 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image-to-image Mapping with Many Domains by Sparse Attribute Transfer
Jun 23, 2020
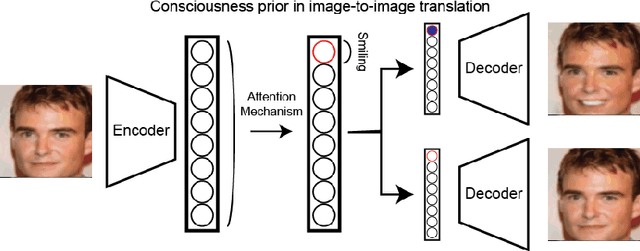
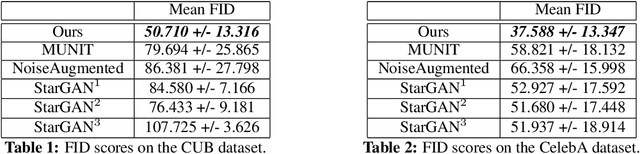
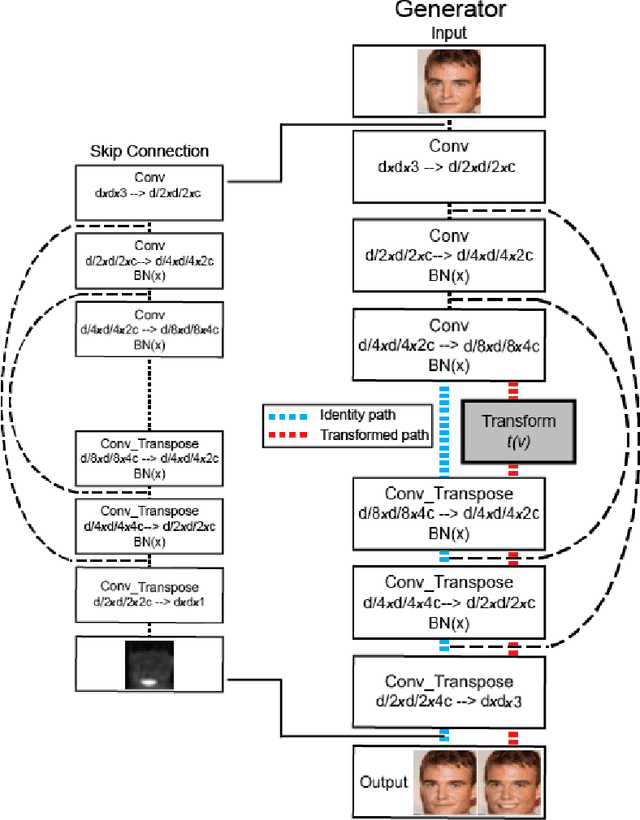

Unsupervised image-to-image translation consists of learning a pair of mappings between two domains without known pairwise correspondences between points. The current convention is to approach this task with cycle-consistent GANs: using a discriminator to encourage the generator to change the image to match the target domain, while training the generator to be inverted with another mapping. While ending up with paired inverse functions may be a good end result, enforcing this restriction at all times during training can be a hindrance to effective modeling. We propose an alternate approach that directly restricts the generator to performing a simple sparse transformation in a latent layer, motivated by recent work from cognitive neuroscience suggesting an architectural prior on representations corresponding to consciousness. Our biologically motivated approach leads to representations more amenable to transformation by disentangling high-level abstract concepts in the latent space. We demonstrate that image-to-image domain translation with many different domains can be learned more effectively with our architecturally constrained, simple transformation than with previous unconstrained architectures that rely on a cycle-consistency loss.
