 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On Salience-Sensitive Sign Classification in Autonomous Vehicle Path Planning: Experimental Explorations with a Novel Dataset
Dec 02, 2021

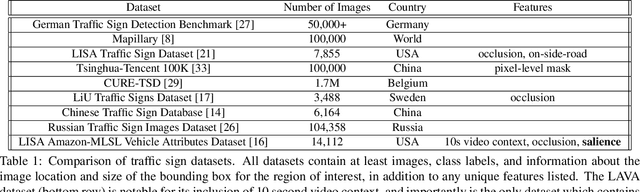

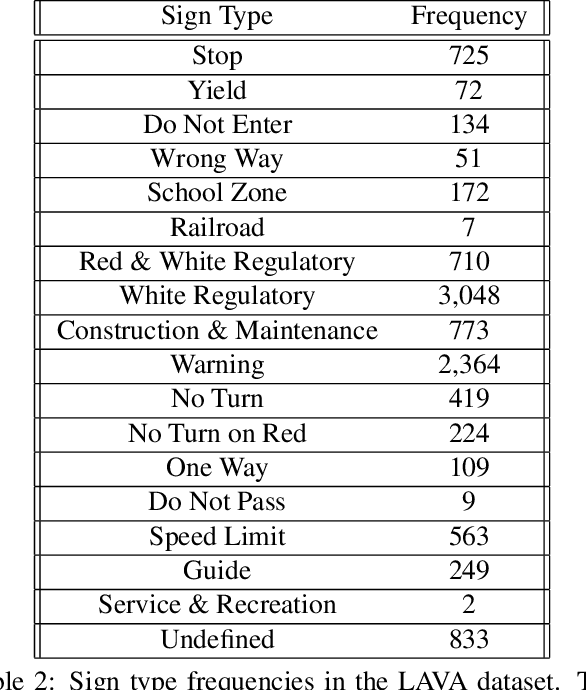
Safe path planning in autonomous driving is a complex task due to the interplay of static scene elements and uncertain surrounding agents. While all static scene elements are a source of information, there is asymmetric importance to the information available to the ego vehicle. We present a dataset with a novel feature, sign salience, defined to indicate whether a sign is distinctly informative to the goals of the ego vehicle with regards to traffic regulations. Using convolutional networks on cropped signs, in tandem with experimental augmentation by road type, image coordinates, and planned maneuver, we predict the sign salience property with 76% accuracy, finding the best improvement using information on vehicle maneuver with sign images.
Image-Based Plant Wilting Estimation
May 27, 2021


Many plants become limp or droop through heat, loss of water, or disease. This is also known as wilting. In this paper, we examine plant wilting caused by bacterial infection. In particular, we want to design a metric for wilting based on images acquired of the plant. A quantifiable wilting metric will be useful in studying bacterial wilt and identifying resistance genes. Since there is no standard way to estimate wilting, it is common to use ad hoc visual scores. This is very subjective and requires expert knowledge of the plants and the disease mechanism. Our solution consists of using various wilting metrics acquired from RGB images of the plants. We also designed several experiments to demonstrate that our metrics are effective at estimating wilting in plants.
