 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Data-Consistent Local Superresolution for Medical Imaging
Feb 22, 2022
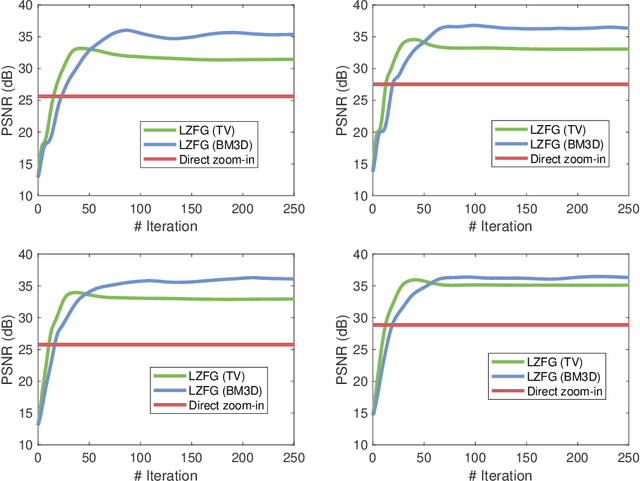
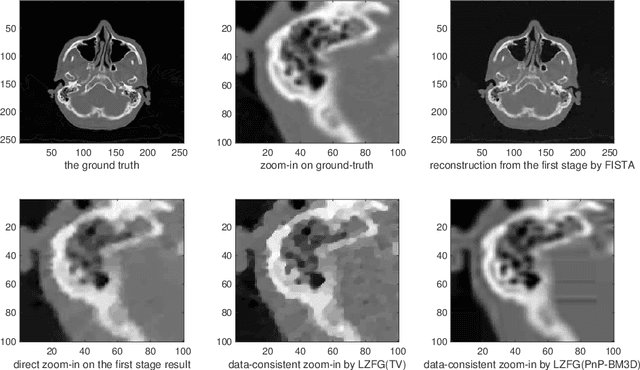
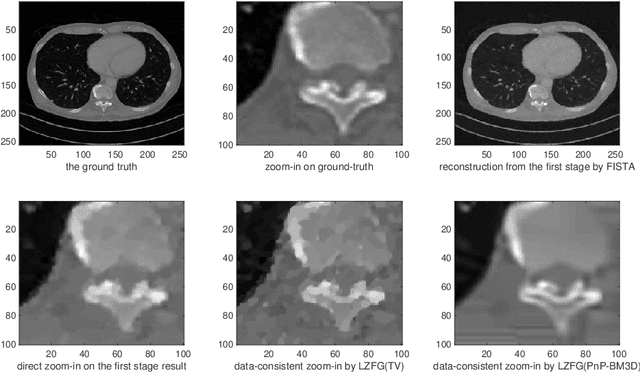

In this work we propose a new paradigm of iterative model-based reconstruction algorithms for providing real-time solution for zooming-in and refining a region of interest in medical and clinical tomographic (such as CT/MRI/PET, etc) images. This algorithmic framework is tailor for a clinical need in medical imaging practice, that after a reconstruction of the full tomographic image, the clinician may believe that some critical parts of the image are not clear enough, and may wish to see clearer these regions-of-interest. A naive approach (which is highly not recommended) would be performing the global reconstruction of a higher resolution image, which has two major limitations: firstly, it is computationally inefficient, and secondly, the image regularization is still applied globally which may over-smooth some local regions. Furthermore if one wish to fine-tune the regularization parameter for local parts, it would be computationally infeasible in practice for the case of using global reconstruction. Our new iterative approaches for such tasks are based on jointly utilizing the measurement information, efficient upsampling/downsampling across image spaces, and locally adjusted image prior for efficient and high-quality post-processing. The numerical results in low-dose X-ray CT image local zoom-in demonstrate the effectiveness of our approach.
