 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FSGANv2: Improved Subject Agnostic Face Swapping and Reenactment
Feb 25, 2022


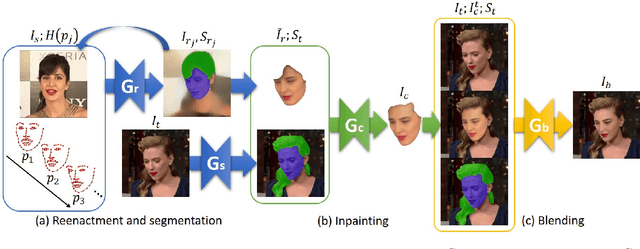
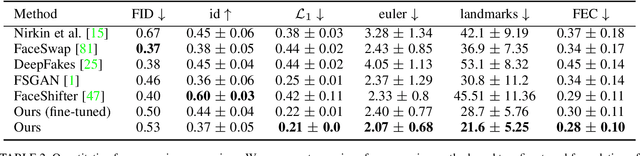
We present Face Swapping GAN (FSGAN) for face swapping and reenactment. Unlike previous work, we offer a subject agnostic swapping scheme that can be applied to pairs of faces without requiring training on those faces. We derive a novel iterative deep learning--based approach for face reenactment which adjusts significant pose and expression variations that can be applied to a single image or a video sequence. For video sequences, we introduce a continuous interpolation of the face views based on reenactment, Delaunay Triangulation, and barycentric coordinates. Occluded face regions are handled by a face completion network. Finally, we use a face blending network for seamless blending of the two faces while preserving the target skin color and lighting conditions. This network uses a novel Poisson blending loss combining Poisson optimization with a perceptual loss. We compare our approach to existing state-of-the-art systems and show our results to be both qualitatively and quantitatively superior. This work describes extensions of the FSGAN method, proposed in an earlier conference version of our work, as well as additional experiments and results.
* arXiv admin note: text overlap with arXiv:1908.05932
DPR-CAE: Capsule Autoencoder with Dynamic Part Representation for Image Parsing
Apr 30, 2021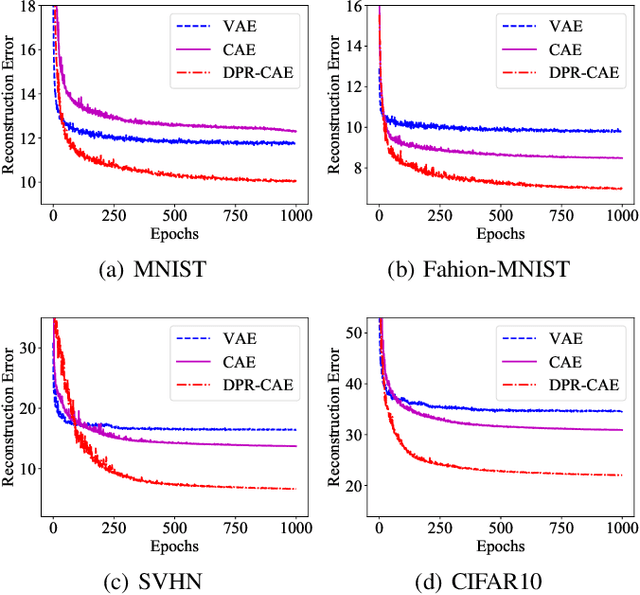
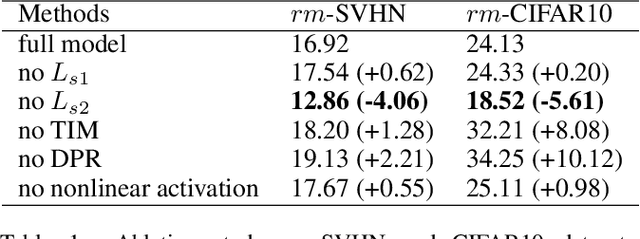
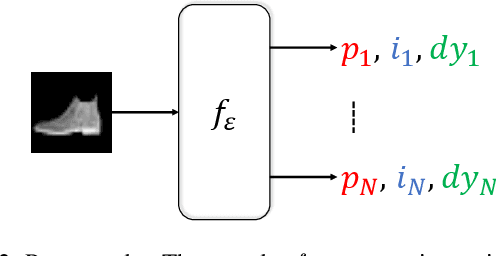

Parsing an image into a hierarchy of objects, parts, and relations is important and also challenging in many computer vision tasks. This paper proposes a simple and effective capsule autoencoder to address this issue, called DPR-CAE. In our approach, the encoder parses the input into a set of part capsules, including pose, intensity, and dynamic vector. The decoder introduces a novel dynamic part representation (DPR) by combining the dynamic vector and a shared template bank. These part representations are then regulated by corresponding capsules to composite the final output in an interpretable way. Besides, an extra translation-invariant module is proposed to avoid directly learning the uncertain scene-part relationship in our DPR-CAE, which makes the resulting method achieves a promising performance gain on $rm$-MNIST and $rm$-Fashion-MNIST. % to model the scene-object relationship DPR-CAE can be easily combined with the existing stacked capsule autoencoder and experimental results show it significantly improves performance in terms of unsupervised object classification. Our code is available in the Appendix.
