 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Lung Cancer Risk Estimation with Incomplete Data: A Joint Missing Imputation Perspective
Jul 25, 2021
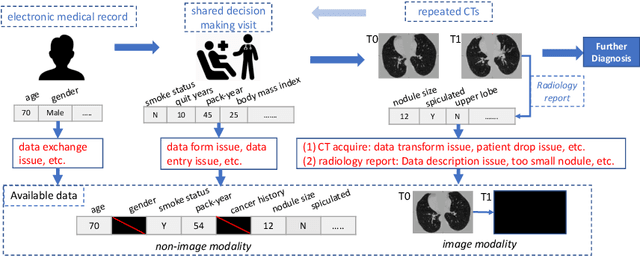
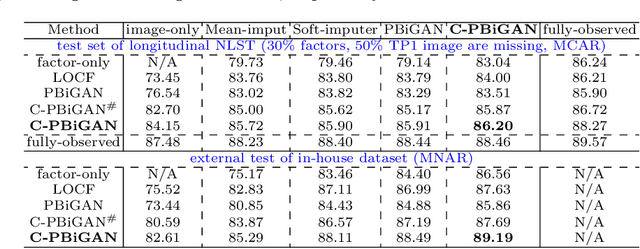
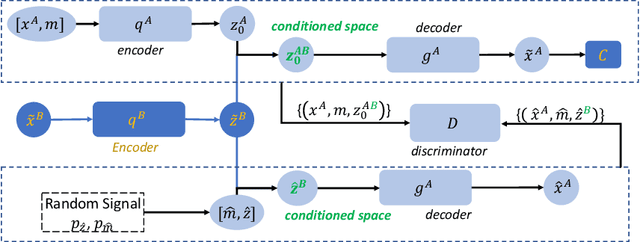
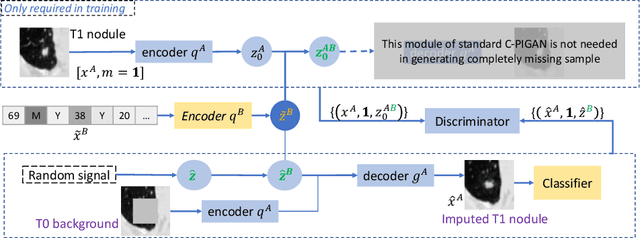
Data from multi-modality provide complementary information in clinical prediction, but missing data in clinical cohorts limits the number of subjects in multi-modal learning context. Multi-modal missing imputation is challenging with existing methods when 1) the missing data span across heterogeneous modalities (e.g., image vs. non-image); or 2) one modality is largely missing. In this paper, we address imputation of missing data by modeling the joint distribution of multi-modal data. Motivated by partial bidirectional generative adversarial net (PBiGAN), we propose a new Conditional PBiGAN (C-PBiGAN) method that imputes one modality combining the conditional knowledge from another modality. Specifically, C-PBiGAN introduces a conditional latent space in a missing imputation framework that jointly encodes the available multi-modal data, along with a class regularization loss on imputed data to recover discriminative information. To our knowledge, it is the first generative adversarial model that addresses multi-modal missing imputation by modeling the joint distribution of image and non-image data. We validate our model with both the national lung screening trial (NLST) dataset and an external clinical validation cohort. The proposed C-PBiGAN achieves significant improvements in lung cancer risk estimation compared with representative imputation methods (e.g., AUC values increase in both NLST (+2.9\%) and in-house dataset (+4.3\%) compared with PBiGAN, p$<$0.05).