FreqNet: A Frequency-domain Image Super-Resolution Network with Dicrete Cosine Transform
Nov 21, 2021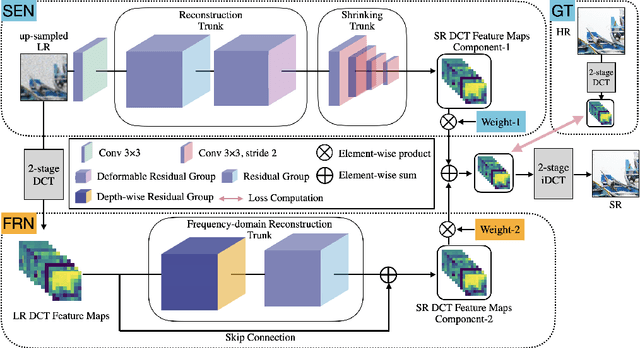
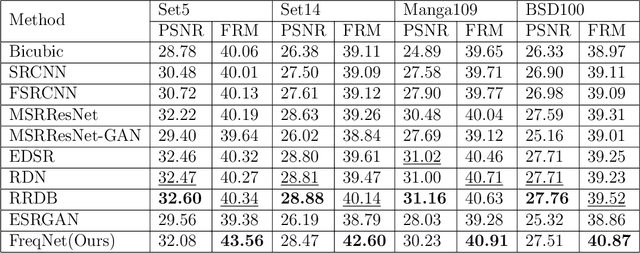

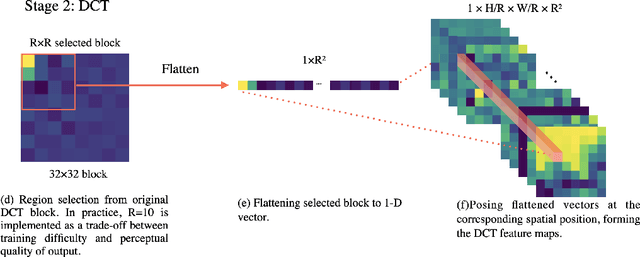
Single image super-resolution(SISR) is an ill-posed problem that aims to obtain high-resolution (HR) output from low-resolution (LR) input, during which extra high-frequency information is supposed to be added to improve the perceptual quality. Existing SISR works mainly operate in the spatial domain by minimizing the mean squared reconstruction error. Despite the high peak signal-to-noise ratios(PSNR) results, it is difficult to determine whether the model correctly adds desired high-frequency details. Some residual-based structures are proposed to guide the model to focus on high-frequency features implicitly. However, how to verify the fidelity of those artificial details remains a problem since the interpretation from spatial-domain metrics is limited. In this paper, we propose FreqNet, an intuitive pipeline from the frequency domain perspective, to solve this problem. Inspired by existing frequency-domain works, we convert images into discrete cosine transform (DCT) blocks, then reform them to obtain the DCT feature maps, which serve as the input and target of our model. A specialized pipeline is designed, and we further propose a frequency loss function to fit the nature of our frequency-domain task. Our SISR method in the frequency domain can learn the high-frequency information explicitly, provide fidelity and good perceptual quality for the SR images. We further observe that our model can be merged with other spatial super-resolution models to enhance the quality of their original SR output.
Structure-Aware Motion Transfer with Deformable Anchor Model
Apr 11, 2022
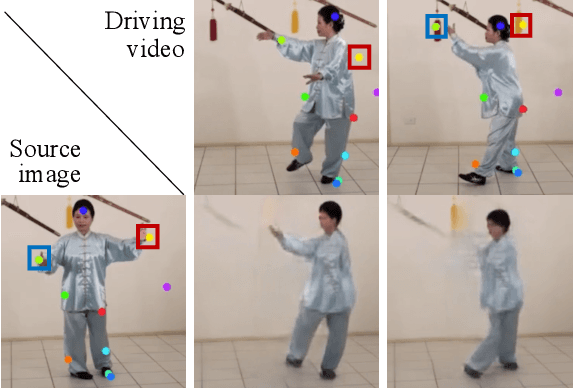

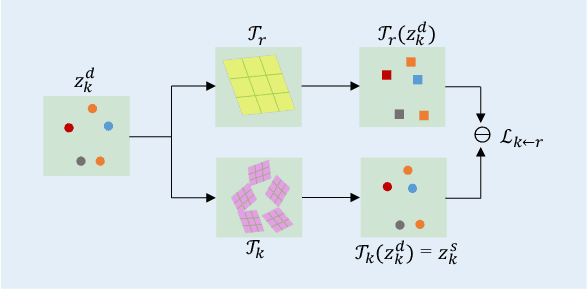
Given a source image and a driving video depicting the same object type, the motion transfer task aims to generate a video by learning the motion from the driving video while preserving the appearance from the source image. In this paper, we propose a novel structure-aware motion modeling approach, the deformable anchor model (DAM), which can automatically discover the motion structure of arbitrary objects without leveraging their prior structure information. Specifically, inspired by the known deformable part model (DPM), our DAM introduces two types of anchors or keypoints: i) a number of motion anchors that capture both appearance and motion information from the source image and driving video; ii) a latent root anchor, which is linked to the motion anchors to facilitate better learning of the representations of the object structure information. Moreover, DAM can be further extended to a hierarchical version through the introduction of additional latent anchors to model more complicated structures. By regularizing motion anchors with latent anchor(s), DAM enforces the correspondences between them to ensure the structural information is well captured and preserved. Moreover, DAM can be learned effectively in an unsupervised manner. We validate our proposed DAM for motion transfer on different benchmark datasets. Extensive experiments clearly demonstrate that DAM achieves superior performance relative to existing state-of-the-art methods.