WORD: Revisiting Organs Segmentation in the Whole Abdominal Region
Nov 17, 2021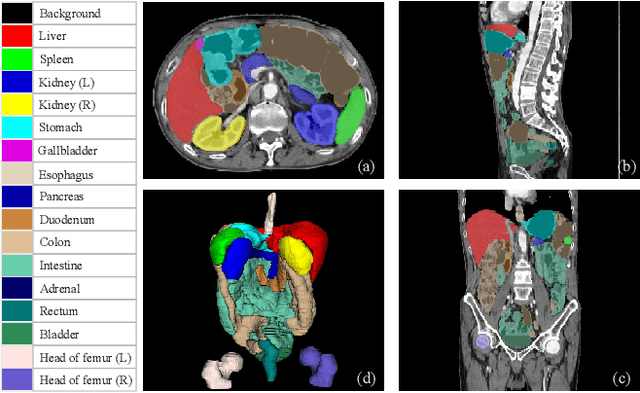
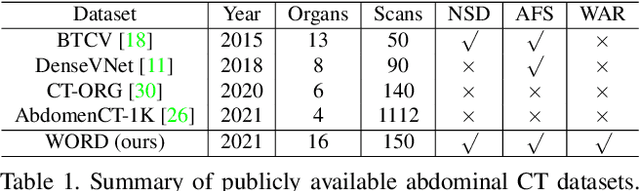
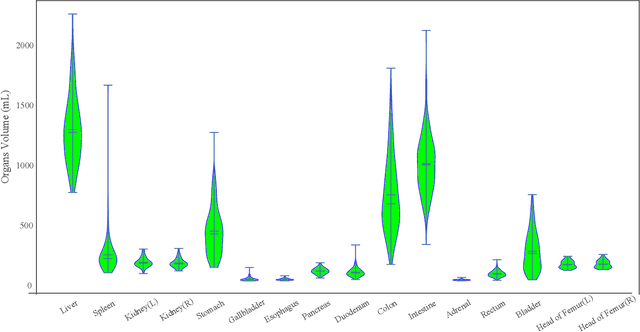

Whole abdominal organs segmentation plays an important role in abdomen lesion diagnosis, radiotherapy planning, and follow-up. However, delineating all abdominal organs by oncologists manually is time-consuming and very expensive. Recently, deep learning-based medical image segmentation has shown the potential to reduce manual delineation efforts, but it still requires a large-scale fine annotated dataset for training. Although many efforts in this task, there are still few large image datasets covering the whole abdomen region with accurate and detailed annotations for the whole abdominal organ segmentation. In this work, we establish a large-scale \textit{W}hole abdominal \textit{OR}gans \textit{D}ataset (\textit{WORD}) for algorithms research and clinical applications development. This dataset contains 150 abdominal CT volumes (30495 slices) and each volume has 16 organs with fine pixel-level annotations and scribble-based sparse annotation, which may be the largest dataset with whole abdominal organs annotation. Several state-of-the-art