Development of the algorithm for differentiating bone metastases and trauma of the ribs in bone scintigraphy and demonstration of visual evidence of the algorithm -- Using only anterior bone scan view of thorax
Sep 30, 2021Background: Although there are many studies on the application of artificial intelligence (AI) models to medical imaging, there is no report of an AI model that determines the accumulation of ribs in bone metastases and trauma only using the anterior image of thorax of bone scintigraphy. In recent years, a method for visualizing diagnostic grounds called Gradient-weighted Class Activation Mapping (Grad-CAM) has been proposed in the area of diagnostic images using Deep Convolutional Neural Network (DCNN). As far as we have investigated, there are no reports of visualization of the diagnostic basis in bone scintigraphy. Our aim is to visualize the area of interest of DCNN, in addition to developing an algorithm to classify and diagnose whether RI accumulation on the ribs is bone metastasis or trauma using only anterior bone scan view of thorax. Material and Methods: For this retrospective study, we used 838 patients who underwent bone scintigraphy to search for bone metastases at our institution. A frontal chest image of bone scintigraphy was used to create the algorithm. We used 437 cases with bone metastases on the ribs and 401 cases with abnormal RI accumulation due to trauma. Result: AI model was able to detect bone metastasis lesion with a sensitivity of 90.00% and accuracy of 86.5%. And it was possible to visualize the part that the AI model focused on with Grad-CAM.
Neural Image Compression for Gigapixel Histopathology Image Analysis
Nov 07, 2018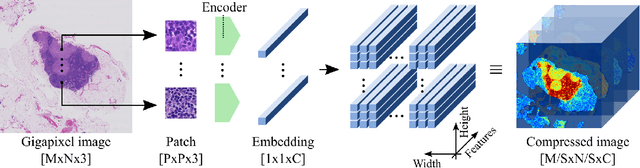

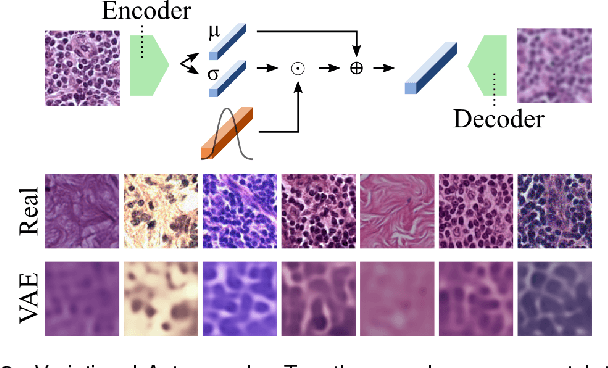
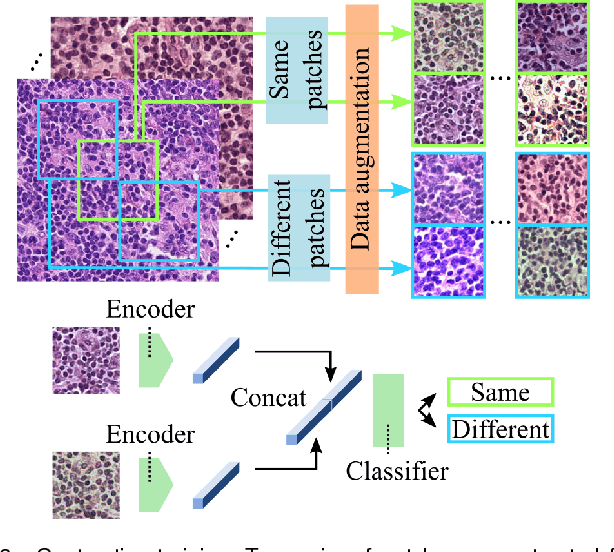
We present Neural Image Compression (NIC), a method to reduce the size of gigapixel images by mapping them to a compact latent space using neural networks. We show that this compression allows us to train convolutional neural networks on histopathology whole-slide images end-to-end using weak image-level labels.
Reversible Adversarial Example based on Reversible Image Transformation
Dec 05, 2019

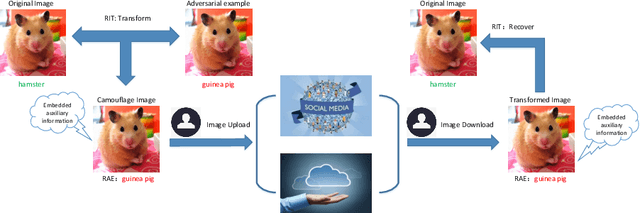

At present there are many companies that take the most advanced Deep Neural Networks (DNNs) to classify and analyze photos we upload to social networks or the cloud. In order to prevent users privacy from leakage, the attack characteristics of the adversarial example can be exploited to make these models misjudged. In this paper, we take advantage of reversible image transformation to construct reversible adversarial example, which is still an adversarial example to DNNs. It not only allows DNNs to extract the wrong information, but also can be recovered to its original image without any distortion. Experimental results show that reversible adversarial examples obtained by our method have higher attack success rates while ensuring that the reversible image quality is still high. Moreover, the proposed method is easy to operate, suitable for practical applications.
