 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pyramid Fusion Transformer for Semantic Segmentation
Jan 11, 2022

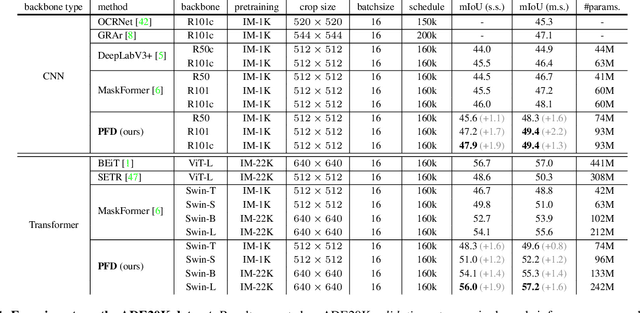
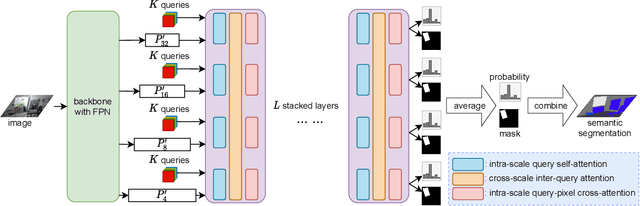
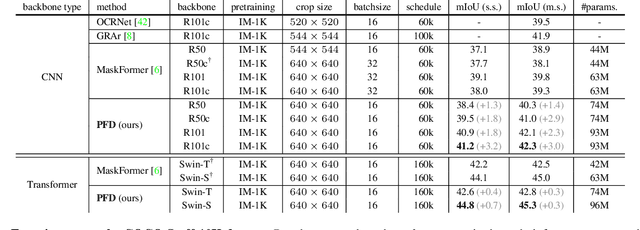
The recently proposed MaskFormer \cite{maskformer} gives a refreshed perspective on the task of semantic segmentation: it shifts from the popular pixel-level classification paradigm to a mask-level classification method. In essence, it generates paired probabilities and masks corresponding to category segments and combines them during inference for the segmentation maps. The segmentation quality thus relies on how well the queries can capture the semantic information for categories and their spatial locations within the images. In our study, we find that per-mask classification decoder on top of a single-scale feature is not effective enough to extract reliable probability or mask. To mine for rich semantic information across the feature pyramid, we propose a transformer-based Pyramid Fusion Transformer (PFT) for per-mask approach semantic segmentation on top of multi-scale features. To efficiently utilize image features of different resolutions without incurring too much computational overheads, PFT uses a multi-scale transformer decoder with cross-scale inter-query attention to exchange complimentary information. Extensive experimental evaluations and ablations demonstrate the efficacy of our framework. In particular, we achieve a 3.2 mIoU improvement on COCO-Stuff 10K dataset with ResNet-101c compared to MaskFormer. Besides, on ADE20K validation set, our result with Swin-B backbone matches that of MaskFormer's with a much larger Swin-L backbone in both single-scale and multi-scale inference, achieving 54.1 mIoU and 55.3 mIoU respectively. Using a Swin-L backbone, we achieve 56.0 mIoU single-scale result on the ADE20K validation set and 57.2 multi-scale result, obtaining state-of-the-art performance on the dataset.
