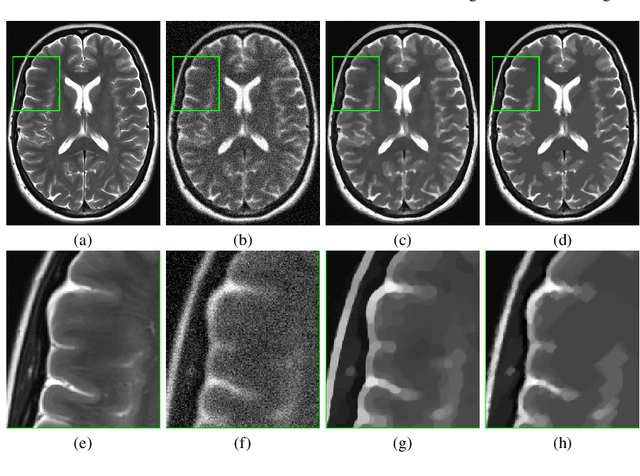
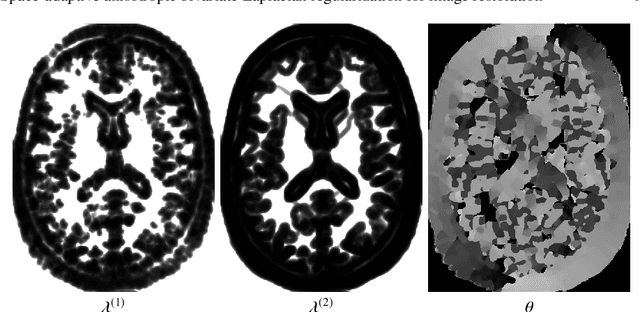
In this paper we present a new regularization term for variational image restoration which can be regarded as a space-variant anisotropic extension of the classical isotropic Total Variation (TV) regularizer. The proposed regularizer comes from the statistical assumption that the gradients of the target image distribute locally according to space-variant bivariate Laplacian distributions. The highly flexible variational structure of the corresponding regularizer encodes several free parameters which hold the potential for faithfully modelling the local geometry in the image and describing local orientation preferences. For an automatic estimation of such parameters, we design a robust maximum likelihood approach and report results on its reliability on synthetic data and natural images. A minimization algorithm based on the Alternating Direction Method of Multipliers (ADMM) is presented for the efficient numerical solution of the proposed variational model. Some experimental results are reported which demonstrate the high-quality of restorations achievable by the proposed model, in particular with respect to classical Total Variation regularization.
Convolutional Image Captioning
Nov 24, 2017
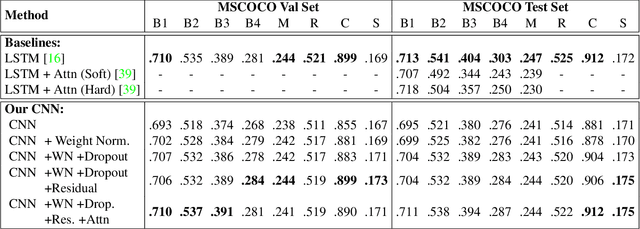
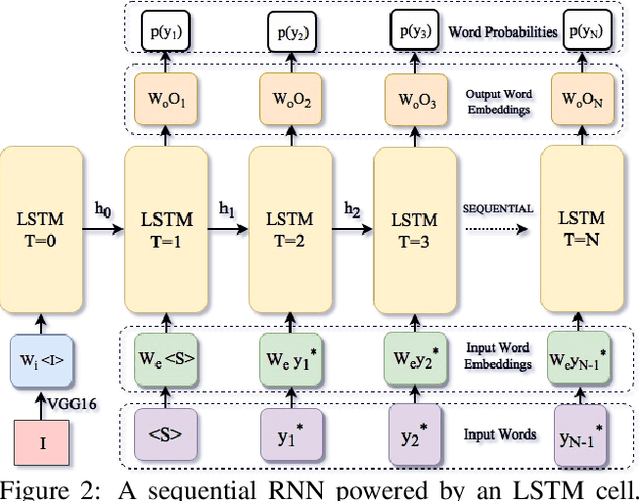

Image captioning is an important but challenging task, applicable to virtual assistants, editing tools, image indexing, and support of the disabled. Its challenges are due to the variability and ambiguity of possible image descriptions. In recent years significant progress has been made in image captioning, using Recurrent Neural Networks powered by long-short-term-memory (LSTM) units. Despite mitigating the vanishing gradient problem, and despite their compelling ability to memorize dependencies, LSTM units are complex and inherently sequential across time. To address this issue, recent work has shown benefits of convolutional networks for machine translation and conditional image generation. Inspired by their success, in this paper, we develop a convolutional image captioning technique. We demonstrate its efficacy on the challenging MSCOCO dataset and demonstrate performance on par with the baseline, while having a faster training time per number of parameters. We also perform a detailed analysis, providing compelling reasons in favor of convolutional language generation approaches.