segmentation methods are evaluated on this dataset. And, we also invited clinical oncologists to revise the model predictions to measure the gap between the deep learning method and real oncologists. We further introduce and evaluate a new scribble-based weakly supervised segmentation on this dataset. The work provided a new benchmark for the abdominal multi-organ segmentation task and these experiments can serve as the baseline for future research and clinical application development. The codebase and dataset will be released at: https://github.com/HiLab-git/WORD
Learning End-to-End Lossy Image Compression: A Benchmark
Feb 19, 2020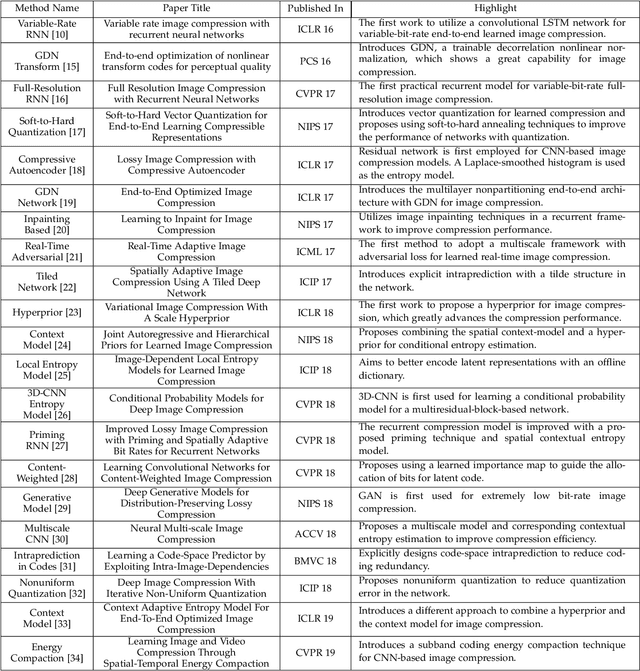
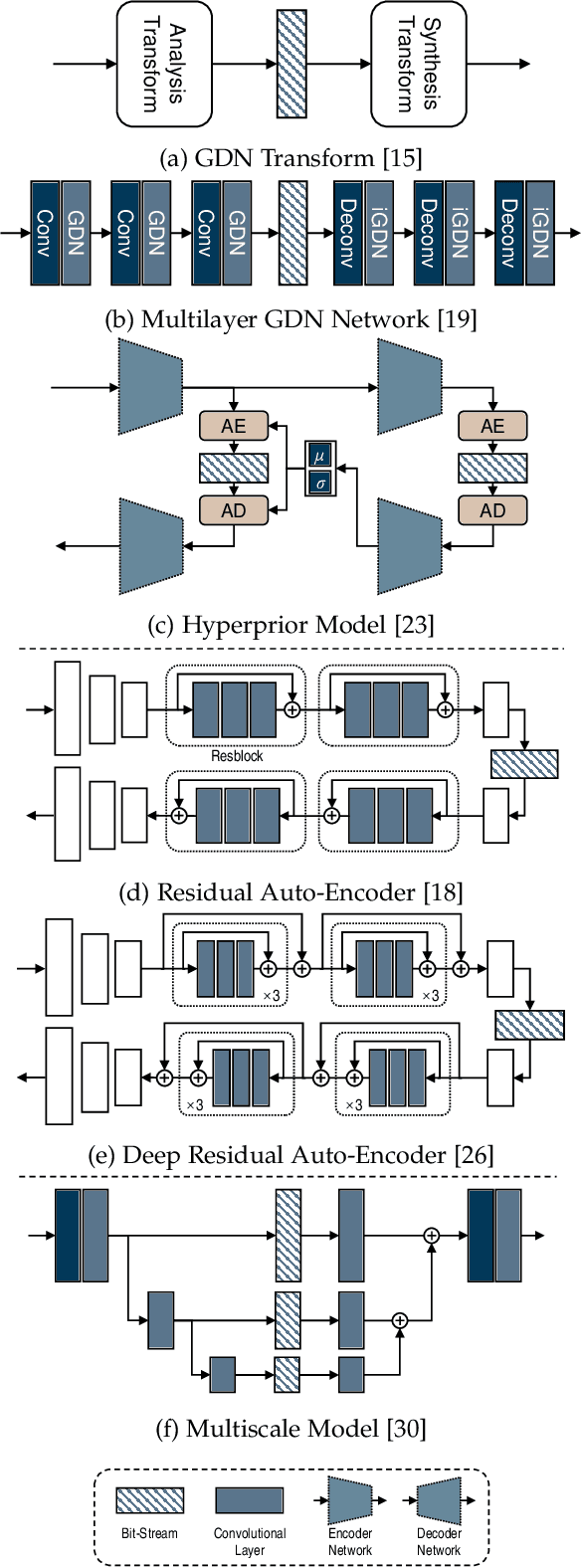
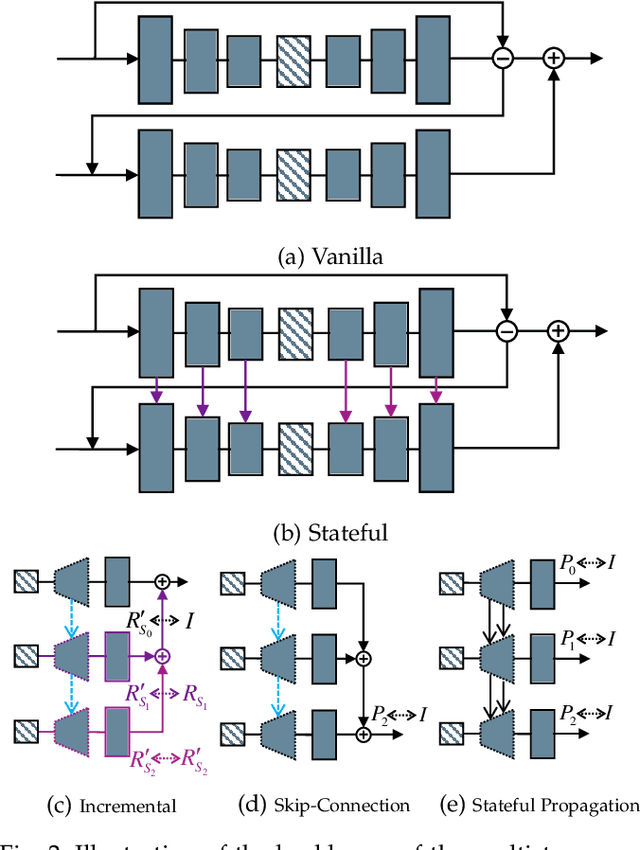
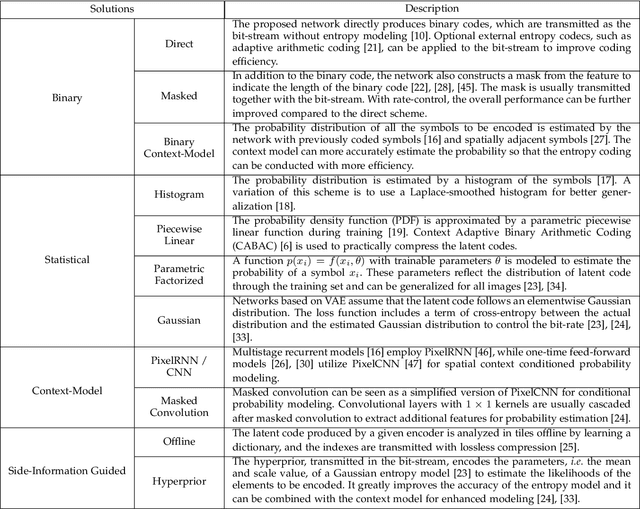
Image compression is one of the most fundamental techniques and commonly used applications in the image and video processing field. Earlier methods built a well-designed pipeline, and efforts were made to improve all modules of the pipeline by handcrafted tuning. Later, tremendous contributions were made, especially when data-driven methods revitalized the domain with their excellent modeling capacities and flexibility in incorporating newly designed modules and constraints. Despite great progress, a systematic benchmark and comprehensive analysis of end-to-end learned image compression methods are lacking. In this paper, we first conduct a comprehensive literature survey of learned image compression methods. The literature is organized based on several aspects to jointly optimize the rate-distortion performance with a neural network, i.e., network architecture, entropy model and rate control. We describe milestones in cutting-edge learned image-compression methods, review a broad range of existing works, and provide insights into their historical development routes. With this survey, the main challenges of image compression methods are revealed, along with opportunities to address the related issues with recent advanced learning methods. This analysis provides an opportunity to take a further step towards higher-efficiency image compression. By introducing a coarse-to-fine hyperprior model for entropy estimation and signal reconstruction, we achieve improved rate-distortion performance, especially on high-resolution images. Extensive benchmark experiments demonstrate the superiority of our model in coding efficiency and the potential for acceleration by large-scale parallel computing devices.
