 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Adversarial Attacks On Multiple Face Recognition System Components
Apr 11, 2023



In this work, we investigate the potential threat of adversarial examples to the security of face recognition systems. Although previous research has explored the adversarial risk to individual components of FRSs, our study presents an initial exploration of an adversary simultaneously fooling multiple components: the face detector and feature extractor in an FRS pipeline. We propose three multi-objective attacks on FRSs and demonstrate their effectiveness through a preliminary experimental analysis on a target system. Our attacks achieved up to 100% Attack Success Rates against both the face detector and feature extractor and were able to manipulate the face detection probability by up to 50% depending on the adversarial objective. This research identifies and examines novel attack vectors against FRSs and suggests possible ways to augment the robustness by leveraging the attack vector's knowledge during training of an FRS's components.
Advancing Deep Metric Learning Through Multiple Batch Norms And Multi-Targeted Adversarial Examples
Dec 06, 2022Deep Metric Learning (DML) is a prominent field in machine learning with extensive practical applications that concentrate on learning visual similarities. It is known that inputs such as Adversarial Examples (AXs), which follow a distribution different from that of clean data, result in false predictions from DML systems. This paper proposes MDProp, a framework to simultaneously improve the performance of DML models on clean data and inputs following multiple distributions. MDProp utilizes multi-distribution data through an AX generation process while leveraging disentangled learning through multiple batch normalization layers during the training of a DML model. MDProp is the first to generate feature space multi-targeted AXs to perform targeted regularization on the training model's denser embedding space regions, resulting in improved embedding space densities contributing to the improved generalization in the trained models. From a comprehensive experimental analysis, we show that MDProp results in up to 2.95% increased clean data Recall@1 scores and up to 2.12 times increased robustness against different input distributions compared to the conventional methods.
Latent SHAP: Toward Practical Human-Interpretable Explanations
Nov 27, 2022



Model agnostic feature attribution algorithms (such as SHAP and LIME) are ubiquitous techniques for explaining the decisions of complex classification models, such as deep neural networks. However, since complex classification models produce superior performance when trained on low-level (or encoded) features, in many cases, the explanations generated by these algorithms are neither interpretable nor usable by humans. Methods proposed in recent studies that support the generation of human-interpretable explanations are impractical, because they require a fully invertible transformation function that maps the model's input features to the human-interpretable features. In this work, we introduce Latent SHAP, a black-box feature attribution framework that provides human-interpretable explanations, without the requirement for a fully invertible transformation function. We demonstrate Latent SHAP's effectiveness using (1) a controlled experiment where invertible transformation functions are available, which enables robust quantitative evaluation of our method, and (2) celebrity attractiveness classification (using the CelebA dataset) where invertible transformation functions are not available, which enables thorough qualitative evaluation of our method.
