 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Deepfake Detection for Electronic Know Your Customer Systems Using Registered Images
Jul 30, 2025In this paper, we present a deepfake detection algorithm specifically designed for electronic Know Your Customer (eKYC) systems. To ensure the reliability of eKYC systems against deepfake attacks, it is essential to develop a robust deepfake detector capable of identifying both face swapping and face reenactment, while also being robust to image degradation. We address these challenges through three key contributions: (1)~Our approach evaluates the video's authenticity by detecting temporal inconsistencies in identity vectors extracted by face recognition models, leading to comprehensive detection of both face swapping and face reenactment. (2)~In addition to processing video input, the algorithm utilizes a registered image (assumed to be genuine) to calculate identity discrepancies between the input video and the registered image, significantly improving detection accuracy. (3)~We find that employing a face feature extractor trained on a larger dataset enhances both detection performance and robustness against image degradation. Our experimental results show that our proposed method accurately detects both face swapping and face reenactment comprehensively and is robust against various forms of unseen image degradation. Our source code is publicly available https://github.com/TaikiMiyagawa/DeepfakeDetection4eKYC.
Prompt Tuning for Audio Deepfake Detection: Computationally Efficient Test-time Domain Adaptation with Limited Target Dataset
Oct 13, 2024



We study test-time domain adaptation for audio deepfake detection (ADD), addressing three challenges: (i) source-target domain gaps, (ii) limited target dataset size, and (iii) high computational costs. We propose an ADD method using prompt tuning in a plug-in style. It bridges domain gaps by integrating it seamlessly with state-of-the-art transformer models and/or with other fine-tuning methods, boosting their performance on target data (challenge (i)). In addition, our method can fit small target datasets because it does not require a large number of extra parameters (challenge (ii)). This feature also contributes to computational efficiency, countering the high computational costs typically associated with large-scale pre-trained models in ADD (challenge (iii)). We conclude that prompt tuning for ADD under domain gaps presents a promising avenue for enhancing accuracy with minimal target data and negligible extra computational burden.
Simultaneous Adversarial Attacks On Multiple Face Recognition System Components
Apr 11, 2023



In this work, we investigate the potential threat of adversarial examples to the security of face recognition systems. Although previous research has explored the adversarial risk to individual components of FRSs, our study presents an initial exploration of an adversary simultaneously fooling multiple components: the face detector and feature extractor in an FRS pipeline. We propose three multi-objective attacks on FRSs and demonstrate their effectiveness through a preliminary experimental analysis on a target system. Our attacks achieved up to 100% Attack Success Rates against both the face detector and feature extractor and were able to manipulate the face detection probability by up to 50% depending on the adversarial objective. This research identifies and examines novel attack vectors against FRSs and suggests possible ways to augment the robustness by leveraging the attack vector's knowledge during training of an FRS's components.
Advancing Deep Metric Learning Through Multiple Batch Norms And Multi-Targeted Adversarial Examples
Dec 06, 2022Deep Metric Learning (DML) is a prominent field in machine learning with extensive practical applications that concentrate on learning visual similarities. It is known that inputs such as Adversarial Examples (AXs), which follow a distribution different from that of clean data, result in false predictions from DML systems. This paper proposes MDProp, a framework to simultaneously improve the performance of DML models on clean data and inputs following multiple distributions. MDProp utilizes multi-distribution data through an AX generation process while leveraging disentangled learning through multiple batch normalization layers during the training of a DML model. MDProp is the first to generate feature space multi-targeted AXs to perform targeted regularization on the training model's denser embedding space regions, resulting in improved embedding space densities contributing to the improved generalization in the trained models. From a comprehensive experimental analysis, we show that MDProp results in up to 2.95% increased clean data Recall@1 scores and up to 2.12 times increased robustness against different input distributions compared to the conventional methods.