ViT2Hash: Unsupervised Information-Preserving Hashing
Jan 14, 2022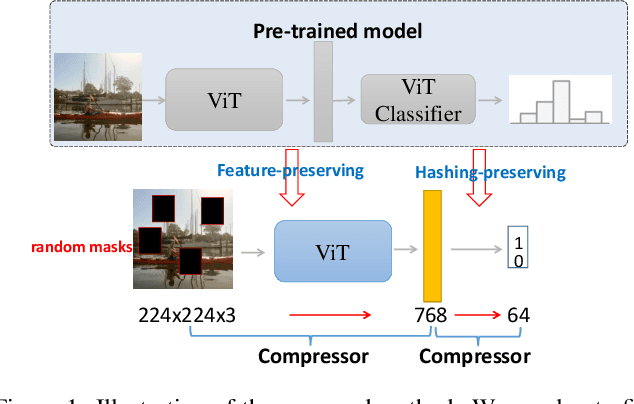
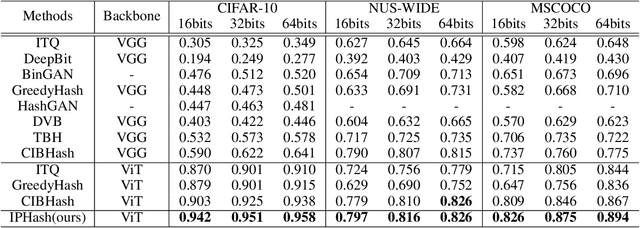
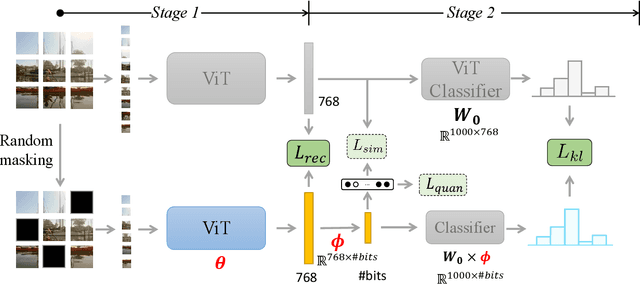
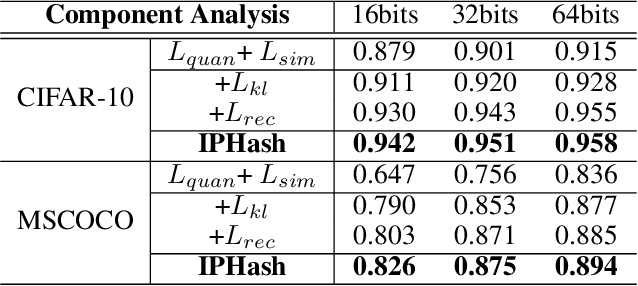
Unsupervised image hashing, which maps images into binary codes without supervision, is a compressor with a high compression rate. Hence, how to preserving meaningful information of the original data is a critical problem. Inspired by the large-scale vision pre-training model, known as ViT, which has shown significant progress for learning visual representations, in this paper, we propose a simple information-preserving compressor to finetune the ViT model for the target unsupervised hashing task. Specifically, from pixels to continuous features, we first propose a feature-preserving module, using the corrupted image as input to reconstruct the original feature from the pre-trained ViT model and the complete image, so that the feature extractor can focus on preserving the meaningful information of original data. Secondly, from continuous features to hash codes, we propose a hashing-preserving module, which aims to keep the semantic information from the pre-trained ViT model by using the proposed Kullback-Leibler divergence loss. Besides, the quantization loss and the similarity loss are added to minimize the quantization error. Our method is very simple and achieves a significantly higher degree of MAP on three benchmark image datasets.
MixFormer: Mixing Features across Windows and Dimensions
Apr 12, 2022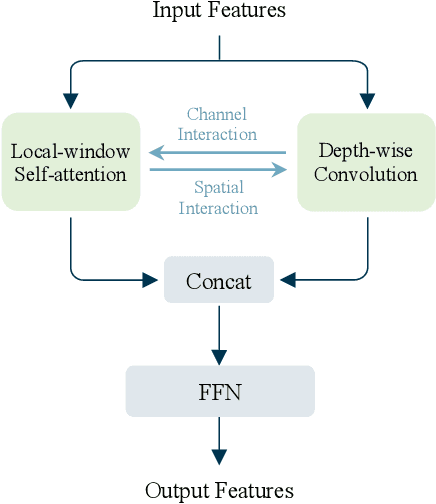

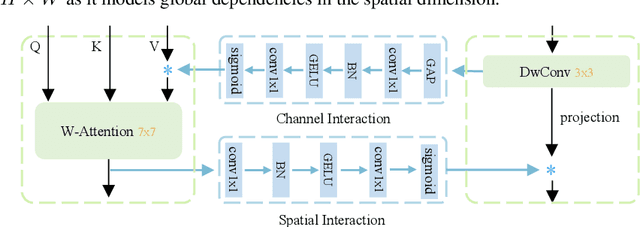

While local-window self-attention performs notably in vision tasks, it suffers from limited receptive field and weak modeling capability issues. This is mainly because it performs self-attention within non-overlapped windows and shares weights on the channel dimension. We propose MixFormer to find a solution. First, we combine local-window self-attention with depth-wise convolution in a parallel design, modeling cross-window connections to enlarge the receptive fields. Second, we propose bi-directional interactions across branches to provide complementary clues in the channel and spatial dimensions. These two designs are integrated to achieve efficient feature mixing among windows and dimensions. Our MixFormer provides competitive results on image classification with EfficientNet and shows better results than RegNet and Swin Transformer. Performance in downstream tasks outperforms its alternatives by significant margins with less computational costs in 5 dense prediction tasks on MS COCO, ADE20k, and LVIS. Code is available at \url{https://github.com/PaddlePaddle/PaddleClas}.
