 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TIME: Text and Image Mutual-Translation Adversarial Networks
May 27, 2020


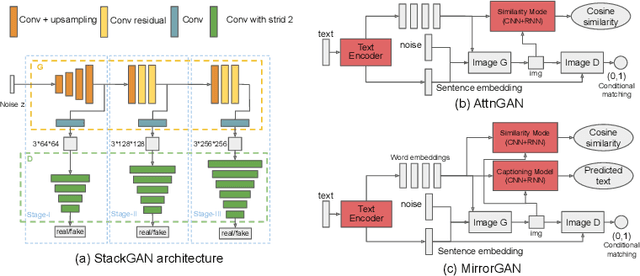

Focusing on text-to-image (T2I) generation, we propose Text and Image Mutual-Translation Adversarial Networks (TIME), a lightweight but effective model that jointly learns a T2I generator $G$ and an image captioning discriminator $D$ under the Generative Adversarial Network framework. While previous methods tackle the T2I problem as a uni-directional task and use pre-trained language models to enforce the image-text consistency, TIME requires neither extra modules nor pre-training. We show that the performance of $G$ can be boosted substantially by training it jointly with $D$ as a language model. Specifically, we adopt Transformers to model the cross-modal connections between the image features and word embeddings, and design a hinged and annealing conditional loss that dynamically balances the adversarial learning. In our experiments, TIME establishes the new state-of-the-art Inception Score of 4.88 on the CUB dataset, and shows competitive performance on MS-COCO on both text-to-image and image captioning tasks.
Open source disease analysis system of cactus by artificial intelligence and image processing
Jun 07, 2021
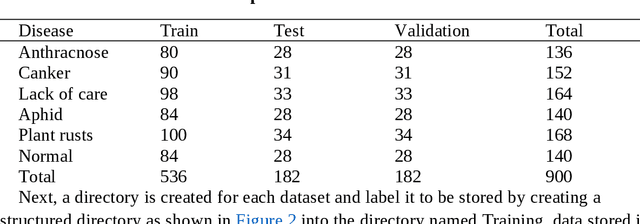
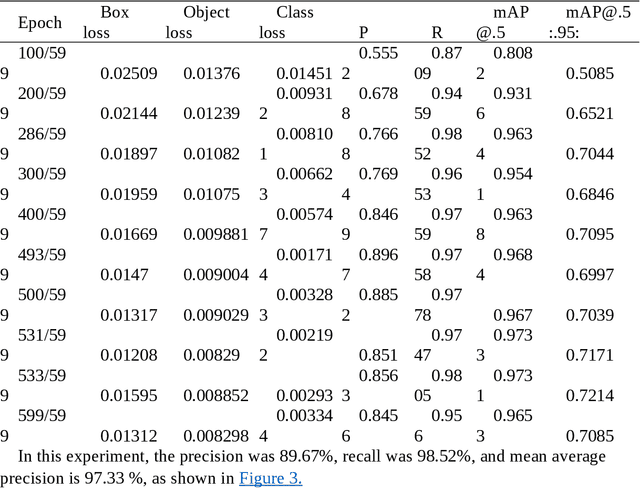
There is a growing interest in cactus cultivation because of numerous cacti uses from houseplants to food and medicinal applications. Various diseases impact the growth of cacti. To develop an automated model for the analysis of cactus disease and to be able to quickly treat and prevent damage to the cactus. The Faster R-CNN and YOLO algorithm technique were used to analyze cactus diseases automatically distributed into six groups: 1) anthracnose, 2) canker, 3) lack of care, 4) aphid, 5) rusts and 6) normal group. Based on the experimental results the YOLOv5 algorithm was found to be more effective at detecting and identifying cactus disease than the Faster R-CNN algorithm. Data training and testing with YOLOv5S model resulted in a precision of 89.7% and an accuracy (recall) of 98.5%, which is effective enough for further use in a number of applications in cactus cultivation. Overall the YOLOv5 algorithm had a test time per image of only 26 milliseconds. Therefore, the YOLOv5 algorithm was found to suitable for mobile applications and this model could be further developed into a program for analyzing cactus disease.