Deep Convolutional Sparse Coding Networks for Image Fusion
May 18, 2020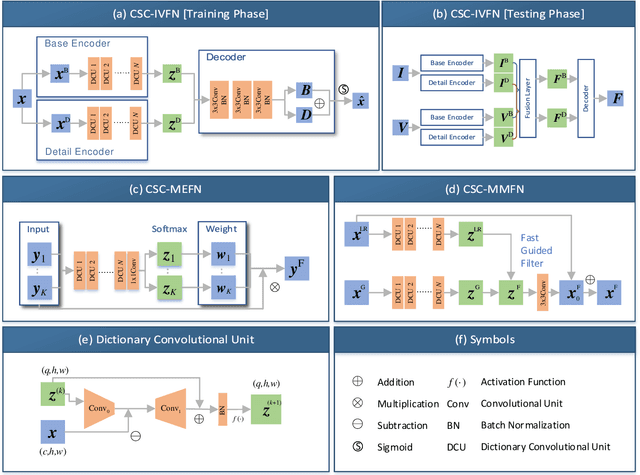


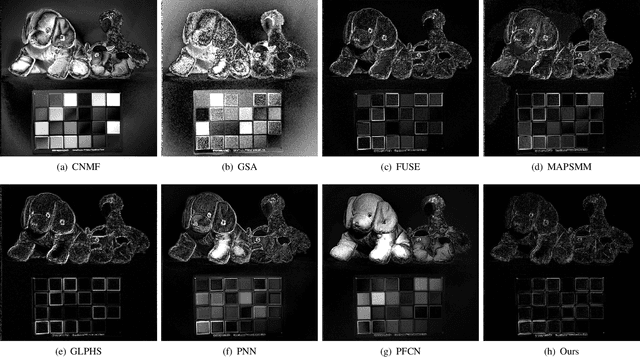
Image fusion is a significant problem in many fields including digital photography, computational imaging and remote sensing, to name but a few. Recently, deep learning has emerged as an important tool for image fusion. This paper presents three deep convolutional sparse coding (CSC) networks for three kinds of image fusion tasks (i.e., infrared and visible image fusion, multi-exposure image fusion, and multi-modal image fusion). The CSC model and the iterative shrinkage and thresholding algorithm are generalized into dictionary convolution units. As a result, all hyper-parameters are learned from data. Our extensive experiments and comprehensive comparisons reveal the superiority of the proposed networks with regard to quantitative evaluation and visual inspection.
