 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Engineering flexible machine learning systems by traversing functionally invariant paths in weight space
May 09, 2022
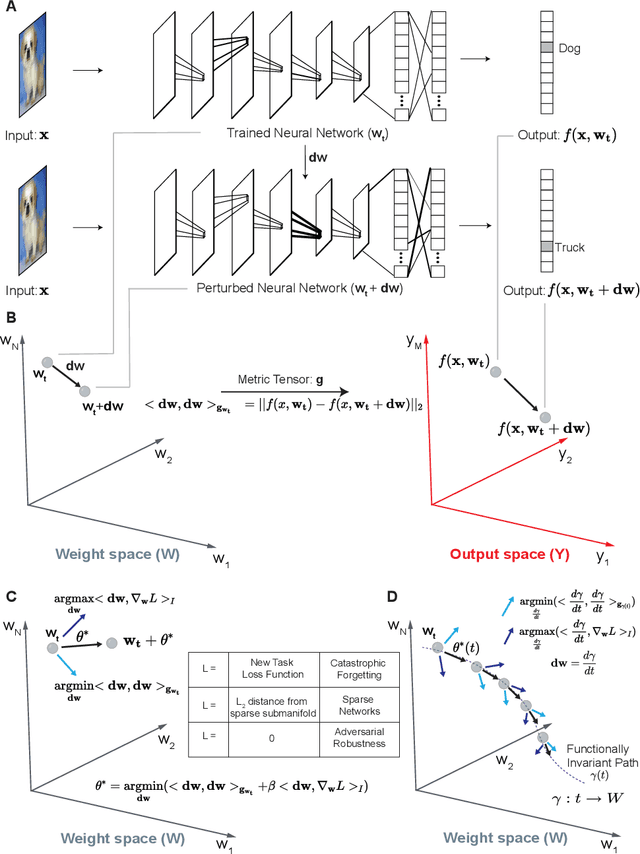
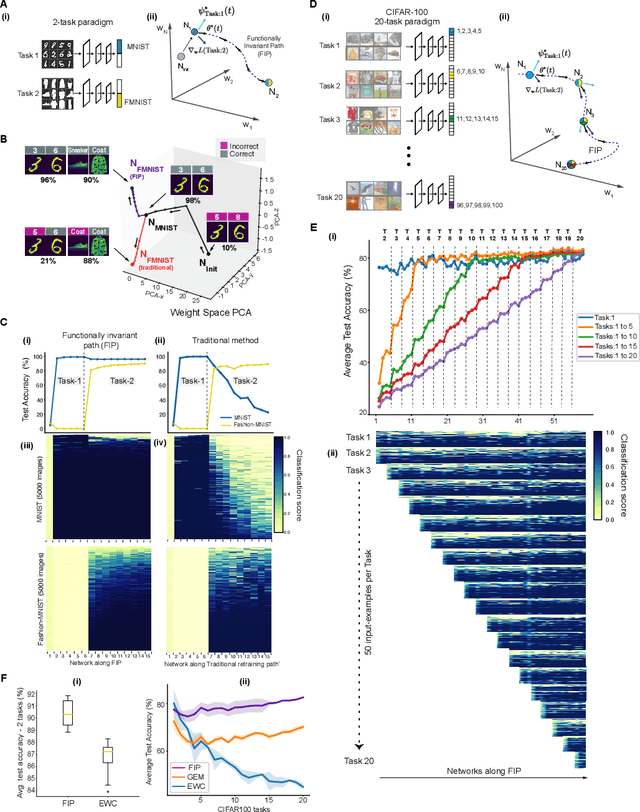
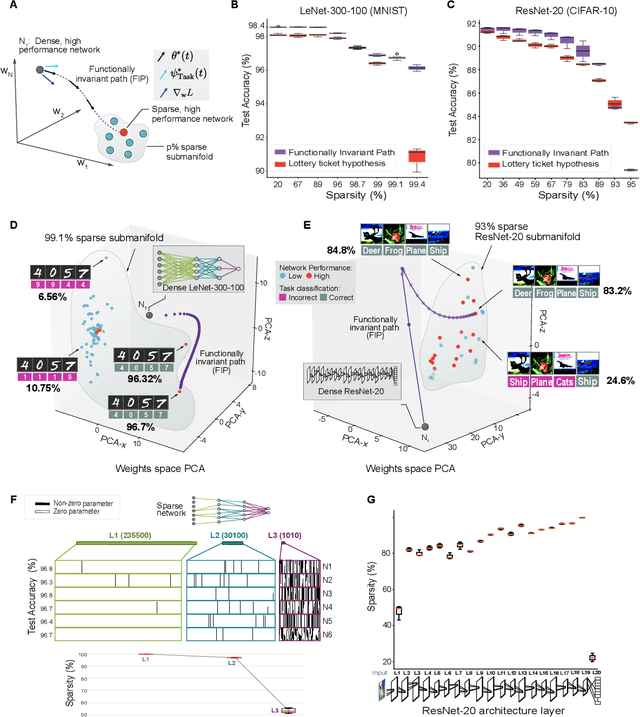
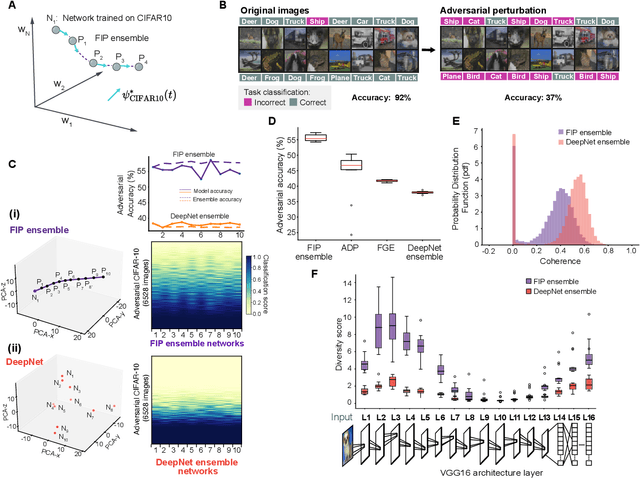
Deep neural networks achieve human-like performance on a variety of perceptual and decision making tasks. However, deep networks perform poorly when confronted with changing tasks or goals, and broadly fail to match the flexibility and robustness of human intelligence. Here, we develop a mathematical and algorithmic framework that enables continual training of deep neural networks on a broad range of objectives by defining path connected sets of neural networks that achieve equivalent functional performance on a given machine learning task while modulating network weights to achieve high-performance on a secondary objective. We view the weight space of a neural network as a curved Riemannian manifold and move a neural network along a functionally invariant path in weight space while searching for networks that satisfy a secondary objective. We introduce a path-sampling algorithm that trains networks with millions of weight parameters to learn a series of image classification tasks without performance loss. The algorithm generalizes to accommodate a range of secondary objectives including weight-pruning and weight diversification and exhibits state of the art performance on network compression and adversarial robustness benchmarks. Broadly, we demonstrate how the intrinsic geometry of machine learning problems can be harnessed to construct flexible and robust neural networks.
