 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-based automated classification of Chinese Speech Sound Disorders
May 24, 2022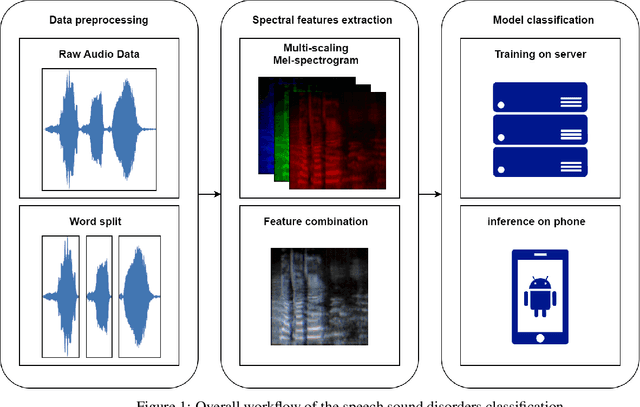

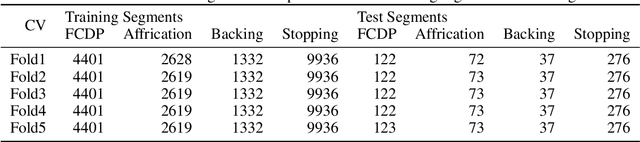
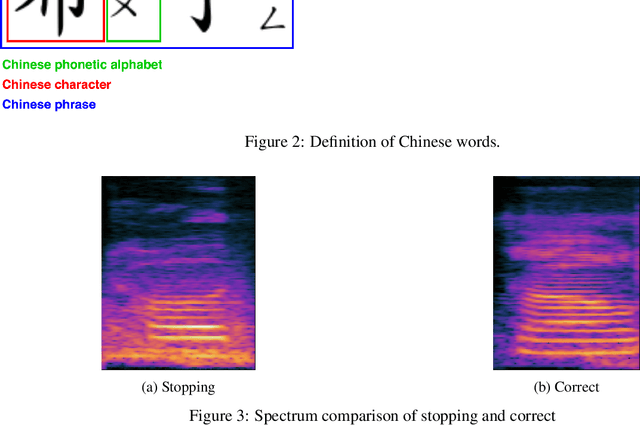
This article describes a system for analyzing acoustic data in order to assist in the diagnosis and classification of children's speech disorders using a computer. The analysis concentrated on identifying and categorizing four distinct types of Chinese misconstructions. The study collected and generated a speech corpus containing 2540 Stopping, Velar, Consonant-vowel, and Affricate samples from 90 children aged 3-6 years with normal or pathological articulatory features. Each recording was accompanied by a detailed annotation from the field of speech therapy. Classification of the speech samples was accomplished using three well-established neural network models for image classification. The feature maps are created using three sets of MFCC parameters extracted from speech sounds and aggregated into a three-dimensional data structure as model input. We employ six techniques for data augmentation in order to augment the available dataset while avoiding over-simulation. The experiments examine the usability of four different categories of Chinese phrases and characters. Experiments with different data subsets demonstrate the system's ability to accurately detect the analyzed pronunciation disorders.