Powerful Physical Adversarial Examples Against Practical Face Recognition Systems
Mar 23, 2022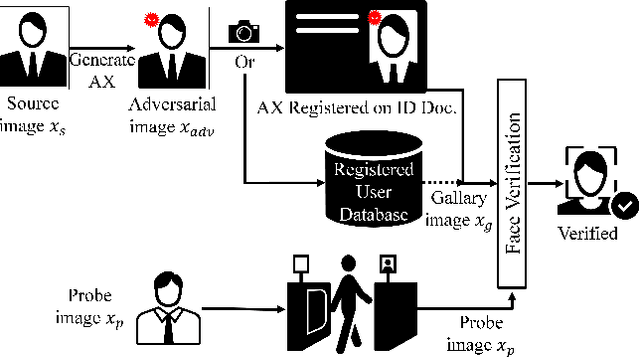
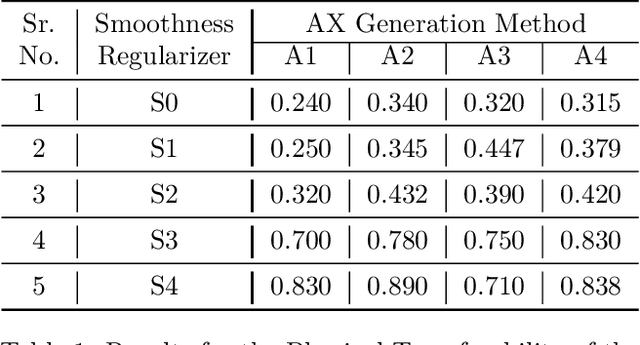
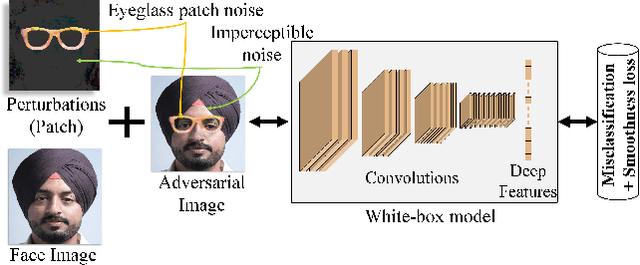
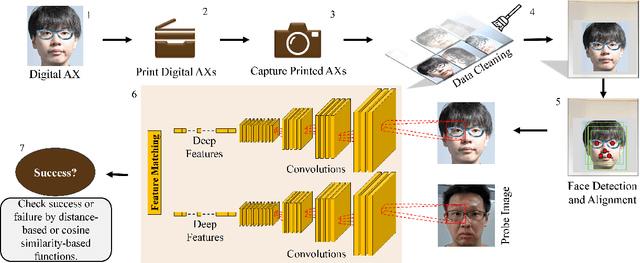
It is well-known that the most existing machine learning (ML)-based safety-critical applications are vulnerable to carefully crafted input instances called adversarial examples (AXs). An adversary can conveniently attack these target systems from digital as well as physical worlds. This paper aims to the generation of robust physical AXs against face recognition systems. We present a novel smoothness loss function and a patch-noise combo attack for realizing powerful physical AXs. The smoothness loss interjects the concept of delayed constraints during the attack generation process, thereby causing better handling of optimization complexity and smoother AXs for the physical domain. The patch-noise combo attack combines patch noise and imperceptibly small noises from different distributions to generate powerful registration-based physical AXs. An extensive experimental analysis found that our smoothness loss results in robust and more transferable digital and physical AXs than the conventional techniques. Notably, our smoothness loss results in a 1.17 and 1.97 times better mean attack success rate (ASR) in physical white-box and black-box attacks, respectively. Our patch-noise combo attack furthers the performance gains and results in 2.39 and 4.74 times higher mean ASR than conventional technique in physical world white-box and black-box attacks, respectively.
