 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMellum2 Technical Report
May 29, 2026We present Mellum 2, an open-weight 12B-parameter Mixture-of-Experts (MoE) language model with 2.5B active parameters per token. Mellum 2 is a general-purpose language model specialized in software engineering, spanning code generation and editing, debugging, multi-step reasoning, tool use and function calling, agentic coding, and conversational programming assistance, and it is the successor to the completion-focused 4B dense Mellum model. The architecture builds on the Mixture-of-Experts (64 experts, 8 active) and combines Grouped-Query Attention with 4 KV heads, Sliding Window Attention on three of every four layers, and a single Multi-Token Prediction head that doubles as both an auxiliary pre-training objective and a built-in draft model for speculative decoding; each choice was validated by ablation with inference efficiency on commodity GPUs as a design constraint. Pre-training spans approximately 10.6 trillion tokens through a three-phase curriculum that progressively shifts the mixture from diverse web data toward curated code and mathematical content, optimized with Muon under FP8 hybrid precision and a Warmup-Hold-Decay schedule with linear decay to zero. The pre-trained base is extended to a 128K context window via a layer-selective YaRN and then post-trained in two stages (supervised fine-tuning followed by RLVR), yielding two released variants: an Instruct model that answers directly and a Thinking model that emits an explicit reasoning trace before its final answer. Across code generation, math and reasoning, tool use, knowledge, and safety benchmarks, Mellum 2 is competitive with open-weight baselines in the 4B-14B range while running at the per-token compute of a 2.5B dense model. We release the base, instruct, and thinking checkpoints, together with this report on the architecture decisions, data pipeline, and training recipe behind them, under the Apache 2.0 license.
Augmenting In-Context-Learning in LLMs via Automatic Data Labeling and Refinement
Oct 14, 2024It has been shown that Large Language Models' (LLMs) performance can be improved for many tasks using Chain of Thought (CoT) or In-Context Learning (ICL), which involve demonstrating the steps needed to solve a task using a few examples. However, while datasets with input-output pairs are relatively easy to produce, providing demonstrations which include intermediate steps requires cumbersome manual work. These steps may be executable programs, as in agentic flows, or step-by-step reasoning as in CoT. In this work, we propose Automatic Data Labeling and Refinement (ADLR), a method to automatically generate and filter demonstrations which include the above intermediate steps, starting from a small seed of manually crafted examples. We demonstrate the advantage of ADLR in code-based table QA and mathematical reasoning, achieving up to a 5.5% gain. The code implementing our method is provided in the Supplementary material and will be made available.
NumeroLogic: Number Encoding for Enhanced LLMs' Numerical Reasoning
Mar 30, 2024



Language models struggle with handling numerical data and performing arithmetic operations. We hypothesize that this limitation can be partially attributed to non-intuitive textual numbers representation. When a digit is read or generated by a causal language model it does not know its place value (e.g. thousands vs. hundreds) until the entire number is processed. To address this issue, we propose a simple adjustment to how numbers are represented by including the count of digits before each number. For instance, instead of "42", we suggest using "{2:42}" as the new format. This approach, which we term NumeroLogic, offers an added advantage in number generation by serving as a Chain of Thought (CoT). By requiring the model to consider the number of digits first, it enhances the reasoning process before generating the actual number. We use arithmetic tasks to demonstrate the effectiveness of the NumeroLogic formatting. We further demonstrate NumeroLogic applicability to general natural language modeling, improving language understanding performance in the MMLU benchmark.