Generalizable Information Theoretic Causal Representation
Feb 17, 2022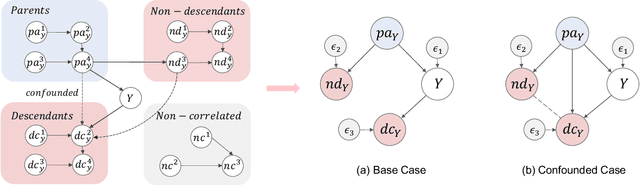
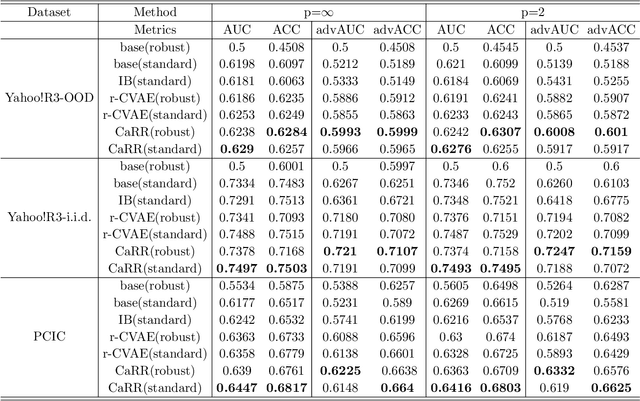
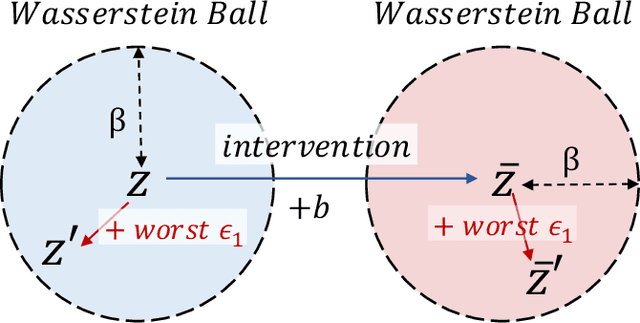
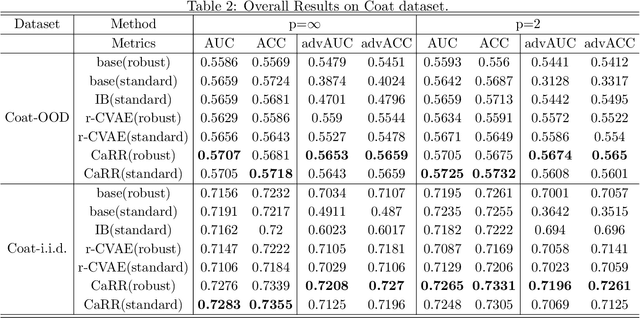
It is evidence that representation learning can improve model's performance over multiple downstream tasks in many real-world scenarios, such as image classification and recommender systems. Existing learning approaches rely on establishing the correlation (or its proxy) between features and the downstream task (labels), which typically results in a representation containing cause, effect and spurious correlated variables of the label. Its generalizability may deteriorate because of the unstability of the non-causal parts. In this paper, we propose to learn causal representation from observational data by regularizing the learning procedure with mutual information measures according to our hypothetical causal graph. The optimization involves a counterfactual loss, based on which we deduce a theoretical guarantee that the causality-inspired learning is with reduced sample complexity and better generalization ability. Extensive experiments show that the models trained on causal representations learned by our approach is robust under adversarial attacks and distribution shift.
Accelerating Neural Architecture Exploration Across Modalities Using Genetic Algorithms
Feb 25, 2022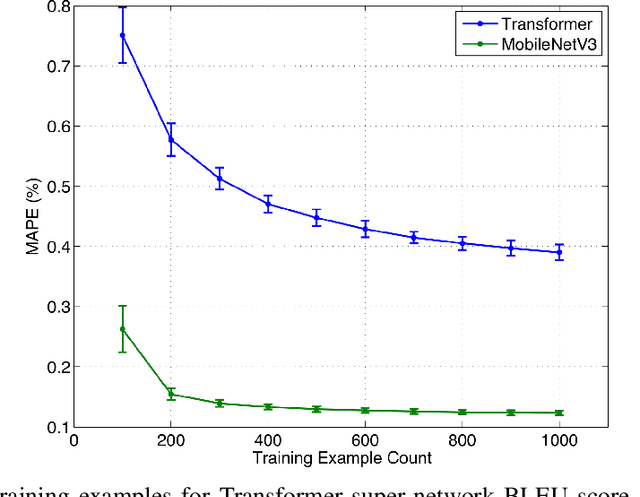
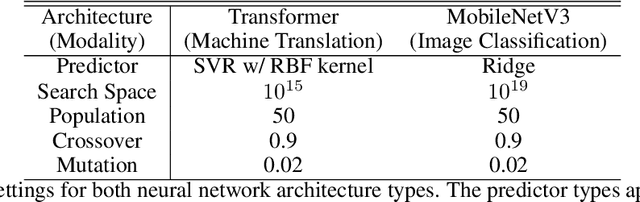
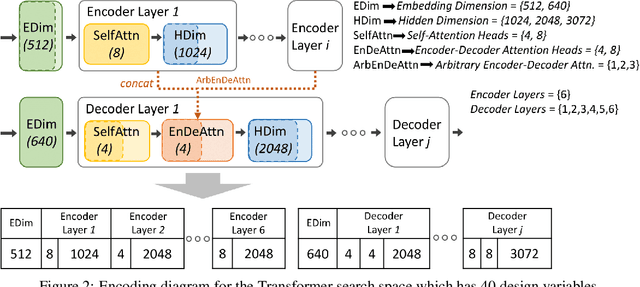
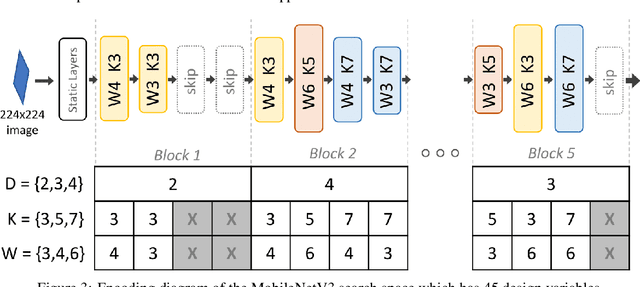
Neural architecture search (NAS), the study of automating the discovery of optimal deep neural network architectures for tasks in domains such as computer vision and natural language processing, has seen rapid growth in the machine learning research community. While there have been many recent advancements in NAS, there is still a significant focus on reducing