Uncertainty-Aware Blind Image Quality Assessment in the Laboratory and Wild
Jun 10, 2020
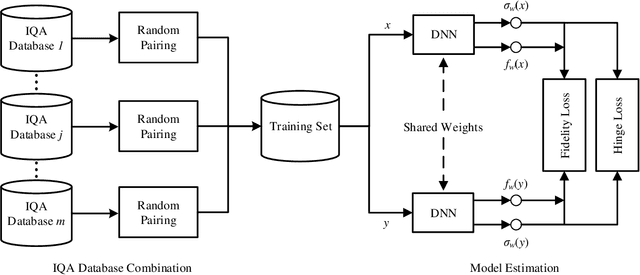
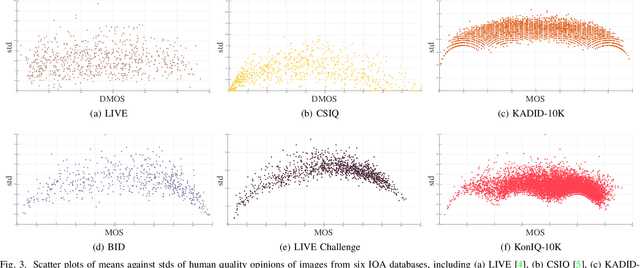

Performance of blind image quality assessment (BIQA) models has been significantly boosted by end-to-end optimization of feature engineering and quality regression. Nevertheless, due to the distributional shifts between images simulated in the laboratory and captured in the wild, models trained on databases with synthetic distortions remain particularly weak at handling realistic distortions (and vice versa). To confront the cross-distortion-scenario challenge, we develop a unified BIQA model and an effective approach of training it for both synthetic and realistic distortions. We first sample pairs of images from the same IQA databases and compute a probability that one image of each pair is of higher quality as the supervisory signal. We then employ the fidelity loss to optimize a deep neural network for BIQA over a large number of such image pairs. We also explicitly enforce a hinge constraint to regularize uncertainty estimation during optimization. Extensive experiments on six IQA databases show the promise of the learned method in blindly assessing image quality in the laboratory and wild. In addition, we demonstrate the universality of the proposed training strategy by using it to improve existing BIQA models.
GL-GAN: Adaptive Global and Local Bilevel Optimization model of Image Generation
Aug 06, 2020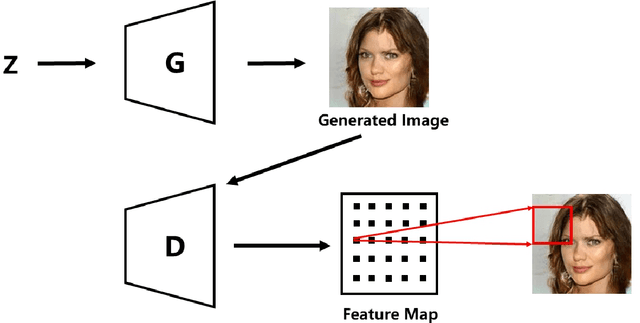


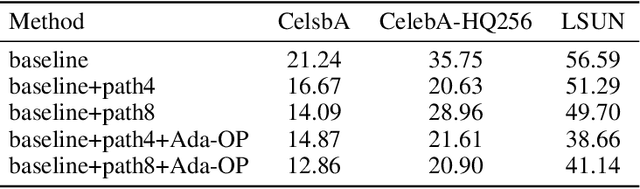
Although Generative Adversarial Networks have shown remarkable performance in image generation, there are some challenges in image realism and convergence speed. The results of some models display the imbalances of quality within a generated image, in which some defective parts appear compared with other regions. Different from general single global optimization methods, we introduce an adaptive global and local bilevel optimization model(GL-GAN). The model achieves the generation of high-resolution images in a complementary and promoting way, where global optimization is to optimize the whole images and local is only to optimize the low-quality areas. With a simple network structure, GL-GAN is allowed to effectively avoid the nature of imbalance by local bilevel optimization, which is accomplished by first locating low-quality areas and then optimizing them. Moreover, by using feature map cues from discriminator output, we propose the adaptive local and global optimization method(Ada-OP) for specific implementation and find that it boosts the convergence speed. Compared with the current GAN methods, our model has shown impressive performance on CelebA, CelebA-HQ and LSUN datasets.
