 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Feature Information Extraction for Interest Point Detection: A Comprehensive Review
Jun 20, 2021
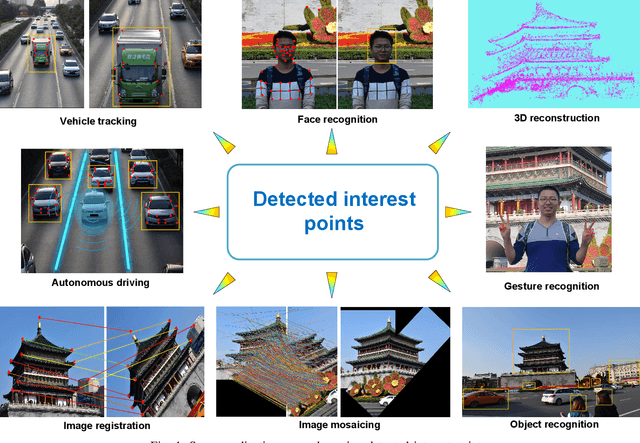
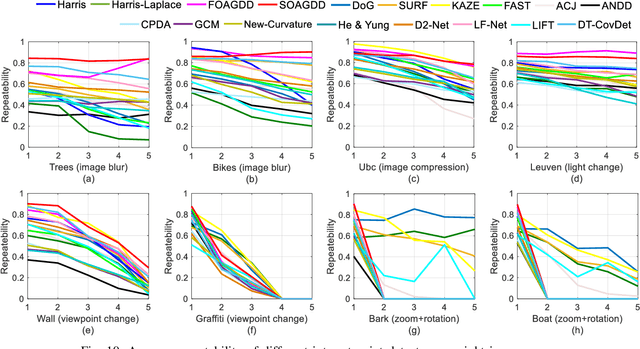

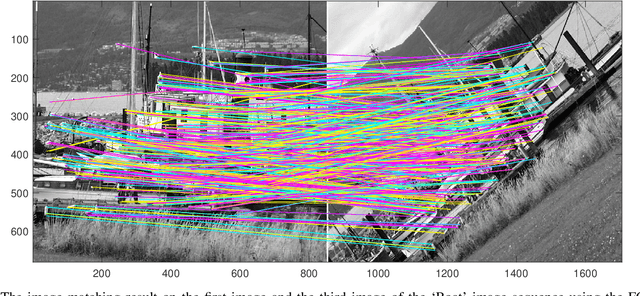
Interest point detection is one of the most fundamental and critical problems in computer vision and image processing. In this paper, we carry out a comprehensive review on image feature information (IFI) extraction techniques for interest point detection. To systematically introduce how the existing interest point detection methods extract IFI from an input image, we propose a taxonomy of the IFI extraction techniques for interest point detection. According to this taxonomy, we discuss different types of IFI extraction techniques for interest point detection. Furthermore, we identify the main unresolved issues related to the existing IFI extraction techniques for interest point detection and any interest point detection methods that have not been discussed before. The existing popular datasets and evaluation standards are provided and the performances for eighteen state-of-the-art approaches are evaluated and discussed. Moreover, future research directions on IFI extraction techniques for interest point detection are elaborated.
MultiEarth 2022 -- Multimodal Learning for Earth and Environment Workshop and Challenge
Apr 15, 2022


The Multimodal Learning for Earth and Environment Challenge (MultiEarth 2022) will be the first competition aimed at the monitoring and analysis of deforestation in the Amazon rainforest at any time and in any weather conditions. The goal of the Challenge is to provide a common benchmark for multimodal information processing and to bring together the earth and environmental science communities as well as multimodal representation learning communities to compare the relative merits of the various multimodal learning methods to deforestation estimation under well-defined and strictly comparable conditions. MultiEarth 2022 will have three sub-challenges: 1) matrix completion, 2) deforestation estimation, and 3) image-to-image translation. This paper presents the challenge guidelines, datasets, and evaluation metrics for the three sub-challenges. Our challenge website is available at https://sites.google.com/view/rainforest-challenge.