the computational cost incurred when validating discovered architectures by making search more efficient. Evolutionary algorithms, specifically genetic algorithms, have a history of usage in NAS and continue to gain popularity versus other optimization approaches as a highly efficient way to explore the architecture objective space. Most NAS research efforts have centered around computer vision tasks and only recently have other modalities, such as the rapidly growing field of natural language processing, been investigated in depth. In this work, we show how genetic algorithms can be paired with lightly trained objective predictors in an iterative cycle to accelerate multi-objective architectural exploration in a way that works in the modalities of both machine translation and image classification.
NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion
Nov 24, 2021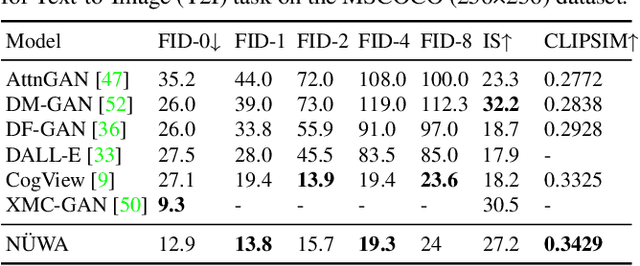
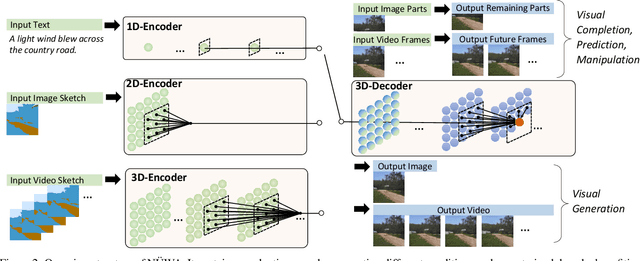
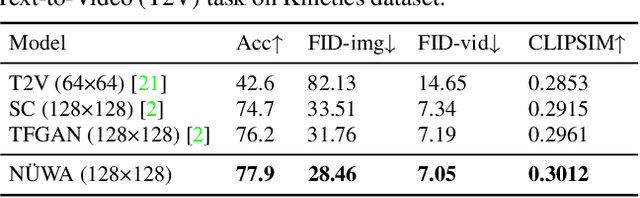

This paper presents a unified multimodal pre-trained model called N\"UWA that can generate new or manipulate existing visual data (i.e., images and videos) for various visual synthesis tasks. To cover language, image, and video at the same time for different scenarios, a 3D transformer encoder-decoder framework is designed, which can not only deal with videos as 3D data but also adapt to texts and images as 1D and 2D data, respectively. A 3D Nearby Attention (3DNA) mechanism is also proposed to consider the nature of the visual data and reduce the computational complexity. We evaluate N\"UWA on 8 downstream tasks. Compared to several strong baselines, N\"UWA achieves state-of-the-art results on text-to-image generation, text-to-video generation, video prediction, etc. Furthermore, it also shows surprisingly good zero-shot capabilities on text-guided image and video manipulation tasks. Project repo is https://github.com/microsoft/NUWA.
