 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Novel Face-Anti Spoofing Neural Network Model For Face Recognition And Detection
May 14, 2022
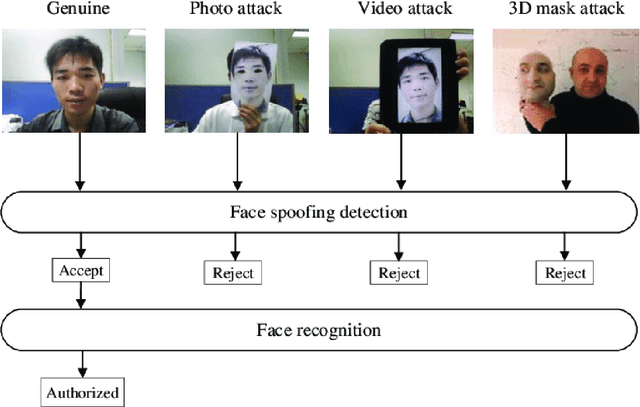


Face Recognition (FR) systems are being used in a variety of applications, including road crossings, banking, and mobile banking. The widespread use of FR systems has raised concerns about the safety of face biometrics against spoofing attacks, which use the use of a photo or video of a legitimate user's face to gain illegal access to the resources or activities. Despite the development of several FAS or liveness detection methods (which determine whether a face is live or spoofed at the time of acquisition), the problem remains unsolved due to the difficulty of identifying discrimination and operationally reasonably priced spoof characteristics but also approaches. Additionally, certain facial portions are frequently repeated or correlate to image clutter, resulting in poor performance overall. This research proposes a face-anti-spoofing neural network model that outperforms existing models and has an efficiency of 0.89 percent.
Test-Time Adaptation for Out-of-distributed Image Inpainting
Feb 02, 2021
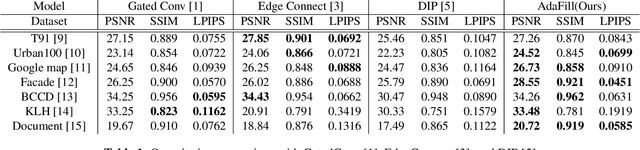
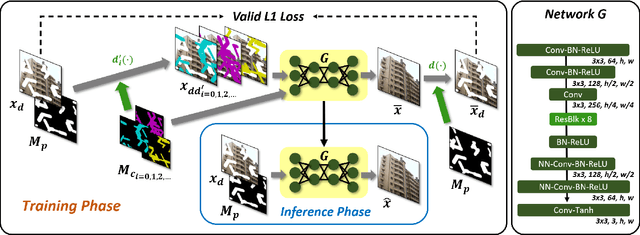
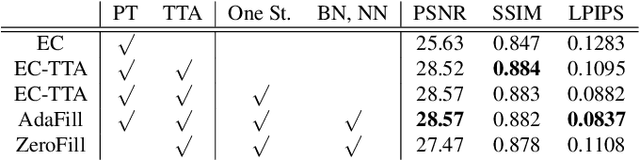
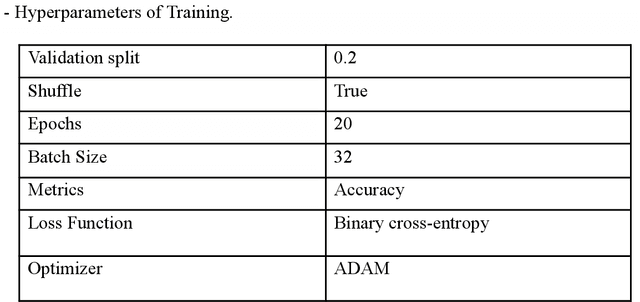
Deep learning-based image inpainting algorithms have shown great performance via powerful learned prior from the numerous external natural images. However, they show unpleasant results on the test image whose distribution is far from the that of training images because their models are biased toward the training images. In this paper, we propose a simple image inpainting algorithm with test-time adaptation named AdaFill. Given a single out-of-distributed test image, our goal is to complete hole region more naturally than the pre-trained inpainting models. To achieve this goal, we treat remained valid regions of the test image as another training cues because natural images have strong internal similarities. From this test-time adaptation, our network can exploit externally learned image priors from the pre-trained features as well as the internal prior of the test image explicitly. Experimental results show that AdaFill outperforms other models on the various out-of-distribution test images. Furthermore, the model named ZeroFill, that are not pre-trained also sometimes outperforms the pre-trained models.