MetaMedSeg: Volumetric Meta-learning for Few-Shot Organ Segmentation
Sep 18, 2021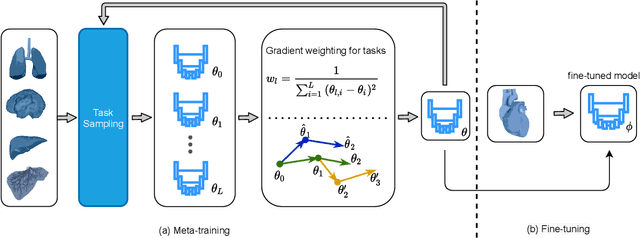
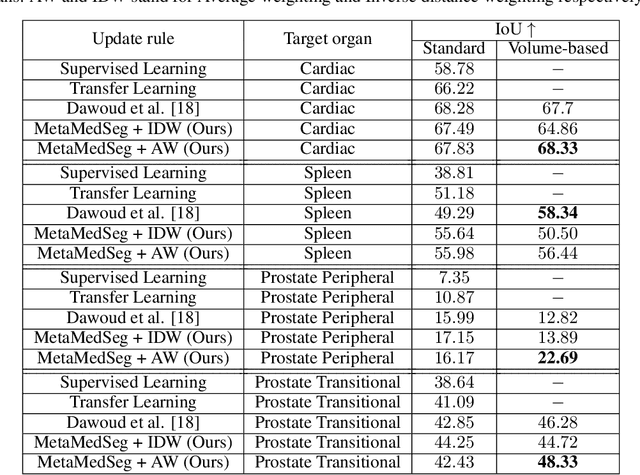
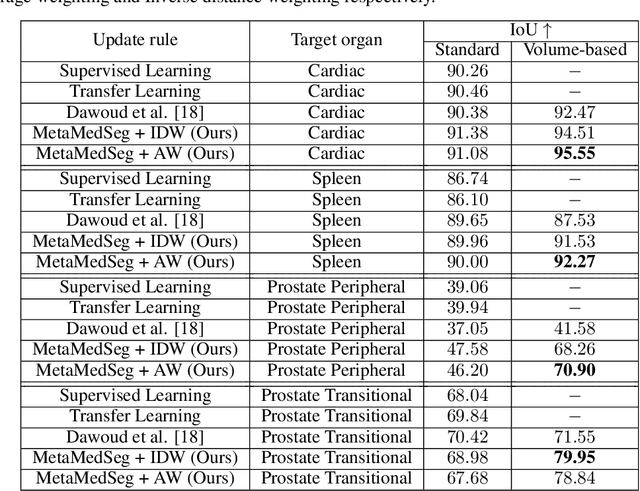
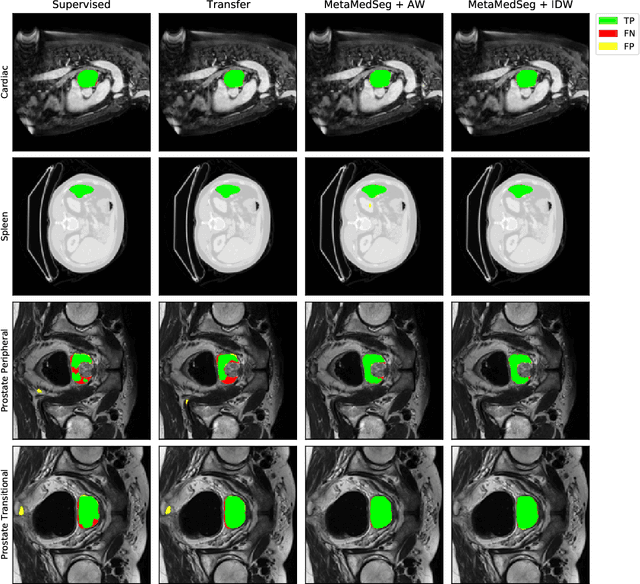
The lack of sufficient annotated image data is a common issue in medical image segmentation. For some organs and densities, the annotation may be scarce, leading to poor model training convergence, while other organs have plenty of annotated data. In this work, we present MetaMedSeg, a gradient-based meta-learning algorithm that redefines the meta-learning task for the volumetric medical data with the goal to capture the variety between the slices. We also explore different weighting schemes for gradients aggregation, arguing that different tasks might have different complexity, and hence, contribute differently to the initialization. We propose an importance-aware weighting scheme to train our model. In the experiments, we present an evaluation of the medical decathlon dataset by extracting 2D slices from CT and MRI volumes of different organs and performing semantic segmentation. The results show that our proposed volumetric task definition leads to up to 30% improvement in terms of IoU compared to related baselines. The proposed update rule is also shown to improve the performance for complex scenarios where the data distribution of the target organ is very different from the source organs.