Dual-Domain Reconstruction Networks with V-Net and K-Net for fast MRI
Mar 14, 2022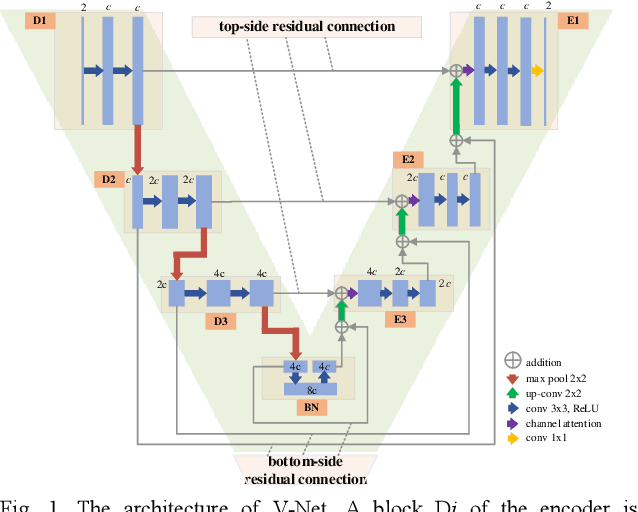
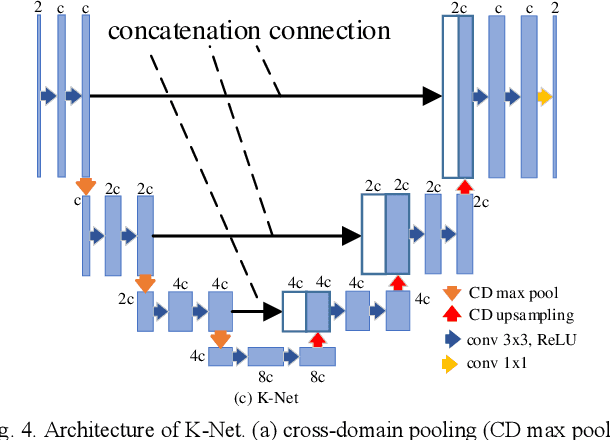

Purpose: To introduce a dual-domain reconstruction network with V-Net and K-Net for accurate MR image reconstruction from undersampled k-space data. Methods: Most state-of-the-art reconstruction methods apply U-Net or cascaded U-Nets in image domain and/or k-space domain. Nevertheless, these methods have following problems: (1) Directly applying U-Net in k-space domain is not optimal for extracting features in k-space domain; (2) Classical image-domain oriented U-Net is heavy-weight and hence is inefficient to be cascaded many times for yielding good reconstruction accuracy; (3) Classical image-domain oriented U-Net does not fully make use information of encoder network for extracting features in decoder network; and (4) Existing methods are ineffective in simultaneously extracting and fusing features in image domain and its dual k-space domain. To tackle these problems, we propose in this paper (1) an image-domain encoder-decoder sub-network called V-Net which is more light-weight for cascading and effective in fully utilizing features in the encoder for decoding, (2) a k-space domain sub-network called K-Net which is more suitable for extracting hierarchical features in k-space domain, and (3) a dual-domain reconstruction network where V-Nets and K-Nets are parallelly and effectively combined and cascaded. Results: Extensive experimental results on the challenging fastMRI dataset demonstrate that the proposed KV-Net can reconstruct high-quality images and outperform current state-of-the-art approaches with fewer parameters. Conclusions: To reconstruct images effectively and efficiently from incomplete k-space data, we have presented a parallel dual-domain KV-Net to combine K-Nets and V-Nets. The KV-Net is more lightweight than state-of-the-art methods but achieves better reconstruction performance.
