 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Accurate Cup-to-Disc Ratio Measurement with Tight Bounding Box Supervision in Fundus Photography
Oct 03, 2021
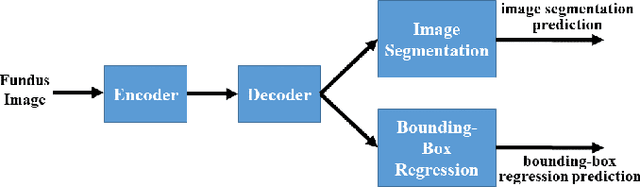

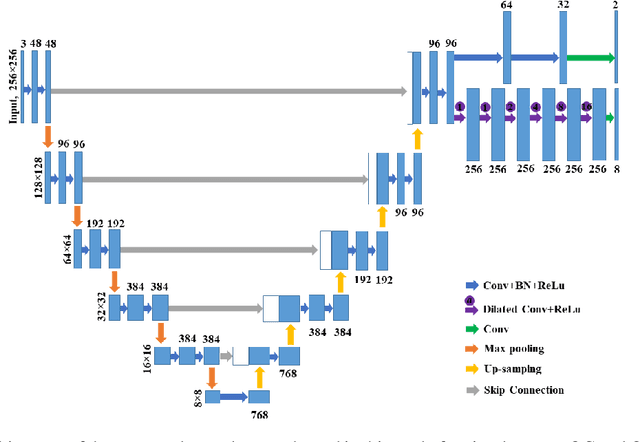
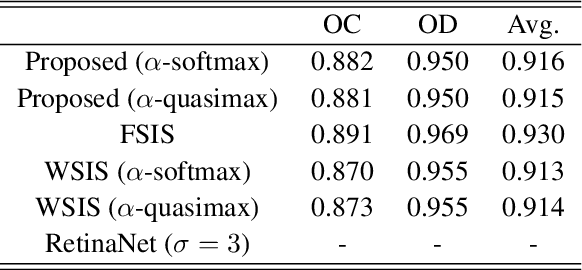
The cup-to-disc ratio (CDR) is one of the most significant indicator for glaucoma diagnosis. Different from the use of costly fully supervised learning formulation with pixel-wise annotations in the literature, this study investigates the feasibility of accurate CDR measurement in fundus images using only tight bounding box supervision. For this purpose, we develop a two-task network for accurate CDR measurement, one for weakly supervised image segmentation, and the other for bounding-box regression. The weakly supervised image segmentation task is implemented based on generalized multiple instance learning formulation and smooth maximum approximation, and the bounding-box regression task outputs class-specific bounding box prediction in a single scale at the original image resolution. To get accurate bounding box prediction, a class-specific bounding-box normalizer and an expected intersection-over-union are proposed. In the experiments, the proposed approach was evaluated by a testing set with 1200 images using CDR error and F1 score for CDR measurement and dice coefficient for image segmentation. A grader study was conducted to compare the performance of the proposed approach with those of individual graders. The results demonstrate that the proposed approach outperforms the state-of-the-art performance obtained from the fully supervised image segmentation (FSIS) approach using pixel-wise annotation for CDR measurement, which is also better than those of individual graders. It also gets performance close to the state-of-the-art obtained from FSIS for optic cup and disc segmentation, similar to those of individual graders. The codes are available at \url{https://github.com/wangjuan313/CDRNet}.