COVID-19 Detection on Chest X-Ray Images: A comparison of CNN architectures and ensembles
Nov 18, 2021
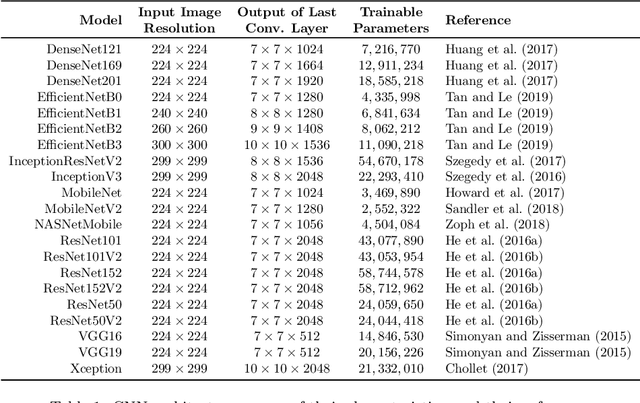
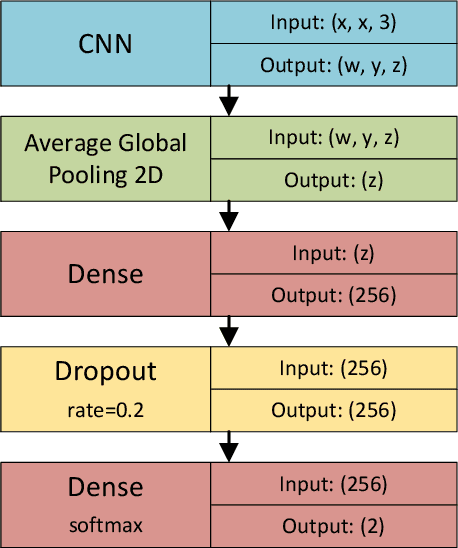
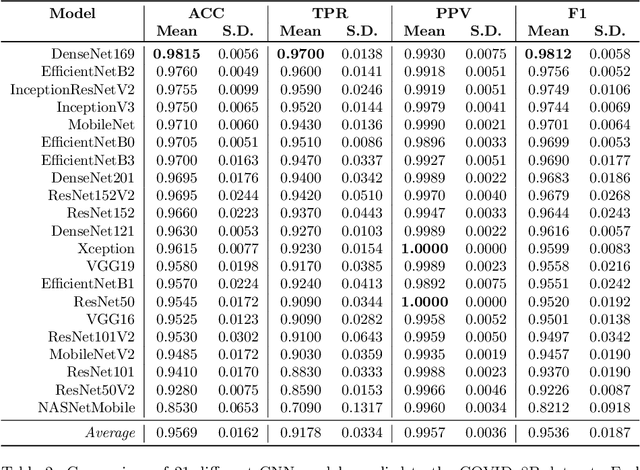
COVID-19 quickly became a global pandemic after only four months of its first detection. It is crucial to detect this disease as soon as possible to decrease its spread. The use of chest X-ray (CXR) images became an effective screening strategy, complementary to the reverse transcription-polymerase chain reaction (RT-PCR). Convolutional neural networks (CNNs) are often used for automatic image classification and they can be very useful in CXR diagnostics. In this paper, 21 different CNN architectures are tested and compared in the task of identifying COVID-19 in CXR images. They were applied to the COVIDx8B dataset, which is the largest and more diverse COVID-19 dataset available. Ensembles of CNNs were also employed and they showed better efficacy than individual instances. The best individual CNN instance results were achieved by DenseNet169, with an accuracy of 98.15% and an F1 score of 98.12%. These were further increased to 99.25% and 99.24%, respectively, through an ensemble with five instances of DenseNet169. These results are higher than those obtained in recent works using the same dataset.