Consistent Attack: Universal Adversarial Perturbation on Embodied Vision Navigation
Jun 12, 2022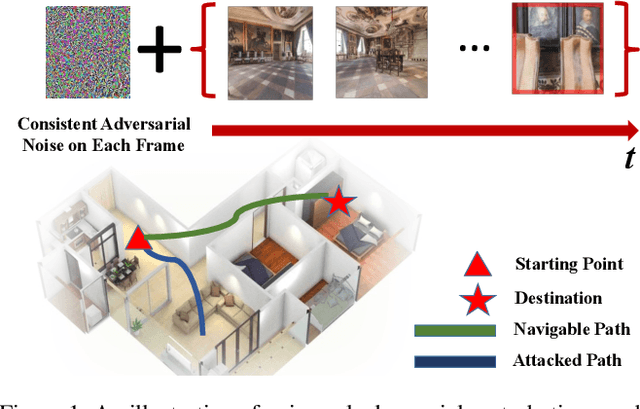
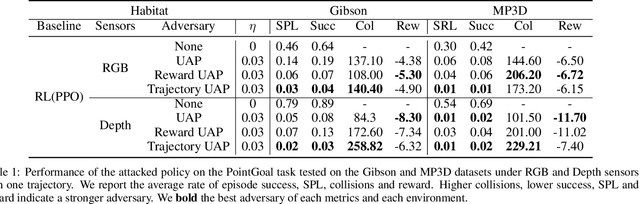

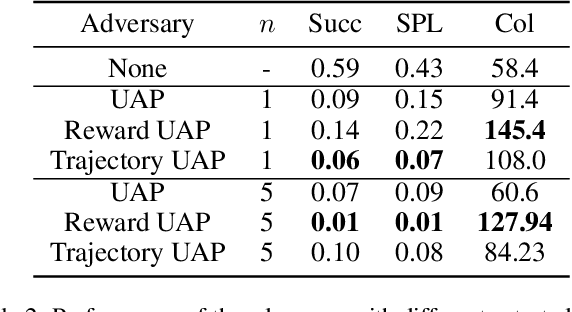
Embodied agents in vision navigation coupled with deep neural networks have attracted increasing attention. However, deep neural networks are vulnerable to malicious adversarial noises, which may potentially cause catastrophic failures in Embodied Vision Navigation. Among these adversarial noises, universal adversarial perturbations (UAP), i.e., the image-agnostic perturbation applied on each frame received by the agent, are more critical for Embodied Vision Navigation since they are computation-efficient and application-practical during the attack. However, existing UAP methods do not consider the system dynamics of Embodied Vision Navigation. For extending UAP in the sequential decision setting, we formulate the disturbed environment under the universal noise $\delta$, as a $\delta$-disturbed Markov Decision Process ($\delta$-MDP). Based on the formulation, we analyze the properties of $\delta$-MDP and propose two novel Consistent Attack methods for attacking Embodied agents, which first consider the dynamic of the MDP by estimating the disturbed Q function and the disturbed distribution. In spite of victim models, our Consistent Attack can cause a significant drop in the performance for the Goalpoint task in habitat. Extensive experimental results indicate that there exist potential risks for applying Embodied Vision Navigation methods to the real world.