CHARTER: heatmap-based multi-type chart data extraction
Nov 28, 2021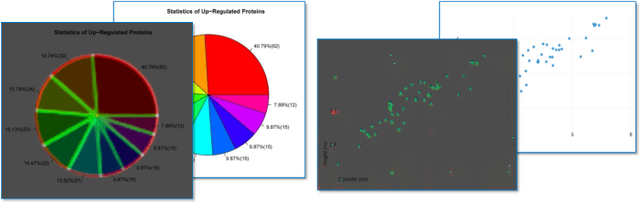
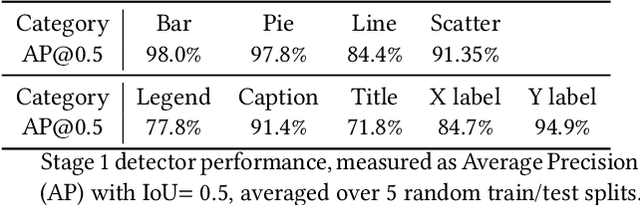
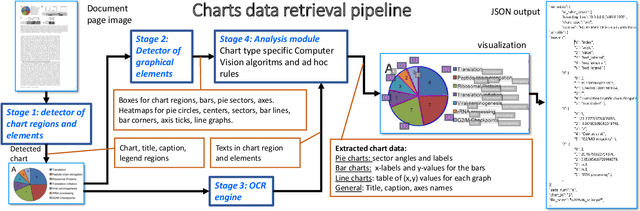
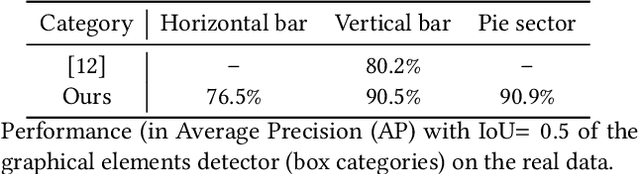
The digital conversion of information stored in documents is a great source of knowledge. In contrast to the documents text, the conversion of the embedded documents graphics, such as charts and plots, has been much less explored. We present a method and a system for end-to-end conversion of document charts into machine readable tabular data format, which can be easily stored and analyzed in the digital domain. Our approach extracts and analyses charts along with their graphical elements and supporting structures such as legends, axes, titles, and captions. Our detection system is based on neural networks, trained solely on synthetic data, eliminating the limiting factor of data collection. As opposed to previous methods, which detect graphical elements using bounding-boxes, our networks feature auxiliary domain specific heatmaps prediction enabling the precise detection of pie charts, line and scatter plots which do not fit the rectangular bounding-box presumption. Qualitative and quantitative results show high robustness and precision, improving upon previous works on popular benchmarks
* Joseph Shtok, Sivan Harary and Leonid Karlinsky had equal contribution
Detector-Free Weakly Supervised Grounding by Separation
Apr 20, 2021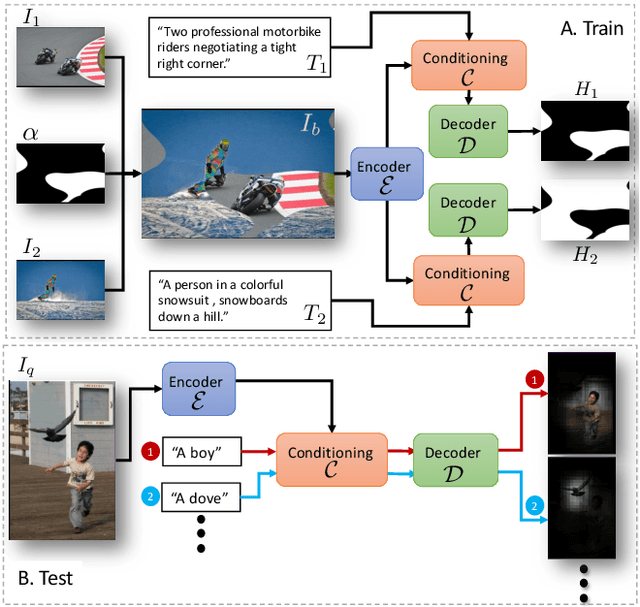
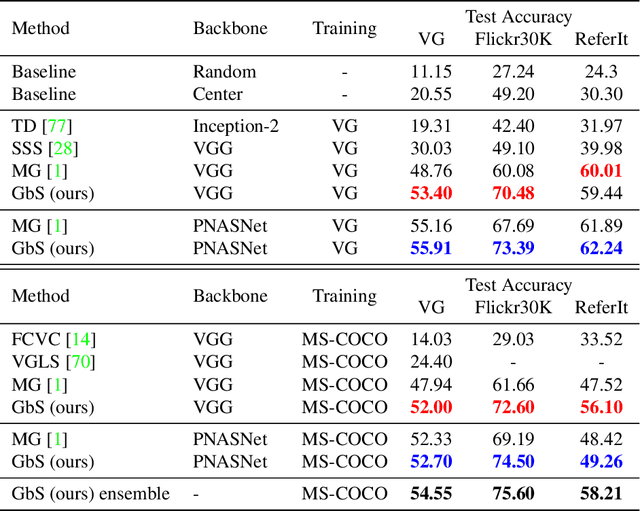
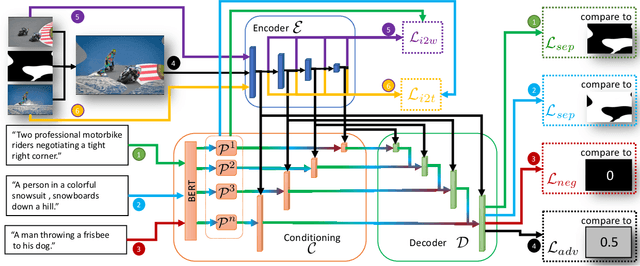
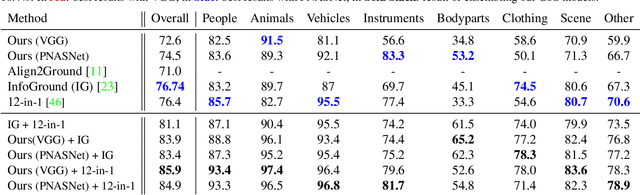
Nowadays, there is an abundance of data involving images and surrounding free-form text weakly corresponding to those images. Weakly Supervised phrase-Grounding (WSG) deals with the task of using this data to learn to localize (or to ground) arbitrary text phrases in images without any additional annotations. However, most recent SotA methods for WSG assume the existence of a pre-trained object detector, relying on it to produce the ROIs for localization. In this work, we focus on the task of