 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMF-QAT: Multi-Format Quantization-Aware Training for Elastic Inference
Apr 01, 2026Quantization-aware training (QAT) is typically performed for a single target numeric format, while practical deployments often need to choose numerical precision at inference time based on hardware support or runtime constraints. We study multi-format QAT, where a single model is trained to be robust across multiple quantization formats. We find that multi-format QAT can match single-format QAT at each target precision, yielding one model that performs well overall across different formats, even formats that were not seen during training. To enable practical deployment, we propose the Slice-and-Scale conversion procedure for both MXINT and MXFP that converts a high-precision representation into lower-precision formats without re-training. Building on this, we introduce a pipeline that (i) trains a model with multi-format QAT, (ii) stores a single anchor format checkpoint (MXINT8/MXFP8), and (iii) allows on-the-fly conversion to lower MXINT or MXFP formats at runtime with negligible-or no-additional accuracy degradation. Together, these components provide a practical path to elastic precision scaling and allow selecting the runtime format at inference time across diverse deployment targets.
Distributed Training of Large Graph Neural Networks with Variable Communication Rates
Jun 25, 2024Training Graph Neural Networks (GNNs) on large graphs presents unique challenges due to the large memory and computing requirements. Distributed GNN training, where the graph is partitioned across multiple machines, is a common approach to training GNNs on large graphs. However, as the graph cannot generally be decomposed into small non-interacting components, data communication between the training machines quickly limits training speeds. Compressing the communicated node activations by a fixed amount improves the training speeds, but lowers the accuracy of the trained GNN. In this paper, we introduce a variable compression scheme for reducing the communication volume in distributed GNN training without compromising the accuracy of the learned model. Based on our theoretical analysis, we derive a variable compression method that converges to a solution equivalent to the full communication case, for all graph partitioning schemes. Our empirical results show that our method attains a comparable performance to the one obtained with full communication. We outperform full communication at any fixed compression ratio for any communication budget.
GraphAny: A Foundation Model for Node Classification on Any Graph
Jun 03, 2024Foundation models that can perform inference on any new task without requiring specific training have revolutionized machine learning in vision and language applications. However, applications involving graph-structured data remain a tough nut for foundation models, due to challenges in the unique feature- and label spaces associated with each graph. Traditional graph ML models such as graph neural networks (GNNs) trained on graphs cannot perform inference on a new graph with feature and label spaces different from the training ones. Furthermore, existing models learn functions specific to the training graph and cannot generalize to new graphs. In this work, we tackle these two challenges with a new foundational architecture for inductive node classification named GraphAny. GraphAny models inference on a new graph as an analytical solution to a LinearGNN, thereby solving the first challenge. To solve the second challenge, we learn attention scores for each node to fuse the predictions of multiple LinearGNNs. Specifically, the attention module is carefully parameterized as a function of the entropy-normalized distance-features between multiple LinearGNNs predictions to ensure generalization to new graphs. Empirically, GraphAny trained on the Wisconsin dataset with only 120 labeled nodes can effectively generalize to 30 new graphs with an average accuracy of 67.26\% in an inductive manner, surpassing GCN and GAT trained in the supervised regime, as well as other inductive baselines.
FloorSet -- a VLSI Floorplanning Dataset with Design Constraints of Real-World SoCs
May 09, 2024



Floorplanning for systems-on-a-chip (SoCs) and its sub-systems is a crucial and non-trivial step of the physical design flow. It represents a difficult combinatorial optimization problem. A typical large scale SoC with 120 partitions generates a search-space of nearly 10E250. As novel machine learning (ML) approaches emerge to tackle such problems, there is a growing need for a modern benchmark that comprises a large training dataset and performance metrics that better reflect real-world constraints and objectives compared to existing benchmarks. To address this need, we present FloorSet -- two comprehensive datasets of synthetic fixed-outline floorplan layouts that reflect the distribution of real SoCs. Each dataset has 1M training samples and 100 test samples where each sample is a synthetic floor-plan. FloorSet-Prime comprises fully-abutted rectilinear partitions and near-optimal wire-length. A simplified dataset that reflects early design phases, FloorSet-Lite comprises rectangular partitions, with under 5 percent white-space and near-optimal wire-length. Both datasets define hard constraints seen in modern design flows such as shape constraints, edge-affinity, grouping constraints, and pre-placement constraints. FloorSet is intended to spur fundamental research on large-scale constrained optimization problems. Crucially, FloorSet alleviates the core issue of reproducibility in modern ML driven solutions to such problems. FloorSet is available as an open-source repository for the research community.