Improving precision of objective image/video quality metrics
Apr 26, 2021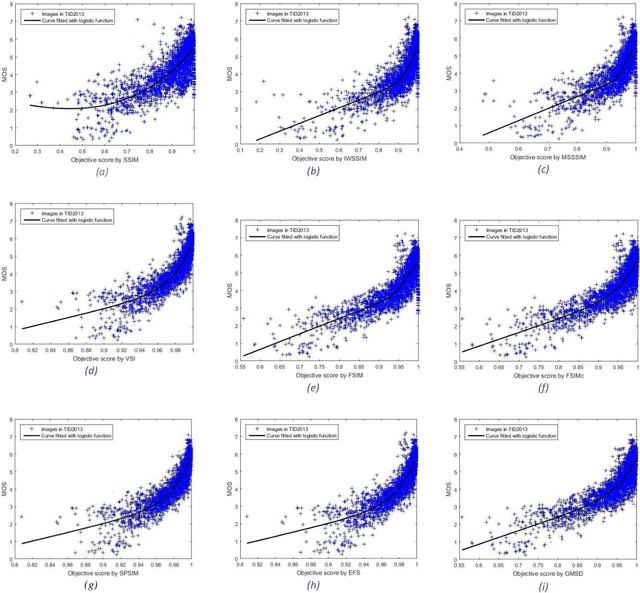
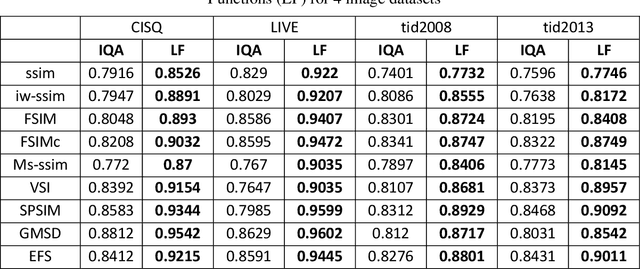
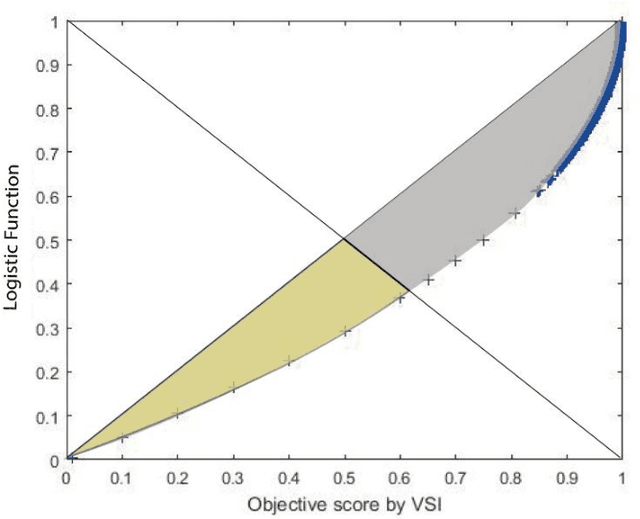
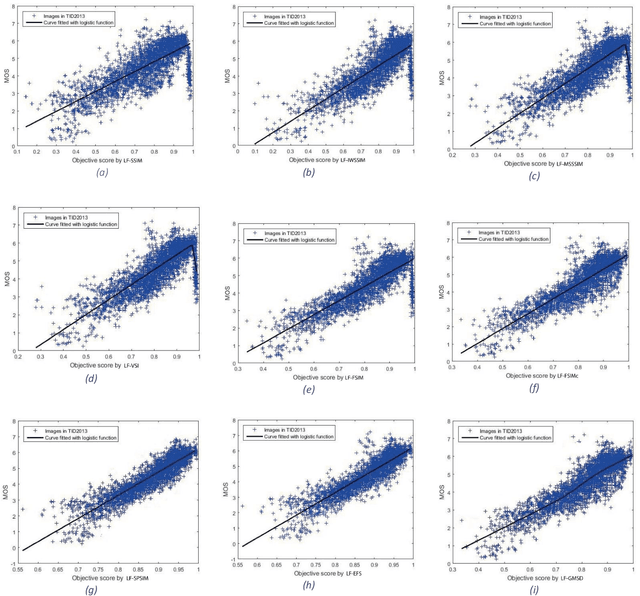
Although subjective tests are most accurate image/video quality assessment tools, they are extremely time demanding. In the past two decades, a variety of objective tools, such as SSIM, IW-SSIM, SPSIM, FSIM, etc., have been devised, that well correlate with the subjective tests results. However, the main problem with these methods is that, they do not discriminate the measured quality well enough, especially at high quality range. In this article we show how the accuracy/precision of these Image Quality Assessment (IQA) meters can be increased by mapping them into a Logistic Function (LF). The precisions are tested over a variety of image/video databases. Our experimental tests indicate while the used high-quality images can be discriminated by 23% resolution on the MOS subjective scores, discrimination resolution by the widely used IQAs are only 2%, but their mapped IQAs to Logistic Function at this quality range can be improved to 9.4%. Moreover, their precision at low to mid quality range can also be improved. At this quality range, while the discrimination resolution of MOS of the tested images is 23.2%, those of raw IQAs is nearly 8.9%, but their adapted logistic functions can lead to 17.7%, very close to that of MOS. Moreover, with the used image databases the Pearson correlation of MOS with the logistic function can be improved by 2%-20.2% as well.