Overview of the HECKTOR Challenge at MICCAI 2021: Automatic Head and Neck Tumor Segmentation and Outcome Prediction in PET/CT Images
Jan 11, 2022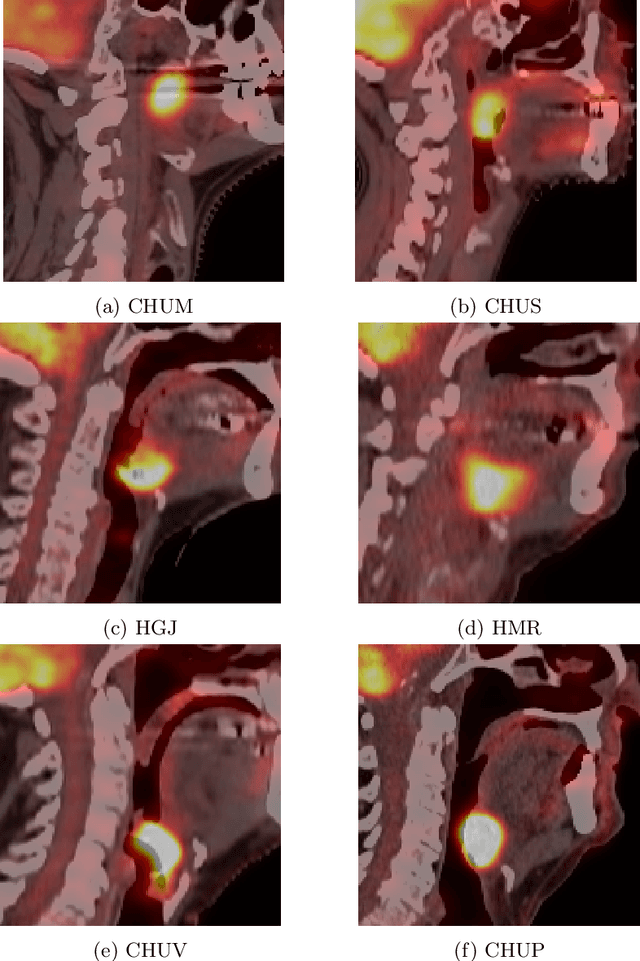
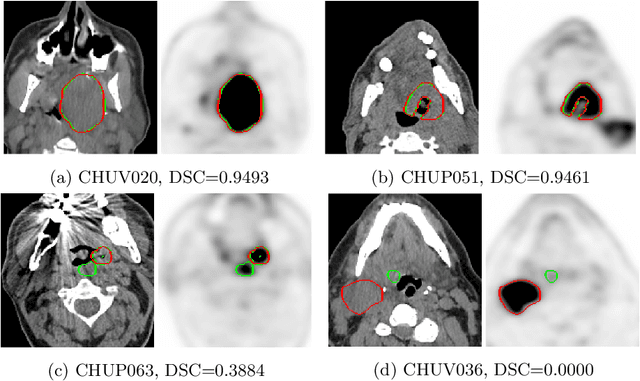
This paper presents an overview of the second edition of the HEad and neCK TumOR (HECKTOR) challenge, organized as a satellite event of the 24th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI) 2021. The challenge is composed of three tasks related to the automatic analysis of PET/CT images for patients with Head and Neck cancer (H&N), focusing on the oropharynx region. Task 1 is the automatic segmentation of H&N primary Gross Tumor Volume (GTVt) in FDG-PET/CT images. Task 2 is the automatic prediction of Progression Free Survival (PFS) from the same FDG-PET/CT. Finally, Task 3 is the same as Task 2 with ground truth GTVt annotations provided to the participants. The data were collected from six centers for a total of 325 images, split into 224 training and 101 testing cases. The interest in the challenge was highlighted by the important participation with 103 registered teams and 448 result submissions. The best methods obtained a Dice Similarity Coefficient (DSC) of 0.7591 in the first task, and a Concordance index (C-index) of 0.7196 and 0.6978 in Tasks 2 and 3, respectively. In all tasks, simplicity of the approach was found to be key to ensure generalization performance. The comparison of the PFS prediction performance in Tasks 2 and 3 suggests that providing the GTVt contour was not crucial to achieve best results, which indicates that fully automatic methods can be used. This potentially obviates the need for GTVt contouring, opening avenues for reproducible and large scale radiomics studies including thousands potential subjects.
Weighted Encoding Based Image Interpolation With Nonlocal Linear Regression Model
Mar 04, 2020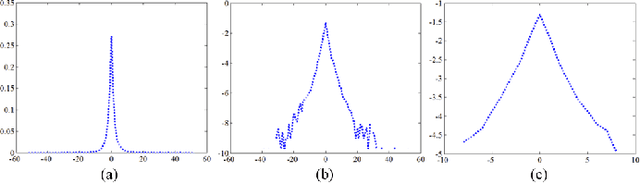



Image interpolation is a special case of image super-resolution, where the low-resolution image is directly down-sampled from its high-resolution counterpart without blurring and noise. Therefore, assumptions adopted in super-resolution models are not valid for image interpolation. To address this problem, we propose a novel image interpolation model based on sparse representation. Two widely used priors including sparsity and nonlocal self-similarity are used as the regularization terms to enhance the stability of interpolation model. Meanwhile, we incorporate the nonlocal linear regression into this model since nonlocal similar patches could provide a better approximation to a given patch. Moreover, we propose a new approach to learn adaptive sub-dictionary online instead of clustering. For each patch, similar patches are grouped to learn adaptive sub-dictionary, generating a more sparse and accurate representation. Finally, the weighted encoding is introduced to suppress tailing of fitting residuals in data fidelity. Abundant experimental results demonstrate that our proposed method outperforms several state-of-the-art methods in terms of quantitative measures and visual quality.