MoFaNeRF: Morphable Facial Neural Radiance Field
Dec 04, 2021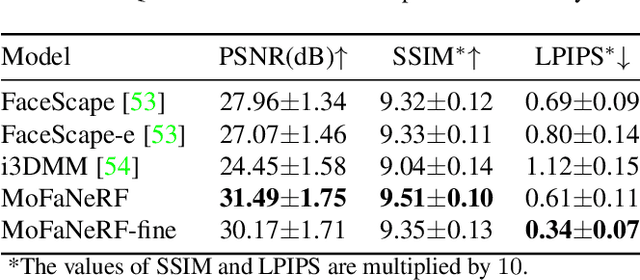
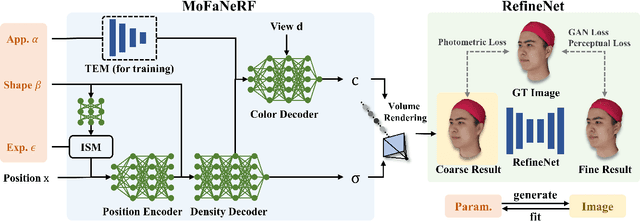

We propose a parametric model that maps free-view images into a vector space of coded facial shape, expression and appearance using a neural radiance field, namely Morphable Facial NeRF. Specifically, MoFaNeRF takes the coded facial shape, expression and appearance along with space coordinate and view direction as input to an MLP, and outputs the radiance of the space point for photo-realistic image synthesis. Compared with conventional 3D morphable models (3DMM), MoFaNeRF shows superiority in directly synthesizing photo-realistic facial details even for eyes, mouths, and beards. Also, continuous face morphing can be easily achieved by interpolating the input shape, expression and appearance codes. By introducing identity-specific modulation and texture encoder, our model synthesizes accurate photometric details and shows strong representation ability. Our model shows strong ability on multiple applications including image-based fitting, random generation, face rigging, face editing, and novel view synthesis. Experiments show that our method achieves higher representation ability than previous parametric models, and achieves competitive performance in several applications. To the best of our knowledge, our work is the first facial parametric model built upon a neural radiance field that can be used in fitting, generation and manipulation. Our code and model are released in https://github.com/zhuhao-nju/mofanerf.
Deep Video Prior for Video Consistency and Propagation
Jan 27, 2022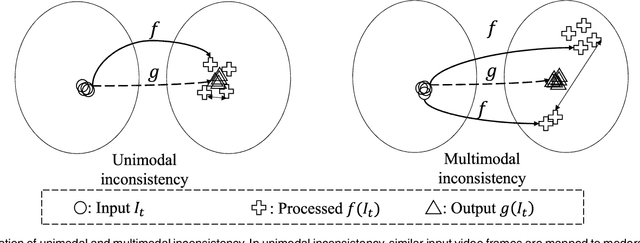
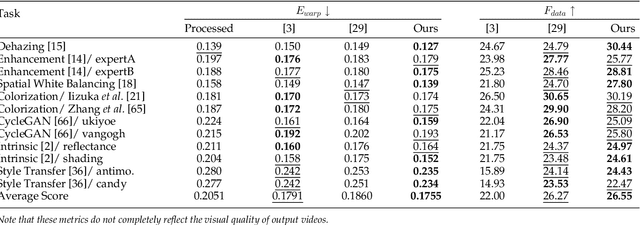
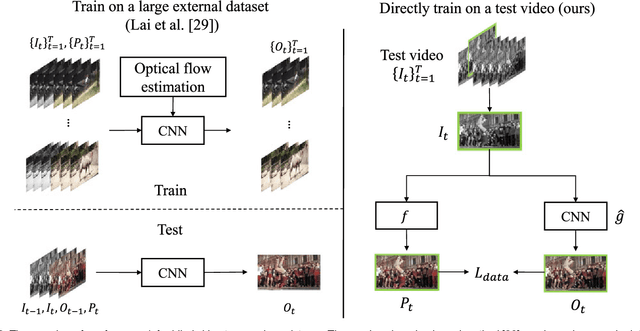
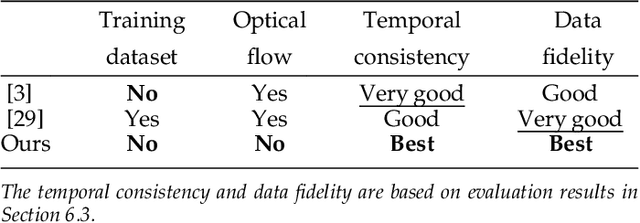
Applying an image processing algorithm independently to each video frame often leads to temporal inconsistency in the resulting video. To address this issue, we present a novel and general approach for blind video temporal consistency. Our method is only trained on a pair of original and processed videos directly instead of a large dataset. Unlike most previous methods that enforce temporal consistency with optical flow, we show that temporal consistency can be achieved by training a convolutional neural network on a video with Deep Video Prior (DVP). Moreover, a carefully designed iteratively reweighted training strategy is proposed to address the challenging multimodal inconsistency problem. We demonstrate the effectiveness of our approach on 7 computer vision tasks on videos. Extensive quantitative and perceptual experiments show that our approach obtains superior performance than state-of-the-art methods on blind video temporal consistency. We further extend DVP to video propagation and demonstrate its effectiveness in propagating three different types of information (color, artistic style, and object segmentation). A progressive propagation strategy with pseudo labels is also proposed to enhance DVP's performance on video propagation. Our source codes are publicly available at https://github.com/ChenyangLEI/deep-video-prior.