An empirical study of CTC based models for OCR of Indian languages
May 13, 2022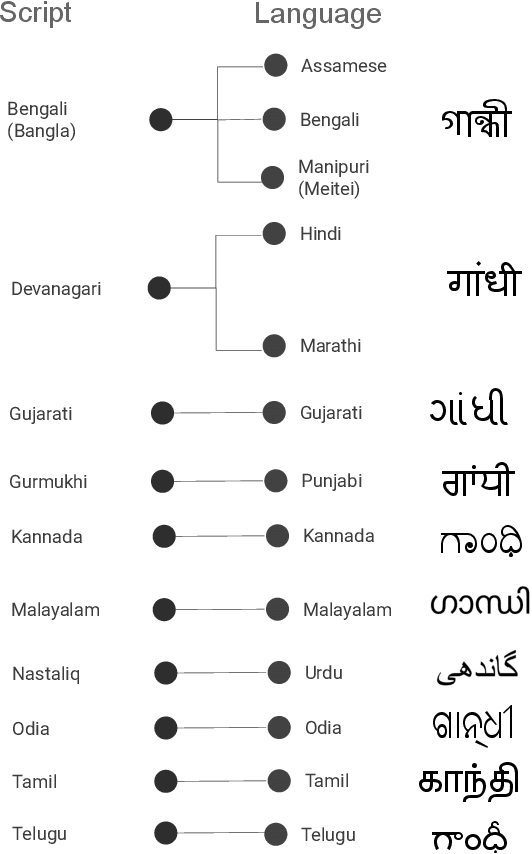
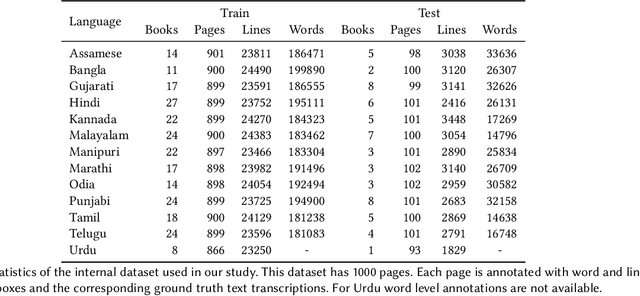
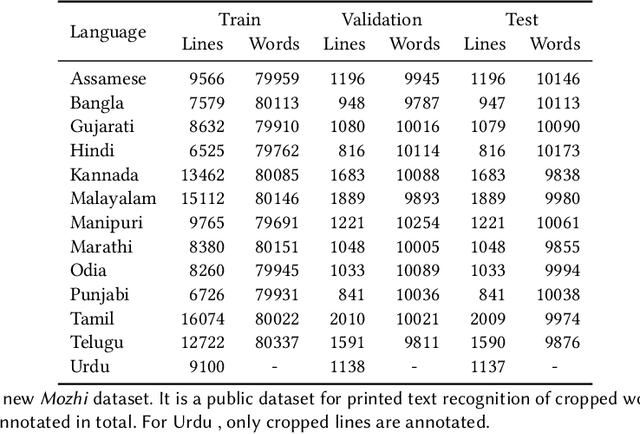

Recognition of text on word or line images, without the need for sub-word segmentation has become the mainstream of research and development of text recognition for Indian languages. Modelling unsegmented sequences using Connectionist Temporal Classification (CTC) is the most commonly used approach for segmentation-free OCR. In this work we present a comprehensive empirical study of various neural network models that uses CTC for transcribing step-wise predictions in the neural network output to a Unicode sequence. The study is conducted for 13 Indian languages, using an internal dataset that has around 1000 pages per language. We study the choice of line vs word as the recognition unit, and use of synthetic data to train the models. We compare our models with popular publicly available OCR tools for end-to-end document image recognition. Our end-to-end pipeline that employ our recognition models and existing text segmentation tools outperform these public OCR tools for 8 out of the 13 languages. We also introduce a new public dataset called Mozhi for word and line recognition in Indian language. The dataset contains more than 1.2 million annotated word images (120 thousand text lines) across 13 Indian languages. Our code, trained models and the Mozhi dataset will be made available at http://cvit.iiit.ac.in/research/projects/cvit-projects/
Exploring the Trade-off between Plausibility, Change Intensity and Adversarial Power in Counterfactual Explanations using Multi-objective Optimization
May 20, 2022
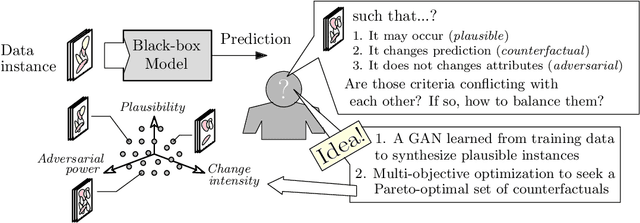
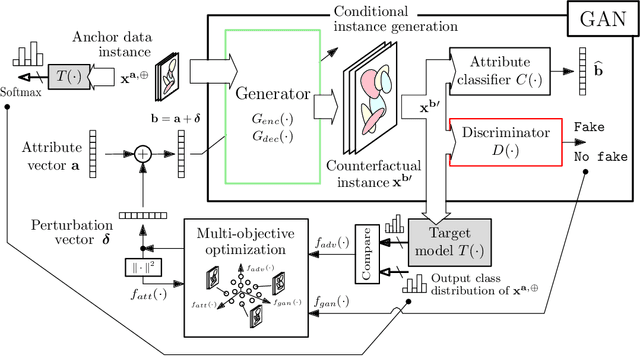
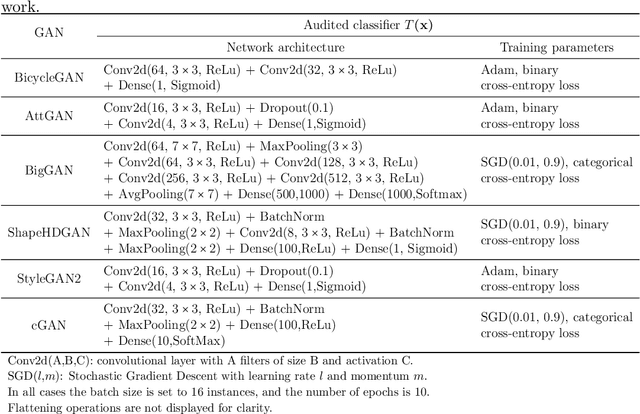
There is a broad consensus on the importance of deep learning models in tasks involving complex data. Often, an adequate understanding of these models is required when focusing on the transparency of decisions in human-critical applications. Besides other explainability techniques, trustworthiness can be achieved by using counterfactuals, like the way a human becomes familiar with an unknown process: by understanding the hypothetical circumstances under which the output changes. In this work we argue that automated counterfactual generation should regard several aspects of the produced adversarial instances, not only their adversarial capability. To this end, we