Universal Adversarial Spoofing Attacks against Face Recognition
Oct 02, 2021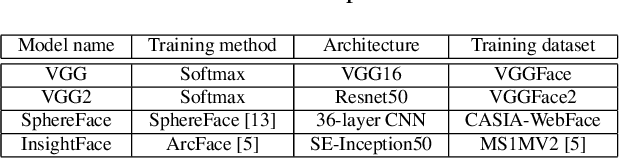
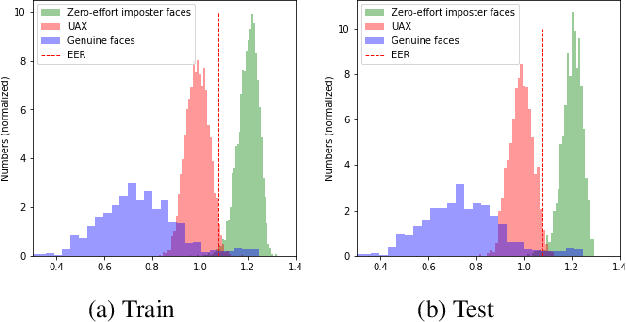
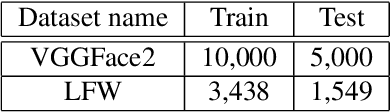
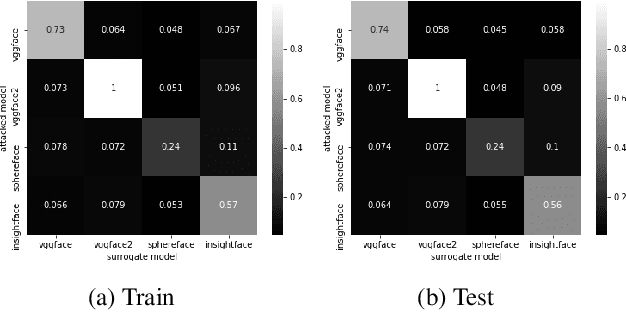
We assess the vulnerabilities of deep face recognition systems for images that falsify/spoof multiple identities simultaneously. We demonstrate that, by manipulating the deep feature representation extracted from a face image via imperceptibly small perturbations added at the pixel level using our proposed Universal Adversarial Spoofing Examples (UAXs), one can fool a face verification system into recognizing that the face image belongs to multiple different identities with a high success rate. One characteristic of the UAXs crafted with our method is that they are universal (identity-agnostic); they are successful even against identities not known in advance. For a certain deep neural network, we show that we are able to spoof almost all tested identities (99\%), including those not known beforehand (not included in training). Our results indicate that a multiple-identity attack is a real threat and should be taken into account when deploying face recognition systems.
On Brightness Agnostic Adversarial Examples Against Face Recognition Systems
Sep 29, 2021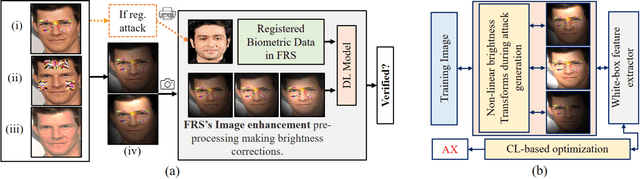
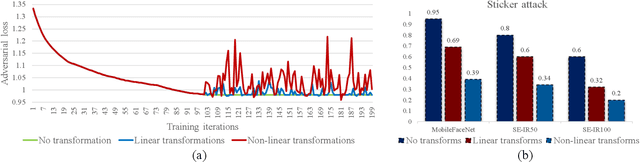
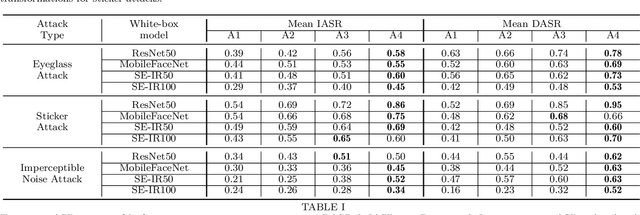
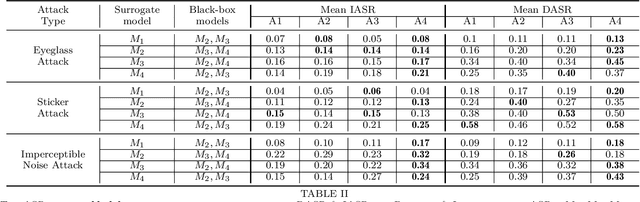
This paper introduces a novel adversarial example generation method against face recognition systems (FRSs). An adversarial example (AX) is an image with deliberately crafted noise to cause incorrect predictions by a target system. The AXs generated from our method remain robust under real-world brightness changes. Our method performs non-linear brightness transformations while leveraging the concept of curriculum learning during the attack generation procedure. We demonstrate that our method outperforms conventional techniques from comprehensive experimental investigations in the digital and physical world. Furthermore, this method enables practical risk assessment of FRSs against brightness agnostic AXs.