Dynamic multi feature-class Gaussian process models
Dec 08, 2021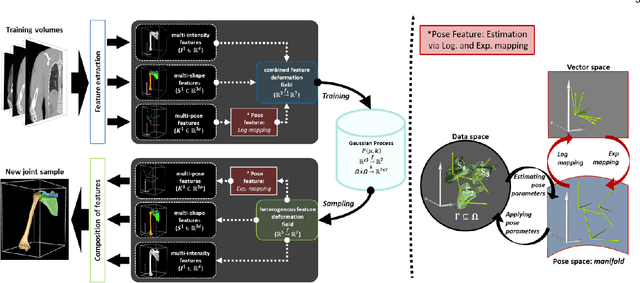
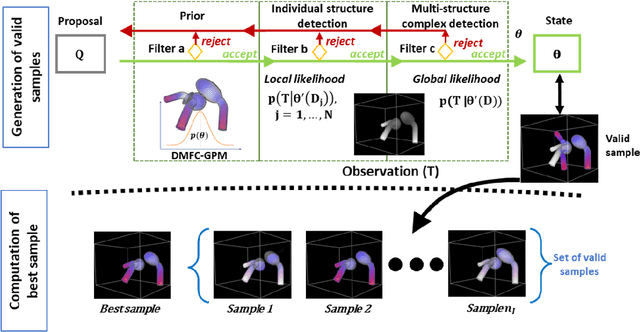
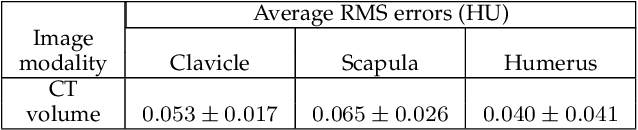
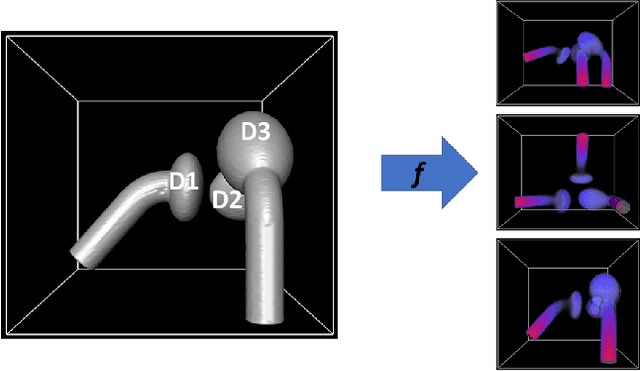
In model-based medical image analysis, three features of interest are the shape of structures of interest, their relative pose, and image intensity profiles representative of some physical property. Often, these are modelled separately through statistical models by decomposing the object's features into a set of basis functions through principal geodesic analysis or principal component analysis. This study presents a statistical modelling method for automatic learning of shape, pose and intensity features in medical images which we call the Dynamic multi feature-class Gaussian process models (DMFC-GPM). A DMFC-GPM is a Gaussian process (GP)-based model with a shared latent space that encodes linear and non-linear variation. Our method is defined in a continuous domain with a principled way to represent shape, pose and intensity feature classes in a linear space, based on deformation fields. A deformation field-based metric is adapted in the method for modelling shape and intensity feature variation as well as for comparing rigid transformations (pose). Moreover, DMFC-GPMs inherit properties intrinsic to GPs including marginalisation and regression. Furthermore, they allow for adding additional pose feature variability on top of those obtained from the image acquisition process; what we term as permutation modelling. For image analysis tasks using DMFC-GPMs, we adapt Metropolis-Hastings algorithms making the prediction of features fully probabilistic. We validate the method using controlled synthetic data and we perform experiments on bone structures from CT images of the shoulder to illustrate the efficacy of the model for pose and shape feature prediction. The model performance results suggest that this new modelling paradigm is robust, accurate, accessible, and has potential applications including the management of musculoskeletal disorders and clinical decision making