NDPNet: A novel non-linear data projection network for few-shot fine-grained image classification
Jun 15, 2021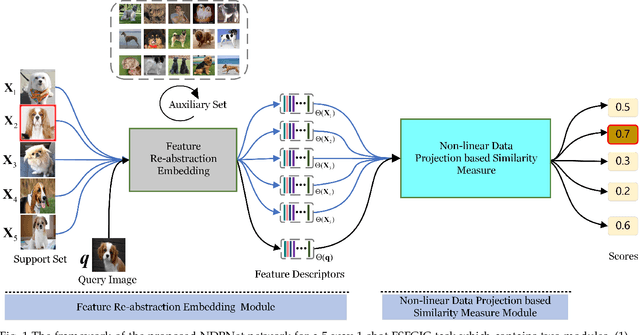
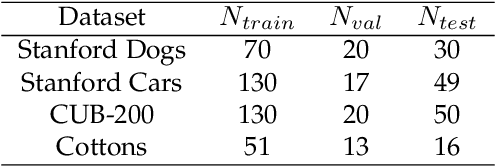
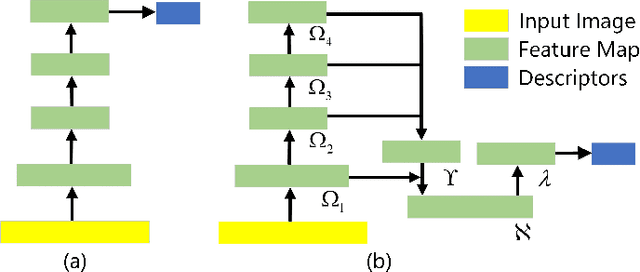
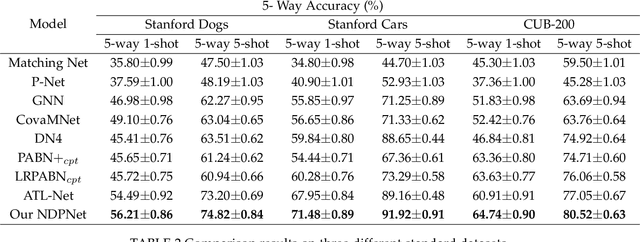
Metric-based few-shot fine-grained image classification (FSFGIC) aims to learn a transferable feature embedding network by estimating the similarities between query images and support classes from very few examples. In this work, we propose, for the first time, to introduce the non-linear data projection concept into the design of FSFGIC architecture in order to address the limited sample problem in few-shot learning and at the same time to increase the discriminability of the model for fine-grained image classification. Specifically, we first design a feature re-abstraction embedding network that has the ability to not only obtain the required semantic features for effective metric learning but also re-enhance such features with finer details from input images. Then the descriptors of the query images and the support classes are projected into different non-linear spaces in our proposed similarity metric learning network to learn discriminative projection factors. This design can effectively operate in the challenging and restricted condition of a FSFGIC task for making the distance between the samples within the same class smaller and the distance between samples from different classes larger and for reducing the coupling relationship between samples from different categories. Furthermore, a novel similarity measure based on the proposed non-linear data project is presented for evaluating the relationships of feature information between a query image and a support set. It is worth to note that our proposed architecture can be easily embedded into any episodic training mechanisms for end-to-end training from scratch. Extensive experiments on FSFGIC tasks demonstrate the superiority of the proposed methods over the state-of-the-art benchmarks.