Semantic-Aware Generation for Self-Supervised Visual Representation Learning
Nov 25, 2021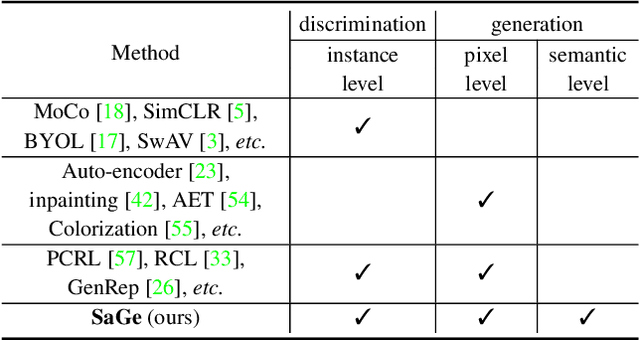
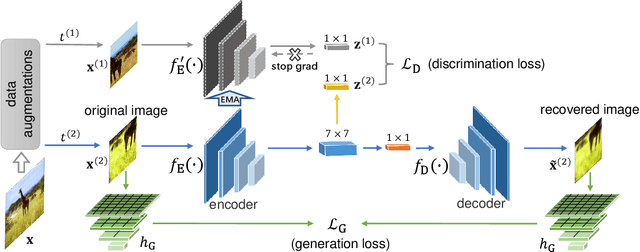

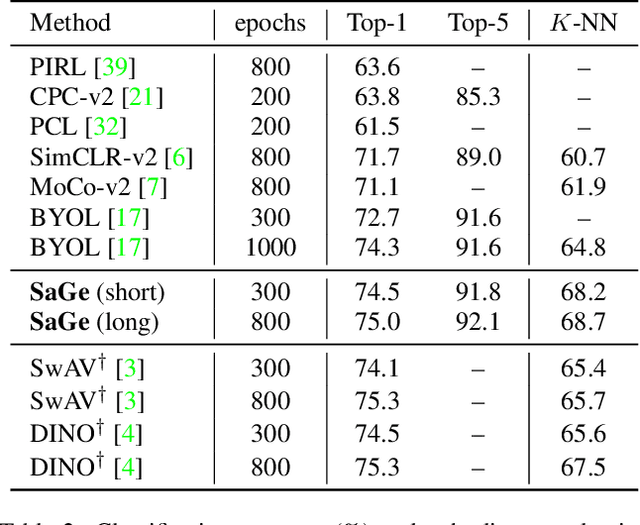
In this paper, we propose a self-supervised visual representation learning approach which involves both generative and discriminative proxies, where we focus on the former part by requiring the target network to recover the original image based on the mid-level features. Different from prior work that mostly focuses on pixel-level similarity between the original and generated images, we advocate for Semantic-aware Generation (SaGe) to facilitate richer semantics rather than details to be preserved in the generated image. The core idea of implementing SaGe is to use an evaluator, a deep network that is pre-trained without labels, for extracting semantic-aware features. SaGe complements the target network with view-specific features and thus alleviates the semantic degradation brought by intensive data augmentations. We execute SaGe on ImageNet-1K and evaluate the pre-trained models on five downstream tasks including nearest neighbor test, linear classification, and fine-scaled image recognition, demonstrating its ability to learn stronger visual representations.