Vision Xformers: Efficient Attention for Image Classification
Jul 05, 2021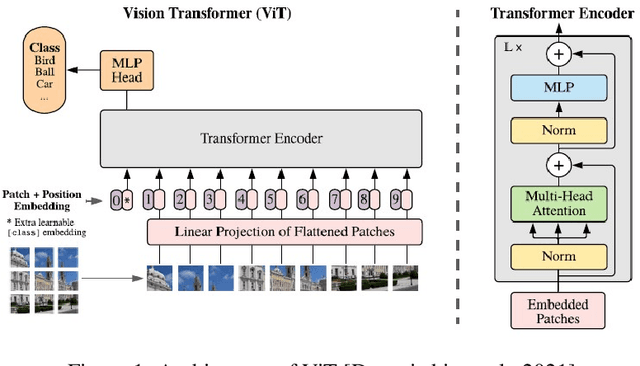

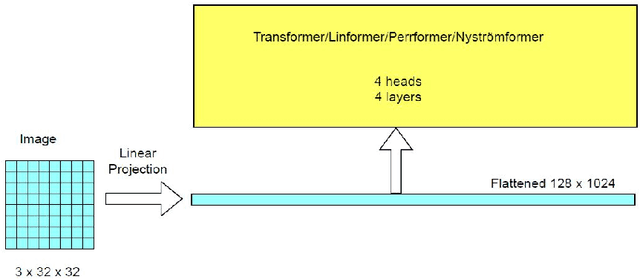

Linear attention mechanisms provide hope for overcoming the bottleneck of quadratic complexity which restricts application of transformer models in vision tasks. We modify the ViT architecture to work on longer sequence data by replacing the quadratic attention with efficient transformers like Performer, Linformer and Nystr\"omformer of linear complexity creating Vision X-formers (ViX). We show that ViX performs better than ViT in image classification consuming lesser computing resources. We further show that replacing the embedding linear layer by convolutional layers in ViX further increases their performance. Our test on recent visions transformer models like LeViT and Compact Convolutional Transformer (CCT) show that replacing the attention with Nystr\"omformer or Performer saves GPU usage and memory without deteriorating performance. Incorporating these changes can democratize transformers by making them accessible to those with limited data and computing resources.
Deep Learning-based automated classification of Chinese Speech Sound Disorders
May 24, 2022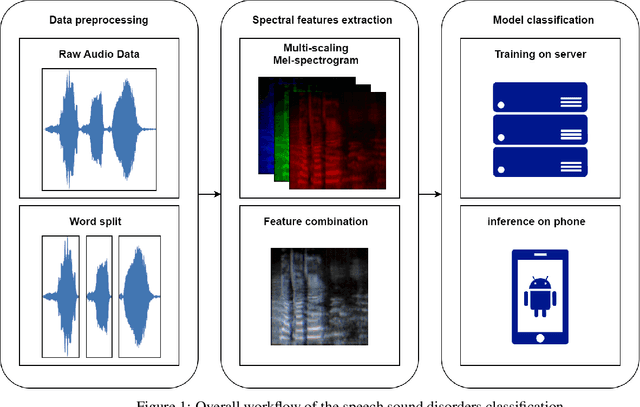

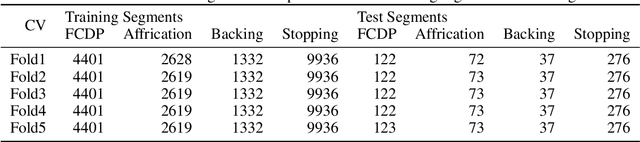
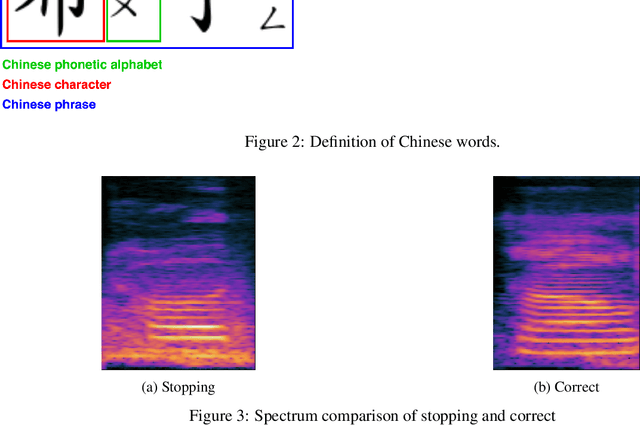
This article describes a system for analyzing acoustic data in order to assist in the diagnosis and classification of children's speech disorders using a computer. The analysis concentrated on identifying and categorizing four distinct types of Chinese misconstructions. The study collected and generated a speech corpus containing 2540 Stopping, Velar, Consonant-vowel, and Affricate samples from 90 children aged 3-6 years with normal or pathological articulatory features. Each recording was accompanied by a detailed annotation from the field of speech therapy. Classification of the speech samples was accomplished using three well-established neural network models for image classification. The feature maps are created using three sets of MFCC parameters extracted from speech sounds and aggregated into a three-dimensional data structure as model input. We employ six techniques for data augmentation in order to augment the available dataset while avoiding over-simulation. The experiments examine the usability of four different categories of Chinese phrases and characters. Experiments with different data subsets demonstrate the system's ability to accurately detect the analyzed pronunciation disorders.