Unsupervised Cross-Modality Domain Adaptation for Segmenting Vestibular Schwannoma and Cochlea with Data Augmentation and Model Ensemble
Sep 24, 2021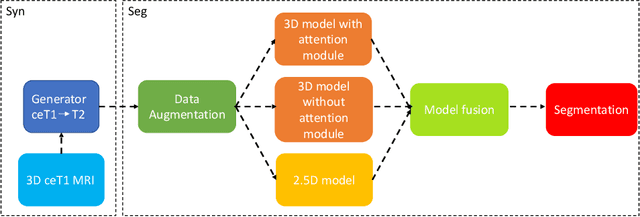
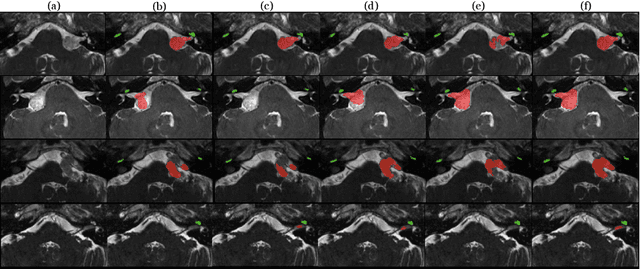
Magnetic resonance images (MRIs) are widely used to quantify vestibular schwannoma and the cochlea. Recently, deep learning methods have shown state-of-the-art performance for segmenting these structures. However, training segmentation models may require manual labels in target domain, which is expensive and time-consuming. To overcome this problem, domain adaptation is an effective way to leverage information from source domain to obtain accurate segmentations without requiring manual labels in target domain. In this paper, we propose an unsupervised learning framework to segment the VS and cochlea. Our framework leverages information from contrast-enhanced T1-weighted (ceT1-w) MRIs and its labels, and produces segmentations for T2-weighted MRIs without any labels in the target domain. We first applied a generator to achieve image-to-image translation. Next, we ensemble outputs from an ensemble of different models to obtain final segmentations. To cope with MRIs from different sites/scanners, we applied various 'online' augmentations during training to better capture the geometric variability and the variability in image appearance and quality. Our method is easy to build and produces promising segmentations, with a mean Dice score of 0.7930 and 0.7432 for VS and cochlea respectively in the validation set.
Simple and Robust Loss Design for Multi-Label Learning with Missing Labels
Dec 27, 2021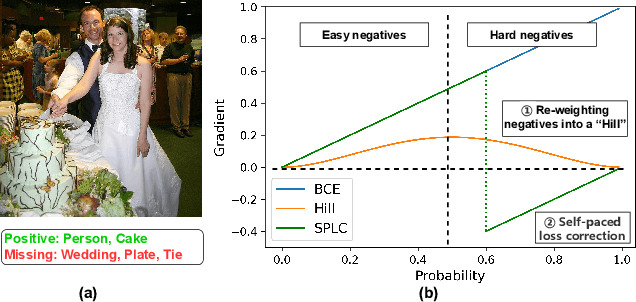
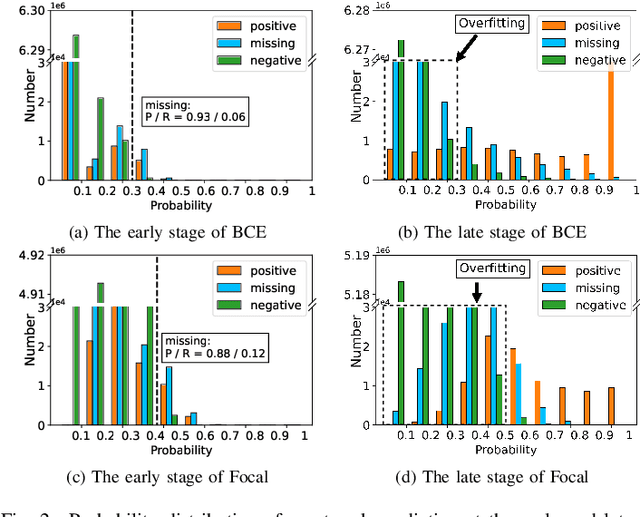
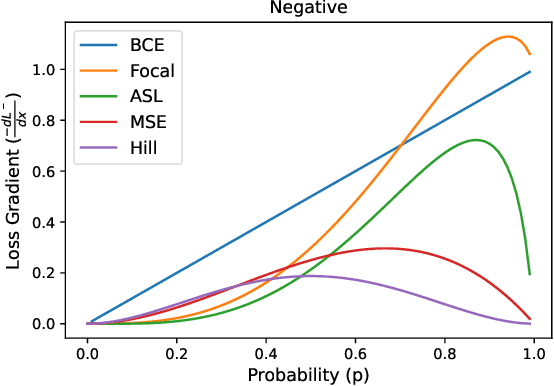
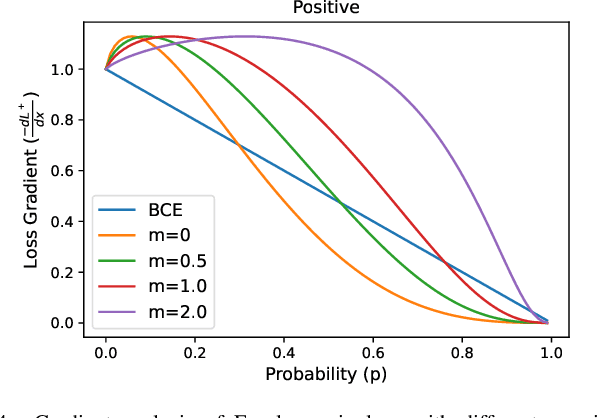
