 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Guided Multi-Annotation Triplet Learning for Remote Sensing Representations
Apr 04, 2026Prior multi-task triplet loss methods relied on static weights to balance supervision between various types of annotation. However, static weighting requires tuning and does not account for how tasks interact when shaping a shared representation. To address this, the proposed task-guided multi-annotation triplet loss removes this dependency by selecting triplets through a mutual-information criteria that identifies triplets most informative across tasks. This strategy modifies which samples influence the representation rather than adjusting loss magnitudes. Experiments on an aerial wildlife dataset compare the proposed task-guided selection against several triplet loss setups for shaping a representation in an effective multi-task manner. The results show improved classification and regression performance and demonstrate that task-aware triplet selection produces a more effective shared representation for downstream tasks.
Beyond Task-Driven Features for Object Detection
Apr 04, 2026Task-driven features learned by modern object detectors optimize end task loss yet often capture shortcut correlations that fail to reflect underlying annotation structure. Such representations limit transfer, interpretability, and robustness when task definitions change or supervision becomes sparse. This paper introduces an annotation-guided feature augmentation framework that injects embeddings into an object detection backbone. The method constructs dense spatial feature grids from annotation-guided latent spaces and fuses them with feature pyramid representations to influence region proposal and detection heads. Experiments across wildlife and remote sensing datasets evaluate classification, localization, and data efficiency under multiple supervision regimes. Results show consistent improvements in object focus, reduced background sensitivity, and stronger generalization to unseen or weakly supervised tasks. The findings demonstrate that aligning features with annotation geometry yields more meaningful representations than purely task optimized features.
Multi-Task Learning with Multi-Annotation Triplet Loss for Improved Object Detection
Apr 10, 2025



Triplet loss traditionally relies only on class labels and does not use all available information in multi-task scenarios where multiple types of annotations are available. This paper introduces a Multi-Annotation Triplet Loss (MATL) framework that extends triplet loss by incorporating additional annotations, such as bounding box information, alongside class labels in the loss formulation. By using these complementary annotations, MATL improves multi-task learning for tasks requiring both classification and localization. Experiments on an aerial wildlife imagery dataset demonstrate that MATL outperforms conventional triplet loss in both classification and localization. These findings highlight the benefit of using all available annotations for triplet loss in multi-task learning frameworks.
DiagrammaticLearning: A Graphical Language for Compositional Training Regimes
Jan 02, 2025



Motivated by deep learning regimes with multiple interacting yet distinct model components, we introduce learning diagrams, graphical depictions of training setups that capture parameterized learning as data rather than code. A learning diagram compiles to a unique loss function on which component models are trained. The result of training on this loss is a collection of models whose predictions ``agree" with one another. We show that a number of popular learning setups such as few-shot multi-task learning, knowledge distillation, and multi-modal learning can be depicted as learning diagrams. We further implement learning diagrams in a library that allows users to build diagrams of PyTorch and Flux.jl models. By implementing some classic machine learning use cases, we demonstrate how learning diagrams allow practitioners to build complicated models as compositions of smaller components, identify relationships between workflows, and manipulate models during or after training. Leveraging a category theoretic framework, we introduce a rigorous semantics for learning diagrams that puts such operations on a firm mathematical foundation.
Cost-efficient Active Illumination Camera For Hyper-spectral Reconstruction
Jun 27, 2024



Hyper-spectral imaging has recently gained increasing attention for use in different applications, including agricultural investigation, ground tracking, remote sensing and many other. However, the high cost, large physical size and complicated operation process stop hyperspectral cameras from being employed for various applications and research fields. In this paper, we introduce a cost-efficient, compact and easy to use active illumination camera that may benefit many applications. We developed a fully functional prototype of such camera. With the hope of helping with agricultural research, we tested our camera for plant root imaging. In addition, a U-Net model for spectral reconstruction was trained by using a reference hyperspectral camera's data as ground truth and our camera's data as input. We demonstrated our camera's ability to obtain additional information over a typical RGB camera. In addition, the ability to reconstruct hyperspectral data from multi-spectral input makes our device compatible to models and algorithms developed for hyperspectral applications with no modifications required.
Quantifying Heterogeneous Ecosystem Services With Multi-Label Soft Classification
Jun 24, 2024