A Mixed Quantization Network for Computationally Efficient Mobile Inverse Tone Mapping
Mar 12, 2022
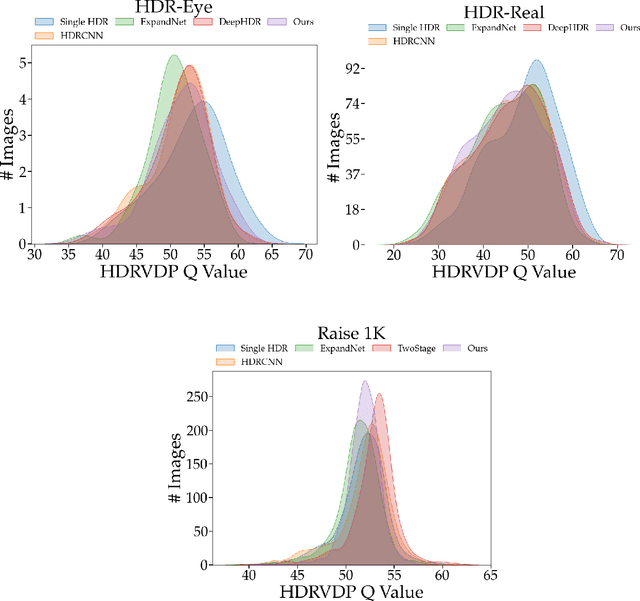
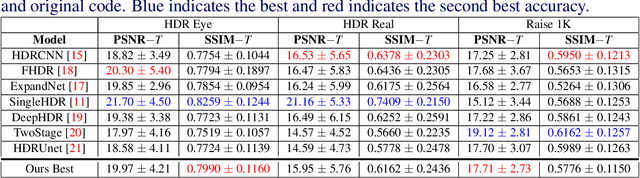
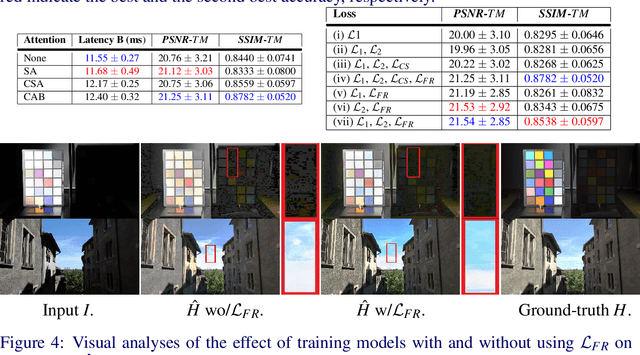
Recovering a high dynamic range (HDR) image from a single low dynamic range (LDR) image, namely inverse tone mapping (ITM), is challenging due to the lack of information in over- and under-exposed regions. Current methods focus exclusively on training high-performing but computationally inefficient ITM models, which in turn hinder deployment of the ITM models in resource-constrained environments with limited computing power such as edge and mobile device applications. To this end, we propose combining efficient operations of deep neural networks with a novel mixed quantization scheme to construct a well-performing but computationally efficient mixed quantization network (MQN) which can perform single image ITM on mobile platforms. In the ablation studies, we explore the effect of using different attention mechanisms, quantization schemes, and loss functions on the performance of MQN in ITM tasks. In the comparative analyses, ITM models trained using MQN perform on par with the state-of-the-art methods on benchmark datasets. MQN models provide up to 10 times improvement on latency and 25 times improvement on memory consumption.