Evaluation of Correctness in Unsupervised Many-to-Many Image Translation
Mar 29, 2021

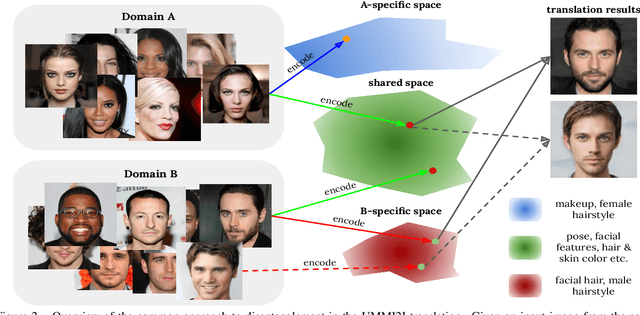
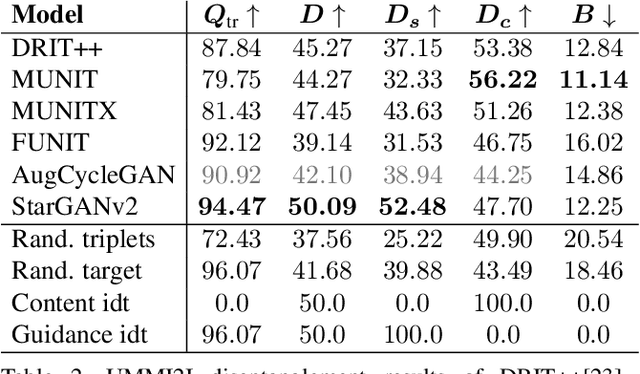
Given an input image from a source domain and a "guidance" image from a target domain, unsupervised many-to-many image-to-image (UMMI2I) translation methods seek to generate a plausible example from the target domain that preserves domain-invariant information of the input source image and inherits the domain-specific information from the guidance image. For example, when translating female faces to male faces, the generated male face should have the same expression, pose and hair color as the input female image, and the same facial hairstyle and other male-specific attributes as the guidance male image. Current state-of-the art UMMI2I methods generate visually pleasing images, but, since for most pairs of real datasets we do not know which attributes are domain-specific and which are domain-invariant, the semantic correctness of existing approaches has not been quantitatively evaluated yet. In this paper, we propose a set of benchmarks and metrics for the evaluation of semantic correctness of UMMI2I methods. We provide an extensive study how well the existing state-of-the-art UMMI2I translation methods preserve domain-invariant and manipulate domain-specific attributes, and discuss the trade-offs shared by all methods, as well as how different architectural choices affect various aspects of semantic correctness.