Understanding and quantifying ecosystem services are crucial for sustainable environmental management, conservation efforts, and policy-making. The advancement of remote sensing technology and machine learning techniques has greatly facilitated this process. Yet, ground truth labels, such as biodiversity, are very difficult and expensive to measure. In addition, more easily obtainable proxy labels, such as land use, often fail to capture the complex heterogeneity of the ecosystem. In this paper, we demonstrate how land use proxy labels can be implemented with a soft, multi-label classifier to predict ecosystem services with complex heterogeneity.
Histogram Layers for Neural Engineered Features
Mar 25, 2024In the computer vision literature, many effective histogram-based features have been developed. These engineered features include local binary patterns and edge histogram descriptors among others and they have been shown to be informative features for a variety of computer vision tasks. In this paper, we explore whether these features can be learned through histogram layers embedded in a neural network and, therefore, be leveraged within deep learning frameworks. By using histogram features, local statistics of the feature maps from the convolution neural networks can be used to better represent the data. We present neural versions of local binary pattern and edge histogram descriptors that jointly improve the feature representation and perform image classification. Experiments are presented on benchmark and real-world datasets.
Shared Manifold Learning Using a Triplet Network for Multiple Sensor Translation and Fusion with Missing Data
Oct 25, 2022



Heterogeneous data fusion can enhance the robustness and accuracy of an algorithm on a given task. However, due to the difference in various modalities, aligning the sensors and embedding their information into discriminative and compact representations is challenging. In this paper, we propose a Contrastive learning based MultiModal Alignment Network (CoMMANet) to align data from different sensors into a shared and discriminative manifold where class information is preserved. The proposed architecture uses a multimodal triplet autoencoder to cluster the latent space in such a way that samples of the same classes from each heterogeneous modality are mapped close to each other. Since all the modalities exist in a shared manifold, a unified classification framework is proposed. The resulting latent space representations are fused to perform more robust and accurate classification. In a missing sensor scenario, the latent space of one sensor is easily and efficiently predicted using another sensor's latent space, thereby allowing sensor translation. We conducted extensive experiments on a manually labeled multimodal dataset containing hyperspectral data from AVIRIS-NG and NEON, and LiDAR (light detection and ranging) data from NEON. Lastly, the model is validated on two benchmark datasets: Berlin Dataset (hyperspectral and synthetic aperture radar) and MUUFL Gulfport Dataset (hyperspectral and LiDAR). A comparison made with other methods demonstrates the superiority of this method. We achieved a mean overall accuracy of 94.3% on the MUUFL dataset and the best overall accuracy of 71.26% on the Berlin dataset, which is better than other state-of-the-art approaches.
Histogram Layers for Synthetic Aperture Sonar Imagery
Sep 08, 2022
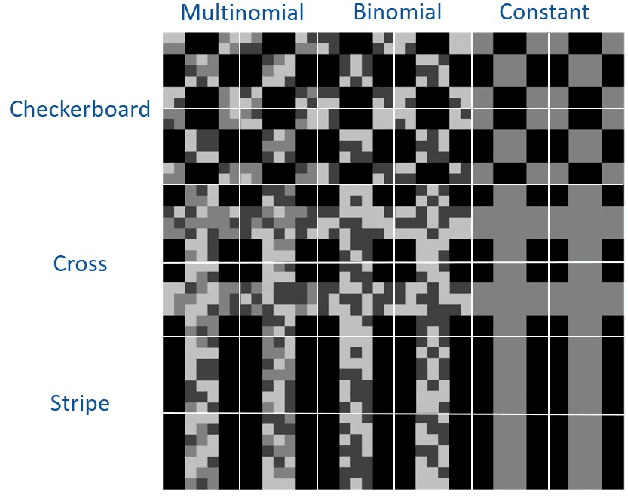
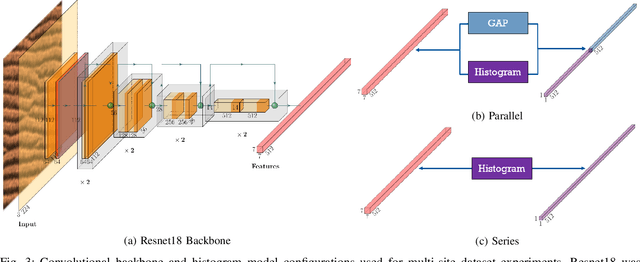