Contrastive learning of Class-agnostic Activation Map for Weakly Supervised Object Localization and Semantic Segmentation
Mar 25, 2022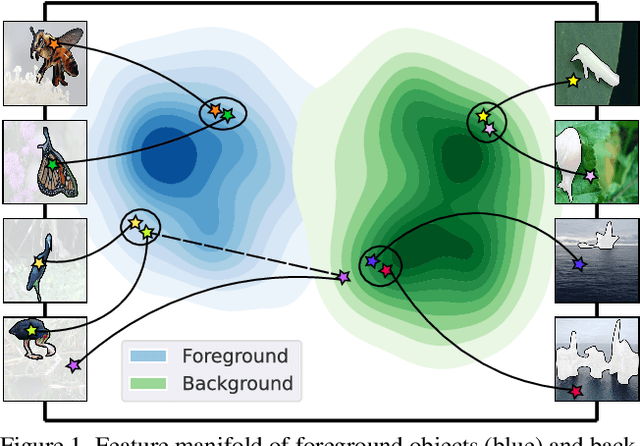
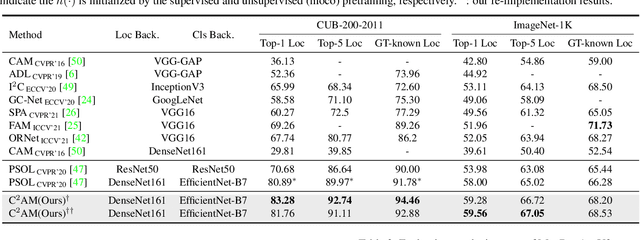
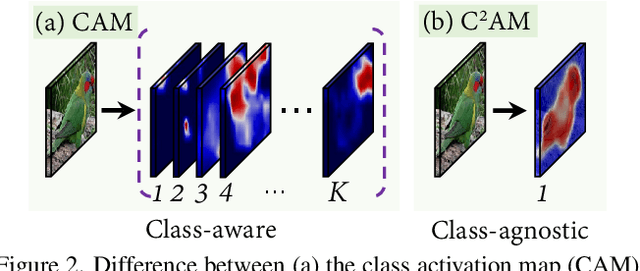
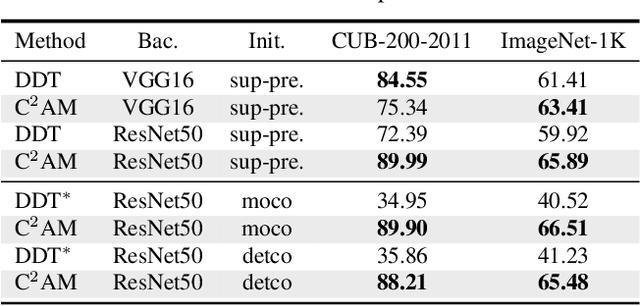
While class activation map (CAM) generated by image classification network has been widely used for weakly supervised object localization (WSOL) and semantic segmentation (WSSS), such classifiers usually focus on discriminative object regions. In this paper, we propose Contrastive learning for Class-agnostic Activation Map (C$^2$AM) generation only using unlabeled image data, without the involvement of image-level supervision. The core idea comes from the observation that i) semantic information of foreground objects usually differs from their backgrounds; ii) foreground objects with similar appearance or background with similar color/texture have similar representations in the feature space. We form the positive and negative pairs based on the above relations and force the network to disentangle foreground and background with a class-agnostic activation map using a novel contrastive loss. As the network is guided to discriminate cross-image foreground-background, the class-agnostic activation maps learned by our approach generate more complete object regions. We successfully extracted from C$^2$AM class-agnostic object bounding boxes for object localization and background cues to refine CAM generated by classification network for semantic segmentation. Extensive experiments on CUB-200-2011, ImageNet-1K, and PASCAL VOC2012 datasets show that both WSOL and WSSS can benefit from the proposed C$^2$AM.