* Accepted at BIOSIG 2021 conference
Adversarial Image Translation: Unrestricted Adversarial Examples in Face Recognition Systems
May 27, 2019

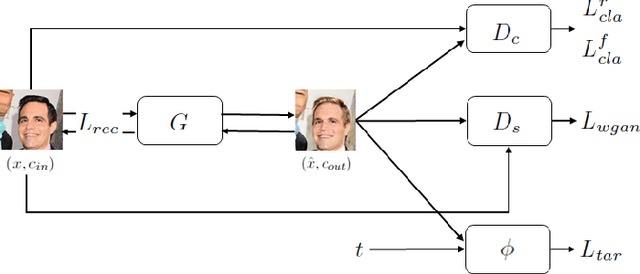

Thanks to recent advances in Deep Neural Networks (DNNs), face recognition systems have achieved high accuracy in classification of a large number of face images. However, recent works demonstrate that DNNs could be vulnerable to adversarial examples and raise concerns about robustness of face recognition systems. In particular adversarial examples that are not restricted to small perturbations could be more serious risks since conventional certified defenses might be ineffective against them. To shed light on the vulnerability to this type of adversarial examples, we propose a flexible and efficient method to generate unrestricted adversarial examples using image translation techniques. Our method enables us to translate a source image into any desired facial appearance with large perturbations so that target face recognition systems could be deceived. Through our experiments, we demonstrate that our method achieves about 90% and 30% attack success rates under a white- and black-box setting, respectively. We also illustrate that our translated images are perceptually realistic and maintain personal identity while the perturbations are large enough to bypass certified defenses.
Lightweight Lipschitz Margin Training for Certified Defense against Adversarial Examples
Nov 20, 2018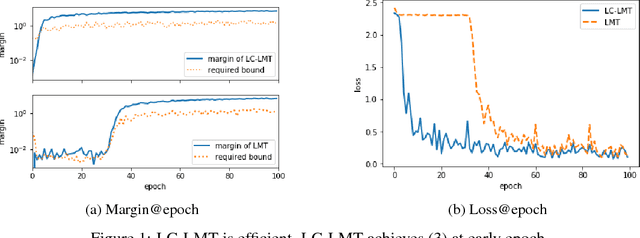
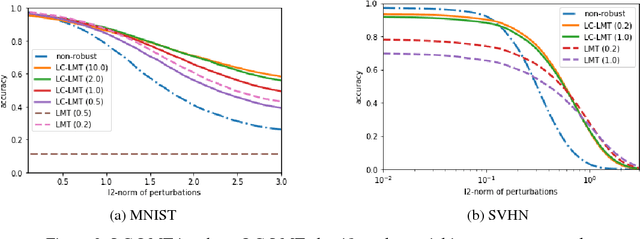
How can we make machine learning provably robust against adversarial examples in a scalable way? Since certified defense methods, which ensure $\epsilon$-robust, consume huge resources, they can only achieve small degree of robustness in practice. Lipschitz margin training (LMT) is a scalable certified defense, but it can also only achieve small robustness due to over-regularization. How can we make certified defense more efficiently? We present LC-LMT, a light weight Lipschitz margin training which solves the above problem. Our method has the following properties; (a) efficient: it can achieve $\epsilon$-robustness at early epoch, and (b) robust: it has a potential to get higher robustness than LMT. In the evaluation, we demonstrate the benefits of the proposed method. LC-LMT can achieve required robustness more than 30 epoch earlier than LMT in MNIST, and shows more than 90 $\%$ accuracy against both legitimate and adversarial inputs.