Synthetic aperture sonar (SAS) imagery is crucial for several applications, including target recognition and environmental segmentation. Deep learning models have led to much success in SAS analysis; however, the features extracted by these approaches may not be suitable for capturing certain textural information. To address this problem, we present a novel application of histogram layers on SAS imagery. The addition of histogram layer(s) within the deep learning models improved performance by incorporating statistical texture information on both synthetic and real-world datasets.
PRMI: A Dataset of Minirhizotron Images for Diverse Plant Root Study
Jan 20, 2022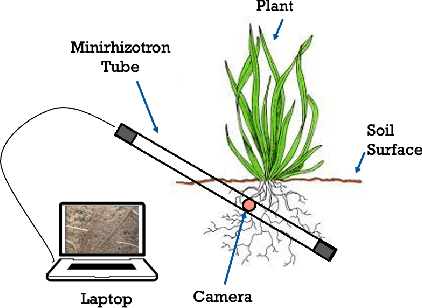
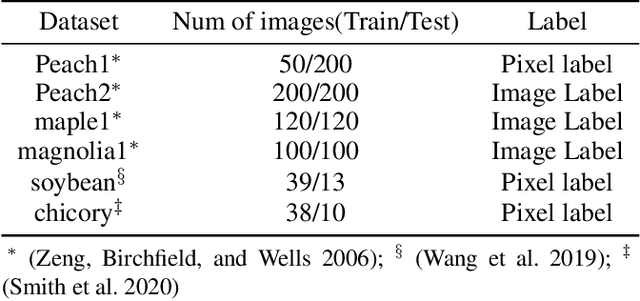

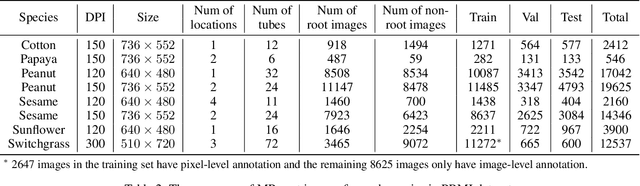
Understanding a plant's root system architecture (RSA) is crucial for a variety of plant science problem domains including sustainability and climate adaptation. Minirhizotron (MR) technology is a widely-used approach for phenotyping RSA non-destructively by capturing root imagery over time. Precisely segmenting roots from the soil in MR imagery is a critical step in studying RSA features. In this paper, we introduce a large-scale dataset of plant root images captured by MR technology. In total, there are over 72K RGB root images across six different species including cotton, papaya, peanut, sesame, sunflower, and switchgrass in the dataset. The images span a variety of conditions including varied root age, root structures, soil types, and depths under the soil surface. All of the images have been annotated with weak image-level labels indicating whether each image contains roots or not. The image-level labels can be used to support weakly supervised learning in plant root segmentation tasks. In addition, 63K images have been manually annotated to generate pixel-level binary masks indicating whether each pixel corresponds to root or not. These pixel-level binary masks can be used as ground truth for supervised learning in semantic segmentation tasks. By introducing this dataset, we aim to facilitate the automatic segmentation of roots and the research of RSA with deep learning and other image analysis algorithms.