Towards Accurate Text-based Image Captioning with Content Diversity Exploration
Apr 23, 2021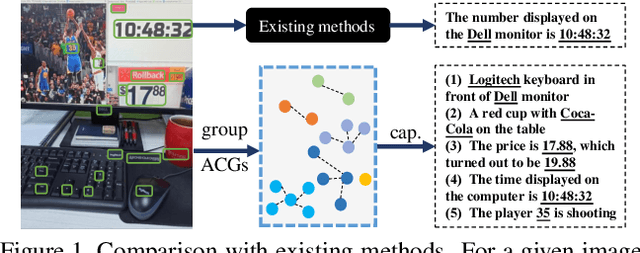
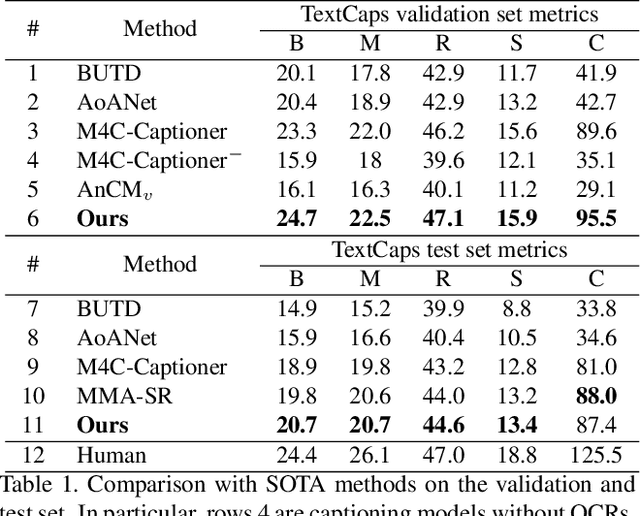
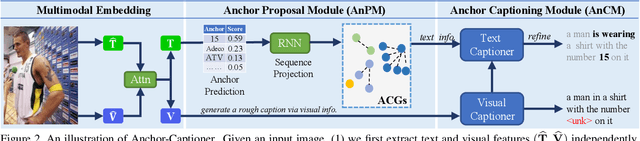
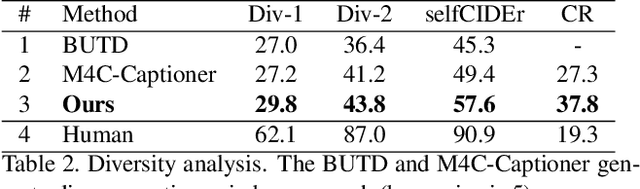
Text-based image captioning (TextCap) which aims to read and reason images with texts is crucial for a machine to understand a detailed and complex scene environment, considering that texts are omnipresent in daily life. This task, however, is very challenging because an image often contains complex texts and visual information that is hard to be described comprehensively. Existing methods attempt to extend the traditional image captioning methods to solve this task, which focus on describing the overall scene of images by one global caption. This is infeasible because the complex text and visual information cannot be described well within one caption. To resolve this difficulty, we seek to generate multiple captions that accurately describe different parts of an image in detail. To achieve this purpose, there are three key challenges: 1) it is hard to decide which parts of the texts of images to copy or paraphrase; 2) it is non-trivial to capture the complex relationship between diverse texts in an image; 3) how to generate multiple captions with diverse content is still an open problem. To conquer these, we propose a novel Anchor-Captioner method. Specifically, we first find the important tokens which are supposed to be paid more attention to and consider them as anchors. Then, for each chosen anchor, we group its relevant texts to construct the corresponding anchor-centred graph (ACG). Last, based on different ACGs, we conduct multi-view caption generation to improve the content diversity of generated captions. Experimental results show that our method not only achieves SOTA performance but also generates diverse captions to describe images.