Towards Foundation Models for Knowledge Graph Reasoning
Oct 06, 2023



Foundation models in language and vision have the ability to run inference on any textual and visual inputs thanks to the transferable representations such as a vocabulary of tokens in language. Knowledge graphs (KGs) have different entity and relation vocabularies that generally do not overlap. The key challenge of designing foundation models on KGs is to learn such transferable representations that enable inference on any graph with arbitrary entity and relation vocabularies. In this work, we make a step towards such foundation models and present ULTRA, an approach for learning universal and transferable graph representations. ULTRA builds relational representations as a function conditioned on their interactions. Such a conditioning strategy allows a pre-trained ULTRA model to inductively generalize to any unseen KG with any relation vocabulary and to be fine-tuned on any graph. Conducting link prediction experiments on 57 different KGs, we find that the zero-shot inductive inference performance of a single pre-trained ULTRA model on unseen graphs of various sizes is often on par or better than strong baselines trained on specific graphs. Fine-tuning further boosts the performance.
Exploiting Long-Term Dependencies for Generating Dynamic Scene Graphs
Dec 18, 2021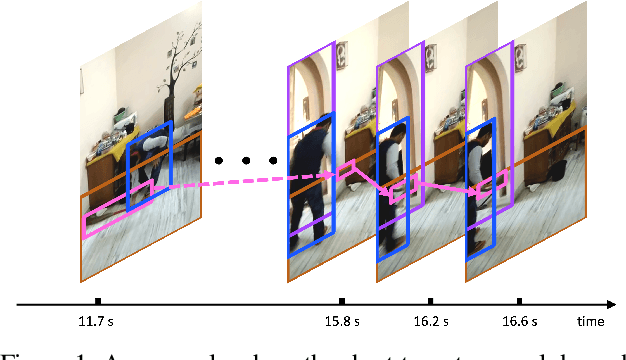
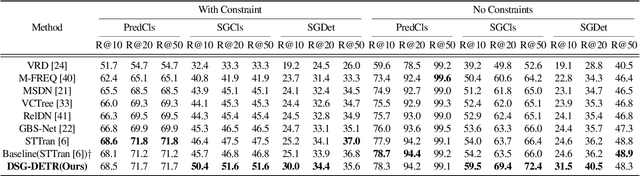
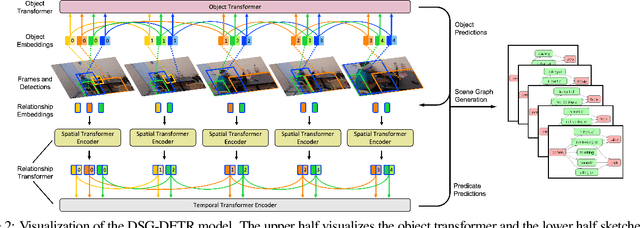
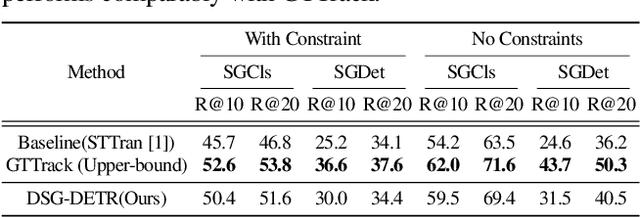
Structured video representation in the form of dynamic scene graphs is an effective tool for several video understanding tasks. Compared to the task of scene graph generation from images, dynamic scene graph generation is more challenging due to the temporal dynamics of the scene and the inherent temporal fluctuations of predictions. We show that capturing long-term dependencies is the key to effective generation of dynamic scene graphs. We present the detect-track-recognize paradigm by constructing consistent long-term object tracklets from a video, followed by transformers to capture the dynamics of objects and visual relations. Experimental results demonstrate that our Dynamic Scene Graph Detection Transformer (DSG-DETR) outperforms state-of-the-art methods by a significant margin on the benchmark dataset Action Genome. We also perform ablation studies and validate the effectiveness of each component of the proposed approach.