Fine-grained Multi-Modal Self-Supervised Learning
Dec 22, 2021
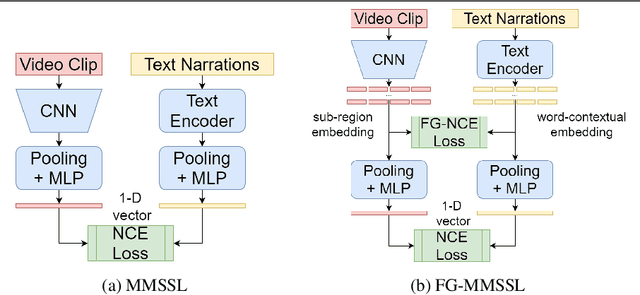

Multi-Modal Self-Supervised Learning from videos has been shown to improve model's performance on various downstream tasks. However, such Self-Supervised pre-training requires large batch sizes and a large amount of computation resources due to the noise present in the uncurated data. This is partly due to the fact that the prevalent training scheme is trained on coarse-grained setting, in which vectors representing the whole video clips or natural language sentences are used for computing similarity. Such scheme makes training noisy as part of the video clips can be totally not correlated with the other-modality input such as text description. In this paper, we propose a fine-grained multi-modal self-supervised training scheme that computes the similarity between embeddings at finer-scale (such as individual feature map embeddings and embeddings of phrases), and uses attention mechanisms to reduce noisy pairs' weighting in the loss function. We show that with the proposed pre-training scheme, we can train smaller models, with smaller batch-size and much less computational resources to achieve downstream tasks performances comparable to State-Of-The-Art, for tasks including action recognition and text-image retrievals.
SECP-Net: SE-Connection Pyramid Network of Organ At Risk Segmentation for Nasopharyngeal Carcinoma
Dec 28, 2021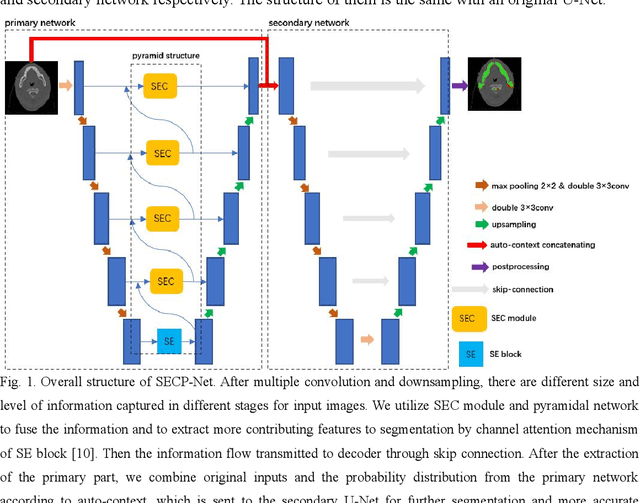
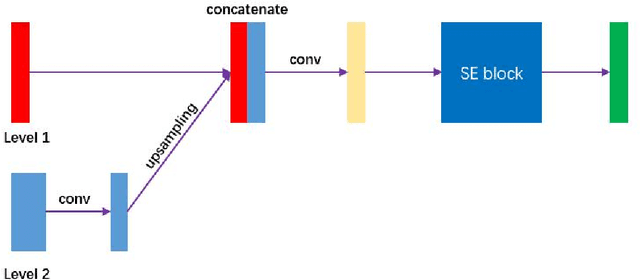
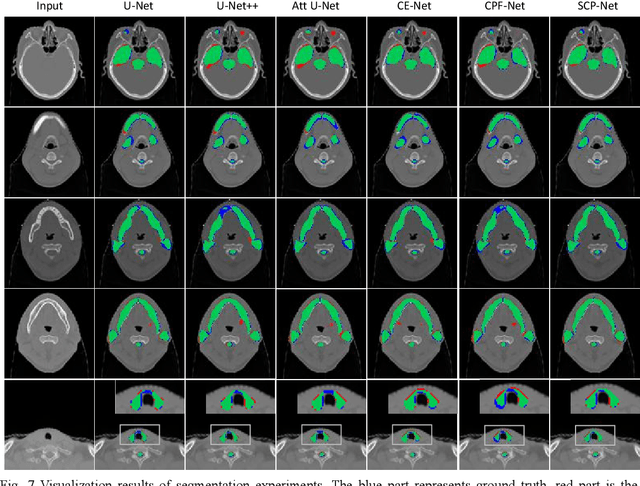
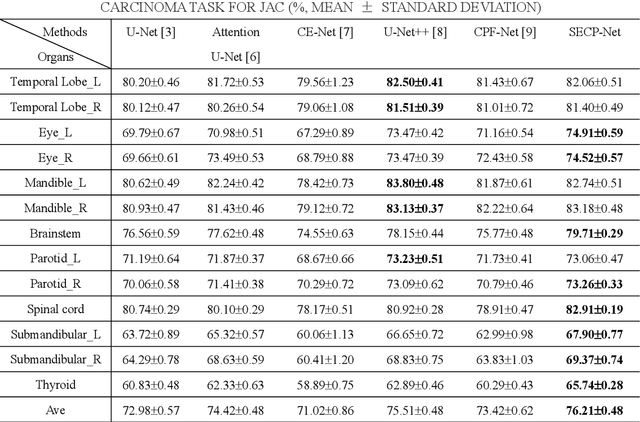
Nasopharyngeal carcinoma (NPC) is a kind of malignant tumor. Accurate and automatic segmentation of organs at risk (OAR) of computed tomography (CT) images is clinically significant. In recent years, deep learning models represented by U-Net have been widely applied in medical image segmentation