X-ViT: High Performance Linear Vision Transformer without Softmax
May 27, 2022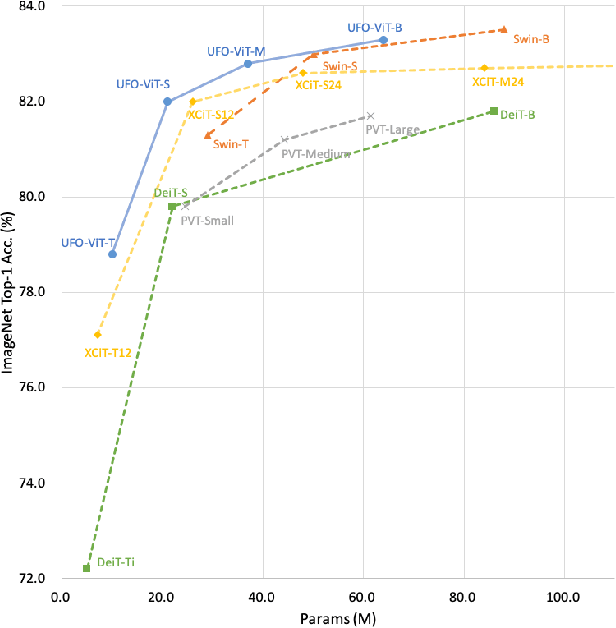

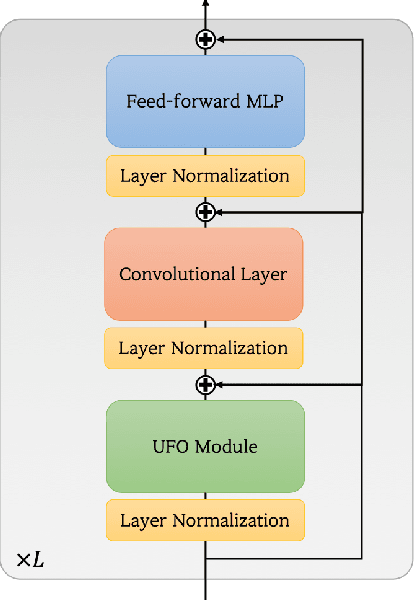

Vision transformers have become one of the most important models for computer vision tasks. Although they outperform prior works, they require heavy computational resources on a scale that is quadratic to the number of tokens, $N$. This is a major drawback of the traditional self-attention (SA) algorithm. Here, we propose the X-ViT, ViT with a novel SA mechanism that has linear complexity. The main approach of this work is to eliminate nonlinearity from the original SA. We factorize the matrix multiplication of the SA mechanism without complicated linear approximation. By modifying only a few lines of code from the original SA, the proposed models outperform most transformer-based models on image classification and dense prediction tasks on most capacity regimes.
Coarse-to-Fine Sparse Transformer for Hyperspectral Image Reconstruction
Mar 09, 2022
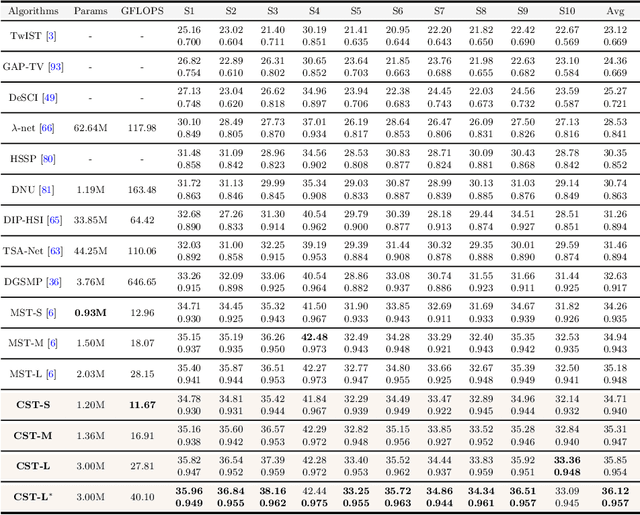
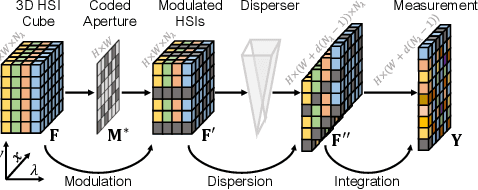
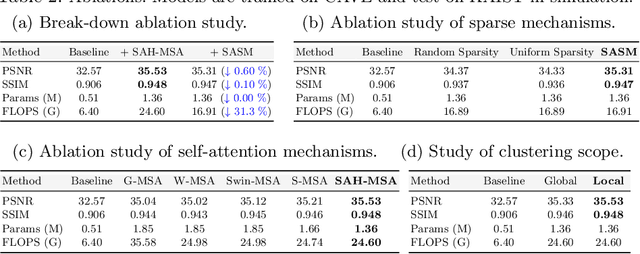
Many algorithms have been developed to solve the inverse problem of coded aperture snapshot spectral imaging (CASSI), i.e., recovering the 3D hyperspectral images (HSIs) from a 2D compressive measurement. In recent years, learning-based methods have demonstrated promising performance and dominated the mainstream research direction. However, existing CNN-based methods show limitations in capturing long-range dependencies and non-local self-similarity. Previous Transformer-based methods densely sample tokens, some of which are uninformative, and calculate the multi-head self-attention (MSA) between some tokens that are unrelated in content. This does not fit the spatially sparse nature of HSI signals and limits the model