Image Quality Assessment: Unifying Structure and Texture Similarity
Apr 16, 2020
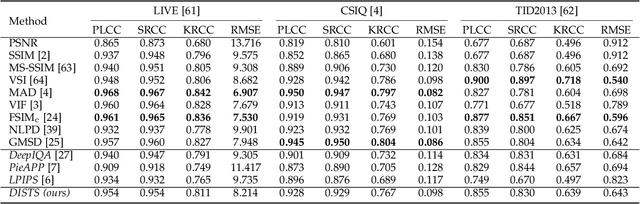

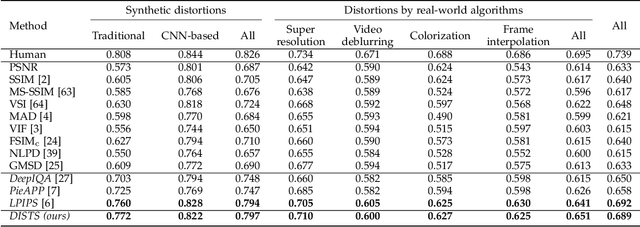
Objective measures of image quality generally operate by making local comparisons of pixels of a "degraded" image to those of the original. Relative to human observers, these measures are overly sensitive to resampling of texture regions (e.g., replacing one patch of grass with another). Here we develop the first full-reference image quality model with explicit tolerance to texture resampling. Using a convolutional neural network, we construct an injective and differentiable function that transforms images to a multi-scale overcomplete representation. We empirically show that the spatial averages of the feature maps in this representation capture texture appearance, in that they provide a set of sufficient statistical constraints to synthesize a wide variety of texture patterns. We then describe an image quality method that combines correlation of these spatial averages ("texture similarity") with correlation of the feature maps ("structure similarity"). The parameters of the proposed measure are jointly optimized to match human ratings of image quality, while minimizing the reported distances between subimages cropped from the same texture images. Experiments show that the optimized method explains human perceptual scores, both on conventional image quality databases, as well as on texture databases. The measure also offers competitive performance on related tasks such as texture classification and retrieval. Finally, we show that our method is relatively insensitive to geometric transformations (e.g., translation and dilation), without use of any specialized training or data augmentation. Code is available at https://github.com/dingkeyan93/DISTS.
Possibilistic Fuzzy Local Information C-Means with Automated Feature Selection for Seafloor Segmentation
Oct 14, 2021The Possibilistic Fuzzy Local Information C-Means (PFLICM) method is presented as a technique to segment side-look synthetic aperture sonar (SAS) imagery into distinct regions of the sea-floor. In this work, we investigate and present the results of an automated feature selection approach for SAS image segmentation. The chosen features and resulting segmentation from the image will be assessed based on a select quantitative clustering validity criterion and the subset of the features that reach a desired threshold will be used for the segmentation process.