Multi-label learning in the presence of missing labels (MLML) is a challenging problem. Existing methods mainly focus on the design of network structures or training schemes, which increase the complexity of implementation. This work seeks to fulfill the potential of loss function in MLML without increasing the procedure and complexity. Toward this end, we propose two simple yet effective methods via robust loss design based on an observation that a model can identify missing labels during training with a high precision. The first is a novel robust loss for negatives, namely the Hill loss, which re-weights negatives in the shape of a hill to alleviate the effect of false negatives. The second is a self-paced loss correction (SPLC) method, which uses a loss derived from the maximum likelihood criterion under an approximate distribution of missing labels. Comprehensive experiments on a vast range of multi-label image classification datasets demonstrate that our methods can remarkably boost the performance of MLML and achieve new state-of-the-art loss functions in MLML.
SSCR: Iterative Language-Based Image Editing via Self-Supervised Counterfactual Reasoning
Sep 21, 2020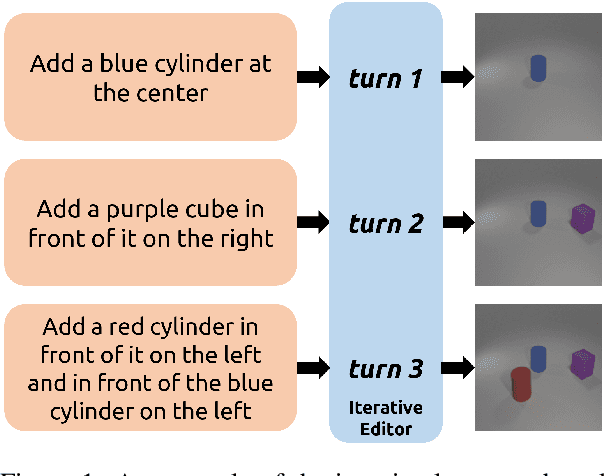

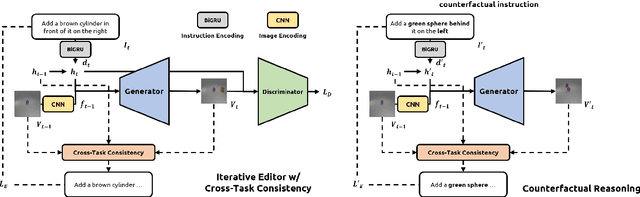
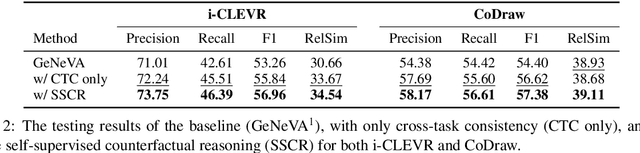
Iterative Language-Based Image Editing (IL-BIE) tasks follow iterative instructions to edit images step by step. Data scarcity is a significant issue for ILBIE as it is challenging to collect large-scale examples of images before and after instruction-based changes. However, humans still accomplish these editing tasks even when presented with an unfamiliar image-instruction pair. Such ability results from counterfactual thinking and the ability to think about alternatives to events that have happened already. In this paper, we introduce a Self-Supervised Counterfactual Reasoning (SSCR) framework that incorporates counterfactual thinking to overcome data scarcity. SSCR allows the model to consider out-of-distribution instructions paired with previous images. With the help of cross-task