scalability. In this paper, we propose a novel Transformer-based method, coarse-to-fine sparse Transformer (CST), firstly embedding HSI sparsity into deep learning for HSI reconstruction. In particular, CST uses our proposed spectra-aware screening mechanism (SASM) for coarse patch selecting. Then the selected patches are fed into our customized spectra-aggregation hashing multi-head self-attention (SAH-MSA) for fine pixel clustering and self-similarity capturing. Comprehensive experiments show that our CST significantly outperforms state-of-the-art methods while requiring cheaper computational costs. The code and models will be made public.
Mask DINO: Towards A Unified Transformer-based Framework for Object Detection and Segmentation
Jun 06, 2022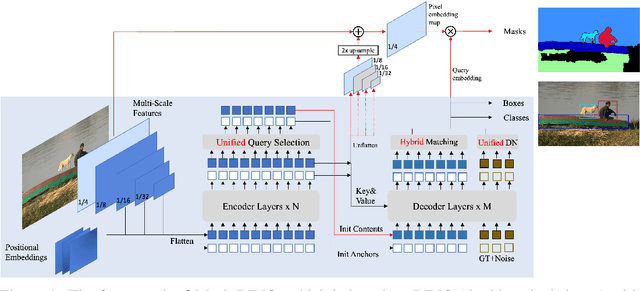



In this paper we present Mask DINO, a unified object detection and segmentation framework. Mask DINO extends DINO (DETR with Improved Denoising Anchor Boxes) by adding a mask prediction branch which supports all image segmentation tasks (instance, panoptic, and semantic). It makes use of the query embeddings from DINO to dot-product a high-resolution pixel embedding map to predict a set of binary masks. Some key components in DINO are extended for segmentation through a shared architecture and training process. Mask DINO is simple, efficient, scalable, and benefits from joint large-scale detection and segmentation datasets. Our experiments show that Mask DINO significantly outperforms all existing specialized segmentation methods, both on a ResNet-50 backbone and a pre-trained model with SwinL backbone. Notably, Mask DINO establishes the best results to date on instance segmentation (54.5 AP on COCO), panoptic segmentation (59.4 PQ on COCO), and semantic segmentation (60.8 mIoU on ADE20K). Code will be avaliable at \url{https://github.com/IDEACVR/MaskDINO}.