Detector-Free WSG (DF-WSG) to solve WSG without relying on a pre-trained detector. We directly learn everything from the images and associated free-form text pairs, thus potentially gaining an advantage on the categories unsupported by the detector. The key idea behind our proposed Grounding by Separation (GbS) method is synthesizing `text to image-regions' associations by random alpha-blending of arbitrary image pairs and using the corresponding texts of the pair as conditions to recover the alpha map from the blended image via a segmentation network. At test time, this allows using the query phrase as a condition for a non-blended query image, thus interpreting the test image as a composition of a region corresponding to the phrase and the complement region. Using this approach we demonstrate a significant accuracy improvement, of up to $8.5\%$ over previous DF-WSG SotA, for a range of benchmarks including Flickr30K, Visual Genome, and ReferIt, as well as a significant complementary improvement (above $7\%$) over the detector-based approaches for WSG.
StarNet: towards weakly supervised few-shot detection and explainable few-shot classification
Mar 15, 2020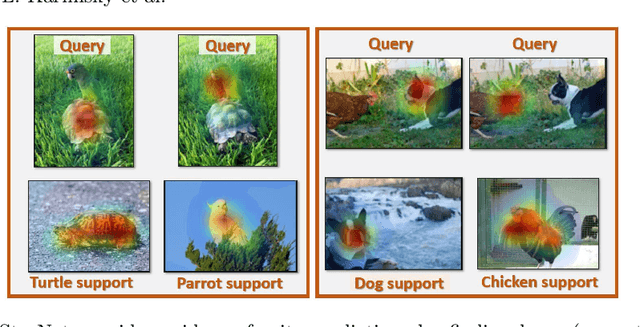
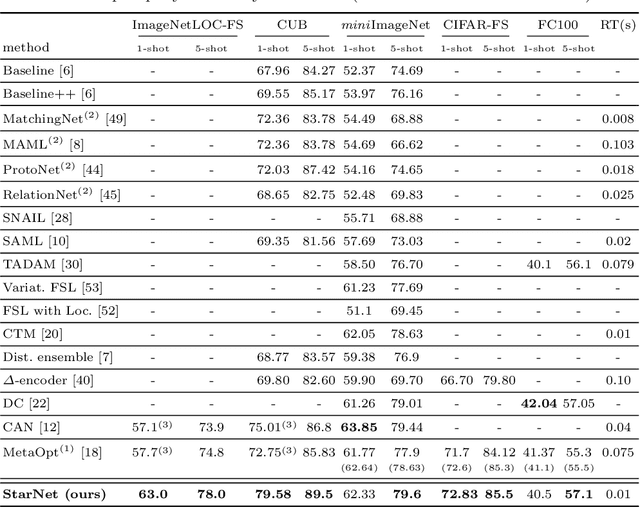
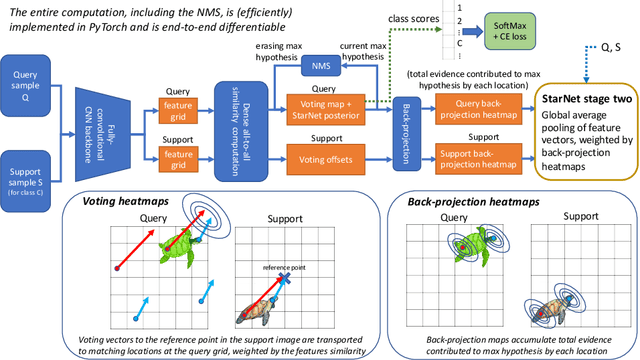
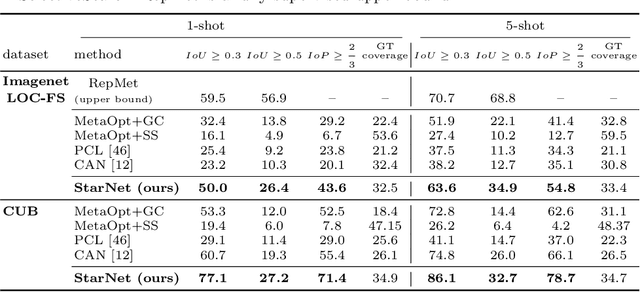
In this paper, we propose a new few-shot learning method called StarNet, which is an end-to-end trainable non-parametric star-model few-shot classifier. While being meta-trained using only image-level class labels, StarNet learns not only to predict the class labels for each query image of a few-shot task, but also to localize (via a heatmap) what it believes to be the key image regions supporting its prediction, thus effectively detecting the instances of the novel categories. The localization is enabled by the StarNet's ability to find large, arbitrarily shaped, semantically matching regions between all pairs of support and query images of a few-shot task. We evaluate StarNet on multiple few-shot classification benchmarks attaining significant state-of-the-art improvement on the CUB and