Differentially Private Analysis of Outliers
Jul 27, 2015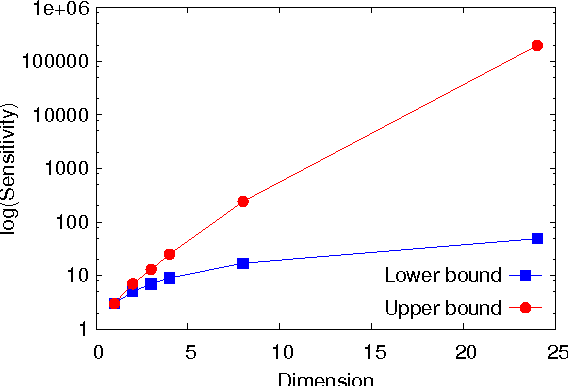
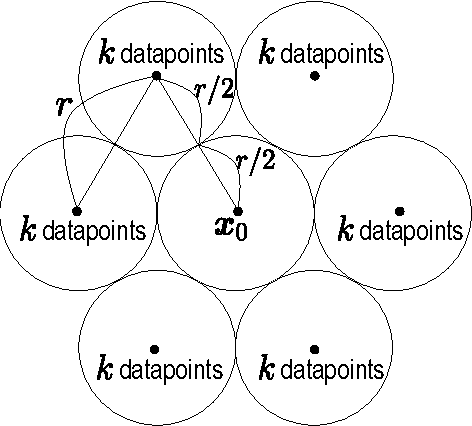
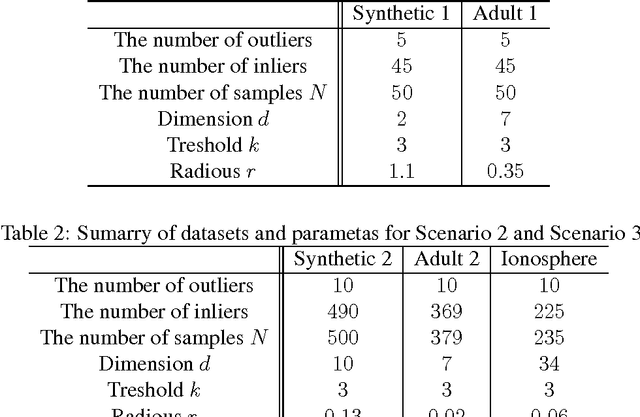
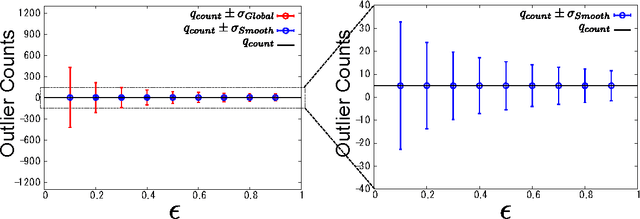
This paper investigates differentially private analysis of distance-based outliers. The problem of outlier detection is to find a small number of instances that are apparently distant from the remaining instances. On the other hand, the objective of differential privacy is to conceal presence (or absence) of any particular instance. Outlier detection and privacy protection are thus intrinsically conflicting tasks. In this paper, instead of reporting outliers detected, we present two types of differentially private queries that help to understand behavior of outliers. One is the query to count outliers, which reports the number of outliers that appear in a given subspace. Our formal analysis on the exact global sensitivity of outlier counts reveals that regular global sensitivity based method can make the outputs too noisy, particularly when the dimensionality of the given subspace is high. Noting that the counts of outliers are typically expected to be relatively small compared to the number of data, we introduce a mechanism based on the smooth upper bound of the local sensitivity. The other is the query to discovery top-$h$ subspaces containing a large number of outliers. This task can be naively achieved by issuing count queries to each subspace in turn. However, the variation of subspaces can grow exponentially in the data dimensionality. This can cause serious consumption of the privacy budget. For this task, we propose an exponential mechanism with a customized score function for subspace discovery. To the best of our knowledge, this study is the first trial to ensure differential privacy for distance-based outlier analysis. We demonstrated our methods with synthesized datasets and real datasets. The experimental results show that out method achieve better utility compared to the global sensitivity based methods.