Attention-based Image Upsampling
Dec 17, 2020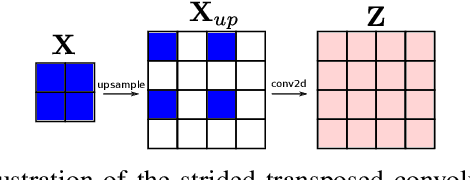
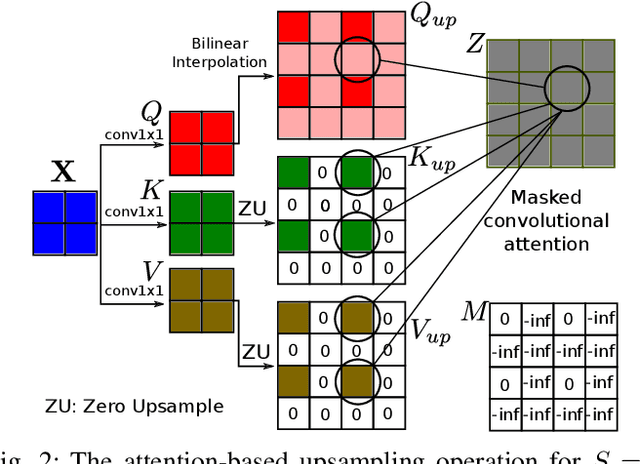
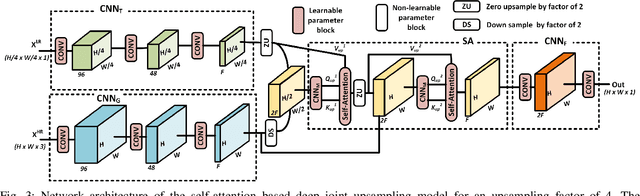

Convolutional layers are an integral part of many deep neural network solutions in computer vision. Recent work shows that replacing the standard convolution operation with mechanisms based on self-attention leads to improved performance on image classification and object detection tasks. In this work, we show how attention mechanisms can be used to replace another canonical operation: strided transposed convolution. We term our novel attention-based operation attention-based upsampling since it increases/upsamples the spatial dimensions of the feature maps. Through experiments on single image super-resolution and joint-image upsampling tasks, we show that attention-based upsampling consistently outperforms traditional upsampling methods based on strided transposed convolution or based on adaptive filters while using fewer parameters. We show that the inherent flexibility of the attention mechanism, which allows it to use separate sources for calculating the attention coefficients and the attention targets, makes attention-based upsampling a natural choice when fusing information from multiple image modalities.
Self-Supervised Implicit Attention: Guided Attention by The Model Itself
Jun 15, 2022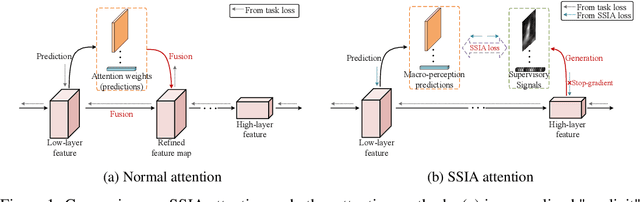

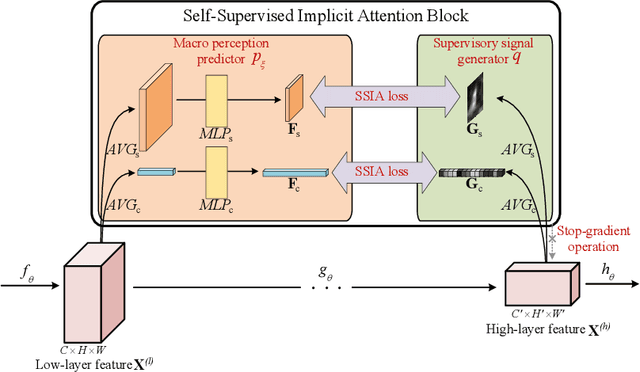
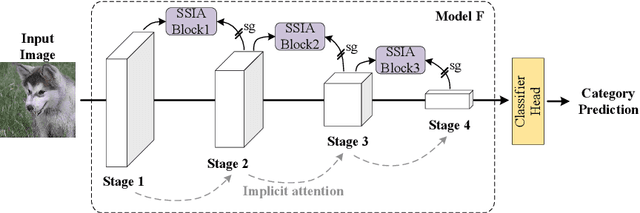
We propose Self-Supervised Implicit Attention (SSIA), a new approach that adaptively guides deep neural network models to gain attention by exploiting the properties of the models themselves. SSIA is a novel attention mechanism that does not require any extra parameters, computation, or memory access costs during inference, which is in contrast to existing attention mechanism. In short, by considering attention weights as higher-level semantic information, we reconsidered the implementation of existing attention mechanisms and further propose generating supervisory signals from higher network layers to guide lower network layers for parameter updates. We achieved this by building a self-supervised learning task using the hierarchical features of the network itself, which only works at the training stage. To verify the effectiveness of SSIA, we performed a particular implementation (called an SSIA block) in convolutional neural network models and validated it on several image classification datasets. The experimental results show that an SSIA block can significantly improve the model performance, even outperforms many popular attention methods that require additional parameters and computation costs, such as Squeeze-and-Excitation and Convolutional Block Attention Module. Our implementation will be available on GitHub.