PISE: Person Image Synthesis and Editing with Decoupled GAN
Mar 16, 2021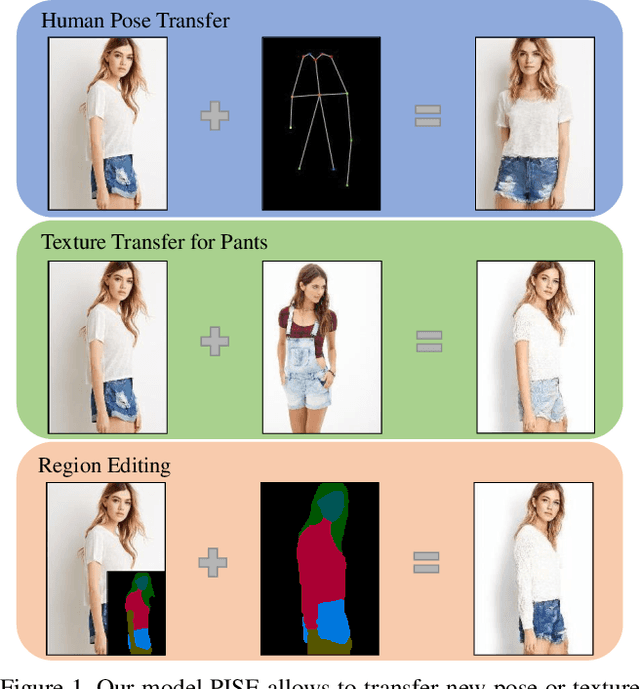
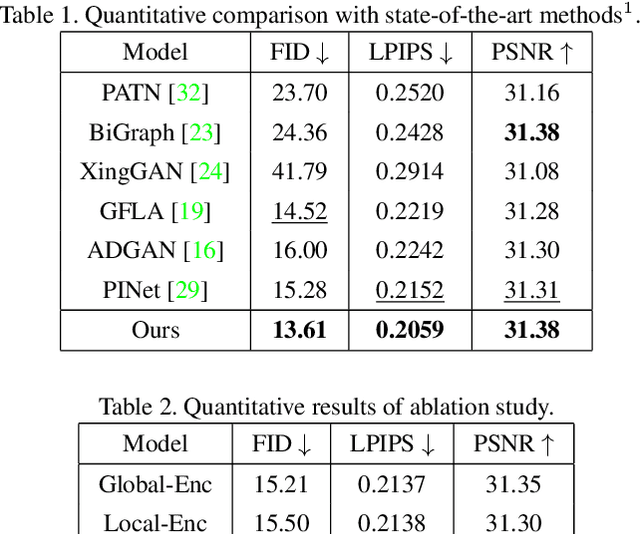
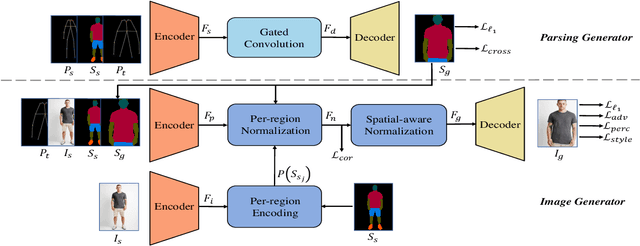
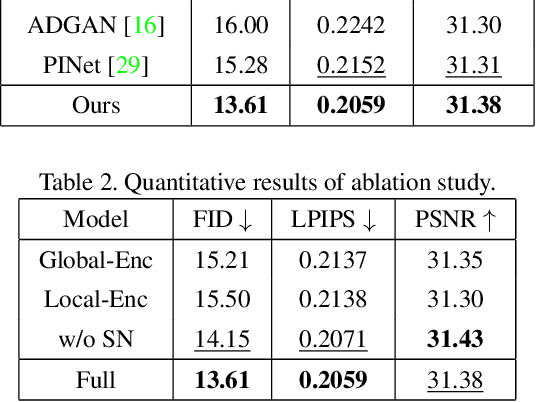
Person image synthesis, e.g., pose transfer, is a challenging problem due to large variation and occlusion. Existing methods have difficulties predicting reasonable invisible regions and fail to decouple the shape and style of clothing, which limits their applications on person image editing. In this paper, we propose PISE, a novel two-stage generative model for Person Image Synthesis and Editing, which is able to generate realistic person images with desired poses, textures, or semantic layouts. For human pose transfer, we first synthesize a human parsing map aligned with the target pose to represent the shape of clothing by a parsing generator, and then generate the final image by an image generator. To decouple the shape and style of clothing, we propose joint global and local per-region encoding and normalization to predict the reasonable style of clothing for invisible regions. We also propose spatial-aware normalization to retain the spatial context relationship in the source image. The results of qualitative and quantitative experiments demonstrate the superiority of our model on human pose transfer. Besides, the results of texture transfer and region editing show that our model can be applied to person image editing.