Accurate 3D Body Shape Regression using Metric and Semantic Attributes
Jun 14, 2022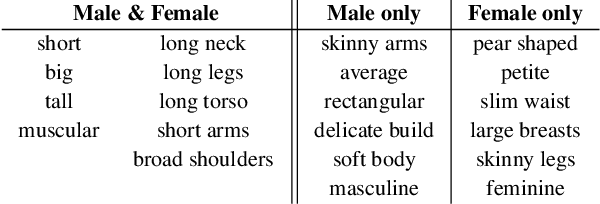

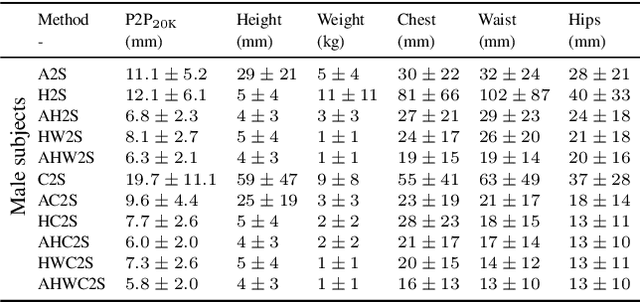
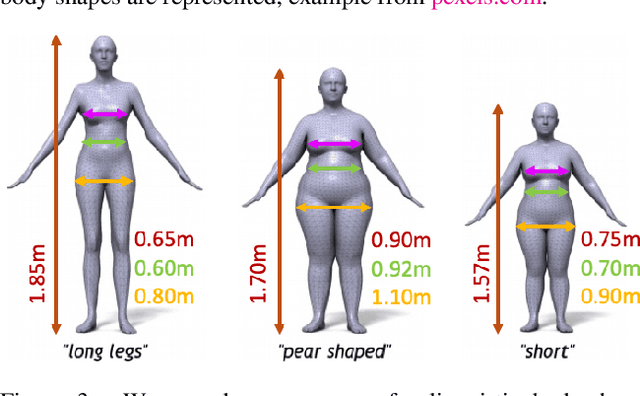
While methods that regress 3D human meshes from images have progressed rapidly, the estimated body shapes often do not capture the true human shape. This is problematic since, for many applications, accurate body shape is as important as pose. The key reason that body shape accuracy lags pose accuracy is the lack of data. While humans can label 2D joints, and these constrain 3D pose, it is not so easy to "label" 3D body shape. Since paired data with images and 3D body shape are rare, we exploit two sources of information: (1) we collect internet images of diverse "fashion" models together with a small set of anthropometric measurements; (2) we collect linguistic shape attributes for a wide range of 3D body meshes and the model images. Taken together, these datasets provide sufficient constraints to infer dense 3D shape. We exploit the anthropometric measurements and linguistic shape attributes in several novel ways to train a neural network, called SHAPY, that regresses 3D human pose and shape from an RGB image. We evaluate SHAPY on public benchmarks, but note that they either lack significant body shape variation, ground-truth shape, or clothing variation. Thus, we collect a new dataset for evaluating 3D human shape estimation, called HBW, containing photos of "Human Bodies in the Wild" for which we have ground-truth 3D body scans. On this new benchmark, SHAPY significantly outperforms state-of-the-art methods on the task of 3D body shape estimation. This is the first demonstration that 3D body shape regression from images can be trained from easy-to-obtain anthropometric measurements and linguistic shape attributes. Our model and data are available at: shapy.is.tue.mpg.de
* First two authors contributed equally
Deep Image Compositing
Nov 04, 2020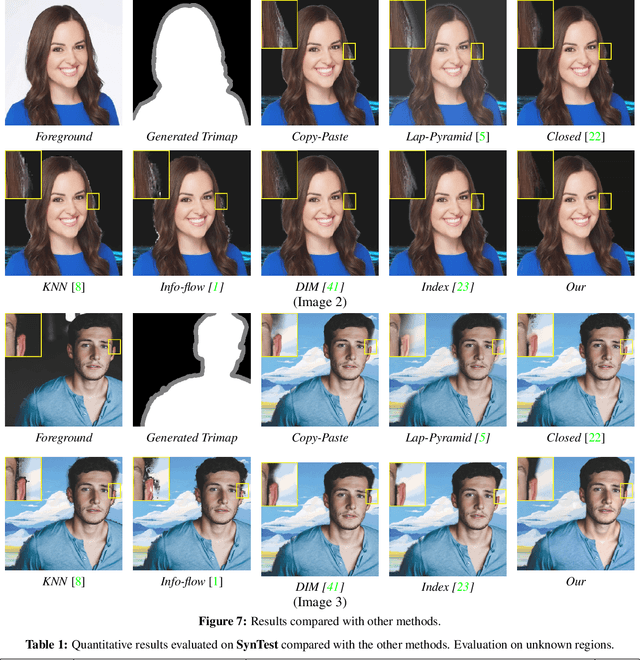

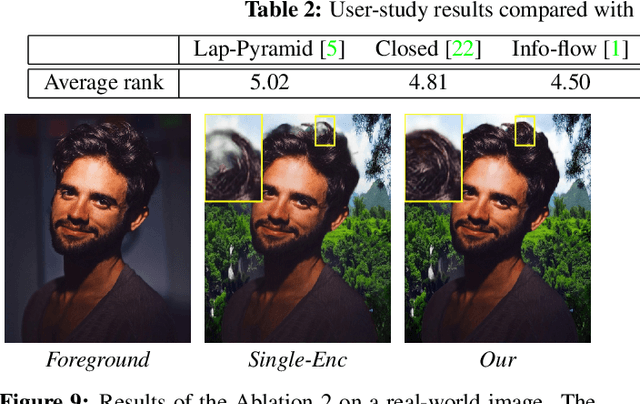
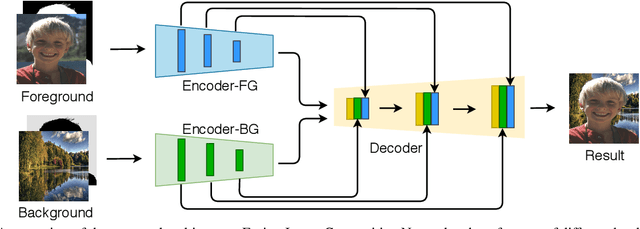