LocATe: End-to-end Localization of Actions in 3D with Transformers
Mar 21, 2022

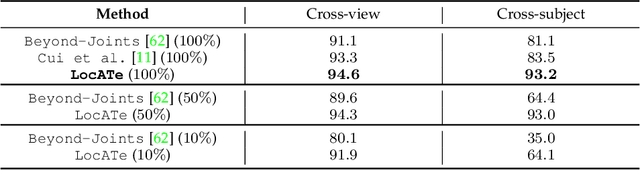
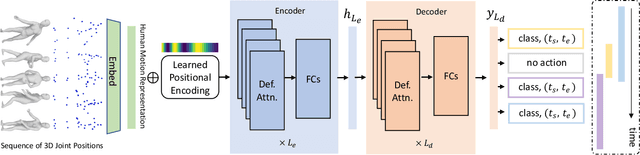
Understanding a person's behavior from their 3D motion is a fundamental problem in computer vision with many applications. An important component of this problem is 3D Temporal Action Localization (3D-TAL), which involves recognizing what actions a person is performing, and when. State-of-the-art 3D-TAL methods employ a two-stage approach in which the action span detection task and the action recognition task are implemented as a cascade. This approach, however, limits the possibility of error-correction. In contrast, we propose LocATe, an end-to-end approach that jointly localizes and recognizes actions in a 3D sequence. Further, unlike existing autoregressive models that focus on modeling the local context in a sequence, LocATe's transformer model is capable of capturing long-term correlations between actions in a sequence. Unlike transformer-based object-detection and classification models which consider image or patch features as input, the input in 3D-TAL is a long sequence of highly correlated frames. To handle the high-dimensional input, we implement an effective input representation, and overcome the diffuse attention across long time horizons by introducing sparse attention in the model. LocATe outperforms previous approaches on the existing PKU-MMD 3D-TAL benchmark (mAP=93.2%). Finally, we argue that benchmark datasets are most useful where there is clear room for performance improvement. To that end, we introduce a new, challenging, and more realistic benchmark dataset, BABEL-TAL-20 (BT20), where the performance of state-of-the-art methods is significantly worse. The dataset and code for the method will be available for research purposes.
Diversify and Disambiguate: Learning From Underspecified Data
Feb 07, 2022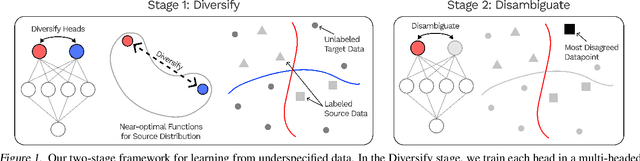
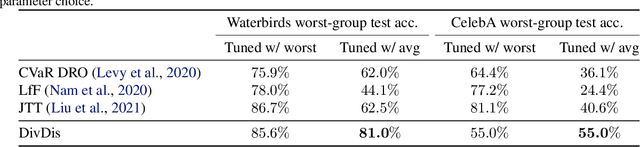
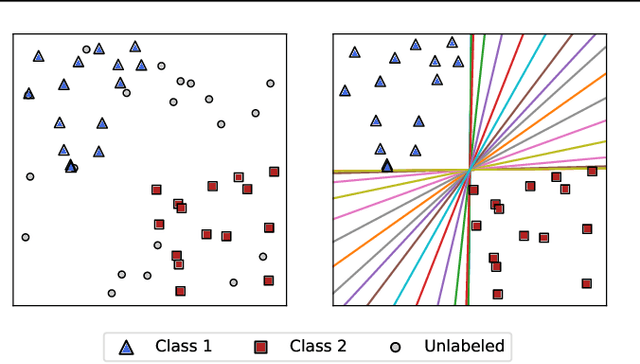
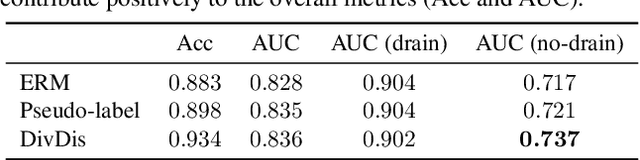
Many datasets are underspecified, which means there are several equally viable solutions for the data. Underspecified datasets can be problematic for methods that learn a single hypothesis because different functions that achieve low training loss can focus on different predictive features and thus have widely varying predictions on out-of-distribution data. We propose DivDis, a simple two-stage framework that first learns a diverse collection of hypotheses for a task by leveraging unlabeled data from the test distribution. We then disambiguate by selecting one of the discovered hypotheses using minimal additional supervision, in the form of additional labels or inspection of function visualization. We demonstrate the ability of DivDis to find hypotheses that use robust features in image classification and natural language processing problems with underspecification.