Sequential Aggregation and Rematerialization: Distributed Full-batch Training of Graph Neural Networks on Large Graphs
Nov 11, 2021
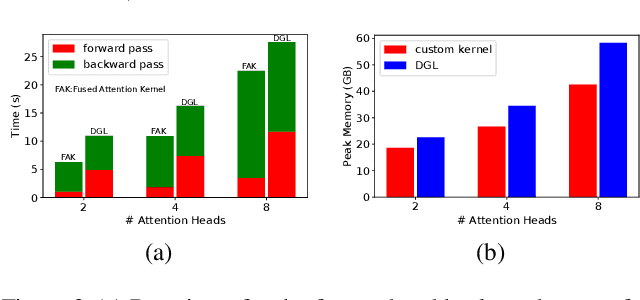
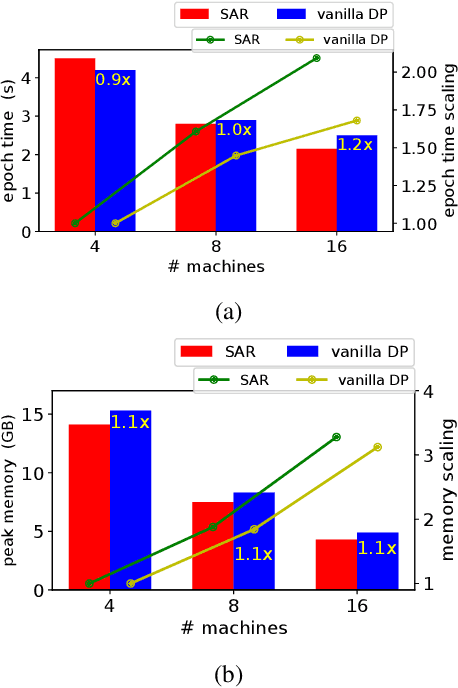
We present the Sequential Aggregation and Rematerialization (SAR) scheme for distributed full-batch training of Graph Neural Networks (GNNs) on large graphs. Large-scale training of GNNs has recently been dominated by sampling-based methods and methods based on non-learnable message passing. SAR on the other hand is a distributed technique that can train any GNN type directly on an entire large graph. The key innovation in SAR is the distributed sequential rematerialization scheme which sequentially re-constructs then frees pieces of the prohibitively large GNN computational graph during the backward pass. This results in excellent memory scaling behavior where the memory consumption per worker goes down linearly with the number of workers, even for densely connected graphs. Using SAR, we report the largest applications of full-batch GNN training to-date, and demonstrate large memory savings as the number of workers increases. We also present a general technique based on kernel fusion and attention-matrix rematerialization to optimize both the runtime and memory efficiency of attention-based models. We show that, coupled with SAR, our optimized attention kernels lead to significant speedups and memory savings in attention-based GNNs.
Implicit SVD for Graph Representation Learning
Nov 11, 2021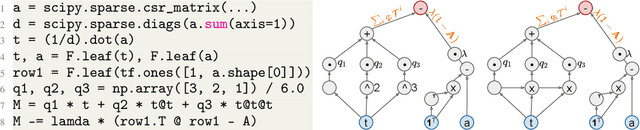
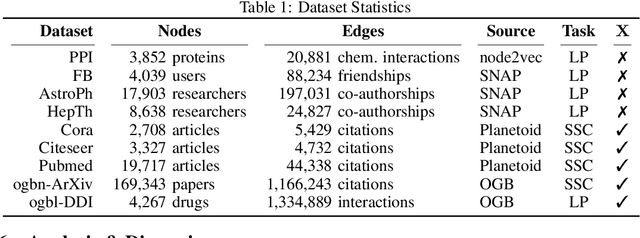
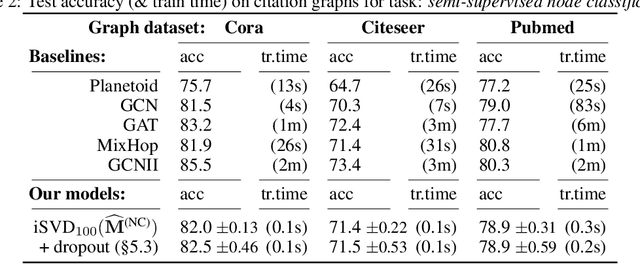
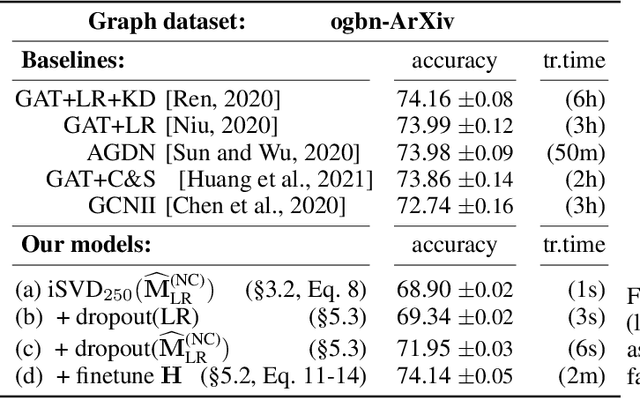
Recent improvements in the performance of state-of-the-art (SOTA) methods for Graph Representational Learning (GRL) have come at the cost of significant computational resource requirements for training, e.g., for calculating gradients via backprop over many data epochs. Meanwhile, Singular Value Decomposition (SVD) can find closed-form