GlassNet: Label Decoupling-based Three-stream Neural Network for Robust Image Glass Detection
Aug 25, 2021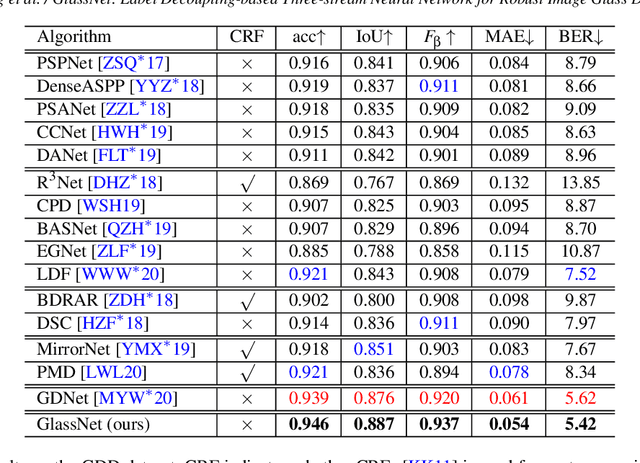

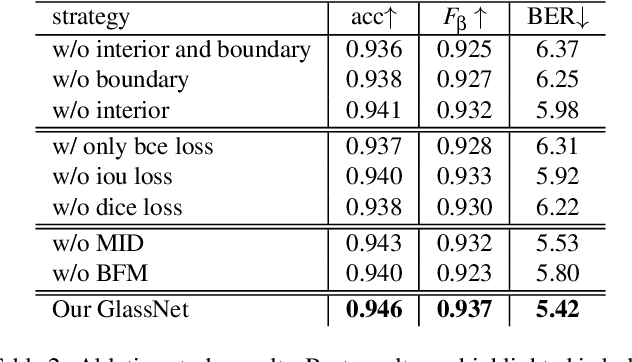

Most of the existing object detection methods generate poor glass detection results, due to the fact that the transparent glass shares the same appearance with arbitrary objects behind it in an image. Different from traditional deep learning-based wisdoms that simply use the object boundary as auxiliary supervision, we exploit label decoupling to decompose the original labeled ground-truth (GT) map into an interior-diffusion map and a boundary-diffusion map. The GT map in collaboration with the two newly generated maps breaks the imbalanced distribution of the object boundary, leading to improved glass detection quality. We have three key contributions to solve the transparent glass detection problem: (1) We propose a three-stream neural network (call GlassNet for short) to fully absorb beneficial features in the three maps. (2) We design a multi-scale interactive dilation module to explore a wider range of contextual information. (3) We develop an attention-based boundary-aware feature Mosaic module to integrate multi-modal information. Extensive experiments on the benchmark dataset exhibit clear improvements of our method over SOTAs, in terms of both the overall glass detection accuracy and boundary clearness.
PSCC-Net: Progressive Spatio-Channel Correlation Network for Image Manipulation Detection and Localization
Mar 19, 2021
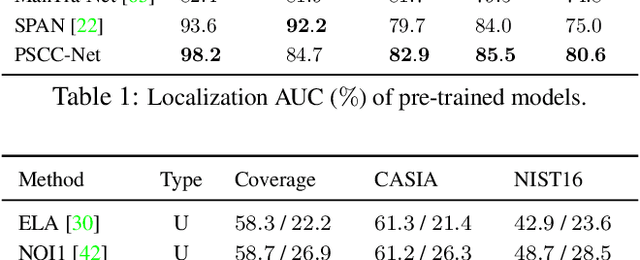
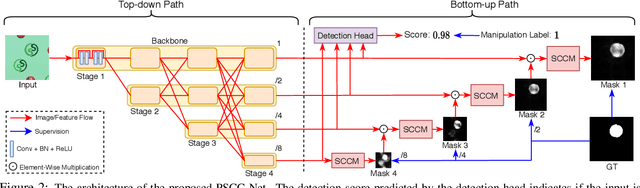
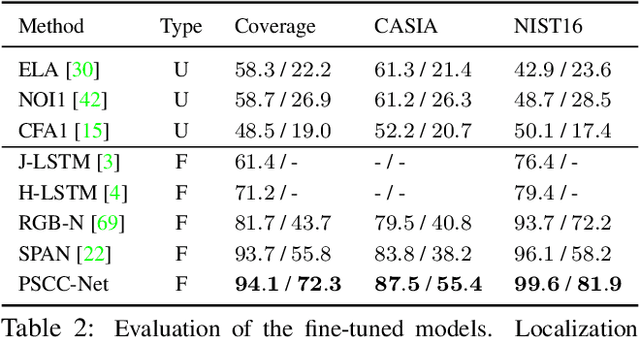
To defend against manipulation of image content, such as splicing, copy-move, and removal, we develop a Progressive Spatio-Channel Correlation Network (PSCC-Net) to detect and localize image manipulations. PSCC-Net processes the image in a two-path procedure: a top-down path that extracts local and global features and a bottom-up path that detects whether the input image is manipulated, and estimates its manipulation masks at 4 scales, where