Powerful Physical Adversarial Examples Against Practical Face Recognition Systems
Mar 23, 2022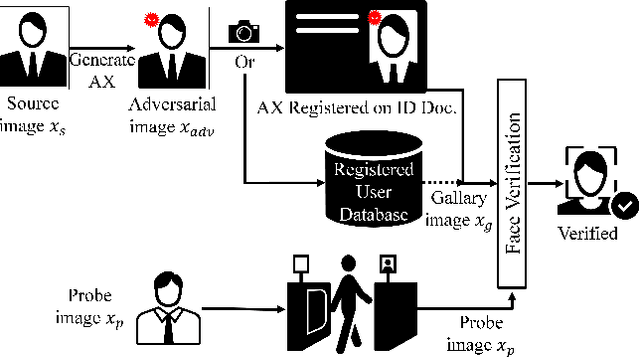
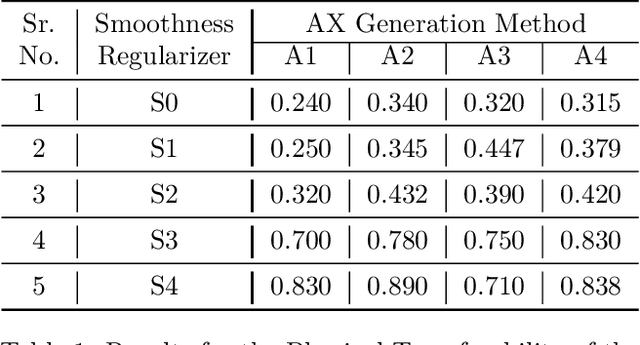
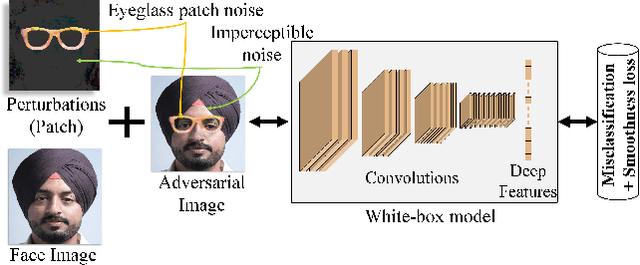
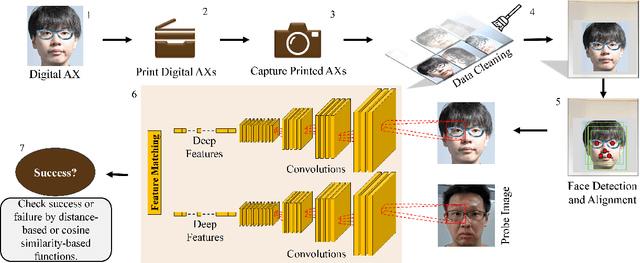
It is well-known that the most existing machine learning (ML)-based safety-critical applications are vulnerable to carefully crafted input instances called adversarial examples (AXs). An adversary can conveniently attack these target systems from digital as well as physical worlds. This paper aims to the generation of robust physical AXs against face recognition systems. We present a novel smoothness loss function and a patch-noise combo attack for realizing powerful physical AXs. The smoothness loss interjects the concept of delayed constraints during the attack generation process, thereby causing better handling of optimization complexity and smoother AXs for the physical domain. The patch-noise combo attack combines patch noise and imperceptibly small noises from different distributions to generate powerful registration-based physical AXs. An extensive experimental analysis found that our smoothness loss results in robust and more transferable digital and physical AXs than the conventional techniques. Notably, our smoothness loss results in a 1.17 and 1.97 times better mean attack success rate (ASR) in physical white-box and black-box attacks, respectively. Our patch-noise combo attack furthers the performance gains and results in 2.39 and 4.74 times higher mean ASR than conventional technique in physical world white-box and black-box attacks, respectively.
Universal Adversarial Spoofing Attacks against Face Recognition
Oct 02, 2021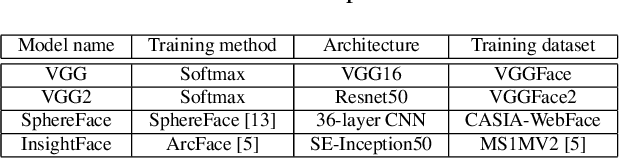
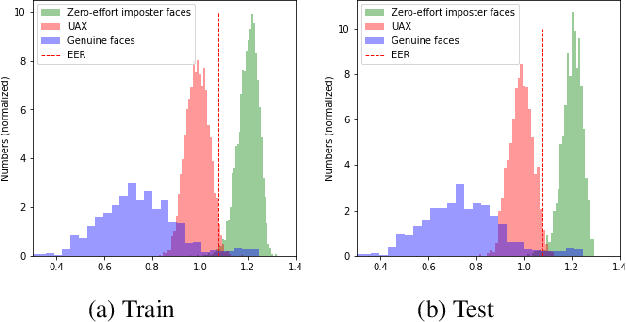
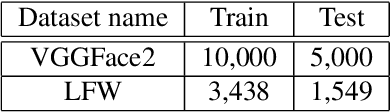
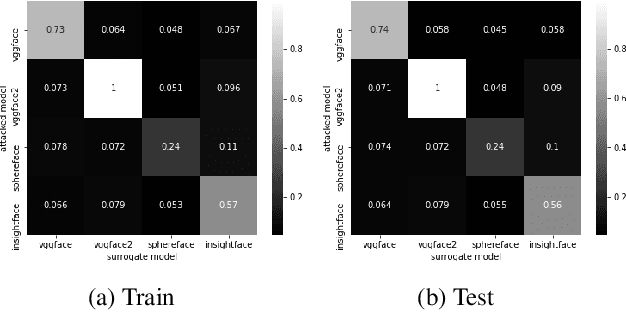