present a novel framework for the generation of counterfactual examples which formulates its goal as a multi-objective optimization problem balancing three different objectives: 1) plausibility, i.e., the likeliness of the counterfactual of being possible as per the distribution of the input data; 2) intensity of the changes to the original input; and 3) adversarial power, namely, the variability of the model's output induced by the counterfactual. The framework departs from a target model to be audited and uses a Generative Adversarial Network to model the distribution of input data, together with a multi-objective solver for the discovery of counterfactuals balancing among these objectives. The utility of the framework is showcased over six classification tasks comprising image and three-dimensional data. The experiments verify that the framework unveils counterfactuals that comply with intuition, increasing the trustworthiness of the user, and leading to further insights, such as the detection of bias and data misrepresentation.
GeoSim: Photorealistic Image Simulation with Geometry-Aware Composition
Jan 16, 2021
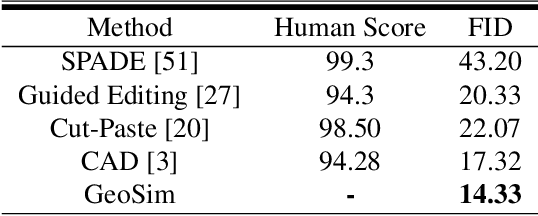
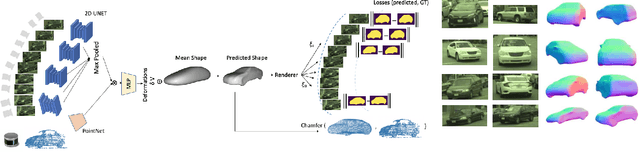

Scalable sensor simulation is an important yet challenging open problem for safety-critical domains such as self-driving. Current work in image simulation either fail to be photorealistic or do not model the 3D environment and the dynamic objects within, losing high-level control and physical realism. In this paper, we present GeoSim, a geometry-aware image composition process that synthesizes novel urban driving scenes by augmenting existing images with dynamic objects extracted from other scenes and rendered at novel poses. Towards this goal, we first build a diverse bank of 3D objects with both realistic geometry and appearance from sensor data. During simulation, we perform a novel geometry-aware simulation-by-composition procedure which 1) proposes plausible and realistic object placements into a given scene, 2) renders novel views of dynamic objects from the asset bank, and 3) composes and blends the rendered image segments. The resulting synthetic images are photorealistic, traffic-aware, and geometrically consistent, allowing image simulation to scale to complex use cases. We demonstrate two such important applications: long-range realistic video simulation across multiple camera sensors, and synthetic data generation for data augmentation on downstream segmentation tasks.