Q-Net: A Quantitative Susceptibility Mapping-based Deep Neural Network for Differential Diagnosis of Brain Iron Deposition in Hemochromatosis
Oct 01, 2021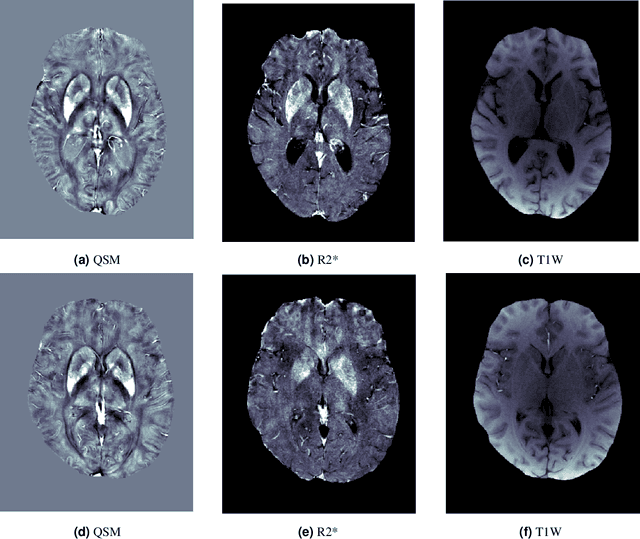

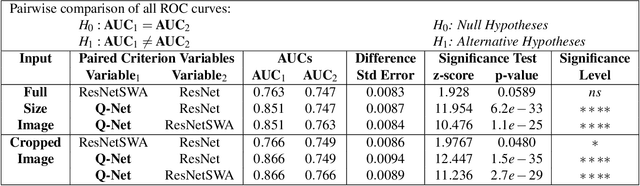
Brain iron deposition, in particular deep gray matter nuclei, increases with advancing age. Hereditary Hemochromatosis (HH) is the most common inherited disorder of systemic iron excess in Europeans and recent studies claimed high brain iron accumulation in patient with Hemochromatosis. In this study, we focus on Artificial Intelligence (AI)-based differential diagnosis of brain iron deposition in HH via Quantitative Susceptibility Mapping (QSM), which is an established Magnetic Resonance Imaging (MRI) technique to study the distribution of iron in the brain. Our main objective is investigating potentials of AI-driven frameworks to accurately and efficiently differentiate individuals with Hemochromatosis from those of the healthy control group. More specifically, we developed the Q-Net framework, which is a data-driven model that processes information on iron deposition in the brain obtained from multi-echo gradient echo imaging data and anatomical information on T1-Weighted images of the brain. We illustrate that the Q-Net framework can assist in differentiating between someone with HH and Healthy control (HC) of the same age, something that is not possible by just visualizing images. The study is performed based on a unique dataset that was collected from 52 subjects with HH and 47 HC. The Q-Net provides a differential diagnosis accuracy of 83.16% and 80.37% in the scan-level and image-level classification, respectively.