tasks, which can help doctors with reduction of workload and get accurate results more quickly. In OAR segmentation of NPC, the sizes of OAR are variable, especially, some of them are small. Traditional deep neural networks underperform during segmentation due to the lack use of global and multi-size information. This paper proposes a new SE-Connection Pyramid Network (SECP-Net). SECP-Net extracts global and multi-size information flow with se connection (SEC) modules and a pyramid structure of network for improving the segmentation performance, especially that of small organs. SECP-Net also designs an auto-context cascaded network to further improve the segmentation performance. Comparative experiments are conducted between SECP-Net and other recently methods on a dataset with CT images of head and neck. Five-fold cross validation is used to evaluate the performance based on two metrics, i.e., Dice and Jaccard similarity. Experimental results show that SECP-Net can achieve SOTA performance in this challenging task.
Stationary Multi-source AI-powered Real-time Tomography (SMART) for Dynamic Cardiac Imaging
Aug 27, 2021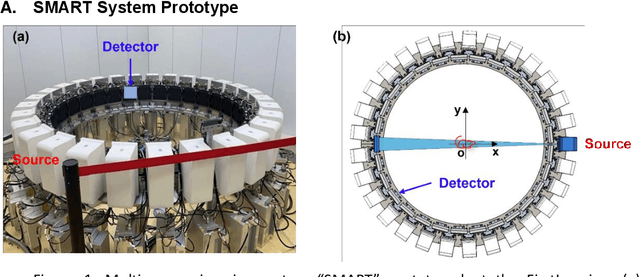
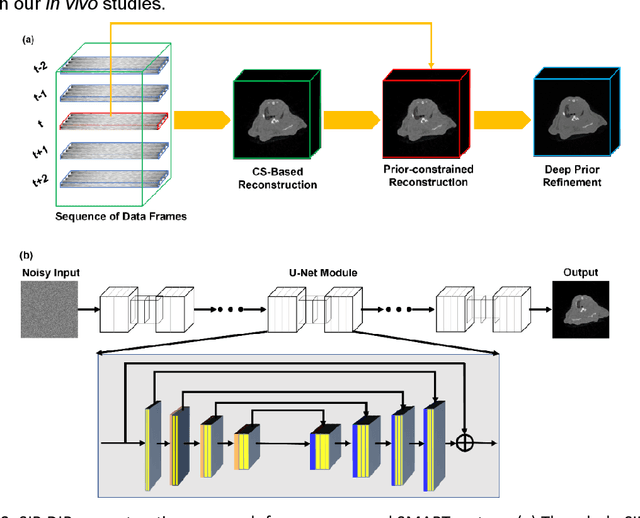
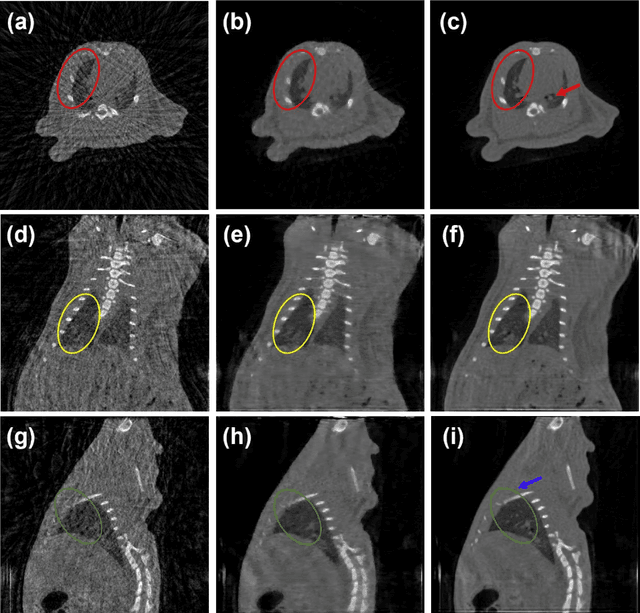

A first stationary multi-source computed tomography (CT) system is prototyped for preclinical imaging to achieve real-time temporal resolution for dynamic cardiac imaging. This unique is featured by 29 source-detector pairs fixed on a circular track for each detector to collect x-ray signals only from the opposite x-ray source. The new system architecture potentially leads to a major improvement in temporal resolution. To demonstrate the feasibility of this Stationary Multi-source AI-based Real-time Tomography (SMART) system, we develop a novel reconstruction scheme integrating both sparsified image prior (SIP) and deep image prior (DIP), which is referred