Graph-Based Depth Denoising & Dequantization for Point Cloud Enhancement
Nov 09, 2021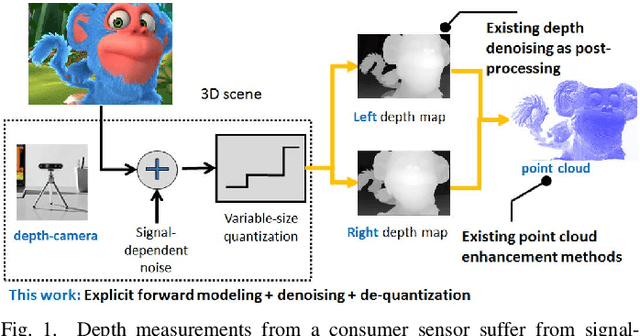
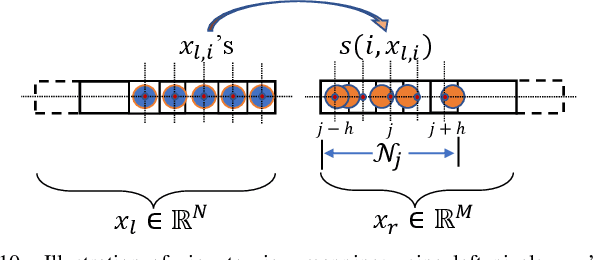
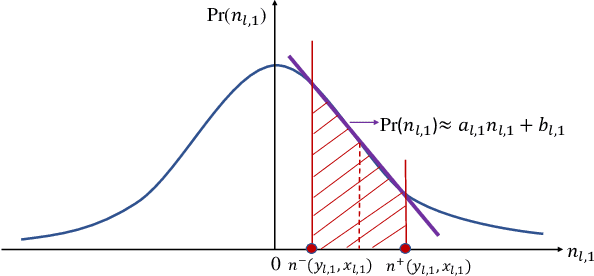
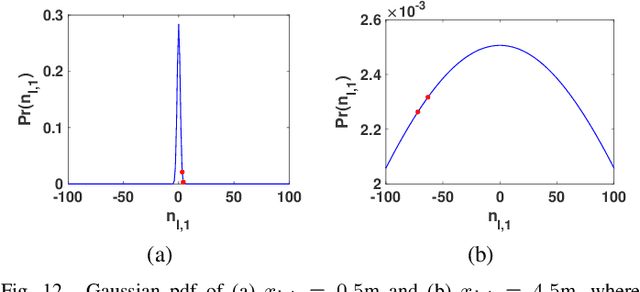
A 3D point cloud is typically constructed from depth measurements acquired by sensors at one or more viewpoints. The measurements suffer from both quantization and noise corruption. To improve quality, previous works denoise a point cloud \textit{a posteriori} after projecting the imperfect depth data onto 3D space. Instead, we enhance depth measurements directly on the sensed images \textit{a priori}, before synthesizing a 3D point cloud. By enhancing near the physical sensing process, we tailor our optimization to our depth formation model before subsequent processing steps that obscure measurement errors. Specifically, we model depth formation as a combined process of signal-dependent noise addition and non-uniform log-based quantization. The designed model is validated (with parameters fitted) using collected empirical data from an actual depth sensor. To enhance each pixel row in a depth image, we first encode intra-view similarities between available row pixels as edge weights via feature graph learning. We next establish inter-view similarities with another rectified depth image via viewpoint mapping and sparse linear interpolation. This leads to a maximum a posteriori (MAP) graph filtering objective that is convex and differentiable. We optimize the objective efficiently using accelerated gradient descent (AGD), where the optimal step size is approximated via Gershgorin circle theorem (GCT). Experiments show that our method significantly outperformed recent point cloud denoising schemes and state-of-the-art image denoising schemes, in two established point cloud quality metrics.