solutions to convex problems, using merely a handful of epochs. In this paper, we make GRL more computationally tractable for those with modest hardware. We design a framework that computes SVD of \textit{implicitly} defined matrices, and apply this framework to several GRL tasks. For each task, we derive linear approximation of a SOTA model, where we design (expensive-to-store) matrix $\mathbf{M}$ and train the model, in closed-form, via SVD of $\mathbf{M}$, without calculating entries of $\mathbf{M}$. By converging to a unique point in one step, and without calculating gradients, our models show competitive empirical test performance over various graphs such as article citation and biological interaction networks. More importantly, SVD can initialize a deeper model, that is architected to be non-linear almost everywhere, though behaves linearly when its parameters reside on a hyperplane, onto which SVD initializes. The deeper model can then be fine-tuned within only a few epochs. Overall, our procedure trains hundreds of times faster than state-of-the-art methods, while competing on empirical test performance. We open-source our implementation at: https://github.com/samihaija/isvd
On Local Aggregation in Heterophilic Graphs
Jun 06, 2021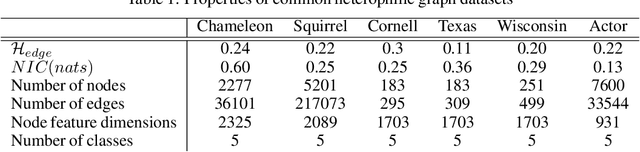
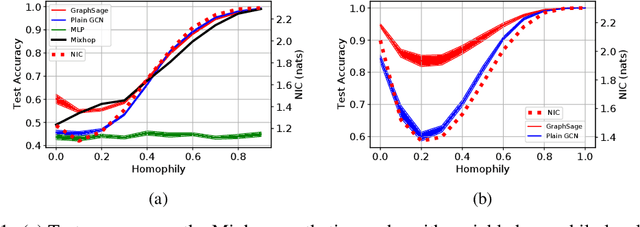
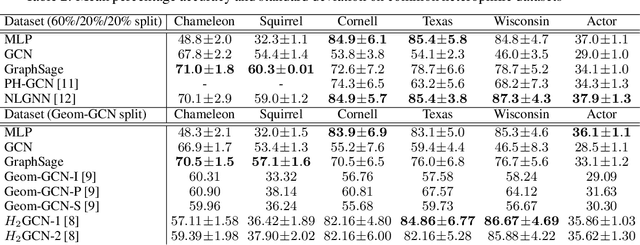
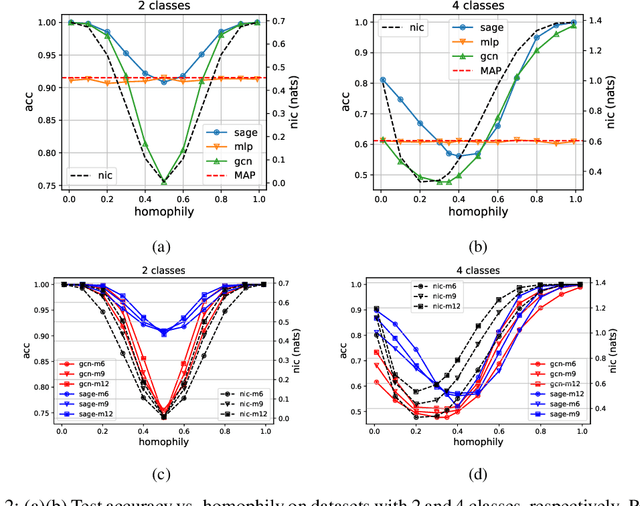
Many recent works have studied the performance of Graph Neural Networks (GNNs) in the context of graph homophily - a label-dependent measure of connectivity. Traditional GNNs generate node embeddings by aggregating information from a node's neighbors in the graph. Recent results in node classification tasks show that this local aggregation approach performs poorly in graphs with low homophily (heterophilic graphs). Several mechanisms have been proposed to improve the accuracy of GNNs on such graphs by increasing the aggregation range of a GNN layer, either through multi-hop aggregation, or through long-range