to as the SIP-DIP network. Then, the SIP-DIP network for cardiac imaging is evaluated on preclinical cardiac datasets of alive rats. The reconstructed image volumes demonstrate the feasibility of the SMART system and the SIP-DIP network and the merits over other reconstruction methods.
DDet: Dual-path Dynamic Enhancement Network for Real-World Image Super-Resolution
Feb 25, 2020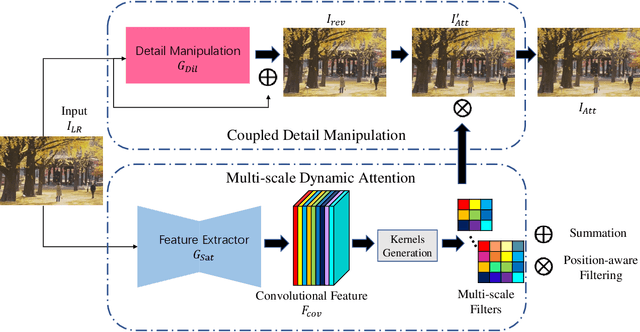
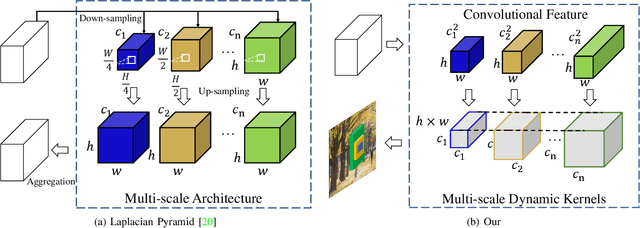

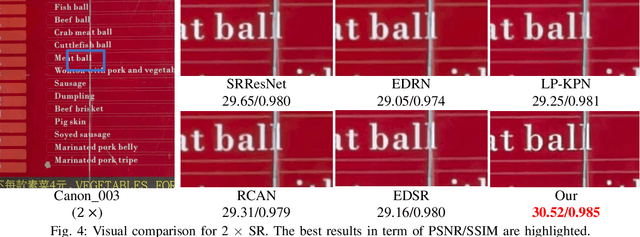
Different from traditional image super-resolution task, real image super-resolution(Real-SR) focus on the relationship between real-world high-resolution(HR) and low-resolution(LR) image. Most of the traditional image SR obtains the LR sample by applying a fixed down-sampling operator. Real-SR obtains the LR and HR image pair by incorporating different quality optical sensors. Generally, Real-SR has more challenges as well as broader application scenarios. Previous image SR methods fail to exhibit similar performance on Real-SR as the image data is not aligned inherently. In this article, we propose a Dual-path Dynamic Enhancement Network(DDet) for Real-SR, which addresses the cross-camera image mapping by realizing a dual-way dynamic sub-pixel weighted aggregation and refinement. Unlike conventional methods which stack up massive convolutional blocks for feature representation, we introduce a content-aware framework to study non-inherently aligned image pair in image SR issue. First, we use a content-adaptive component to exhibit the Multi-scale Dynamic Attention(MDA). Second, we incorporate a long-term skip connection with a Coupled Detail Manipulation(CDM) to perform collaborative compensation and manipulation. The above dual-path model is joint into a unified model and works collaboratively. Extensive experiments on the challenging benchmarks demonstrate the superiority of our model.