How to Fill the Optimum Set? Population Gradient Descent with Harmless Diversity
Feb 16, 2022
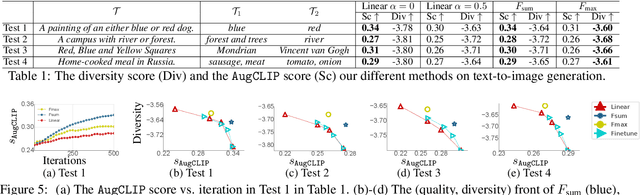
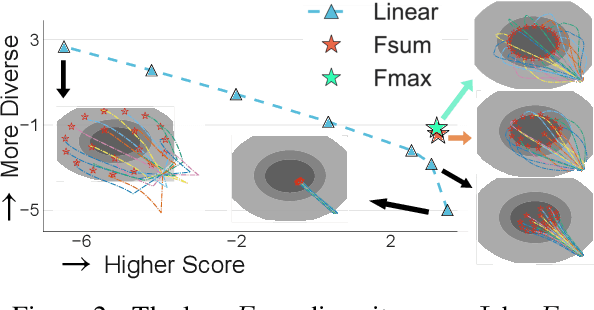

Although traditional optimization methods focus on finding a single optimal solution, most objective functions in modern machine learning problems, especially those in deep learning, often have multiple or infinite numbers of optima. Therefore, it is useful to consider the problem of finding a set of diverse points in the optimum set of an objective function. In this work, we frame this problem as a bi-level optimization problem of maximizing a diversity score inside the optimum set of the main loss function, and solve it with a simple population gradient descent framework that iteratively updates the points to maximize the diversity score in a fashion that does not hurt the optimization of the main loss. We demonstrate that our method can efficiently generate diverse solutions on a variety of applications, including text-to-image generation, text-to-mesh generation, molecular conformation generation and ensemble neural network training.
Model-Based Reconstruction for Collimated Beam Ultrasound Systems
Feb 20, 2022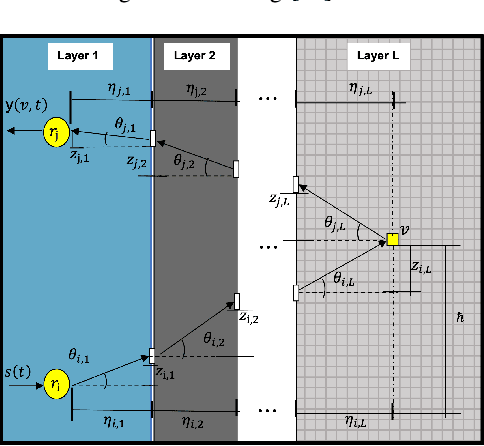
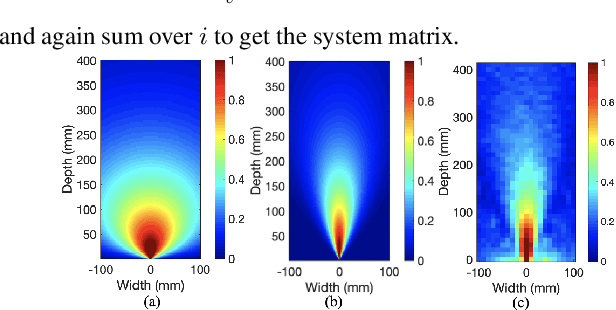
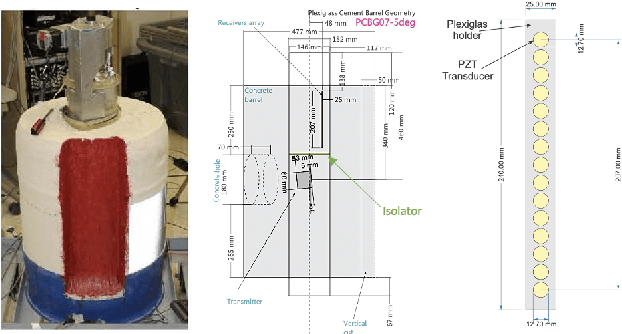
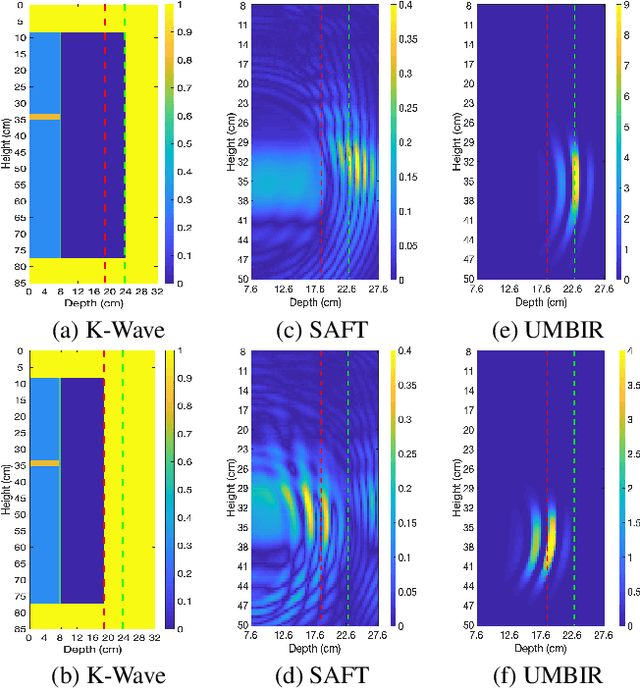
Collimated beam ultrasound systems are a novel technology for imaging inside multi-layered structures such as geothermal wells. Such systems include a transmitter and multiple receivers to capture reflected signals. Common algorithms for ultrasound reconstruction use delay-and-sum (DAS) approaches; these have low computational complexity but produce inaccurate images in the presence of complex structures and specialized geometries such as collimated beams. In this paper, we propose a multi-layer, ultrasonic, model-based iterative reconstruction algorithm designed for collimated beam systems. We introduce a physics-based forward model to accurately account for the propagation of a collimated ultrasonic beam in multi-layer media and describe an efficient