 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Xformers: Efficient Attention for Image Classification
Paper and Code
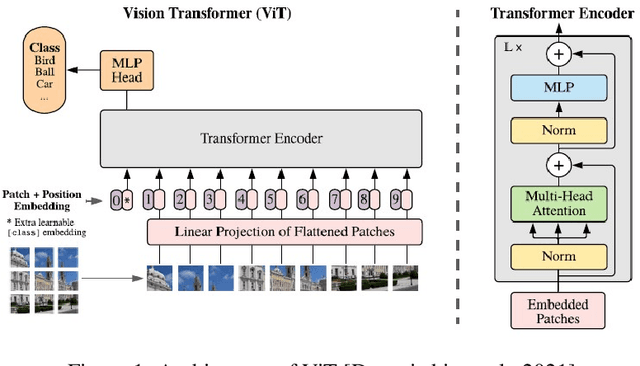

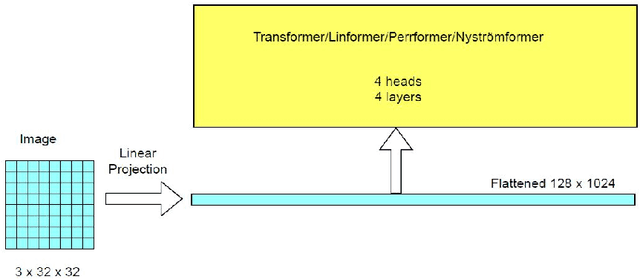

We propose three improvements to vision transformers (ViT) to reduce the number of trainable parameters without compromising classification accuracy. We address two shortcomings of the early ViT architectures -- quadratic bottleneck of the attention mechanism and the lack of an inductive bias in their architectures that rely on unrolling the two-dimensional image structure. Linear attention mechanisms overcome the bottleneck of quadratic complexity, which restricts application of transformer models in vision tasks. We modify the ViT architecture to work on longer sequence data by replacing the quadratic attention with efficient transformers, such as Performer, Linformer and Nystr\"omformer of linear complexity creating Vision X-formers (ViX). We show that all three versions of ViX may be more accurate than ViT for image classification while using far fewer parameters and computational resources. We also compare their performance with FNet and multi-layer perceptron (MLP) mixer. We further show that replacing the initial linear embedding layer by convolutional layers in ViX further increases their performance. Furthermore, our tests on recent vision transformer models, such as LeViT, Convolutional vision Transformer (CvT), Compact Convolutional Transformer (CCT) and Pooling-based Vision Transformer (PiT) show that replacing the attention with Nystr\"omformer or Performer saves GPU usage and memory without deteriorating the classification accuracy. We also show that replacing the standard learnable 1D position embeddings in ViT with Rotary Position Embedding (RoPE) give further improvements in accuracy. Incorporating these changes can democratize transformers by making them accessible to those with limited data and computing resources.