Image compositing is a task of combining regions from different images to compose a new image. A common use case is background replacement of portrait images. To obtain high quality composites, professionals typically manually perform multiple editing steps such as segmentation, matting and foreground color decontamination, which is very time consuming even with sophisticated photo editing tools. In this paper, we propose a new method which can automatically generate high-quality image compositing without any user input. Our method can be trained end-to-end to optimize exploitation of contextual and color information of both foreground and background images, where the compositing quality is considered in the optimization. Specifically, inspired by Laplacian pyramid blending, a dense-connected multi-stream fusion network is proposed to effectively fuse the information from the foreground and background images at different scales. In addition, we introduce a self-taught strategy to progressively train from easy to complex cases to mitigate the lack of training data. Experiments show that the proposed method can automatically generate high-quality composites and outperforms existing methods both qualitatively and quantitatively.
MonoDETR: Depth-aware Transformer for Monocular 3D Object Detection
Mar 28, 2022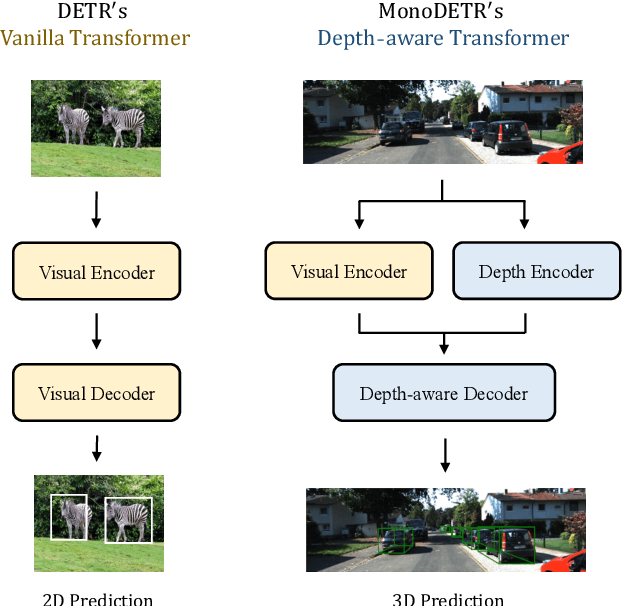
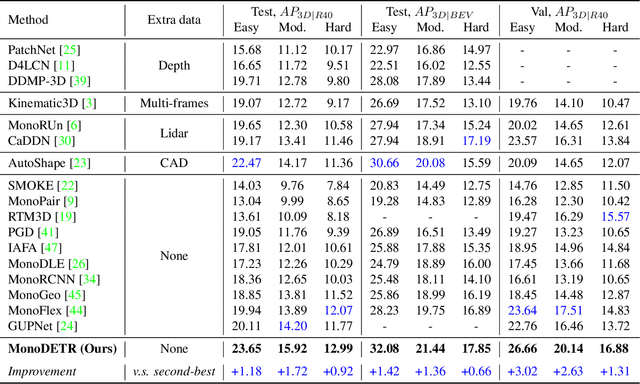

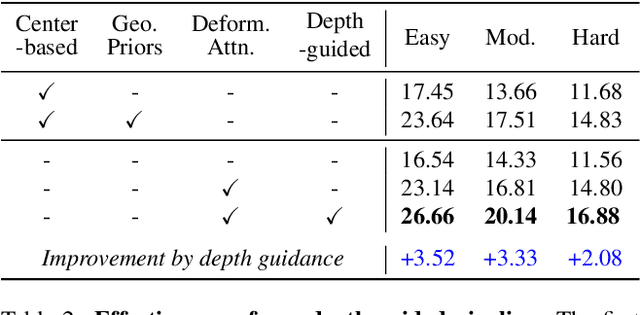
Monocular 3D object detection has long been a challenging task in autonomous driving, which requires to decode 3D predictions solely from a single 2D image. Most existing methods follow conventional 2D object detectors to first localize objects by their centers, and then predict 3D attributes using center-neighboring local features. However, such center-based pipeline views 3D prediction as a subordinate task and lacks inter-object depth interactions with global spatial clues. In this paper, we introduce a simple framework for Monocular DEtection with depth-aware TRansformer, named MonoDETR. We enable the vanilla transformer to be depth-aware and enforce the whole detection process guided by depth. Specifically, we represent 3D object candidates as a set of queries and produce non-local depth embeddings of the input image by a lightweight depth predictor and an attention-based depth encoder. Then, we propose a depth-aware decoder to conduct both inter-query and query-scene depth feature communication. In this way, each object estimates its 3D attributes adaptively from the depth-informative regions