each mask is conditioned on the previous one. Different from the conventional encoder-decoder and no-pooling structures, PSCC-Net leverages features at different scales with dense cross-connections to produce manipulation masks in a coarse-to-fine fashion. Moreover, a Spatio-Channel Correlation Module (SCCM) captures both spatial and channel-wise correlations in the bottom-up path, which endows features with holistic cues, enabling the network to cope with a wide range of manipulation attacks. Thanks to the light-weight backbone and progressive mechanism, PSCC-Net can process 1,080P images at 50+ FPS. Extensive experiments demonstrate the superiority of PSCC-Net over the state-of-the-art methods on both detection and localization.
Learning-Based Quality Assessment for Image Super-Resolution
Dec 16, 2020
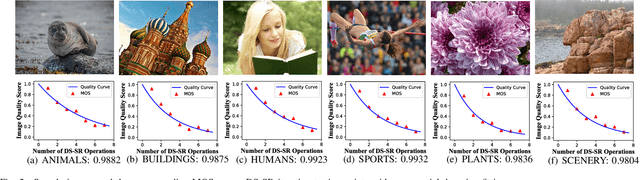

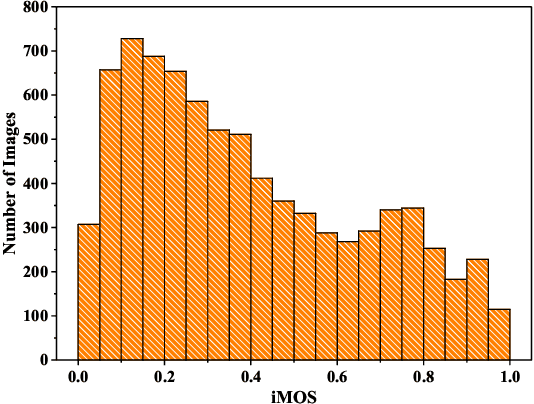
Image Super-Resolution (SR) techniques improve visual quality by enhancing the spatial resolution of images. Quality evaluation metrics play a critical role in comparing and optimizing SR algorithms, but current metrics achieve only limited success, largely due to the lack of large-scale quality databases, which are essential for learning accurate and robust SR quality metrics. In this work, we first build a large-scale SR image database using a novel semi-automatic labeling approach, which allows us to label a large number of images with manageable human workload. The resulting SR Image quality database with Semi-Automatic Ratings (SISAR), so far the largest of SR-IQA database, contains 8,400 images of 100 natural scenes. We train an end-to-end Deep Image SR Quality (DISQ) model by employing two-stream Deep Neural Networks (DNNs) for feature extraction, followed by a feature fusion network for quality prediction. Experimental results demonstrate that the proposed method outperforms state-of-the-art metrics and achieves promising generalization performance in cross-database tests. The SISAR database and DISQ model will be made publicly available to facilitate reproducible research.