ImageNetLOC-FS, and smaller improvements on other benchmarks. At the same time, in many cases, StarNet provides plausible explanations for its class label predictions, by highlighting the correctly paired novel category instances on the query and on its best matching support (for the predicted class). In addition, we test the proposed approach on the previously unexplored and challenging task of Weakly Supervised Few-Shot Object Detection (WS-FSOD), obtaining significant improvements over the baselines.
LaSO: Label-Set Operations networks for multi-label few-shot learning
Feb 26, 2019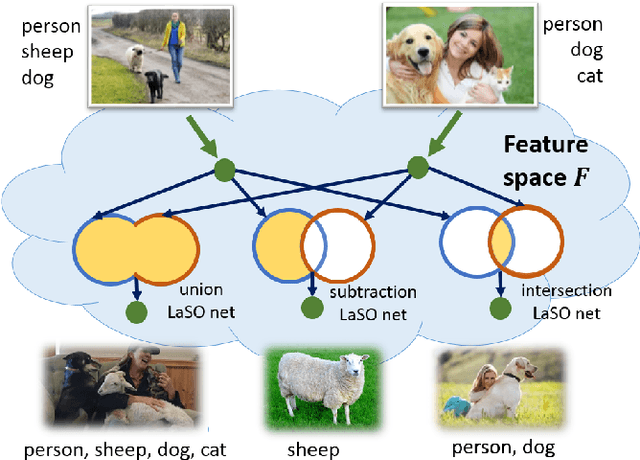
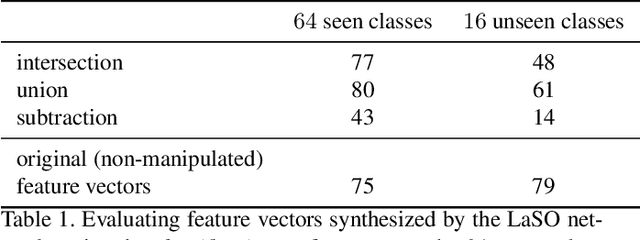

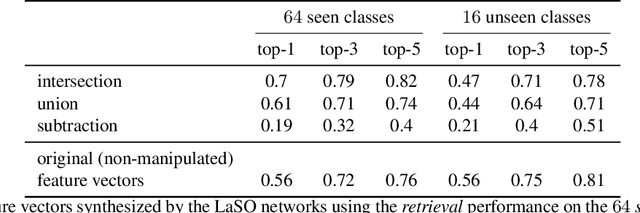
Example synthesis is one of the leading methods to tackle the problem of few-shot learning, where only a small number of samples per class are available. However, current synthesis approaches only address the scenario of a single category label per image. In this work, we propose a novel technique for synthesizing samples with multiple labels for the (yet unhandled) multi-label few-shot classification scenario. We propose to combine pairs of given examples in feature space, so that the resulting synthesized feature vectors will correspond to examples whose label sets are obtained through certain set operations on the label sets of the corresponding input pairs. Thus, our method is capable of producing a sample containing the intersection, union or set-difference of labels present in two input samples. As we show, these set operations generalize to labels unseen during training. This enables performing augmentation on examples of novel categories, thus, facilitating multi-label few-shot classifier learning. We conduct numerous experiments showing promising results for the label-set manipulation capabilities of the proposed approach, both directly (using the classification and retrieval metrics), and in the context of performing data augmentation for multi-label few-shot learning. We propose a benchmark for this new and challenging task and show that our method compares favorably to all the common baselines.