Learned Variable-Rate Image Compression with Residual Divisive Normalization
Dec 11, 2019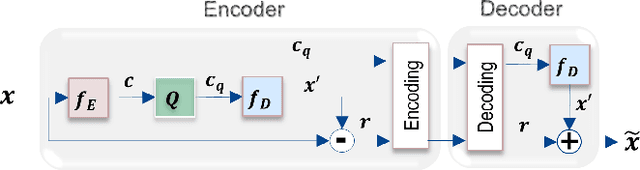
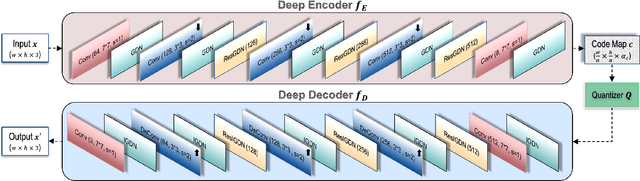
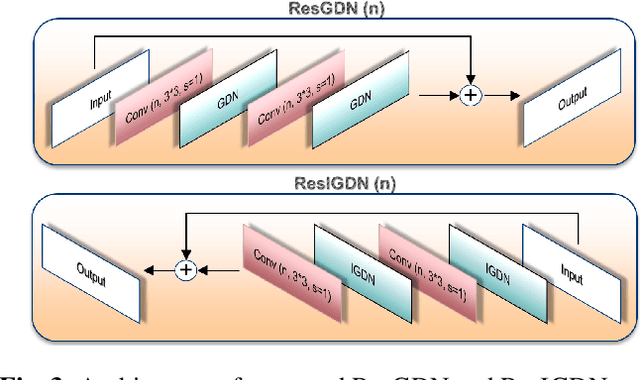
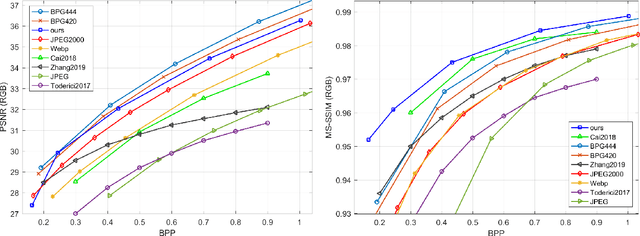
Recently it has been shown that deep learning-based image compression has shown the potential to outperform traditional codecs. However, most existing methods train multiple networks for multiple bit rates, which increases the implementation complexity. In this paper, we propose a variable-rate image compression framework, which employs more Generalized Divisive Normalization (GDN) layers than previous GDN-based methods. Novel GDN-based residual sub-networks are also developed in the encoder and decoder networks. Our scheme also uses a stochastic rounding-based scalable quantization. To further improve the performance, we encode the residual between the input and the reconstructed image from the decoder network as an enhancement layer. To enable a single model to operate with different bit rates and to learn multi-rate image features, a new objective function is introduced. Experimental results show that the proposed framework trained with variable-rate objective function outperforms all standard codecs such as H.265/HEVC-based BPG and state-of-the-art learning-based variable-rate methods.