Efficient sign language recognition system and dataset creation method based on deep learning and image processing
Mar 22, 2021

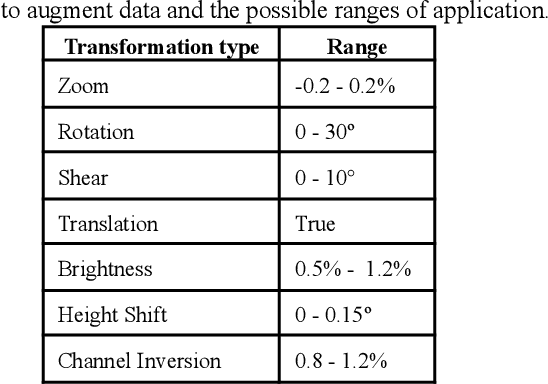
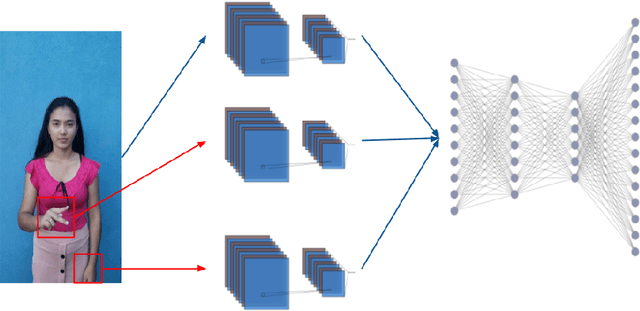
New deep-learning architectures are created every year, achieving state-of-the-art results in image recognition and leading to the belief that, in a few years, complex tasks such as sign language translation will be considerably easier, serving as a communication tool for the hearing-impaired community. On the other hand, these algorithms still need a lot of data to be trained and the dataset creation process is expensive, time-consuming, and slow. Thereby, this work aims to investigate techniques of digital image processing and machine learning that can be used to create a sign language dataset effectively. We argue about data acquisition, such as the frames per second rate to capture or subsample the videos, the background type, preprocessing, and data augmentation, using convolutional neural networks and object detection to create an image classifier and comparing the results based on statistical tests. Different datasets were created to test the hypotheses, containing 14 words used daily and recorded by different smartphones in the RGB color system. We achieved an accuracy of 96.38% on the test set and 81.36% on the validation set containing more challenging conditions, showing that 30 FPS is the best frame rate subsample to train the classifier, geometric transformations work better than intensity transformations, and artificial background creation is not effective to model generalization. These trade-offs should be considered in future work as a cost-benefit guideline between computational cost and accuracy gain when creating a dataset and training a sign recognition model.
Leveraging Visual Question Answering to Improve Text-to-Image Synthesis
Oct 28, 2020
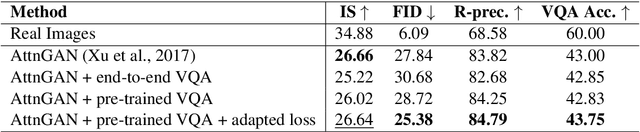
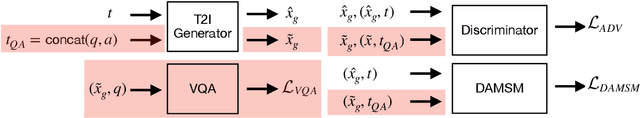
Generating images from textual descriptions has recently attracted a lot of interest. While current models can generate photo-realistic images of individual objects such as birds and human faces, synthesising images with multiple objects is still very difficult. In this paper, we propose an effective way to combine Text-to-Image (T2I) synthesis with Visual Question Answering (VQA) to improve the image quality and image-text alignment of generated images by leveraging the VQA 2.0 dataset. We create additional training samples by concatenating question and answer (QA) pairs and employ a standard VQA model to provide the T2I model with an auxiliary learning signal. We encourage images generated from QA pairs to look realistic and additionally minimize an external VQA loss. Our method lowers the FID from 27.84 to 25.38 and increases the R-prec. from 83.82% to 84.79% when compared to the baseline, which indicates that T2I synthesis can successfully be improved using a standard VQA model.