We assess the vulnerabilities of deep face recognition systems for images that falsify/spoof multiple identities simultaneously. We demonstrate that, by manipulating the deep feature representation extracted from a face image via imperceptibly small perturbations added at the pixel level using our proposed Universal Adversarial Spoofing Examples (UAXs), one can fool a face verification system into recognizing that the face image belongs to multiple different identities with a high success rate. One characteristic of the UAXs crafted with our method is that they are universal (identity-agnostic); they are successful even against identities not known in advance. For a certain deep neural network, we show that we are able to spoof almost all tested identities (99\%), including those not known beforehand (not included in training). Our results indicate that a multiple-identity attack is a real threat and should be taken into account when deploying face recognition systems.
On Brightness Agnostic Adversarial Examples Against Face Recognition Systems
Sep 29, 2021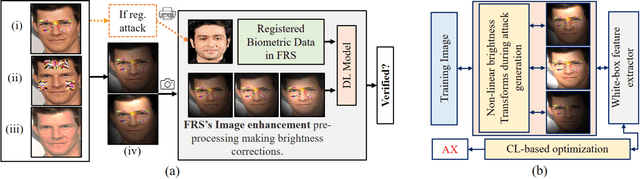
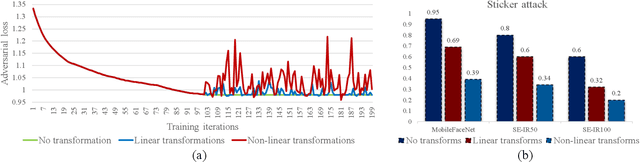
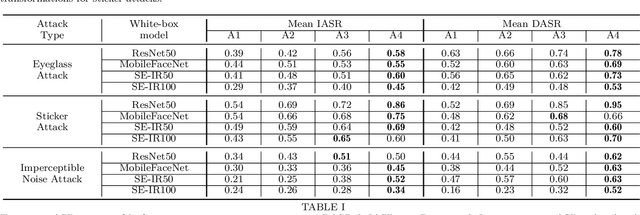
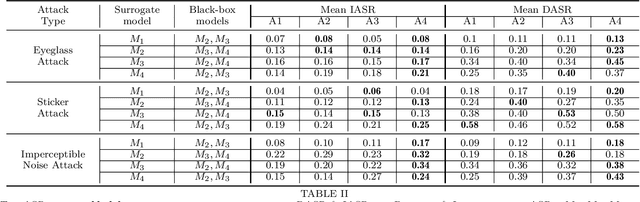
This paper introduces a novel adversarial example generation method against face recognition systems (FRSs). An adversarial example (AX) is an image with deliberately crafted noise to cause incorrect predictions by a target system. The AXs generated from our method remain robust under real-world brightness changes. Our method performs non-linear brightness transformations while leveraging the concept of curriculum learning during the attack generation procedure. We demonstrate that our method outperforms conventional techniques from comprehensive experimental investigations in the digital and physical world. Furthermore, this method enables practical risk assessment of FRSs against brightness agnostic AXs.
* Accepted at BIOSIG 2021 conference