 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeuristic-based Inter-training to Improve Few-shot Multi-perspective Dialog Summarization
Mar 30, 2022
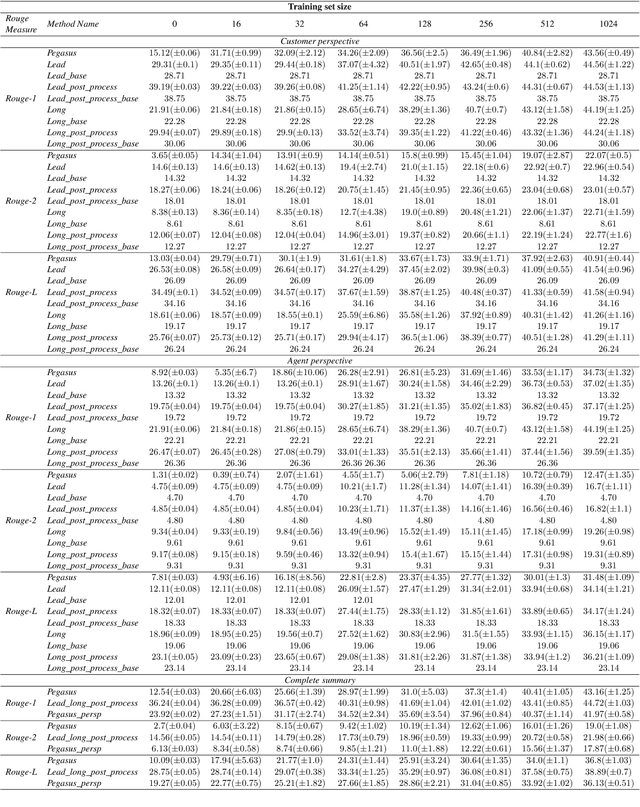
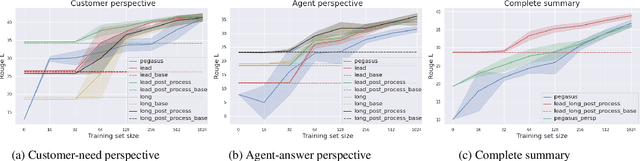
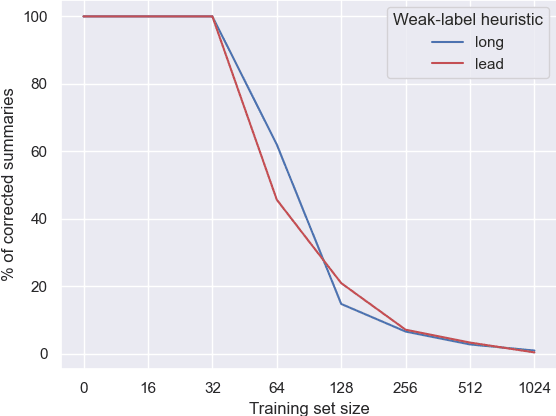
Many organizations require their customer-care agents to manually summarize their conversations with customers. These summaries are vital for decision making purposes of the organizations. The perspective of the summary that is required to be created depends on the application of the summaries. With this work, we study the multi-perspective summarization of customer-care conversations between support agents and customers. We observe that there are different heuristics that are associated with summaries of different perspectives, and explore these heuristics to create weak-labeled data for intermediate training of the models before fine-tuning with scarce human annotated summaries. Most importantly, we show that our approach supports models to generate multi-perspective summaries with a very small amount of annotated data. For example, our approach achieves 94\% of the performance (Rouge-2) of a model trained with the original data, by training only with 7\% of the original data.
HowSumm: A Multi-Document Summarization Dataset Derived from WikiHow Articles
Oct 08, 2021
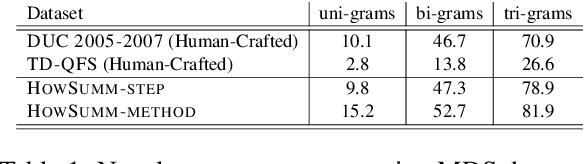
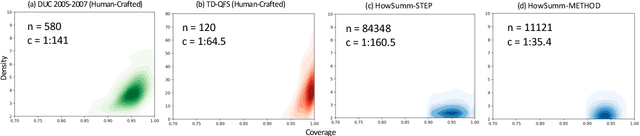

We present HowSumm, a novel large-scale dataset for the task of query-focused multi-document summarization (qMDS), which targets the use-case of generating actionable instructions from a set of sources. This use-case is different from the use-cases covered in existing multi-document summarization (MDS) datasets and is applicable to educational and industrial scenarios. We employed automatic methods, and leveraged statistics from existing human-crafted qMDS datasets, to create HowSumm from wikiHow website articles and the sources they cite. We describe the creation of the dataset and discuss the unique features that distinguish it from other summarization corpora. Automatic and human evaluations of both extractive and abstractive summarization models on the dataset reveal that there is room for improvement.