SparseNeuS: Fast Generalizable Neural Surface Reconstruction from Sparse views
Jun 12, 2022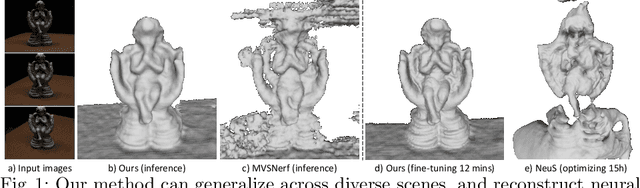
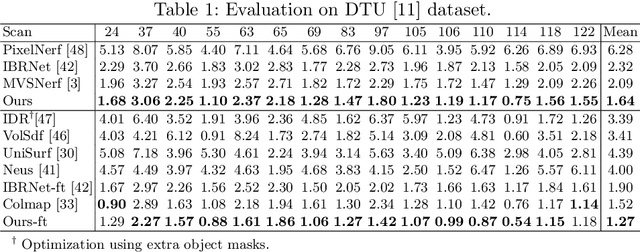
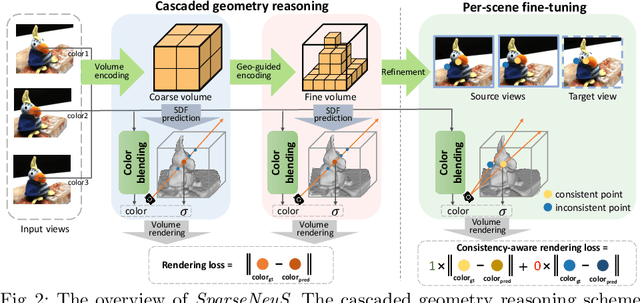

We introduce SparseNeuS, a novel neural rendering based method for the task of surface reconstruction from multi-view images. This task becomes more difficult when only sparse images are provided as input, a scenario where existing neural reconstruction approaches usually produce incomplete or distorted results. Moreover, their inability of generalizing to unseen new scenes impedes their application in practice. Contrarily, SparseNeuS can generalize to new scenes and work well with sparse images (as few as 2 or 3). SparseNeuS adopts signed distance function (SDF) as the surface representation, and learns generalizable priors from image features by introducing geometry encoding volumes for generic surface prediction. Moreover, several strategies are introduced to effectively leverage sparse views for high-quality reconstruction, including 1) a multi-level geometry reasoning framework to recover the surfaces in a coarse-to-fine manner; 2) a multi-scale color blending scheme for more reliable color prediction; 3) a consistency-aware fine-tuning scheme to control the inconsistent regions caused by occlusion and noise. Extensive experiments demonstrate that our approach not only outperforms the state-of-the-art methods, but also exhibits good efficiency, generalizability, and flexibility.
Multi-Compound Transformer for Accurate Biomedical Image Segmentation
Jun 28, 2021
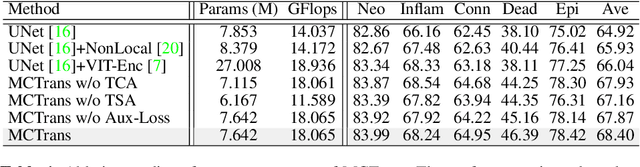
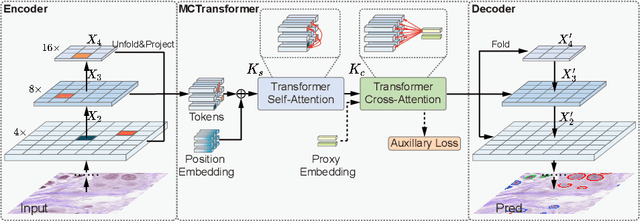
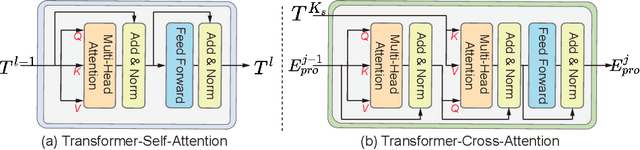
The recent vision transformer(i.e.for image classification) learns non-local attentive interaction of different patch tokens. However, prior arts miss learning the cross-scale dependencies of different pixels, the semantic correspondence of different labels, and the consistency of the feature representations and semantic embeddings, which are critical for biomedical segmentation. In this paper, we tackle the above issues by proposing a unified transformer network, termed Multi-Compound Transformer (MCTrans), which incorporates rich feature learning and semantic structure mining into a unified framework. Specifically, MCTrans embeds the multi-scale convolutional features as a sequence of tokens and performs intra- and inter-scale self-attention, rather than single-scale attention in previous works. In addition, a learnable proxy embedding is also introduced to model semantic relationship and feature enhancement by using self-attention and cross-attention, respectively. MCTrans can be easily plugged into a UNet-like network and attains a significant improvement over the state-of-the-art methods in biomedical image segmentation in six standard benchmarks. For example, MCTrans outperforms UNet by 3.64%, 3.71%, 4.34%, 2.8%, 1.88%, 1.57% in Pannuke, CVC-Clinic, CVC-Colon, Etis, Kavirs, ISIC2018 dataset, respectively. Code is available at https://github.com/JiYuanFeng/MCTrans.