implementation using binary search. We model direct arrival signals, detector noise, and a spatially varying image prior, then cast the reconstruction as a maximum a posteriori estimation problem. Using simulated and experimental data we obtain significantly fewer artifacts relative to DAS while running in near real time using commodity compute resources.
A-ESRGAN: Training Real-World Blind Super-Resolution with Attention U-Net Discriminators
Dec 19, 2021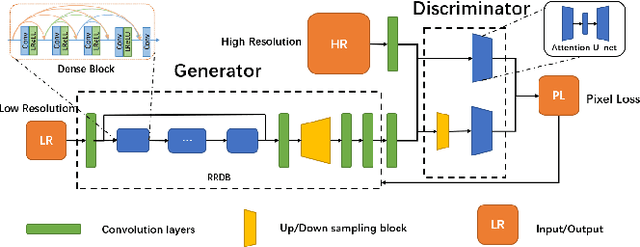

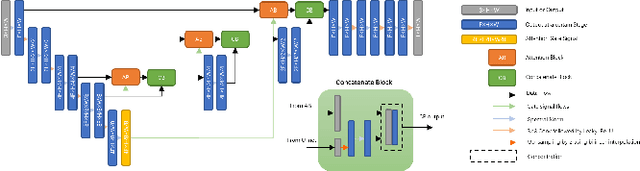
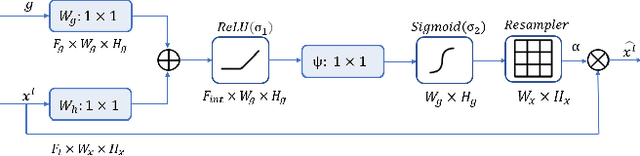
Blind image super-resolution(SR) is a long-standing task in CV that aims to restore low-resolution images suffering from unknown and complex distortions. Recent work has largely focused on adopting more complicated degradation models to emulate real-world degradations. The resulting models have made breakthroughs in perceptual loss and yield perceptually convincing results. However, the limitation brought by current generative adversarial network structures is still significant: treating pixels equally leads to the ignorance of the image's structural features, and results in performance drawbacks such as twisted lines and background over-sharpening or blurring. In this paper, we present A-ESRGAN, a GAN model for blind SR tasks featuring an attention U-Net based, multi-scale discriminator that can be seamlessly integrated with other generators. To our knowledge, this is the first work to introduce attention U-Net structure as the discriminator of GAN to solve blind SR problems. And the paper also gives an interpretation for the mechanism behind multi-scale attention U-Net that brings performance breakthrough to the model. Through comparison experiments with prior works, our model presents state-of-the-art level performance on the non-reference natural image quality evaluator metric. And our ablation studies have shown that with our discriminator, the RRDB based generator can leverage the structural features of an image in multiple scales, and consequently yields more perceptually realistic high-resolution images compared to prior works.