 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Multihop QA: A Cause-Effect Approach for Reducing Disconnected Reasoning
Oct 13, 2022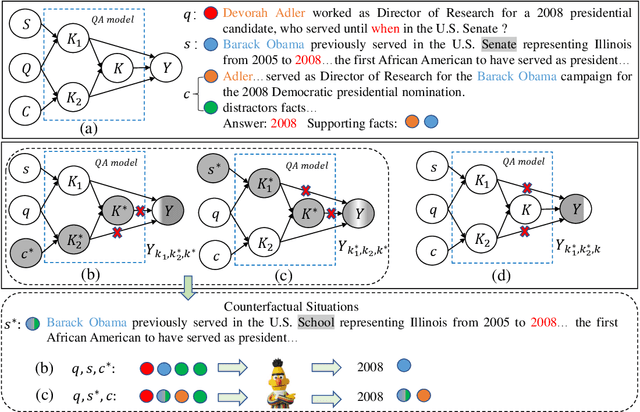
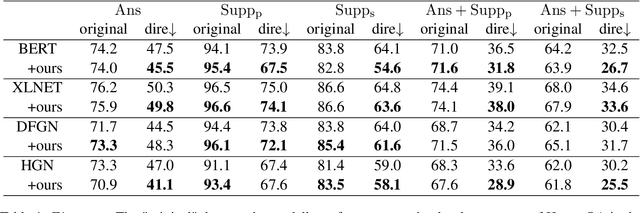
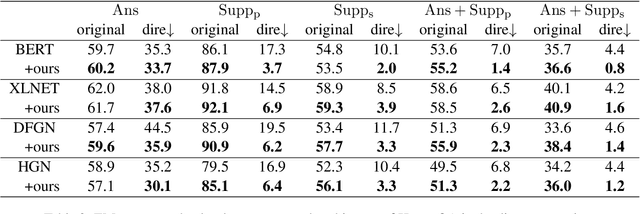
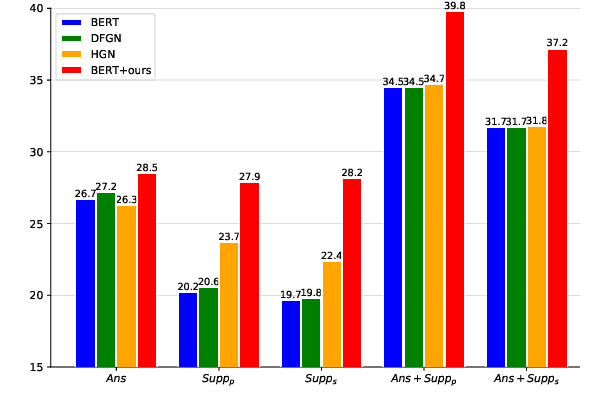
Multi-hop QA requires reasoning over multiple supporting facts to answer the question. However, the existing QA models always rely on shortcuts, e.g., providing the true answer by only one fact, rather than multi-hop reasoning, which is referred as $\textit{disconnected reasoning}$ problem. To alleviate this issue, we propose a novel counterfactual multihop QA, a causal-effect approach that enables to reduce the disconnected reasoning. It builds upon explicitly modeling of causality: 1) the direct causal effects of disconnected reasoning and 2) the causal effect of true multi-hop reasoning from the total causal effect. With the causal graph, a counterfactual inference is proposed to disentangle the disconnected reasoning from the total causal effect, which provides us a new perspective and technology to learn a QA model that exploits the true multi-hop reasoning instead of shortcuts. Extensive experiments have conducted on the benchmark HotpotQA dataset, which demonstrate that the proposed method can achieve notable improvement on reducing disconnected reasoning. For example, our method achieves 5.8% higher points of its Supp$_s$ score on HotpotQA through true multihop reasoning. The code is available at supplementary material.
ViT2Hash: Unsupervised Information-Preserving Hashing
Jan 14, 2022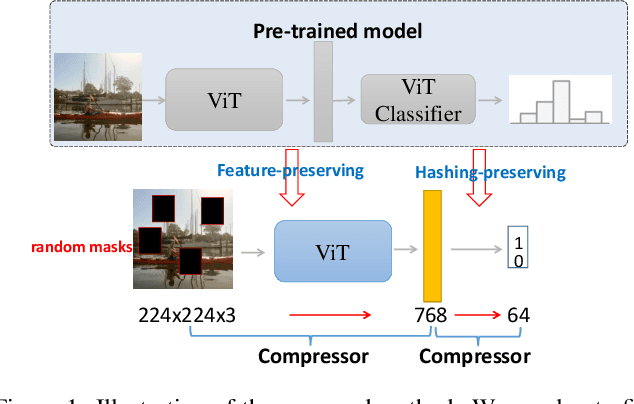
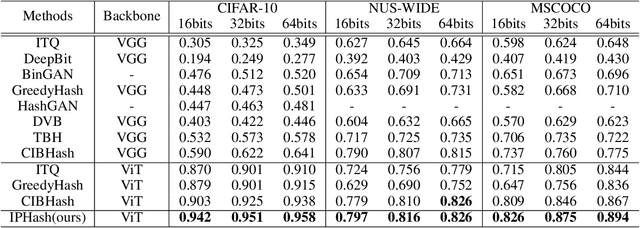
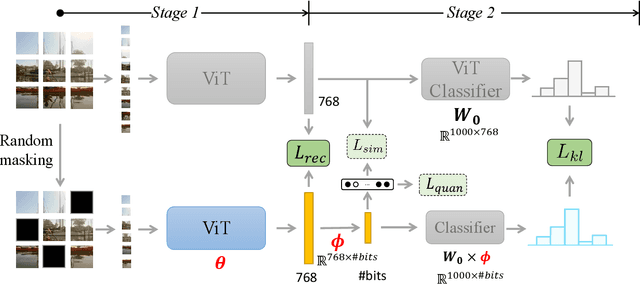
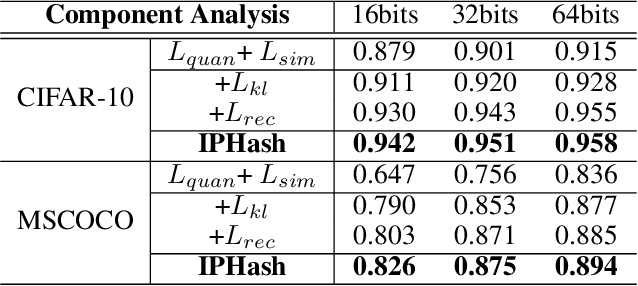
Unsupervised image hashing, which maps images into binary codes without supervision, is a compressor with a high compression rate. Hence, how to preserving meaningful information of the original data is a critical problem. Inspired by the large-scale vision pre-training model, known as ViT, which has shown significant progress for learning visual representations, in this paper, we propose a simple information-preserving compressor to finetune the ViT model for the target unsupervised hashing task. Specifically, from pixels to continuous features, we first propose a feature-preserving module, using the corrupted image as input to reconstruct the original feature from the pre-trained ViT model and the complete image, so that the feature extractor can focus on preserving the meaningful information of original data. Secondly, from continuous features to hash codes, we propose a hashing-preserving module, which aims to keep the semantic information from the pre-trained ViT model by using the proposed Kullback-Leibler divergence loss. Besides, the quantization loss and the similarity loss are added to minimize the quantization error. Our method is very simple and achieves a significantly higher degree of MAP on three benchmark image datasets.