Deep Neural Network Pruning for Nuclei Instance Segmentation in Hematoxylin & Eosin-Stained Histological Images
Jun 15, 2022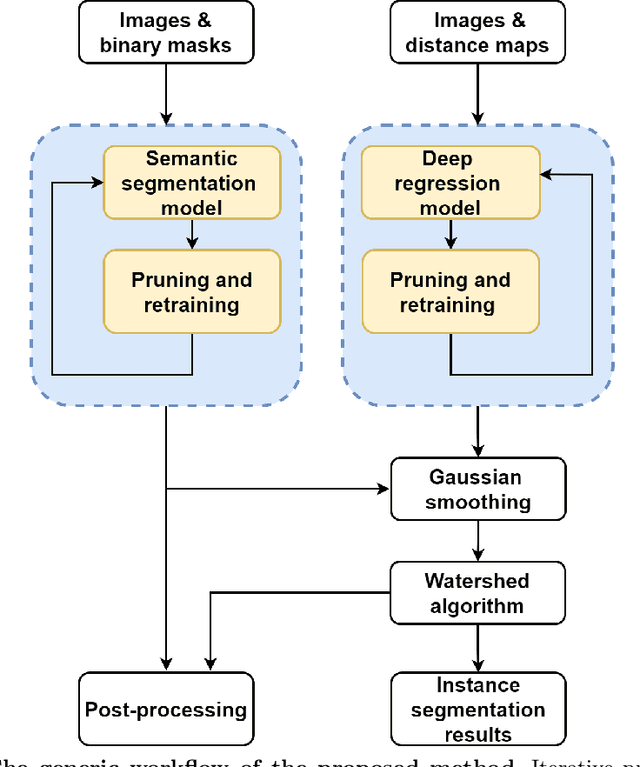

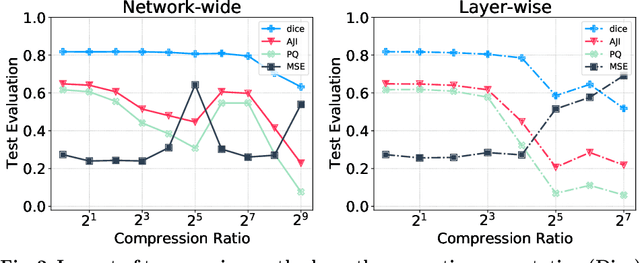
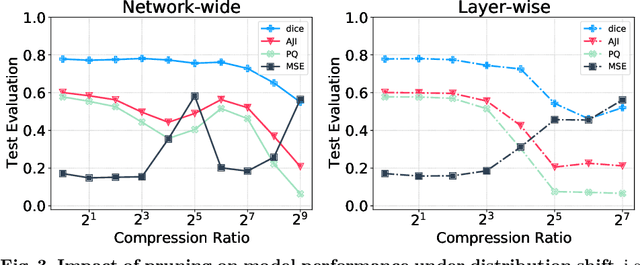
Recently, pruning deep neural networks (DNNs) has received a lot of attention for improving accuracy and generalization power, reducing network size, and increasing inference speed on specialized hardwares. Although pruning was mainly tested on computer vision tasks, its application in the context of medical image analysis has hardly been explored. This work investigates the impact of well-known pruning techniques, namely layer-wise and network-wide magnitude pruning, on the nuclei instance segmentation performance in histological images. Our utilized instance segmentation model consists of two main branches: (1) a semantic segmentation branch, and (2) a deep regression branch. We investigate the impact of weight pruning on the performance of both branches separately and on the final nuclei instance segmentation result. Evaluated on two publicly available datasets, our results show that layer-wise pruning delivers slightly better performance than networkwide pruning for small compression ratios (CRs) while for large CRs, network-wide pruning yields superior performance. For semantic segmentation, deep regression and final instance segmentation, 93.75 %, 95 %, and 80 % of the model weights can be pruned by layer-wise pruning with less than 2 % reduction in the performance of respective models.