Towards the Generation of Synthetic Images of Palm Vein Patterns: A Review
May 20, 2022



With the recent success of computer vision and deep learning, remarkable progress has been achieved on automatic personal recognition using vein biometrics. However, collecting large-scale real-world training data for palm vein recognition has turned out to be challenging, mainly due to the noise and irregular variations included at the time of acquisition. Meanwhile, existing palm vein recognition datasets are usually collected under near-infrared light, lacking detailed annotations on attributes (e.g., pose), so the influences of different attributes on vein recognition have been poorly investigated. Therefore, this paper examines the suitability of synthetic vein images generated to compensate for the urgent lack of publicly available large-scale datasets. Firstly, we present an overview of recent research progress on palm vein recognition, from the basic background knowledge to vein anatomical structure, data acquisition, public database, and quality assessment procedures. Then, we focus on the state-of-the-art methods that have allowed the generation of vascular structures for biometric purposes and the modeling of biological networks with their respective application domains. In addition, we review the existing research on the generation of style transfer and biological nature-based synthetic palm vein image algorithms. Afterward, we formalize a general flowchart for the creation of a synthetic database comparing real palm vein images and generated synthetic samples to obtain some understanding into the development of the realistic vein imaging system. Ultimately, we conclude by discussing the challenges, insights, and future perspectives in generating synthetic palm vein images for further works.
A Location-Sensitive Local Prototype Network for Few-Shot Medical Image Segmentation
Mar 18, 2021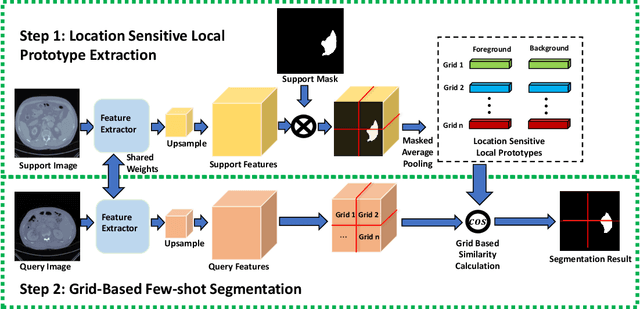
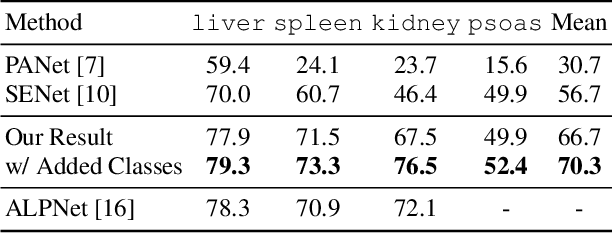
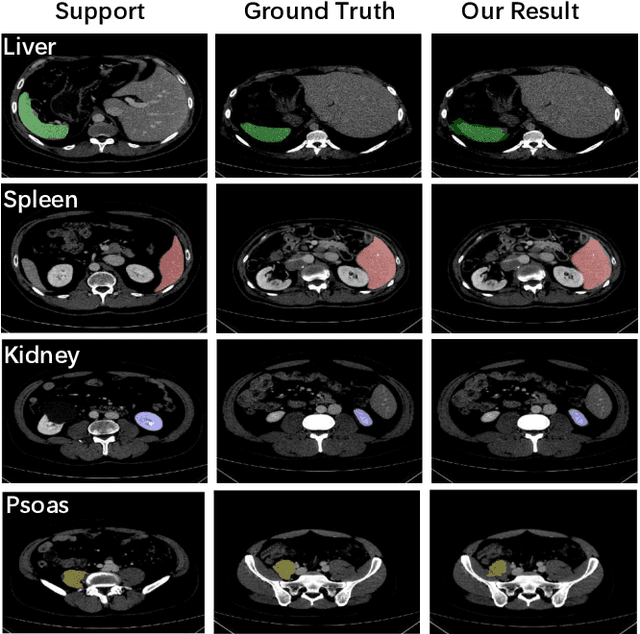
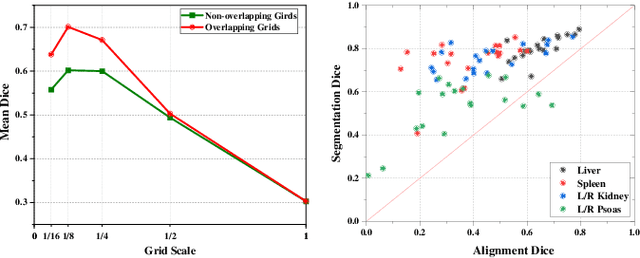