Exploring Intensity Invariance in Deep Neural Networks for Brain Image Registration
Sep 21, 2020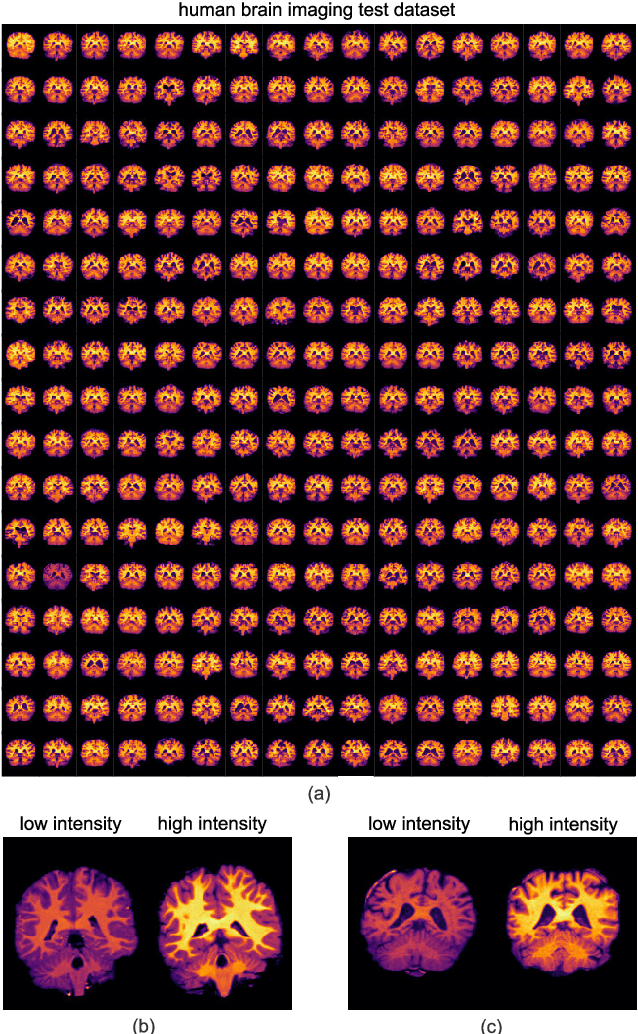
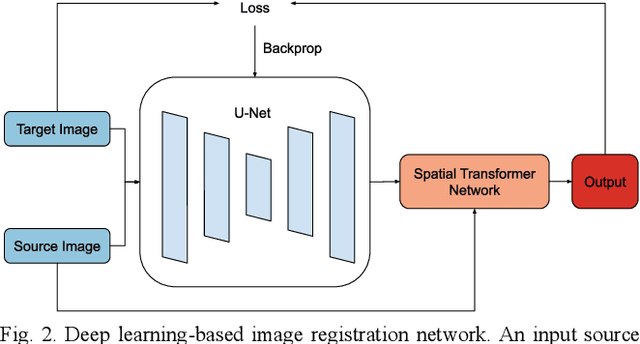

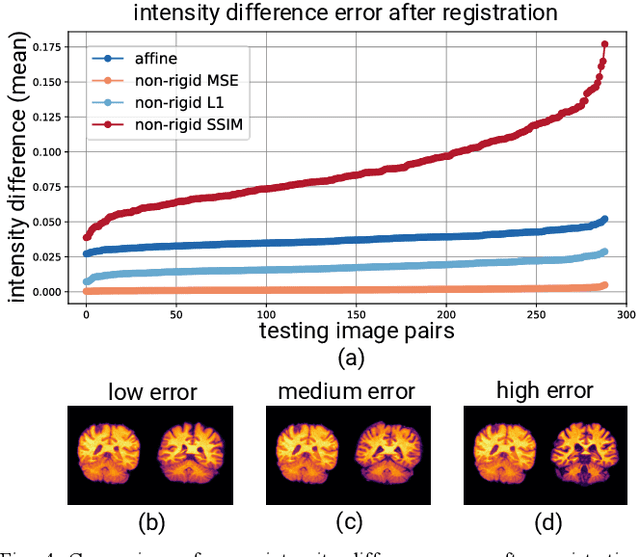
Image registration is a widely-used technique in analysing large scale datasets that are captured through various imaging modalities and techniques in biomedical imaging such as MRI, X-Rays, etc. These datasets are typically collected from various sites and under different imaging protocols using a variety of scanners. Such heterogeneity in the data collection process causes inhomogeneity or variation in intensity (brightness) and noise distribution. These variations play a detrimental role in the performance of image registration, segmentation and detection algorithms. Classical image registration methods are computationally expensive but are able to handle these artifacts relatively better. However, deep learning-based techniques are shown to be computationally efficient for automated brain registration but are sensitive to the intensity variations. In this study, we investigate the effect of variation in intensity distribution among input image pairs for deep learning-based image registration methods. We find a performance degradation of these models when brain image pairs with different intensity distribution are presented even with similar structures. To overcome this limitation, we incorporate a structural similarity-based loss function in a deep neural network and test its performance on the validation split separated before training as well as on a completely unseen new dataset. We report that the deep learning models trained with structure similarity-based loss seems to perform better for both datasets. This investigation highlights a possible performance limiting factor in deep learning-based registration models and suggests a potential solution to incorporate the intensity distribution variation in the input image pairs. Our code and models are available at https://github.com/hassaanmahmood/DeepIntense.