Enhanced Magnetic Resonance Image Synthesis with Contrast-Aware Generative Adversarial Networks
Mar 01, 2021
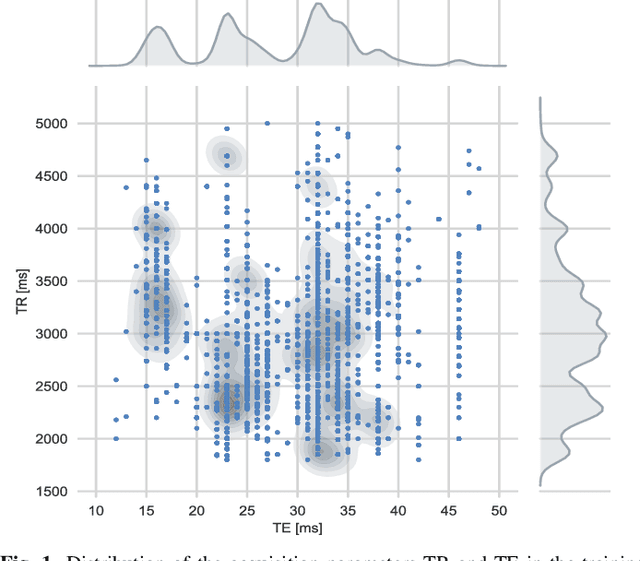
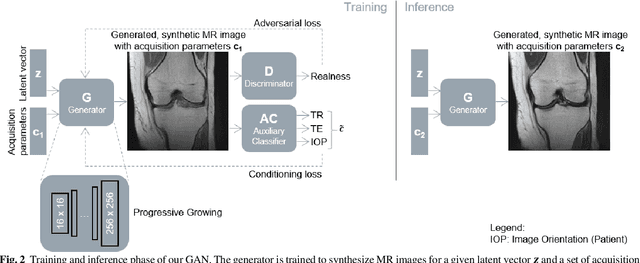
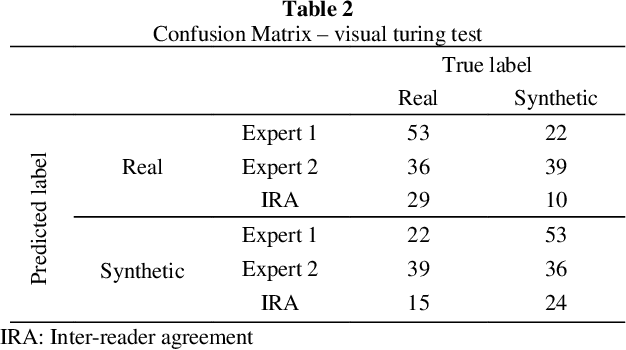
A Magnetic Resonance Imaging (MRI) exam typically consists of the acquisition of multiple MR pulse sequences, which are required for a reliable diagnosis. Each sequence can be parameterized through multiple acquisition parameters affecting MR image contrast, signal-to-noise ratio, resolution, or scan time. With the rise of generative deep learning models, approaches for the synthesis of MR images are developed to either synthesize additional MR contrasts, generate synthetic data, or augment existing data for AI training. However, current generative approaches for the synthesis of MR images are only trained on images with a specific set of acquisition parameter values, limiting the clinical value of these methods as various sets of acquisition parameter settings are used in clinical practice. Therefore, we trained a generative adversarial network (GAN) to generate synthetic MR knee images conditioned on various acquisition parameters (repetition time, echo time, image orientation). This approach enables us to synthesize MR images with adjustable image contrast. In a visual Turing test, two experts mislabeled 40.5% of real and synthetic MR images, demonstrating that the image quality of the generated synthetic and real MR images is comparable. This work can support radiologists and technologists during the parameterization of MR sequences by previewing the yielded MR contrast, can serve as a valuable tool for radiology training, and can be used for customized data generation to support AI training.