on the image, not limited by center-around features. With minimal handcrafted designs, MonoDETR is an end-to-end framework without additional data, anchors or NMS and achieves competitive performance on KITTI benchmark among state-of-the-art center-based networks. Extensive ablation studies demonstrate the effectiveness of our approach and its potential to serve as a transformer baseline for future monocular research. Code is available at https://github.com/ZrrSkywalker/MonoDETR.git.
Real-time FPGA Design for OMP Targeting 8K Image Reconstruction
Oct 10, 2021
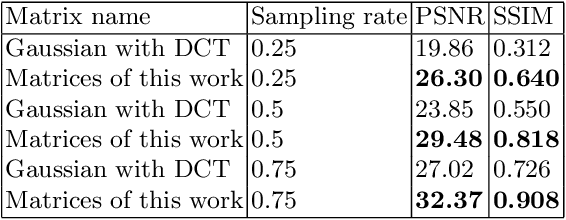

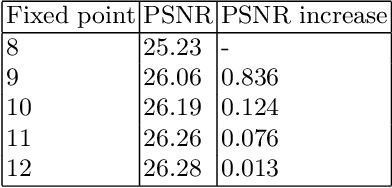
During the past decade, implementing reconstruction algorithms on hardware has been at the center of much attention in the field of real-time reconstruction in Compressed Sensing (CS). Orthogonal Matching Pursuit (OMP) is the most widely used reconstruction algorithm on hardware implementation because OMP obtains good quality reconstruction results under a proper time cost. OMP includes Dot Product (DP) and Least Square Problem (LSP). These two parts have numerous division calculations and considerable vector-based multiplications, which limit the implementation of real-time reconstruction on hardware. In the theory of CS, besides the reconstruction algorithm, the choice of sensing matrix affects the quality of reconstruction. It also influences the reconstruction efficiency by affecting the hardware architecture. Thus, designing a real-time hardware architecture of OMP needs to take three factors into consideration. The choice of sensing matrix, the implementation of DP and LSP. In this paper, a sensing matrix, which is sparsity and contains zero vectors mainly, is adopted to optimize the OMP reconstruction to break the bottleneck of reconstruction efficiency. Based on the features of the chosen matrix, the DP and LSP are implemented by simple shift, add and comparing procedures. This work is implemented on the Xilinx Virtex UltraScale+ FPGA device. To reconstruct a digital signal with 1024 length under 0.25 sampling rate, the proposal method costs 0.818us while the state-of-the-art costs 238$us. Thus, this work speedups the state-of-the-art method 290 times. This work costs 0.026s to reconstruct an 8K gray image, which achieves 30FPS real-time reconstruction.