Adaptive Denoising via GainTuning
Jul 27, 2021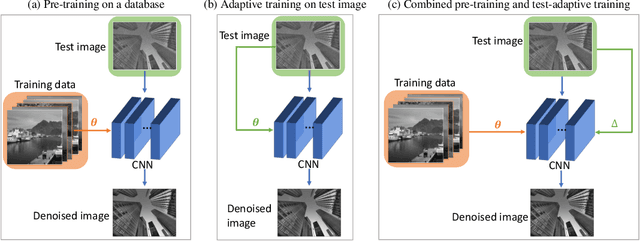
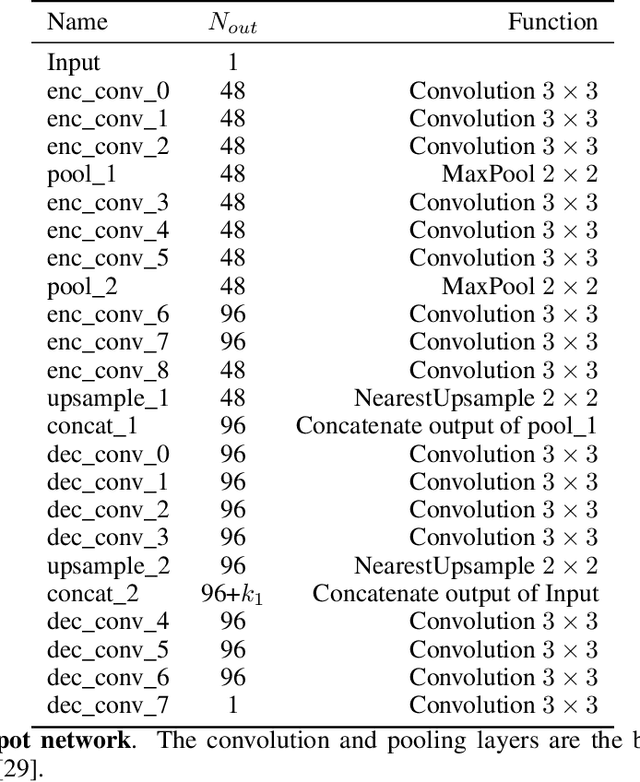
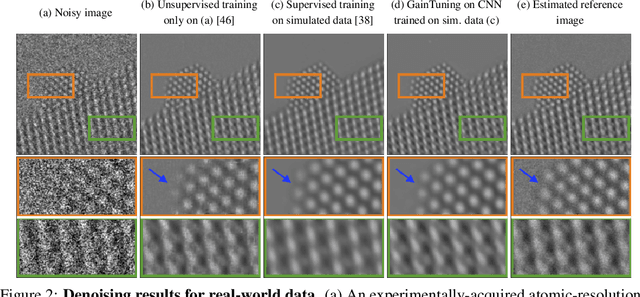

Deep convolutional neural networks (CNNs) for image denoising are usually trained on large datasets. These models achieve the current state of the art, but they have difficulties generalizing when applied to data that deviate from the training distribution. Recent work has shown that it is possible to train denoisers on a single noisy image. These models adapt to the features of the test image, but their performance is limited by the small amount of information used to train them. Here we propose "GainTuning", in which CNN models pre-trained on large datasets are adaptively and selectively adjusted for individual test images. To avoid overfitting, GainTuning optimizes a single multiplicative scaling parameter (the "Gain") of each channel in the convolutional layers of the CNN. We show that GainTuning improves state-of-the-art CNNs on standard image-denoising benchmarks, boosting their denoising performance on nearly every image in a held-out test set. These adaptive improvements are even more substantial for test images differing systematically from the training data, either in noise level or image type. We illustrate the potential of adaptive denoising in a scientific application, in which a CNN is trained on synthetic data, and tested on real transmission-electron-microscope images. In contrast to the existing methodology, GainTuning is able to faithfully reconstruct the structure of catalytic nanoparticles from these data at extremely low signal-to-noise ratios.