Detector-Free Weakly Supervised Grounding by Separation
Apr 20, 2021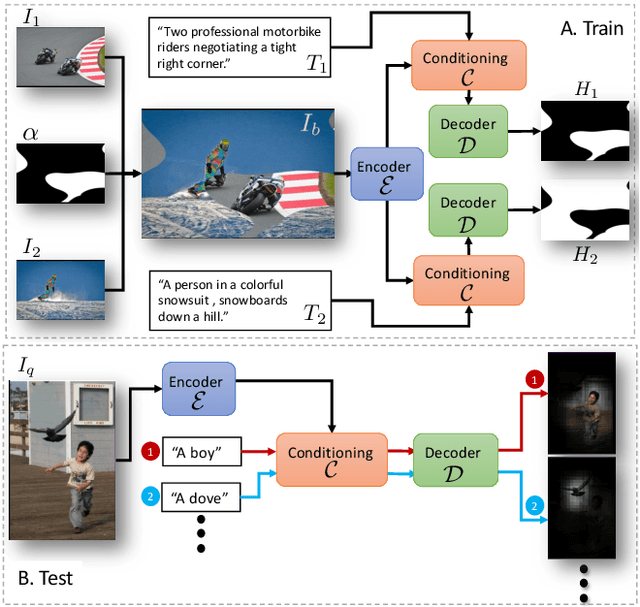
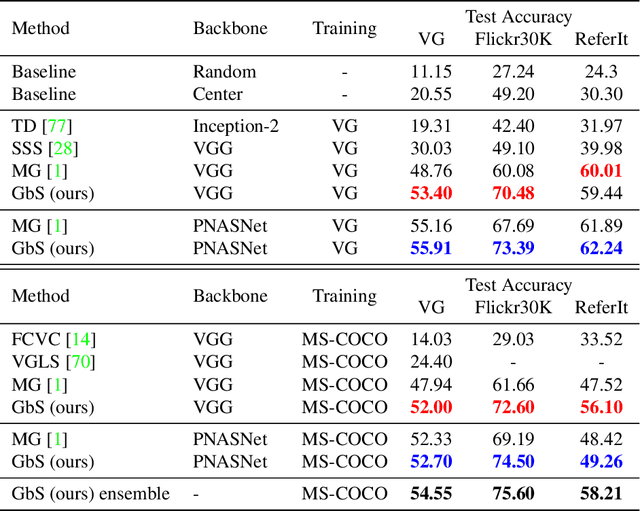
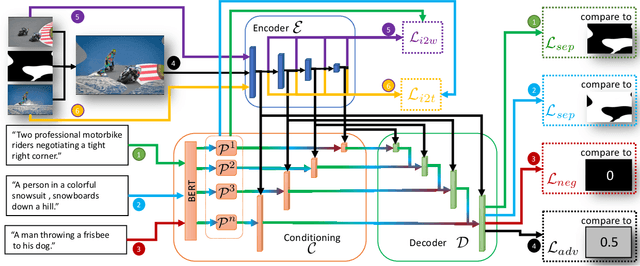
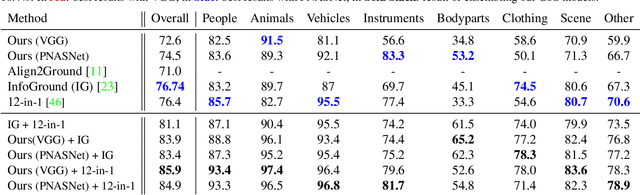
Nowadays, there is an abundance of data involving images and surrounding free-form text weakly corresponding to those images. Weakly Supervised phrase-Grounding (WSG) deals with the task of using this data to learn to localize (or to ground) arbitrary text phrases in images without any additional annotations. However, most recent SotA methods for WSG assume the existence of a pre-trained object detector, relying on it to produce the ROIs for localization. In this work, we focus on the task of Detector-Free WSG (DF-WSG) to solve WSG without relying on a pre-trained detector. We directly learn everything from the images and associated free-form text pairs, thus potentially gaining an advantage on the categories unsupported by the detector. The key idea behind our proposed Grounding by Separation (GbS) method is synthesizing `text to image-regions' associations by random alpha-blending of arbitrary image pairs and using the corresponding texts of the pair as conditions to recover the alpha map from the blended image via a segmentation network. At test time, this allows using the query phrase as a condition for a non-blended query image, thus interpreting the test image as a composition of a region corresponding to the phrase and the complement region. Using this approach we demonstrate a significant accuracy improvement, of up to $8.5\%$ over previous DF-WSG SotA, for a range of benchmarks including Flickr30K, Visual Genome, and ReferIt, as well as a significant complementary improvement (above $7\%$) over the detector-based approaches for WSG.