Despite the tremendous success of deep neural networks in medical image segmentation, they typically require a large amount of costly, expert-level annotated data. Few-shot segmentation approaches address this issue by learning to transfer knowledge from limited quantities of labeled examples. Incorporating appropriate prior knowledge is critical in designing high-performance few-shot segmentation algorithms. Since strong spatial priors exist in many medical imaging modalities, we propose a prototype-based method -- namely, the location-sensitive local prototype network -- that leverages spatial priors to perform few-shot medical image segmentation. Our approach divides the difficult problem of segmenting the entire image with global prototypes into easily solvable subproblems of local region segmentation with local prototypes. For organ segmentation experiments on the VISCERAL CT image dataset, our method outperforms the state-of-the-art approaches by 10% in the mean Dice coefficient. Extensive ablation studies demonstrate the substantial benefits of incorporating spatial information and confirm the effectiveness of our approach.
Unpaired Single-Image Depth Synthesis with cycle-consistent Wasserstein GANs
Mar 31, 2021
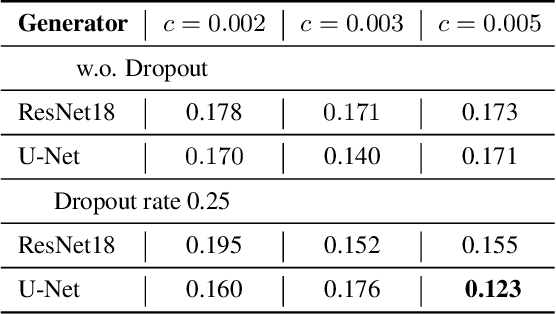
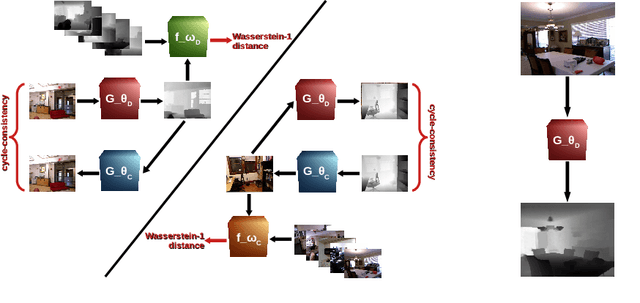
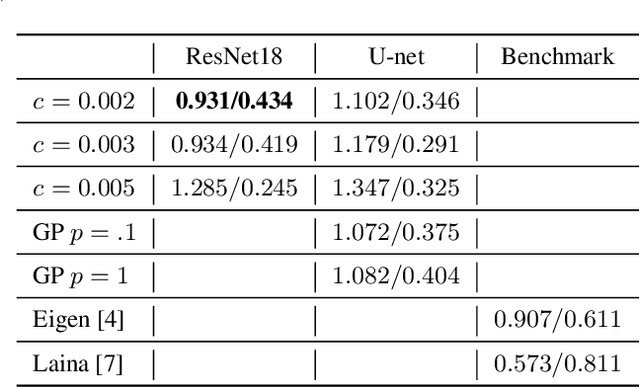
Real-time estimation of actual environment depth is an essential module for various autonomous system tasks such as localization, obstacle detection and pose estimation. During the last decade of machine learning, extensive deployment of deep learning methods to computer vision tasks yielded successful approaches for realistic depth synthesis out of a simple RGB modality. While most of these models rest on paired depth data or availability of video sequences and stereo images, there is a lack of methods facing single-image depth synthesis in an unsupervised manner. Therefore, in this study, latest advancements in the field of generative neural networks are leveraged to fully unsupervised single-image depth synthesis. To be more exact, two cycle-consistent generators for RGB-to-depth and depth-to-RGB transfer are implemented and simultaneously optimized using the Wasserstein-1 distance. To ensure plausibility of the proposed method, we apply the models to a self acquised industrial data set as well as to the renown NYU Depth v2 data set, which allows comparison with existing approaches. The observed success in this study suggests high potential for unpaired single-image depth estimation in real world applications.