Use of the Deep Learning Approach to Measure Alveolar Bone Level
Sep 24, 2021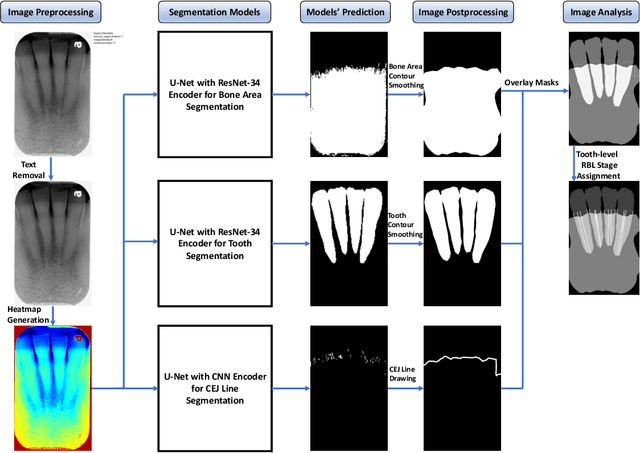
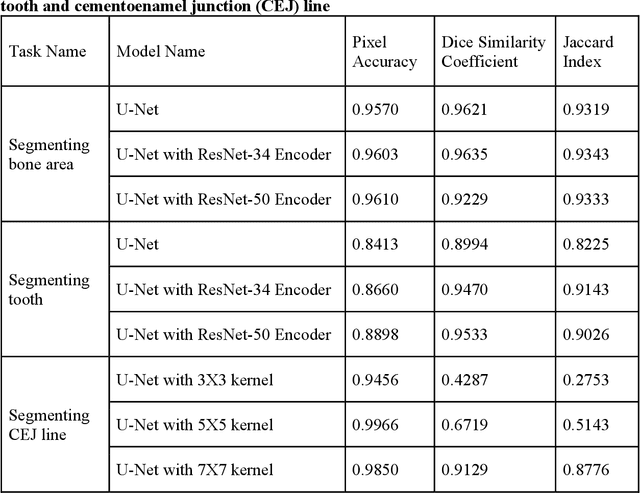
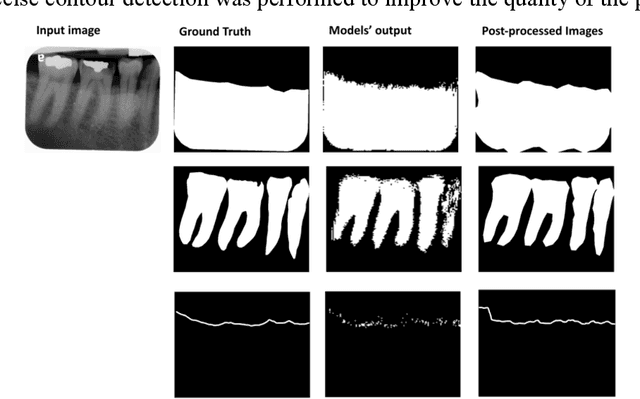
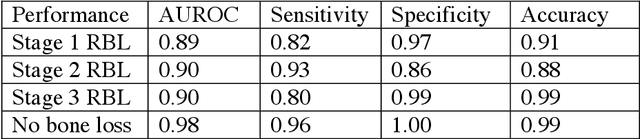
Abstract: Aim: The goal was to use a Deep Convolutional Neural Network to measure the radiographic alveolar bone level to aid periodontal diagnosis. Material and methods: A Deep Learning (DL) model was developed by integrating three segmentation networks (bone area, tooth, cementoenamel junction) and image analysis to measure the radiographic bone level and assign radiographic bone loss (RBL) stages. The percentage of RBL was calculated to determine the stage of RBL for each tooth. A provisional periodontal diagnosis was assigned using the 2018 periodontitis classification. RBL percentage, staging, and presumptive diagnosis were compared to the measurements and diagnoses made by the independent examiners. Results: The average Dice Similarity Coefficient (DSC) for segmentation was over 0.91. There was no significant difference in RBL percentage measurements determined by DL and examiners (p=0.65). The Area Under the Receiver Operating Characteristics Curve of RBL stage assignment for stage I, II and III was 0.89, 0.90 and 0.90, respectively. The accuracy of the case diagnosis was 0.85. Conclusion: The proposed DL model provides reliable RBL measurements and image-based periodontal diagnosis using periapical radiographic images. However, this model has to be further optimized and validated by a larger number of images to facilitate its application.