orgFAQ: A New Dataset and Analysis on Organizational FAQs and User Questions
Sep 03, 2020Frequently Asked Questions (FAQ) webpages are created by organizations for their users. FAQs are used in several scenarios, e.g., to answer user questions. On the other hand, the content of FAQs is affected by user questions by definition. In order to promote research in this field, several FAQ datasets exist. However, we claim that being collected from community websites, they do not correctly represent challenges associated with FAQs in an organizational context. Thus, we release orgFAQ, a new dataset composed of $6988$ user questions and $1579$ corresponding FAQs that were extracted from organizations' FAQ webpages in the Jobs domain. In this paper, we provide an analysis of the properties of such FAQs, and demonstrate the usefulness of our new dataset by utilizing it in a relevant task from the Jobs domain. We also show the value of the orgFAQ dataset in a task of a different domain - the COVID-19 pandemic.
A Summarization System for Scientific Documents
Aug 29, 2019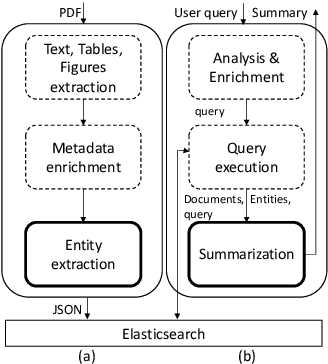
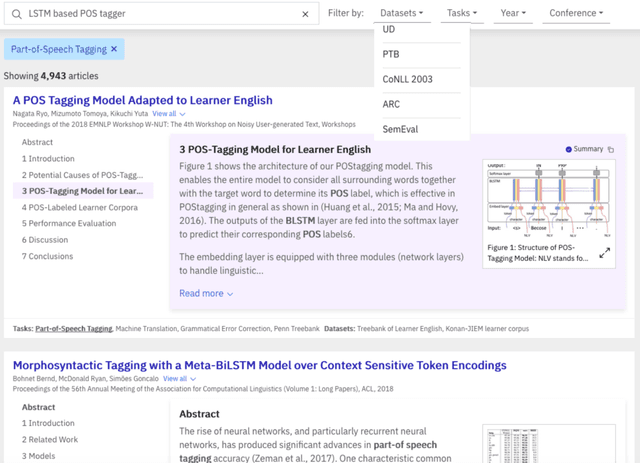
We present a novel system providing summaries for Computer Science publications. Through a qualitative user study, we identified the most valuable scenarios for discovery, exploration and understanding of scientific documents. Based on these findings, we built a system that retrieves and summarizes scientific documents for a given information need, either in form of a free-text query or by choosing categorized values such as scientific tasks, datasets and more. Our system ingested 270,000 papers, and its summarization module aims to generate concise yet detailed summaries. We validated our approach with human experts.