RepMet: Representative-based metric learning for classification and one-shot object detection
Jun 15, 2018
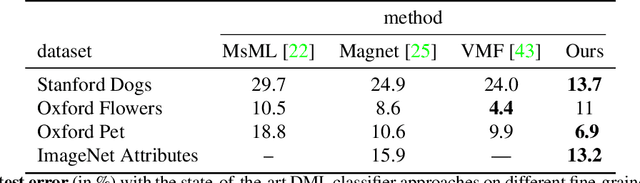
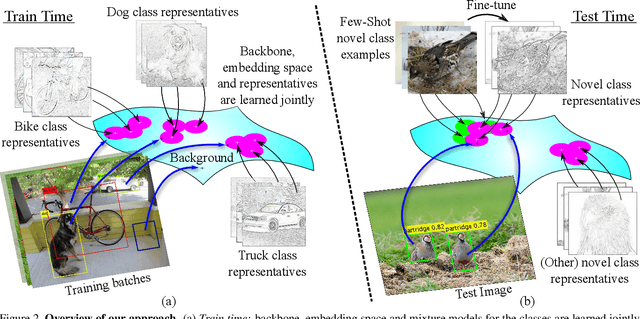
Distance metric learning (DML) has been successfully applied to object classification, both in the standard regime of rich training data and in the few-shot scenario, where each category is represented by only few examples. In this work, we propose a new method for DML, featuring a joint learning of the embedding space and of the data distribution of the training categories, in a single training process. Our method improves upon leading algorithms for DML-based object classification. Furthermore, it opens the door for a new task in Computer Vision - a few-shot object detection, since the proposed DML architecture can be naturally embedded as the classification head of any standard object detector. In numerous experiments, we achieve state-of-the-art classification results on a variety of fine-grained datasets, and offer the community a benchmark on the few-shot detection task, performed on the Imagenet-LOC dataset. The code will be made available upon acceptance.
Delta-encoder: an effective sample synthesis method for few-shot object recognition
Jun 12, 2018
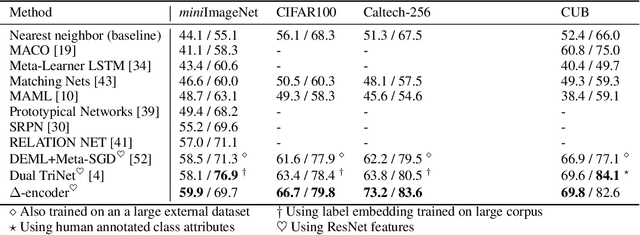
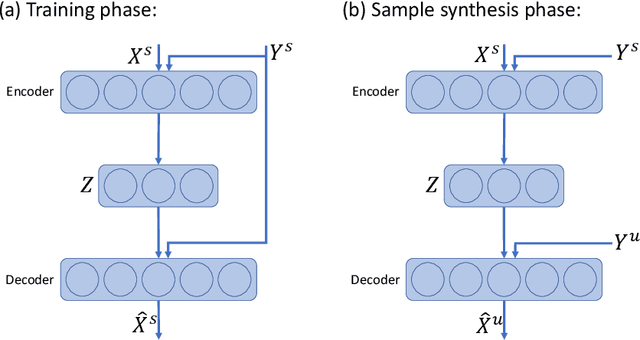

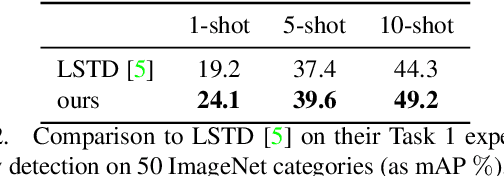
Learning to classify new categories based on just one or a few examples is a long-standing challenge in modern computer vision. In this work, we proposes a simple yet effective method for few-shot (and one-shot) object recognition. Our approach is based on a modified auto-encoder, denoted Delta-encoder, that learns to synthesize new samples for an unseen category just by seeing few examples from it. The synthesized samples are then used to train a classifier. The proposed approach learns to both extract transferable intra-class deformations, or "deltas", between same-class pairs of training examples, and to apply those deltas to the few provided examples of a novel class (unseen during training) in order to efficiently synthesize samples from that new class. The proposed method improves over the state-of-the-art in one-shot object-recognition and compares favorably in the few-shot case. Upon acceptance code will be made available.