Benchmarking Deep Deblurring Algorithms: A Large-Scale Multi-Cause Dataset and A New Baseline Model
Dec 01, 2021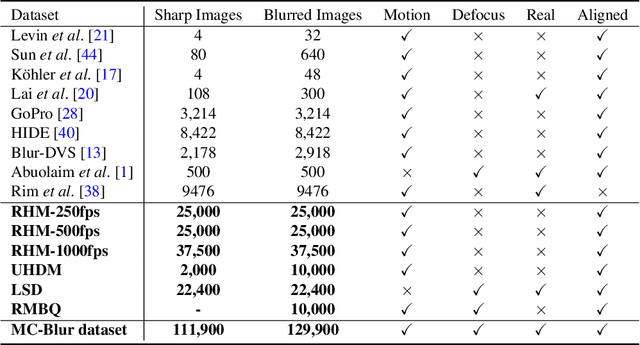
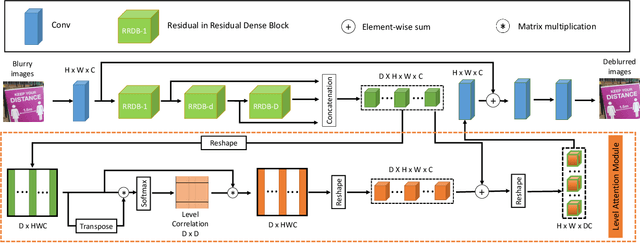

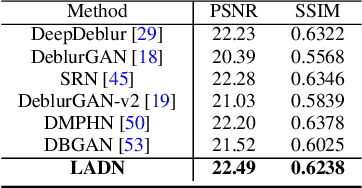
Blur artifacts can seriously degrade the visual quality of images, and numerous deblurring methods have been proposed for specific scenarios. However, in most real-world images, blur is caused by different factors, e.g., motion and defocus. In this paper, we address how different deblurring methods perform on general types of blur. For in-depth performance evaluation, we construct a new large-scale multi-cause image deblurring dataset called (MC-Blur) including real-world and synthesized blurry images with mixed factors of blurs. The images in the proposed MC-Blur dataset are collected using different techniques: convolving Ultra-High-Definition (UHD) sharp images with large kernels, averaging sharp images captured by a 1000 fps high-speed camera, adding defocus to images, and real-world blurred images captured by various camera models. These results provide a comprehensive overview of the advantages and limitations of current deblurring methods. Further, we propose a new baseline model, level-attention deblurring network, to adapt to multiple causes of blurs. By including different weights of attention to the different levels of features, the proposed network derives more powerful features with larger weights assigned to more important levels, thereby enhancing the feature representation. Extensive experimental results on the new dataset demonstrate the effectiveness of the proposed model for the multi-cause blur scenarios.
Real-MFF Dataset: A Large Realistic Multi-focus Image Dataset with Ground Truth
Mar 28, 2020



Multi-focus image fusion, a technique to generate an all-in-focus image from two or more source images, can benefit many computer vision tasks. However, currently there is no large and realistic dataset to perform convincing evaluation and comparison for exiting multi-focus image fusion. For deep learning methods, it is difficult to train a network without a suitable dataset. In this paper, we introduce a large and realistic multi-focus dataset containing 800 pairs of source images with the corresponding ground truth images. The dataset is generated using a light field camera, consequently, the source images as well as the ground truth images are realistic. Moreover, the dataset contains a variety of scenes, including buildings, plants, humans, shopping malls, squares and so on, to serve as a well-founded benchmark for multi-focus image fusion tasks. For illustration, we evaluate 10 typical multi-focus algorithms on this dataset.