TalkSumm: A Dataset and Scalable Annotation Method for Scientific Paper Summarization Based on Conference Talks
Jun 13, 2019
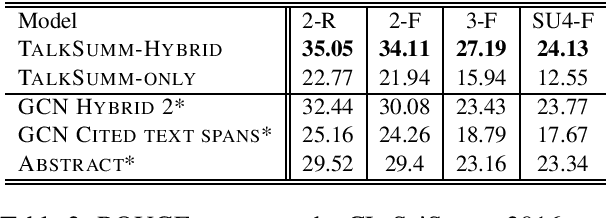

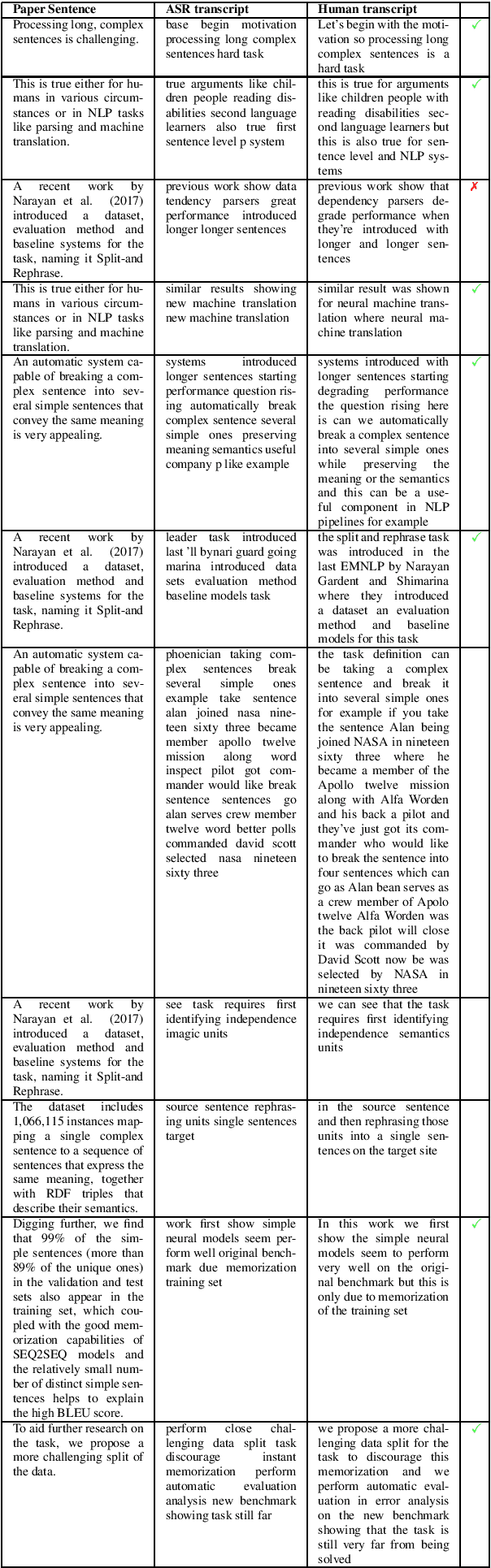
Currently, no large-scale training data is available for the task of scientific paper summarization. In this paper, we propose a novel method that automatically generates summaries for scientific papers, by utilizing videos of talks at scientific conferences. We hypothesize that such talks constitute a coherent and concise description of the papers' content, and can form the basis for good summaries. We collected 1716 papers and their corresponding videos, and created a dataset of paper summaries. A model trained on this dataset achieves similar performance as models trained on a dataset of summaries created manually. In addition, we validated the quality of our summaries by human experts.
Joint Learning of Correlated Sequence Labelling Tasks Using Bidirectional Recurrent Neural Networks
Jul 18, 2017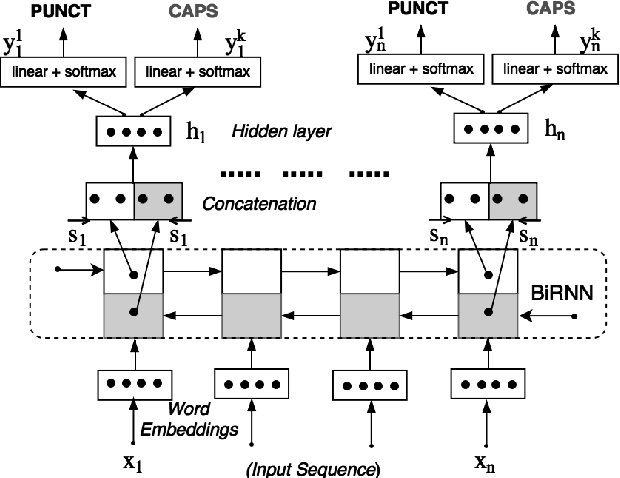
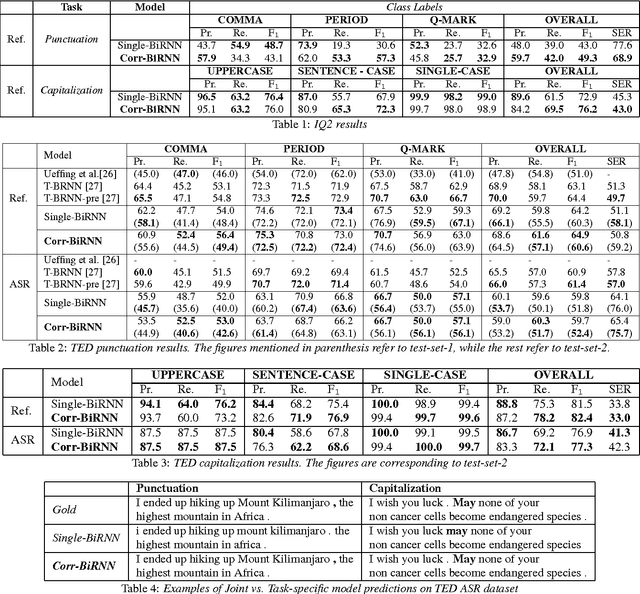
The stream of words produced by Automatic Speech Recognition (ASR) systems is typically devoid of punctuations and formatting. Most natural language processing applications expect segmented and