Sample Efficient Learning of Image-Based Diagnostic Classifiers Using Probabilistic Labels
Feb 11, 2021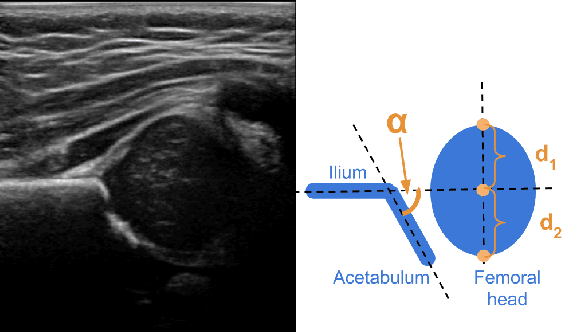
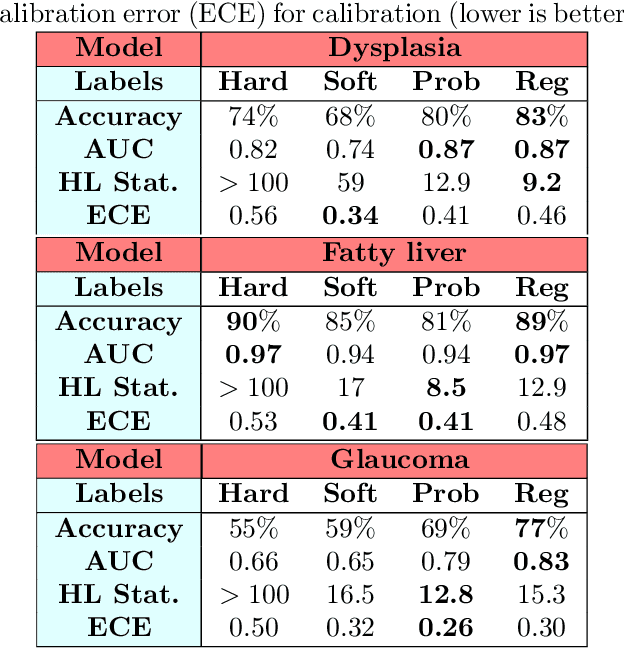
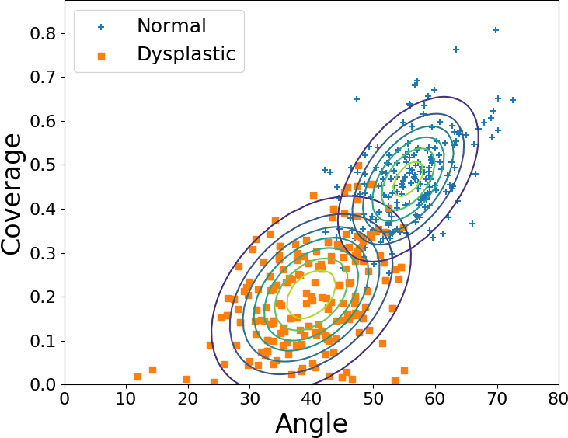
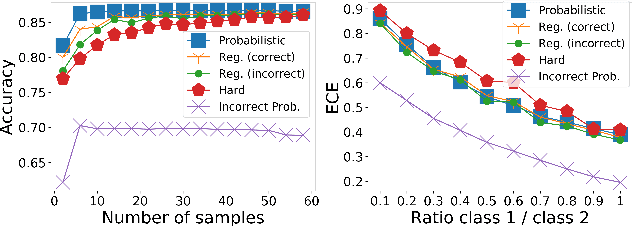
Deep learning approaches often require huge datasets to achieve good generalization. This complicates its use in tasks like image-based medical diagnosis, where the small training datasets are usually insufficient to learn appropriate data representations. For such sensitive tasks it is also important to provide the confidence in the predictions. Here, we propose a way to learn and use probabilistic labels to train accurate and calibrated deep networks from relatively small datasets. We observe gains of up to 22% in the accuracy of models trained with these labels, as compared with traditional approaches, in three classification tasks: diagnosis of hip dysplasia, fatty liver, and glaucoma. The outputs of models trained with probabilistic labels are calibrated, allowing the interpretation of its predictions as proper probabilities. We anticipate this approach will apply to other tasks where few training instances are available and expert knowledge can be encoded as probabilities.