When Image Decomposition Meets Deep Learning: A Novel Infrared and Visible Image Fusion Method
Sep 02, 2020


Infrared and visible image fusion, as a hot topic in image processing and image enhancement, aims to produce fused images retaining the detail texture information in visible images and the thermal radiation information in infrared images. In this paper, we propose a novel two-stream auto-encoder (AE) based fusion network. The core idea is that the encoder decomposes an image into base and detail feature maps with low- and high-frequency information, respectively, and that the decoder is responsible for the original image reconstruction. To this end, a well-designed loss function is established to make the base/detail feature maps similar/dissimilar. In the test phase, base and detail feature maps are respectively merged via a fusion module, and the fused image is recovered by the decoder. Qualitative and quantitative results demonstrate that our method can generate fusion images containing highlighted targets and abundant detail texture information with strong reproducibility and meanwhile superior than the state-of-the-art (SOTA) approaches.
FAST-LIVO: Fast and Tightly-coupled Sparse-Direct LiDAR-Inertial-Visual Odometry
Mar 02, 2022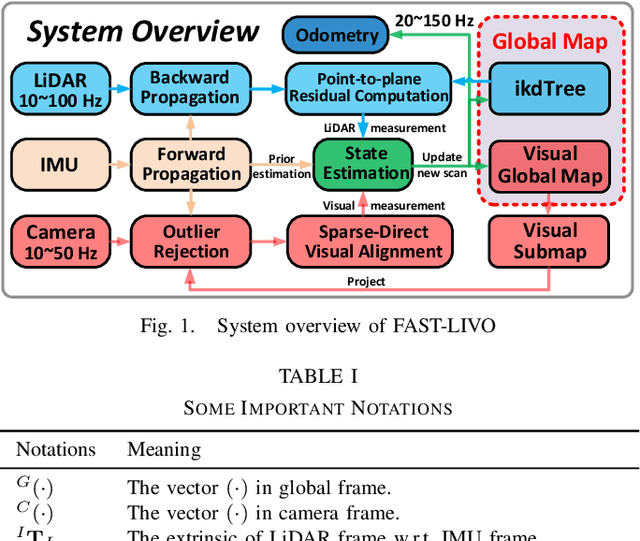
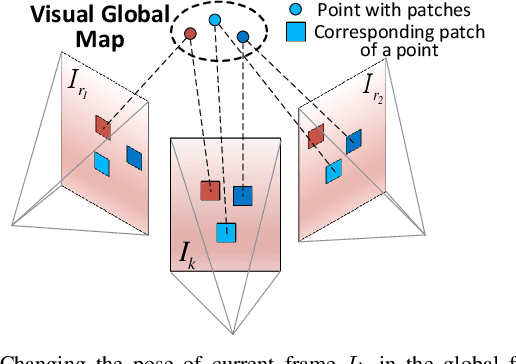
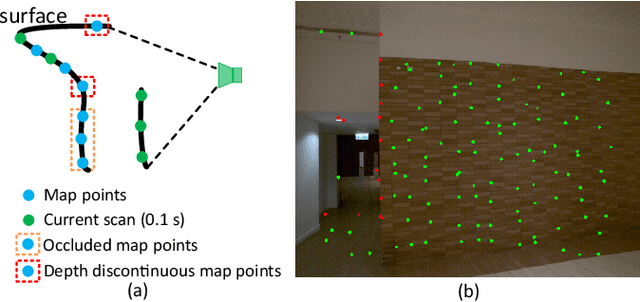
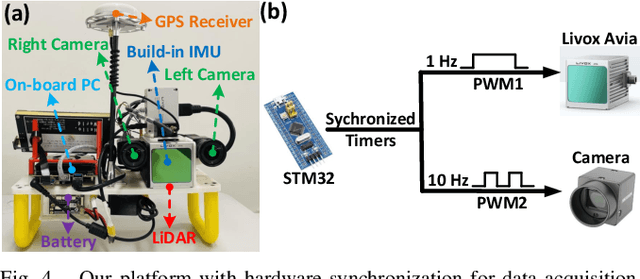
To achieve accurate and robust pose estimation in Simultaneous Localization and Mapping (SLAM) task, multi-sensor fusion is proven to be an effective solution and thus provides great potential in robotic applications. This paper proposes FAST-LIVO, a fast LiDAR-Inertial-Visual Odometry system, which builds on two tightly-coupled and direct odometry subsystems: a VIO subsystem and a LIO subsystem. The LIO subsystem registers raw points (instead of feature points on e.g., edges or planes) of a new scan to an incrementally-built point cloud map. The map points are additionally attached with image patches, which are then used in the VIO subsystem to align a new image by minimizing the direct photometric errors without extracting any visual features (e.g., ORB or FAST corner features). To further improve the VIO robustness and accuracy, a novel outlier rejection method is proposed to reject unstable map points that lie on edges or are occluded in the image view. Experiments on