Detector-Free Weakly Supervised Grounding by Separation
Apr 20, 2021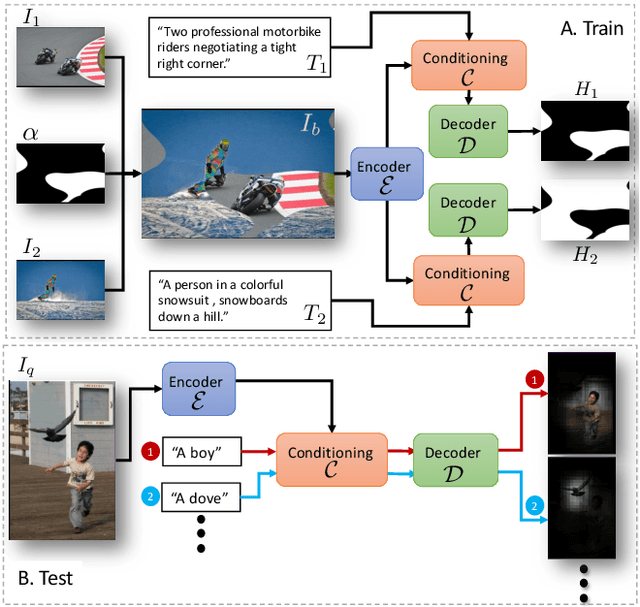
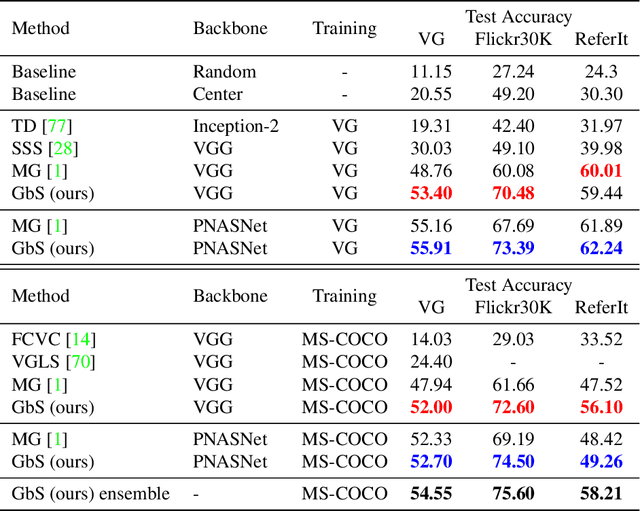
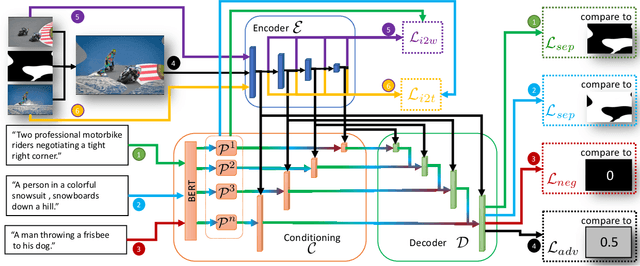
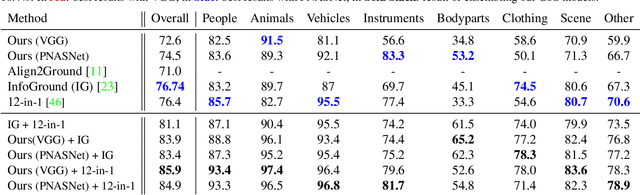
Nowadays, there is an abundance of data involving images and surrounding free-form text weakly corresponding to those images. Weakly Supervised phrase-Grounding (WSG) deals with the task of using this data to learn to localize (or to ground) arbitrary text phrases in images without any additional annotations. However, most recent SotA methods for WSG assume the existence of a pre-trained object detector, relying on it to produce the ROIs for localization. In this work, we focus on the task of Detector-Free WSG (DF-WSG) to solve WSG without relying on a pre-trained detector. We directly learn everything from the images and associated free-form text pairs, thus potentially gaining an advantage on the categories unsupported by the detector. The key idea behind our proposed Grounding by Separation (GbS) method is synthesizing `text to image-regions' associations by random alpha-blending of arbitrary image pairs and using the corresponding texts of the pair as conditions to recover the alpha map from the blended image via a segmentation network. At test time, this allows using the query phrase as a condition for a non-blended query image, thus interpreting the test image as a composition of a region corresponding to the phrase and the complement region. Using this approach we demonstrate a significant accuracy improvement, of up to $8.5\%$ over previous DF-WSG SotA, for a range of benchmarks including Flickr30K, Visual Genome, and ReferIt, as well as a significant complementary improvement (above $7\%$) over the detector-based approaches for WSG.