Latent Outlier Exposure for Anomaly Detection with Contaminated Data
Feb 20, 2022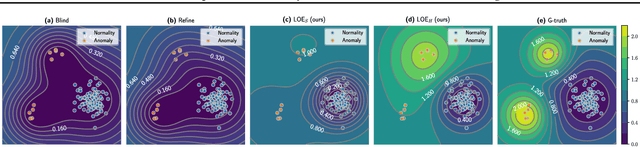
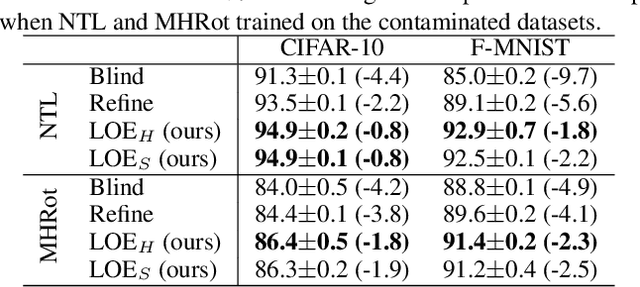
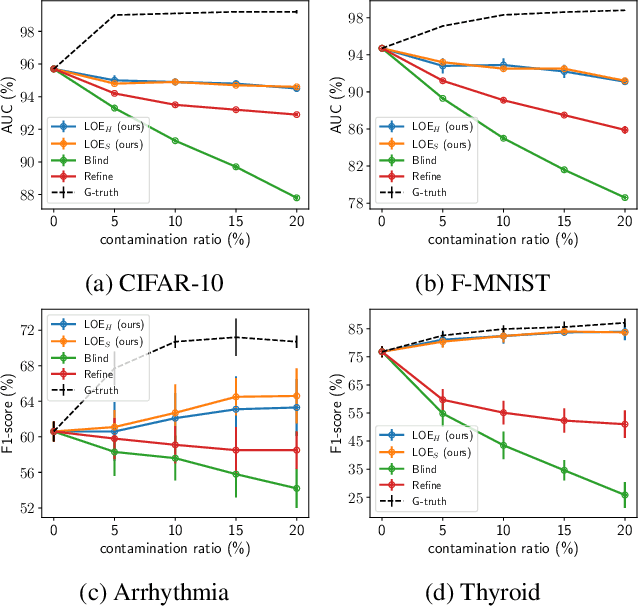
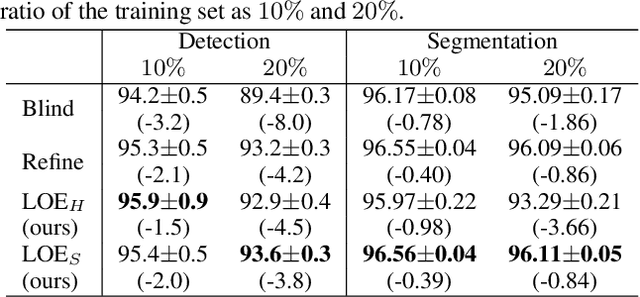
Anomaly detection aims at identifying data points that show systematic deviations from the majority of data in an unlabeled dataset. A common assumption is that clean training data (free of anomalies) is available, which is often violated in practice. We propose a strategy for training an anomaly detector in the presence of unlabeled anomalies that is compatible with a broad class of models. The idea is to jointly infer binary labels to each datum (normal vs. anomalous) while updating the model parameters. Inspired by outlier exposure (Hendrycks et al., 2018) that considers synthetically created, labeled anomalies, we thereby use a combination of two losses that share parameters: one for the normal and one for the anomalous data. We then iteratively proceed with block coordinate updates on the parameters and the most likely (latent) labels. Our experiments with several backbone models on three image datasets, 30 tabular data sets, and a video anomaly detection benchmark showed consistent and significant improvements over the baselines.