well-formatted texts as input, which is not available in ASR output. This paper proposes a novel technique of jointly modeling multiple correlated tasks such as punctuation and capitalization using bidirectional recurrent neural networks, which leads to improved performance for each of these tasks. This method could be extended for joint modeling of any other correlated sequence labeling tasks.
RNN Fisher Vectors for Action Recognition and Image Annotation
Dec 12, 2015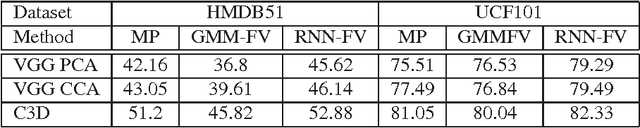
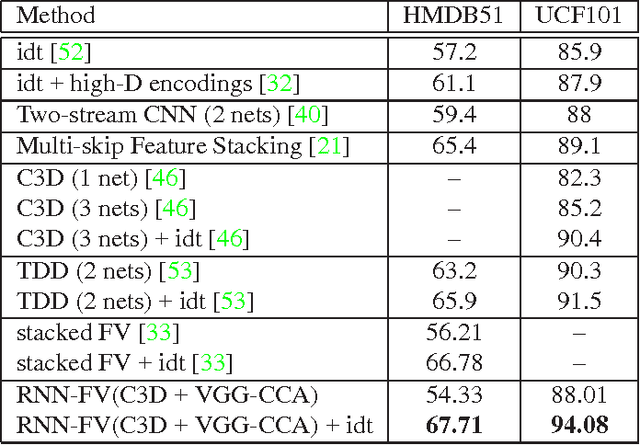
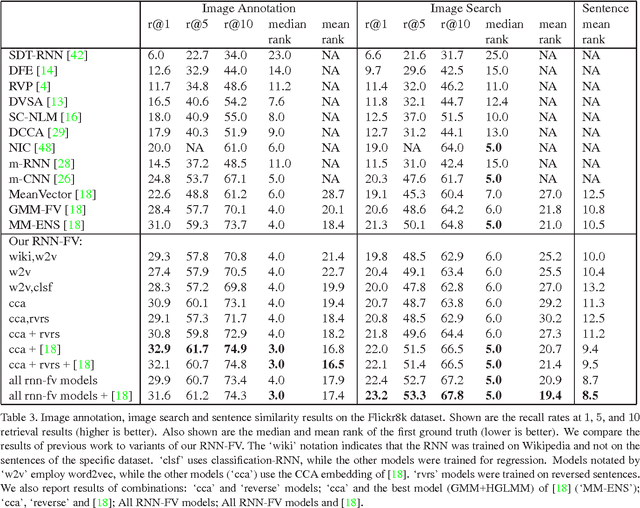
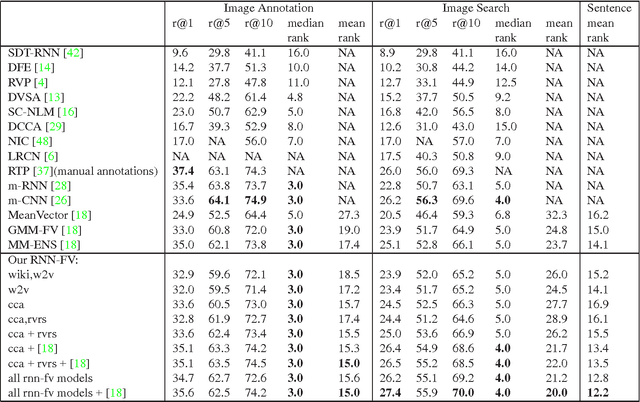
Recurrent Neural Networks (RNNs) have had considerable success in classifying and predicting sequences. We demonstrate that RNNs can be effectively used in order to encode sequences and provide effective representations. The methodology we use is based on Fisher Vectors, where the RNNs are the generative probabilistic models and the partial derivatives are computed using backpropagation. State of the art results are obtained in two central but distant tasks, which both rely on sequences: video action recognition and image annotation. We also show a surprising transfer learning result from the task of image annotation to the task of video action recognition.