Effect of Radiology Report Labeler Quality on Deep Learning Models for Chest X-Ray Interpretation
Apr 01, 2021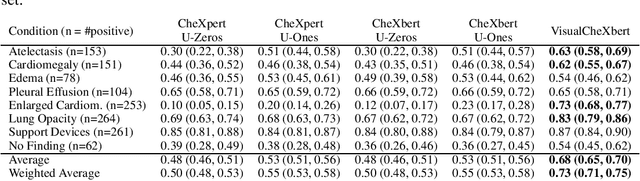
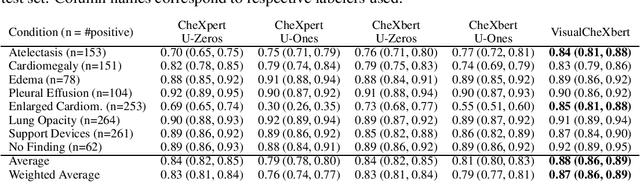
Although deep learning models for chest X-ray interpretation are commonly trained on labels generated by automatic radiology report labelers, the impact of improvements in report labeling on the performance of chest X-ray classification models has not been systematically investigated. We first compare the CheXpert, CheXbert, and VisualCheXbert labelers on the task of extracting accurate chest X-ray image labels from radiology reports, reporting that the VisualCheXbert labeler outperforms the CheXpert and CheXbert labelers. Next, after training image classification models using labels generated from the different radiology report labelers on one of the largest datasets of chest X-rays, we show that an image classification model trained on labels from the VisualCheXbert labeler outperforms image classification models trained on labels from the CheXpert and CheXbert labelers. Our work suggests that recent improvements in radiology report labeling can translate to the development of higher performing chest X-ray classification models.
Deep-Geometric 6 DoF Localization from a Single Image in Topo-metric Maps
Feb 04, 2020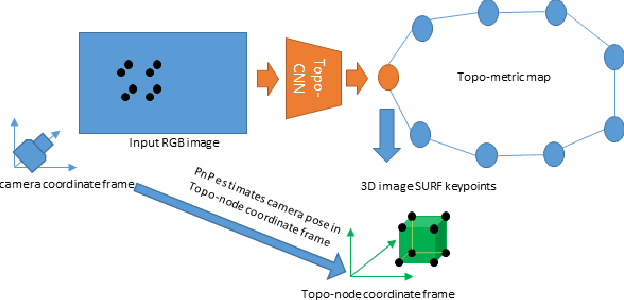
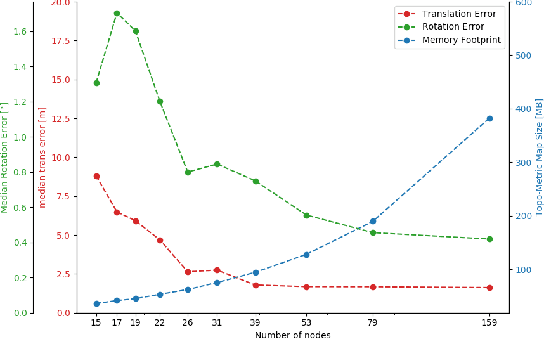
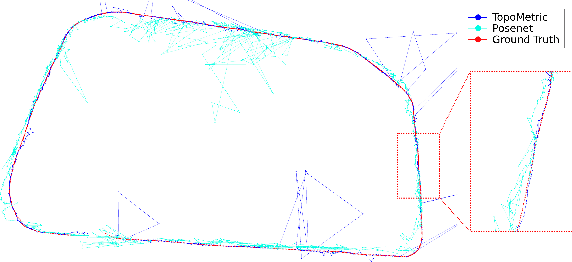

We describe a Deep-Geometric Localizer that is able to estimate the full 6 Degree of Freedom (DoF) global pose of the camera from a single image in a previously mapped environment. Our map is a topo-metric one, with discrete topological nodes whose 6 DoF poses are known. Each topo-node in our map also comprises of a set of points, whose 2D features and 3D locations are stored as part of the mapping process. For the mapping phase, we utilise a stereo camera and a regular stereo visual SLAM pipeline. During the localization phase, we take a single camera image, localize it to a topological node using Deep Learning, and use a geometric algorithm (PnP) on the matched 2D features (and their 3D positions in the topo map) to determine the full 6 DoF globally consistent pose of the camera. Our method divorces the mapping and the localization algorithms and sensors (stereo and mono), and allows accurate 6 DoF pose estimation in a previously mapped environment using a single camera. With potential VR/AR and localization applications in single camera devices such as mobile phones and drones, our hybrid algorithm compares favourably with the fully Deep-Learning based Pose-Net that regresses pose from a single image in simulated as well as real environments.