consistency (CTC), we train these counterfactual instructions in a self-supervised scenario. Extensive results show that SSCR improves the correctness of ILBIE in terms of both object identity and position, establishing a new state of the art (SOTA) on two IBLIE datasets (i-CLEVR and CoDraw). Even with only 50% of the training data, SSCR achieves a comparable result to using complete data.
Development of Automatic Tree Counting Software from UAV Based Aerial Images With Machine Learning
Jan 07, 2022

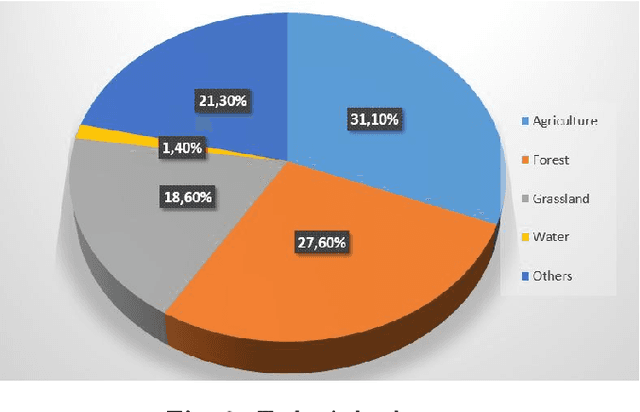
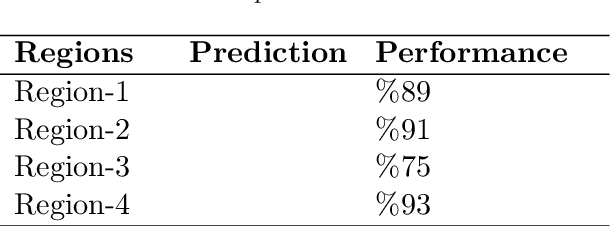
Unmanned aerial vehicles (UAV) are used successfully in many application areas such as military, security, monitoring, emergency aid, tourism, agriculture, and forestry. This study aims to automatically count trees in designated areas on the Siirt University campus from high-resolution images obtained by UAV. Images obtained at 30 meters height with 20% overlap were stitched offline at the ground station using Adobe Photoshop's photo merge tool. The resulting image was denoised and smoothed by applying the 3x3 median and mean filter, respectively. After generating the orthophoto map of the aerial images captured by the UAV in certain regions, the bounding boxes of different objects on these maps were labeled in the modalities of HSV (Hue Saturation Value), RGB (Red Green Blue) and Gray. Training, validation, and test datasets were generated and then have been evaluated for classification success rates related to tree detection using various machine learning algorithms. In the last step, a ground truth model was established by obtaining the actual tree numbers, and then the prediction performance was calculated by comparing the reference ground truth data with the proposed model. It is considered that significant success has been achieved for tree count with an average accuracy rate of 87% obtained using the MLP classifier in predetermined regions.