The Manifold Hypothesis for Gradient-Based Explanations
Jun 15, 2022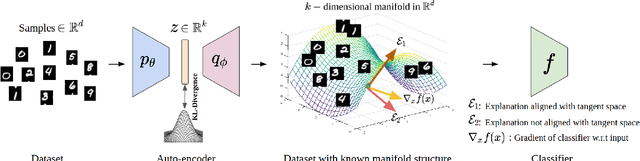
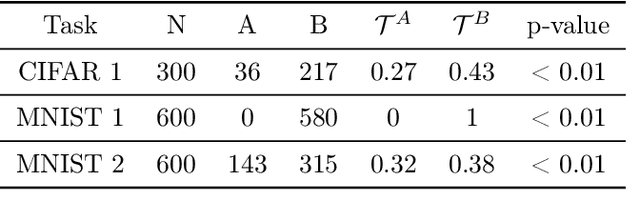
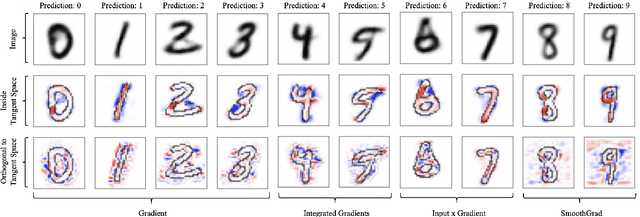
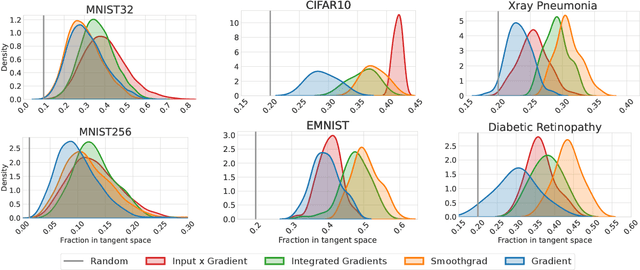
When do gradient-based explanation algorithms provide meaningful explanations? We propose a necessary criterion: their feature attributions need to be aligned with the tangent space of the data manifold. To provide evidence for this hypothesis, we introduce a framework based on variational autoencoders that allows to estimate and generate image manifolds. Through experiments across a range of different datasets -- MNIST, EMNIST, CIFAR10, X-ray pneumonia and Diabetic Retinopathy detection -- we demonstrate that the more a feature attribution is aligned with the tangent space of the data, the more structured and explanatory it tends to be. In particular, the attributions provided by popular post-hoc methods such as Integrated Gradients, SmoothGrad and Input $\times$ Gradient tend to be more strongly aligned with the data manifold than the raw gradient. As a consequence, we suggest that explanation algorithms should actively strive to align their explanations with the data manifold. In part, this can be achieved by adversarial training, which leads to better alignment across all datasets. Some form of adjustment to the model architecture or training algorithm is necessary, since we show that generalization of neural networks alone does not imply the alignment of model gradients with the data manifold.