Explaining Classifiers by Constructing Familiar Concepts
Mar 07, 2022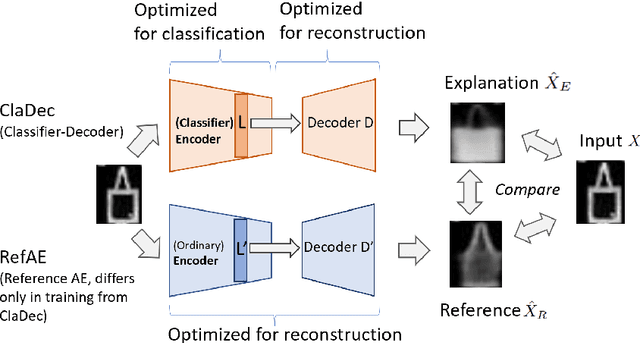
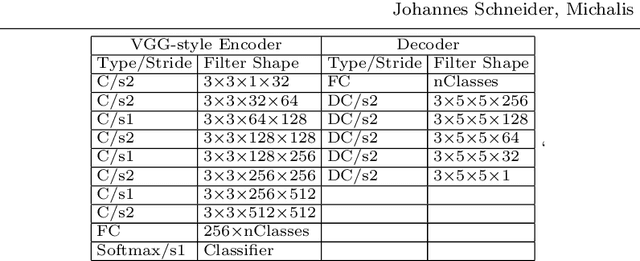
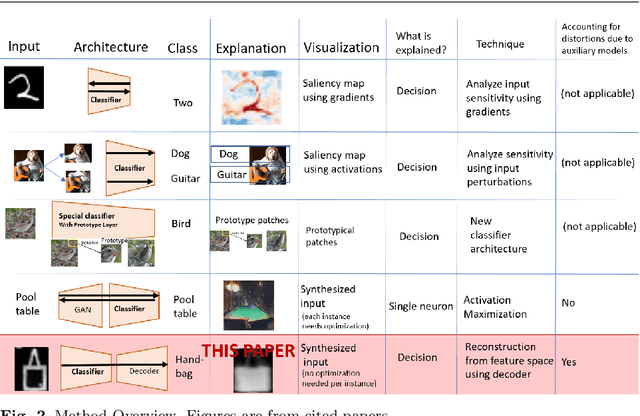
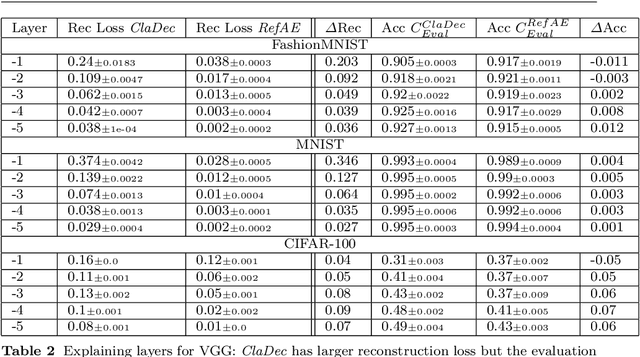
Interpreting a large number of neurons in deep learning is difficult. Our proposed `CLAssifier-DECoder' architecture (ClaDec) facilitates the understanding of the output of an arbitrary layer of neurons or subsets thereof. It uses a decoder that transforms the incomprehensible representation of the given neurons to a representation that is more similar to the domain a human is familiar with. In an image recognition problem, one can recognize what information (or concepts) a layer maintains by contrasting reconstructed images of ClaDec with those of a conventional auto-encoder(AE) serving as reference. An extension of ClaDec allows trading comprehensibility and fidelity. We evaluate our approach for image classification using convolutional neural networks. We show that reconstructed visualizations using encodings from a classifier capture more relevant classification information than conventional AEs. This holds although AEs contain more information on the original input. Our user study highlights that even non-experts can identify a diverse set of concepts contained in images that are relevant (or irrelevant) for the classifier. We also compare against saliency based methods that focus on pixel relevance rather than concepts. We show that ClaDec tends to highlight more relevant input areas to classification though outcomes depend on classifier architecture. Code is at \url{https://github.com/JohnTailor/ClaDec}
Automatic Detection of Interplanetary Coronal Mass Ejections in Solar Wind In Situ Data
