 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient 3D Full-Body Motion Generation from Sparse Tracking Inputs with Temporal Windows
May 03, 2025To have a seamless user experience on immersive AR/VR applications, the importance of efficient and effective Neural Network (NN) models is undeniable, since missing body parts that cannot be captured by limited sensors should be generated using these models for a complete 3D full-body reconstruction in virtual environment. However, the state-of-the-art NN-models are typically computational expensive and they leverage longer sequences of sparse tracking inputs to generate full-body movements by capturing temporal context. Inevitably, longer sequences increase the computation overhead and introduce noise in longer temporal dependencies that adversely affect the generation performance. In this paper, we propose a novel Multi-Layer Perceptron (MLP)-based method that enhances the overall performance while balancing the computational cost and memory overhead for efficient 3D full-body generation. Precisely, we introduce a NN-mechanism that divides the longer sequence of inputs into smaller temporal windows. Later, the current motion is merged with the information from these windows through latent representations to utilize the past context for the generation. Our experiments demonstrate that generation accuracy of our method with this NN-mechanism is significantly improved compared to the state-of-the-art methods while greatly reducing computational costs and memory overhead, making our method suitable for resource-constrained devices.
A Mixed Quantization Network for Computationally Efficient Mobile Inverse Tone Mapping
Mar 12, 2022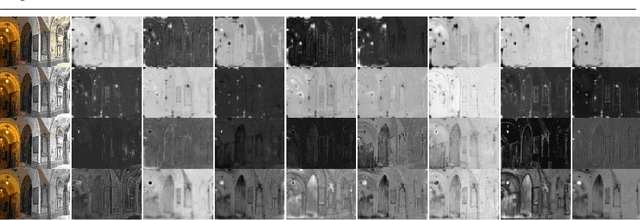
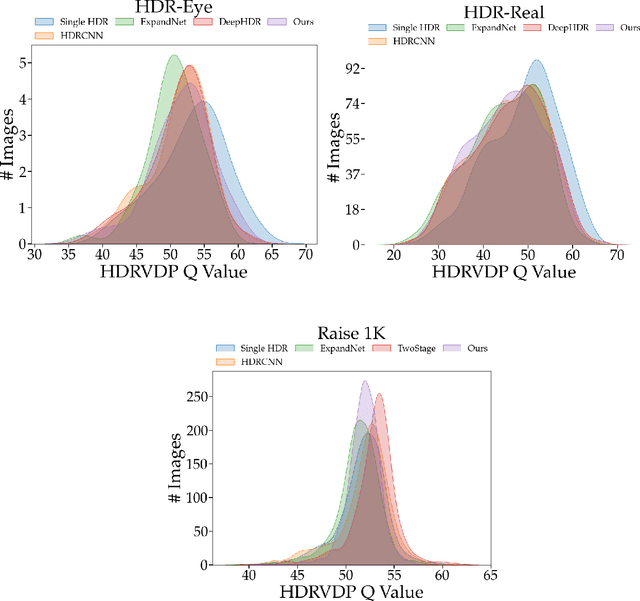
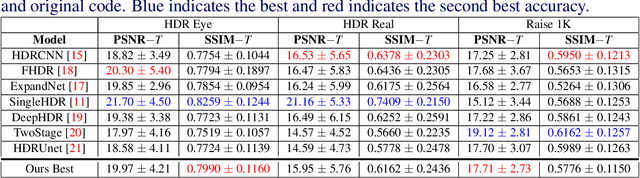
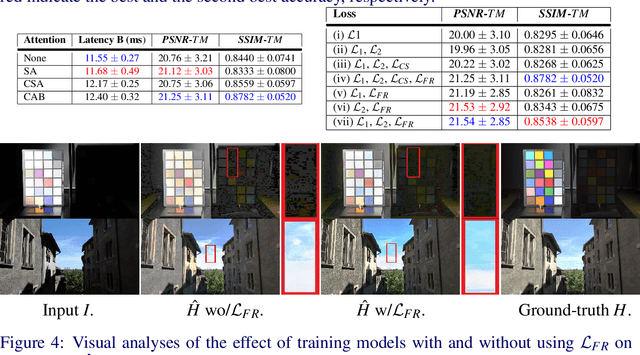
Recovering a high dynamic range (HDR) image from a single low dynamic range (LDR) image, namely inverse tone mapping (ITM), is challenging due to the lack of information in over- and under-exposed regions. Current methods focus exclusively on training high-performing but computationally inefficient ITM models, which in turn hinder deployment of the ITM models in resource-constrained environments with limited computing power such as edge and mobile device applications. To this end, we propose combining efficient operations of deep neural networks with a novel mixed quantization scheme to construct a well-performing but computationally efficient mixed quantization network (MQN) which can perform single image ITM on mobile platforms. In the ablation studies, we explore the effect of using different attention mechanisms, quantization schemes, and loss functions on the performance of MQN in ITM tasks. In the comparative analyses, ITM models trained using MQN perform on par with the state-of-the-art methods on benchmark datasets. MQN models provide up to 10 times improvement on latency and 25 times improvement on memory consumption.