Spatially-Adaptive Reconstruction in Computed Tomography using Neural Networks
Nov 28, 2013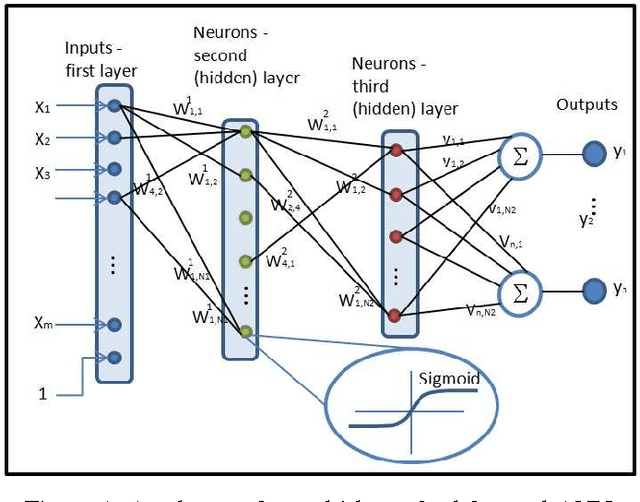
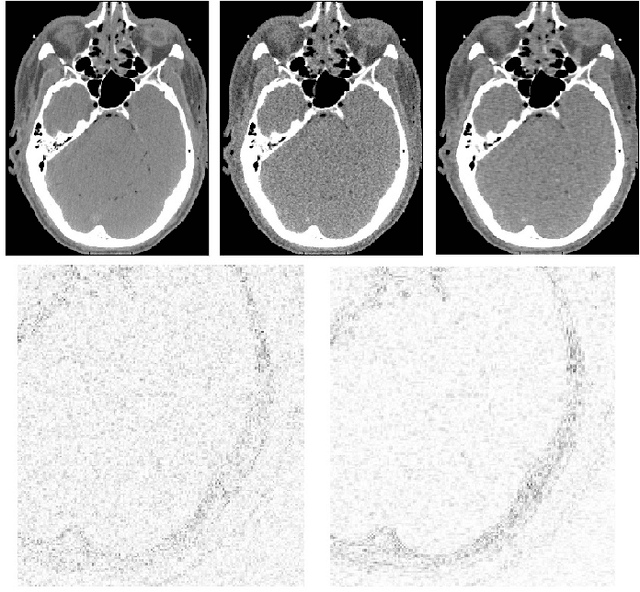
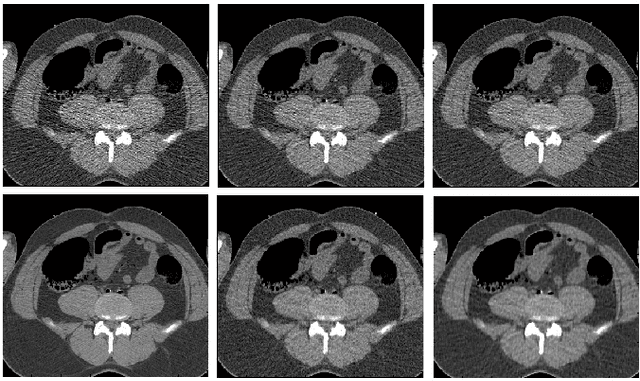
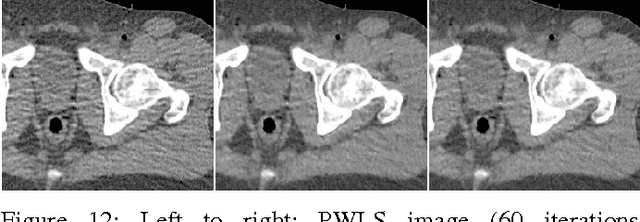
We propose a supervised machine learning approach for boosting existing signal and image recovery methods and demonstrate its efficacy on example of image reconstruction in computed tomography. Our technique is based on a local nonlinear fusion of several image estimates, all obtained by applying a chosen reconstruction algorithm with different values of its control parameters. Usually such output images have different bias/variance trade-off. The fusion of the images is performed by feed-forward neural network trained on a set of known examples. Numerical experiments show an improvement in reconstruction quality relatively to existing direct and iterative reconstruction methods.