Attention-based network for low-light image enhancement
May 20, 2020
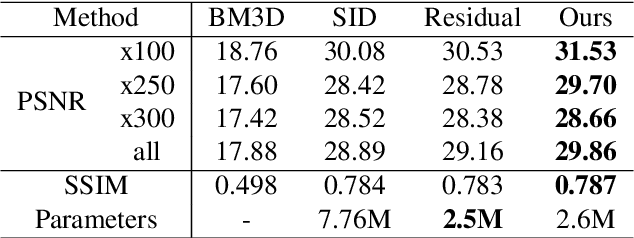
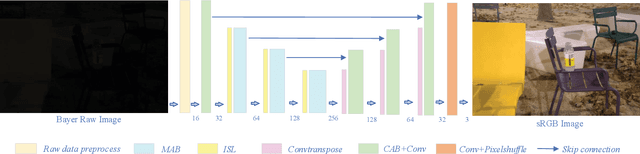

The captured images under low light conditions often suffer insufficient brightness and notorious noise. Hence, low-light image enhancement is a key challenging task in computer vision. A variety of methods have been proposed for this task, but these methods often failed in an extreme low-light environment and amplified the underlying noise in the input image. To address such a difficult problem, this paper presents a novel attention-based neural network to generate high-quality enhanced low-light images from the raw sensor data. Specifically, we first employ attention strategy (i.e. channel attention and spatial attention modules) to suppress undesired chromatic aberration and noise. The channel attention module guides the network to refine redundant colour features. The spatial attention module focuses on denoising by taking advantage of the non-local correlation in the image. Furthermore, we propose a new pooling layer, called inverted shuffle layer, which adaptively selects useful information from previous features. Extensive experiments demonstrate the superiority of the proposed network in terms of suppressing the chromatic aberration and noise artifacts in enhancement, especially when the low-light image has severe noise.
TransGaGa: Geometry-Aware Unsupervised Image-to-Image Translation
Apr 21, 2019
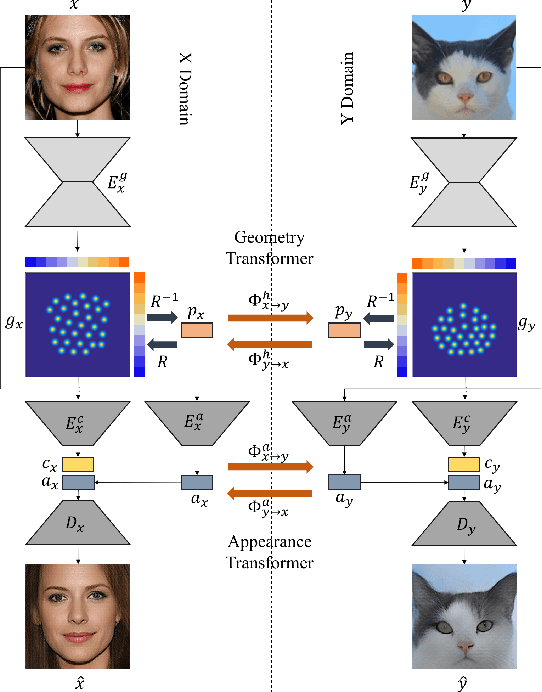
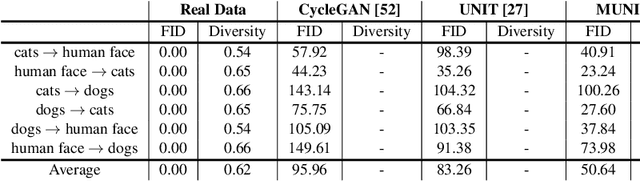

Unsupervised image-to-image translation aims at learning a mapping between two visual domains. However, learning a translation across large geometry variations always ends up with failure. In this work, we present a novel disentangle-and-translate framework to tackle the complex objects image-to-image translation task. Instead of learning the mapping on the image space directly, we disentangle image space into a Cartesian product of the appearance and the geometry latent spaces. Specifically, we first introduce a