Learning Multi-Modal Image Registration without Real Data
Apr 21, 2020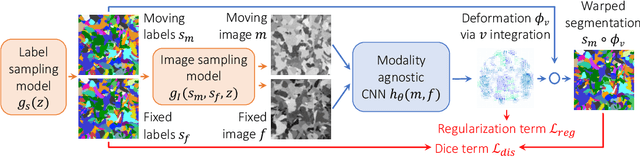

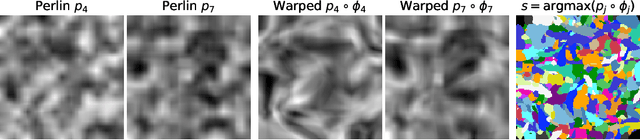
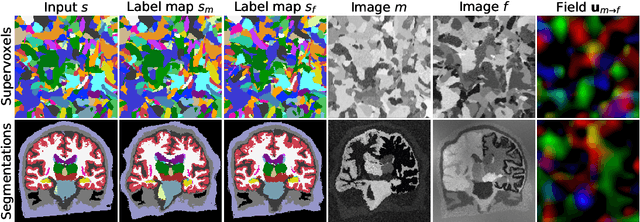
We introduce a learning-based strategy for multi-modal registration of images acquired with any modality, without requiring real data during training. While classical registration methods can accurately align multi-modal image pairs, they solve a costly optimization problem for every new pair of images. Learning-based techniques are fast at test time, but can only register images of the specific anatomy and modalities they were trained on. In contrast, our approach leverages a generative model to synthesize label maps and gray-scale images that expose a network to a wide range of anatomy and contrast during training. We demonstrate that this strategy enables robust registration of arbitrary modalities, without the need to retrain for a new modality. Critically, we show that input labels need not be of actual anatomy: training on randomly synthesized shapes, or supervoxels, results in competitive registration performance and makes the network agnostic to anatomy and contrast, all while eradicating the need for real data. We present extensive experiments demonstrating that this strategy enables registration of modalities not seen during training and surpasses the state of art in cross-contrast registration. Our code is integrated with the VoxelMorph library at: http://voxelmorph.csail.mit.edu
Scene Graphs: A Survey of Generations and Applications
Mar 17, 2021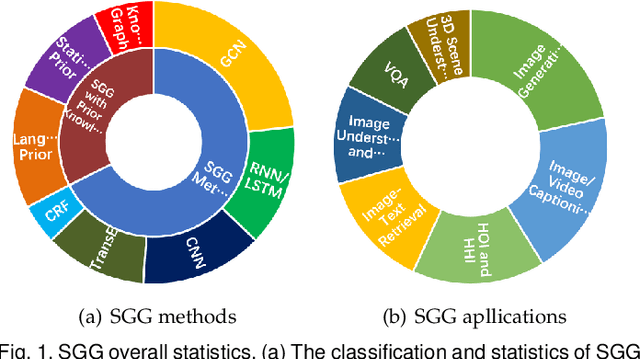

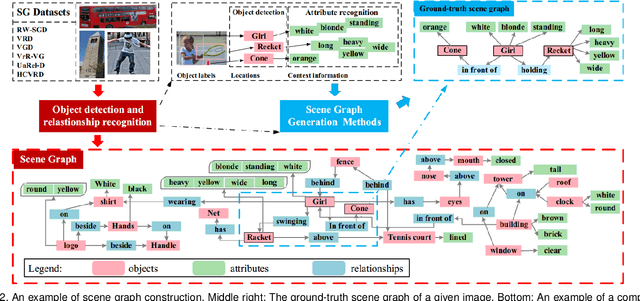
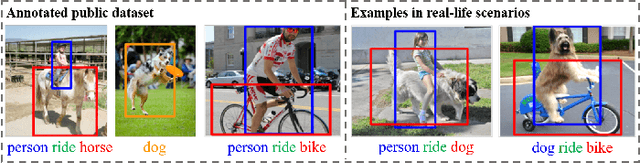
Scene graph is a structured representation of a scene that can clearly express the objects, attributes, and relationships between objects in the scene. As computer vision technology continues to develop, people are no longer satisfied with simply detecting and recognizing objects in images; instead, people look forward to a higher level of understanding and reasoning about visual scenes. For example, given an image, we want to not only detect and recognize objects in the image, but also know the relationship between objects (visual relationship detection), and generate a text description (image captioning) based on the image content. Alternatively, we might want the machine to tell us what the little girl in the image is doing (Visual Question Answering (VQA)), or even remove the dog from the image and find similar images (image editing and retrieval), etc. These tasks require a higher level of understanding and reasoning for image vision tasks. The scene graph is just such a powerful tool for scene understanding. Therefore, scene graphs have attracted the attention of a large number of researchers, and related research is often cross-modal, complex, and rapidly developing. However, no relatively systematic survey of scene graphs exists at present. To this end, this survey conducts a comprehensive investigation of the current scene graph research. More specifically, we first summarized the general definition of the scene graph, then conducted a comprehensive and systematic discussion on the generation method of the scene graph (SGG) and the SGG with the aid of prior knowledge. We then investigated the main applications of scene graphs and summarized the most commonly used datasets. Finally, we provide some insights into the future development of scene graphs. We believe this will be a very helpful foundation for future research on scene graphs.