EPNet++: Cascade Bi-directional Fusion for Multi-Modal 3D Object Detection
Jan 12, 2022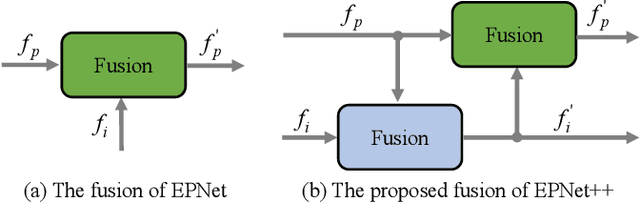
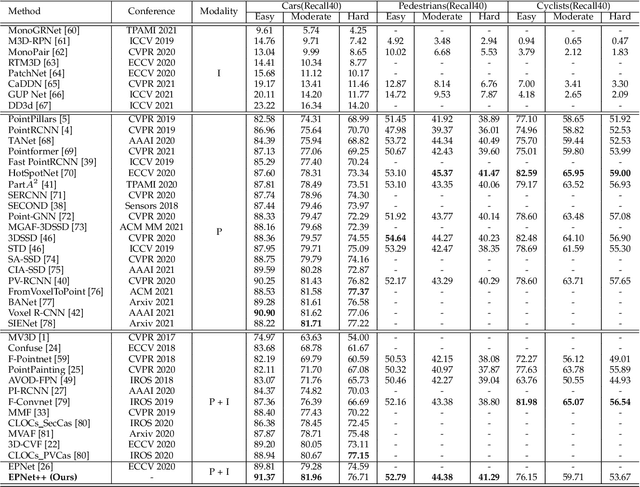
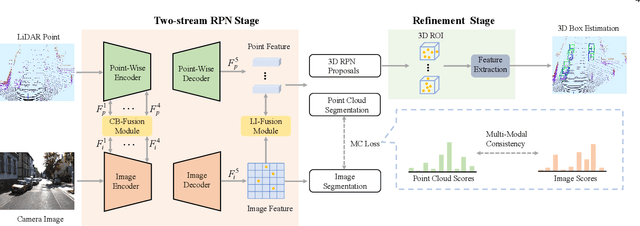
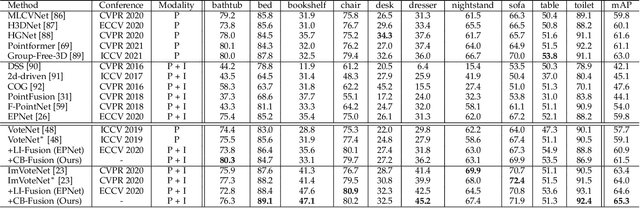
Recently, fusing the LiDAR point cloud and camera image to improve the performance and robustness of 3D object detection has received more and more attention, as these two modalities naturally possess strong complementarity. In this paper, we propose EPNet++ for multi-modal 3D object detection by introducing a novel Cascade Bi-directional Fusion~(CB-Fusion) module and a Multi-Modal Consistency~(MC) loss. More concretely, the proposed CB-Fusion module boosts the plentiful semantic information of point features with the image features in a cascade bi-directional interaction fusion manner, leading to more comprehensive and discriminative feature representations. The MC loss explicitly guarantees the consistency between predicted scores from two modalities to obtain more comprehensive and reliable confidence scores. The experiment results on the KITTI, JRDB and SUN-RGBD datasets demonstrate the superiority of EPNet++ over the state-of-the-art methods. Besides, we emphasize a critical but easily overlooked problem, which is to explore the performance and robustness of a 3D detector in a sparser scene. Extensive experiments present that EPNet++ outperforms the existing SOTA methods with remarkable margins in highly sparse point cloud cases, which might be an available direction to reduce the expensive cost of LiDAR sensors. Code will be released in the future.