both open data sequences and our customized device data are conducted. The results show our proposed system outperforms other counterparts and can handle challenging environments at reduced computation cost. The system supports both multi-line spinning LiDARs and emerging solid-state LiDARs with completely different scanning patterns, and can run in real-time on both Intel and ARM processors. We open source our code and dataset of this work on Github to benefit the robotics community.
Wukong: 100 Million Large-scale Chinese Cross-modal Pre-training Dataset and A Foundation Framework
Feb 14, 2022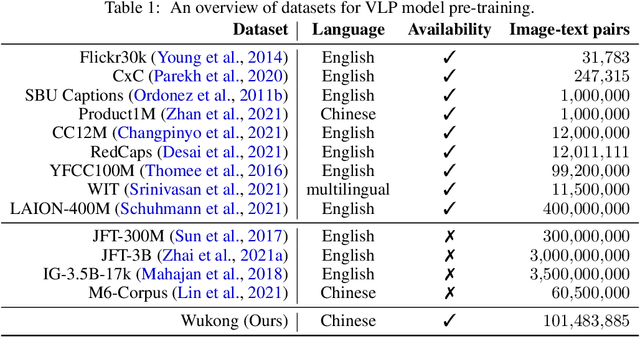
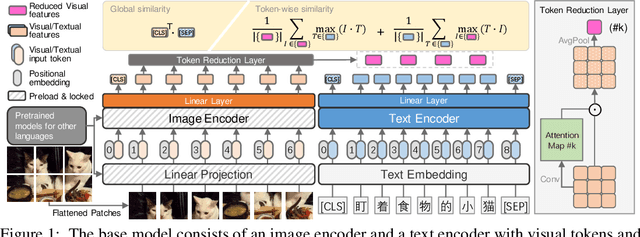


This paper presents a large-scale Chinese cross-modal dataset for benchmarking different multi-modal pre-training methods to facilitate the Vision-Language Pre-training (VLP) research and community development. Recent dual-stream VLP models like CLIP, ALIGN and FILIP have shown remarkable performance on various downstream tasks as well as their remarkable zero-shot ability in the open domain tasks. However, their success heavily relies on the scale of pre-trained datasets. Though there have been both small-scale vision-language English datasets like Flickr30k, CC12M as well as large-scale LAION-400M, the current community lacks large-scale Vision-Language benchmarks in Chinese, hindering the development of broader multilingual applications. On the other hand, there is very rare publicly available large-scale Chinese cross-modal pre-training dataset that has been released, making it hard to use pre-trained models as services for downstream tasks. In this work, we release a Large-Scale Chinese Cross-modal dataset named Wukong, containing 100 million Chinese image-text pairs from the web. Furthermore, we release a group of big models pre-trained with advanced image encoders (ResNet/ViT/SwinT) and different pre-training methods (CLIP/FILIP/LiT). We provide extensive experiments, a deep benchmarking of different downstream tasks, and some exciting findings. Experiments show that Wukong can serve as a promising Chinese pre-training dataset and benchmark for different cross-modal learning methods, which gives superior performance on various downstream tasks such as zero-shot image classification and image-text retrieval benchmarks. More information can refer to https://wukong-dataset.github.io/wukong-dataset/.