aggregation from distant nodes. In this paper, we show that properly tuned classical GNNs and multi-layer perceptrons match or exceed the accuracy of recent long-range aggregation methods on heterophilic graphs. Thus, our results highlight the need for alternative datasets to benchmark long-range GNN aggregation mechanisms. We also show that homophily is a poor measure of the information in a node's local neighborhood and propose the Neighborhood Information Content(NIC) metric, which is a novel information-theoretic graph metric. We argue that NIC is more relevant for local aggregation methods as used by GNNs. We show that, empirically, it correlates better with GNN accuracy in node classification tasks than homophily.
Attention-based Image Upsampling
Dec 17, 2020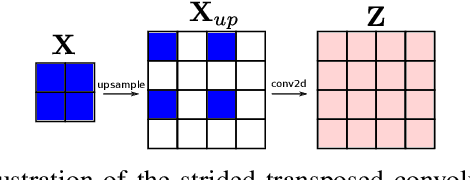
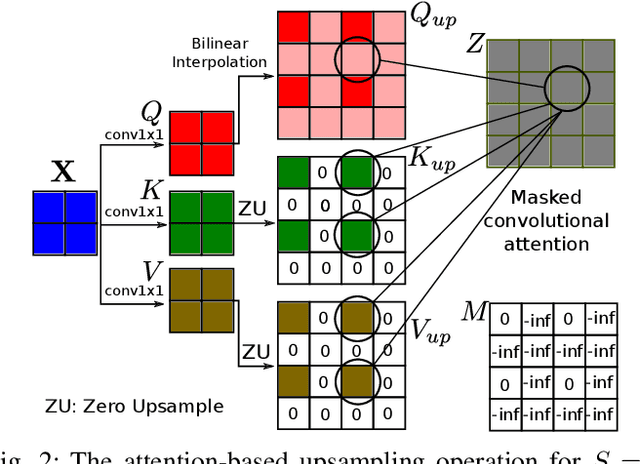
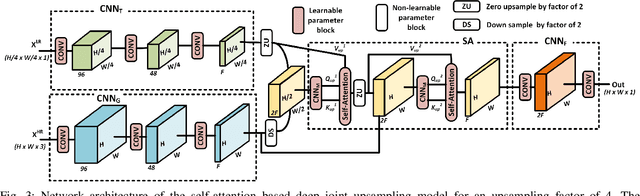

Convolutional layers are an integral part of many deep neural network solutions in computer vision. Recent work shows that replacing the standard convolution operation with mechanisms based on self-attention leads to improved performance on image classification and object detection tasks. In this work, we show how attention mechanisms can be used to replace another canonical operation: strided transposed convolution. We term our novel attention-based operation attention-based upsampling since it increases/upsamples the spatial dimensions of the feature maps. Through experiments on single image super-resolution and joint-image upsampling tasks, we show that attention-based upsampling consistently outperforms traditional upsampling methods based on strided transposed convolution or based on adaptive filters while using fewer parameters. We show that the inherent flexibility of the attention mechanism, which allows it to use separate sources for calculating the attention coefficients and the attention targets, makes attention-based upsampling a natural choice when fusing information from multiple image modalities.