Recyclable Waste Identification Using CNN Image Recognition and Gaussian Clustering
Nov 02, 2020
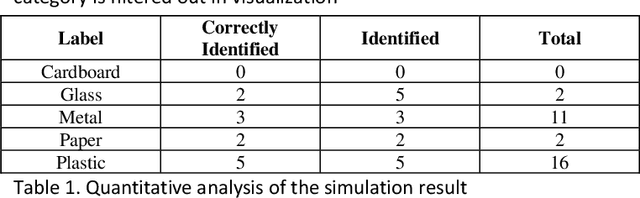

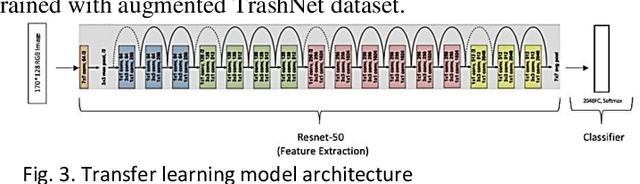
Waste recycling is an important way of saving energy and materials in the production process. In general cases recyclable objects are mixed with unrecyclable objects, which raises a need for identification and classification. This paper proposes a convolutional neural network (CNN) model to complete both tasks. The model uses transfer learning from a pretrained Resnet-50 CNN to complete feature extraction. A subsequent fully connected layer for classification was trained on the augmented TrashNet dataset [1]. In the application, sliding-window is used for image segmentation in the pre-classification stage. In the post-classification stage, the labelled sample points are integrated with Gaussian Clustering to locate the object. The resulting model has achieved an overall detection rate of 48.4% in simulation and final classification accuracy of 92.4%.
Universal Adversarial Spoofing Attacks against Face Recognition
Oct 02, 2021
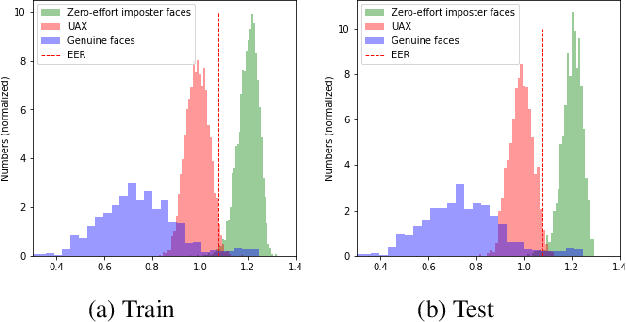
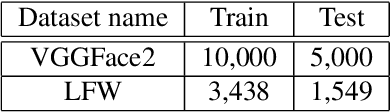
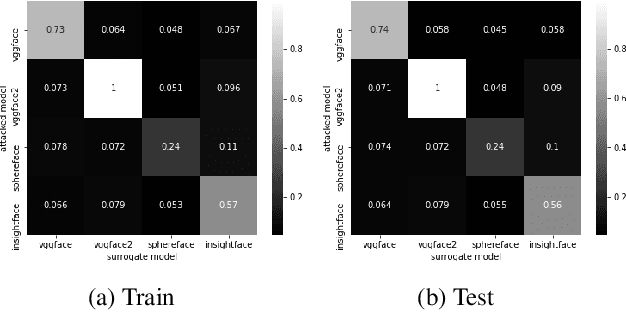
We assess the vulnerabilities of deep face recognition systems for images that falsify/spoof multiple identities simultaneously. We demonstrate that, by manipulating the deep feature representation extracted from a face image via imperceptibly small perturbations added at the pixel level using our proposed Universal Adversarial Spoofing Examples (UAXs), one can fool a face verification system into recognizing that the face image belongs to multiple different identities with a high success rate. One characteristic of the UAXs crafted with our method is that they are universal (identity-agnostic); they are successful even against identities not known in advance. For a certain deep neural network, we show that we are able to spoof almost all tested identities (99\%), including those not known beforehand (not included in training). Our results indicate that a multiple-identity attack is a real threat and should be taken into account when deploying face recognition systems.