Fisher Vectors Derived from Hybrid Gaussian-Laplacian Mixture Models for Image Annotation
Jan 24, 2015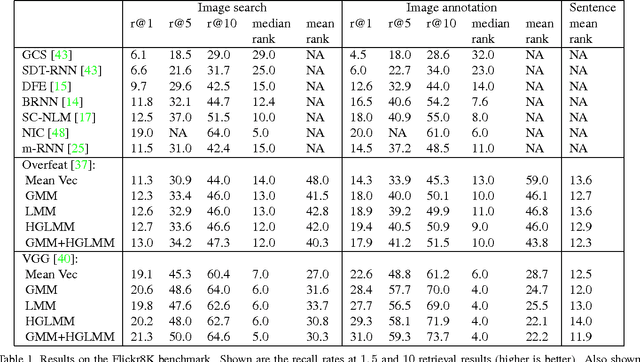

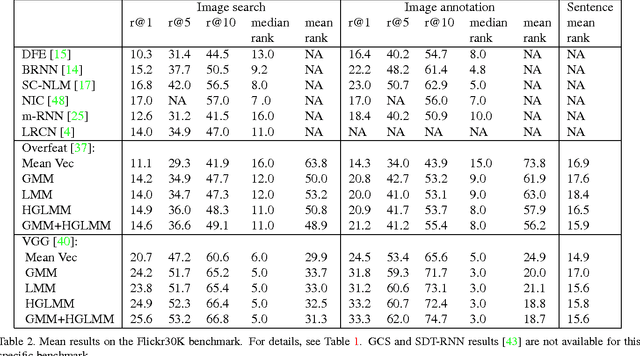
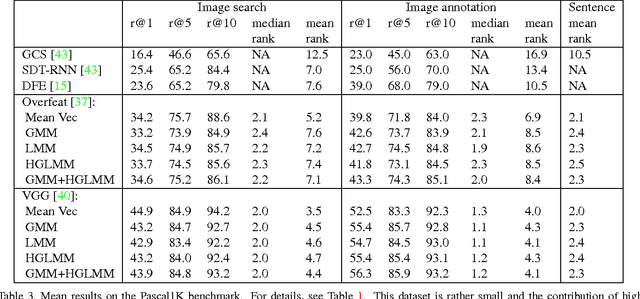
In the traditional object recognition pipeline, descriptors are densely sampled over an image, pooled into a high dimensional non-linear representation and then passed to a classifier. In recent years, Fisher Vectors have proven empirically to be the leading representation for a large variety of applications. The Fisher Vector is typically taken as the gradients of the log-likelihood of descriptors, with respect to the parameters of a Gaussian Mixture Model (GMM). Motivated by the assumption that different distributions should be applied for different datasets, we present two other Mixture Models and derive their Expectation-Maximization and Fisher Vector expressions. The first is a Laplacian Mixture Model (LMM), which is based on the Laplacian distribution. The second Mixture Model presented is a Hybrid Gaussian-Laplacian Mixture Model (HGLMM) which is based on a weighted geometric mean of the Gaussian and Laplacian distribution. An interesting property of the Expectation-Maximization algorithm for the latter is that in the maximization step, each dimension in each component is chosen to be either a Gaussian or a Laplacian. Finally, by using the new Fisher Vectors derived from HGLMMs, we achieve state-of-the-art results for both the image annotation and the image search by a sentence tasks.