geometry prior loss and a conditional VAE loss to encourage the network to learn independent but complementary representations. The translation is then built on appearance and geometry space separately. Extensive experiments demonstrate the superior performance of our method to other state-of-the-art approaches, especially in the challenging near-rigid and non-rigid objects translation tasks. In addition, by taking different exemplars as the appearance references, our method also supports multimodal translation. Project page: https://wywu.github.io/projects/TGaGa/TGaGa.html
Progressive Distillation for Fast Sampling of Diffusion Models
Feb 01, 2022

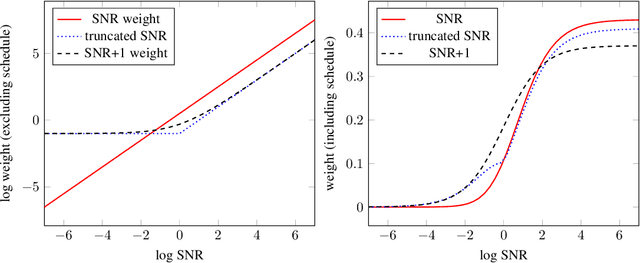
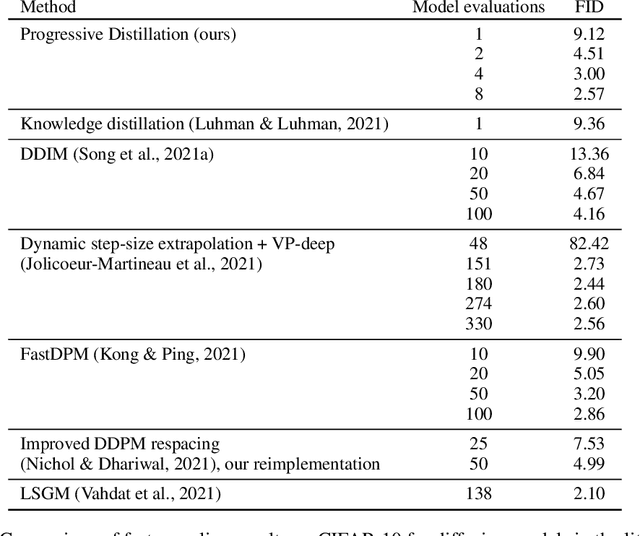
Diffusion models have recently shown great promise for generative modeling, outperforming GANs on perceptual quality and autoregressive models at density estimation. A remaining downside is their slow sampling time: generating high quality samples takes many hundreds or thousands of model evaluations. Here we make two contributions to help eliminate this downside: First, we present new parameterizations of diffusion models that provide increased stability when using few sampling steps. Second, we present a method to distill a trained deterministic diffusion sampler, using many steps, into a new diffusion model that takes half as many sampling steps. We then keep progressively applying this distillation procedure to our model, halving the number of required sampling steps each time. On standard image generation benchmarks like CIFAR-10, ImageNet, and LSUN, we start out with state-of-the-art samplers taking as many as 8192 steps, and are able to distill down to models taking as few as 4 steps without losing much perceptual quality; achieving, for example, a FID of 3.0 on CIFAR-10 in 4 steps. Finally, we show that the full progressive distillation procedure does not take more time than it takes to train the original model, thus representing an efficient solution for generative modeling using diffusion at both train and test time.