Interpreting and improving deep-learning models with reality checks
Aug 16, 2021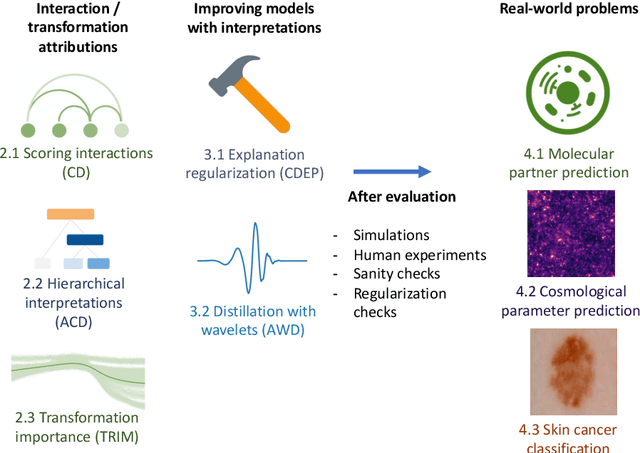

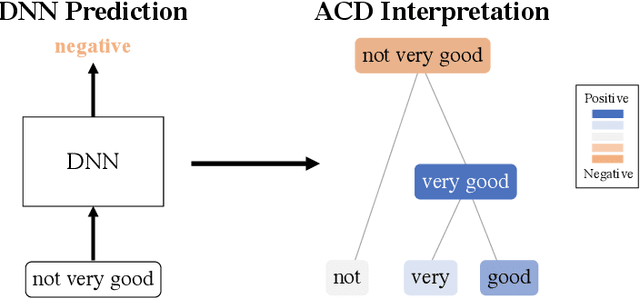
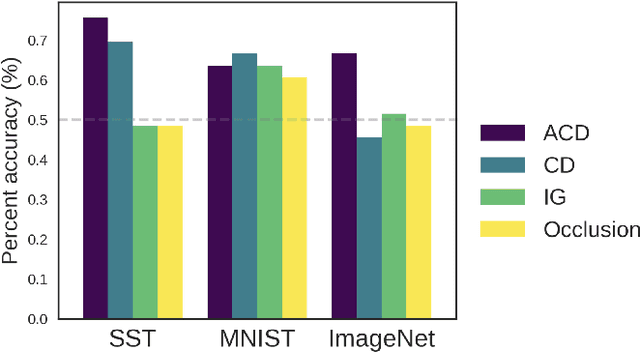
Recent deep-learning models have achieved impressive predictive performance by learning complex functions of many variables, often at the cost of interpretability. This chapter covers recent work aiming to interpret models by attributing importance to features and feature groups for a single prediction. Importantly, the proposed attributions assign importance to interactions between features, in addition to features in isolation. These attributions are shown to yield insights across real-world domains, including bio-imaging, cosmology image and natural-language processing. We then show how these attributions can be used to directly improve the generalization of a neural network or to distill it into a simple model. Throughout the chapter, we emphasize the use of reality checks to scrutinize the proposed interpretation techniques.