May 07, 2022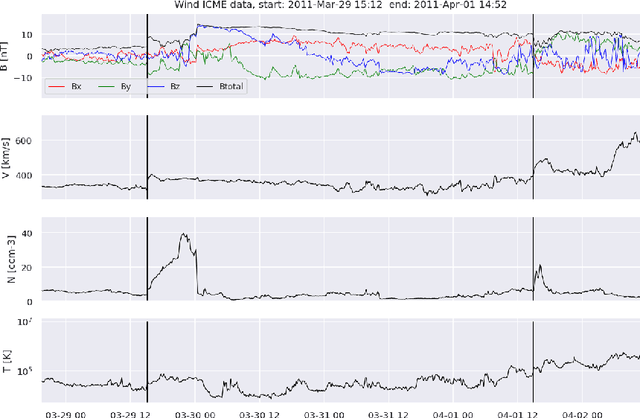
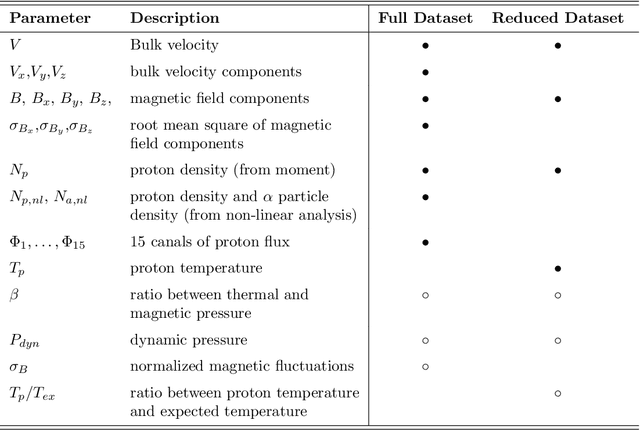
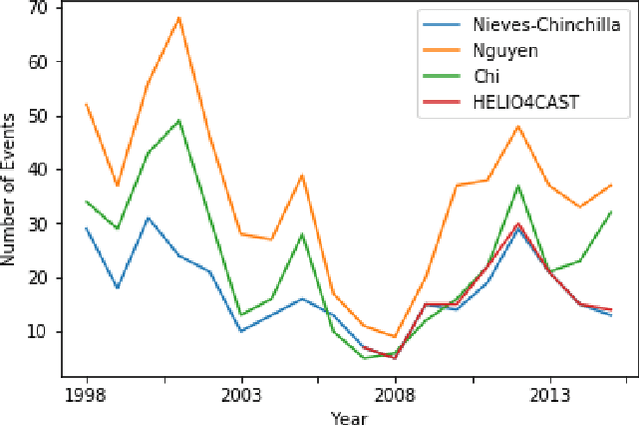
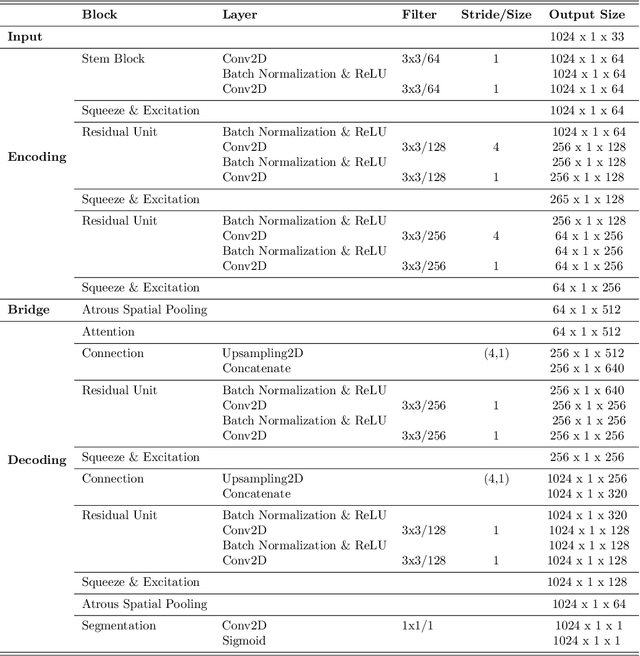
Interplanetary coronal mass ejections (ICMEs) are one of the main drivers for space weather disturbances. In the past, different approaches have been used to automatically detect events in existing time series resulting from solar wind in situ observations. However, accurate and fast detection still remains a challenge when facing the large amount of data from different instruments. For the automatic detection of ICMEs we propose a pipeline using a method that has recently proven successful in medical image segmentation. Comparing it to an existing method, we find that while achieving similar results, our model outperforms the baseline regarding training time by a factor of approximately 20, thus making it more applicable for other datasets. The method has been tested on in situ data from the Wind spacecraft between 1997 and 2015 with a True Skill Statistic (TSS) of 0.64. Out of the 640 ICMEs, 466 were detected correctly by our algorithm, producing a total of 254 False Positives. Additionally, it produced reasonable results on datasets with fewer features and smaller training sets from Wind, STEREO-A and STEREO-B with True Skill Statistics of 0.56, 0.57 and 0.53, respectively. Our pipeline manages to find the start of an ICME with a mean absolute error (MAE) of around 2 hours and 56 minutes, and the end time with a MAE of 3 hours and 20 minutes. The relatively fast training allows straightforward tuning of hyperparameters and could therefore easily be used to detect other structures and phenomena in solar wind data, such as corotating interaction regions.