 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dcl-Net: Dual Contrastive Learning Network for Semi-Supervised Multi-Organ Segmentation
Mar 06, 2024
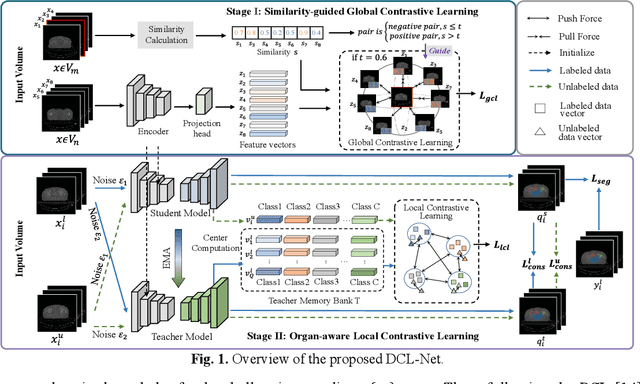
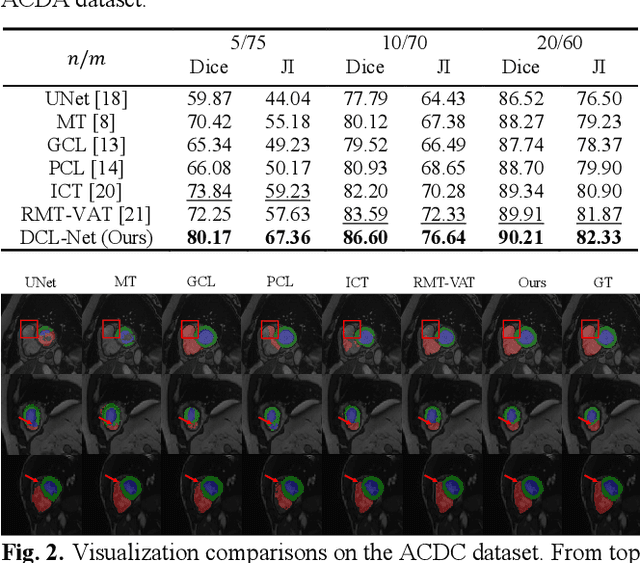
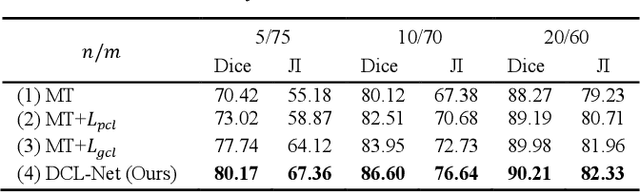
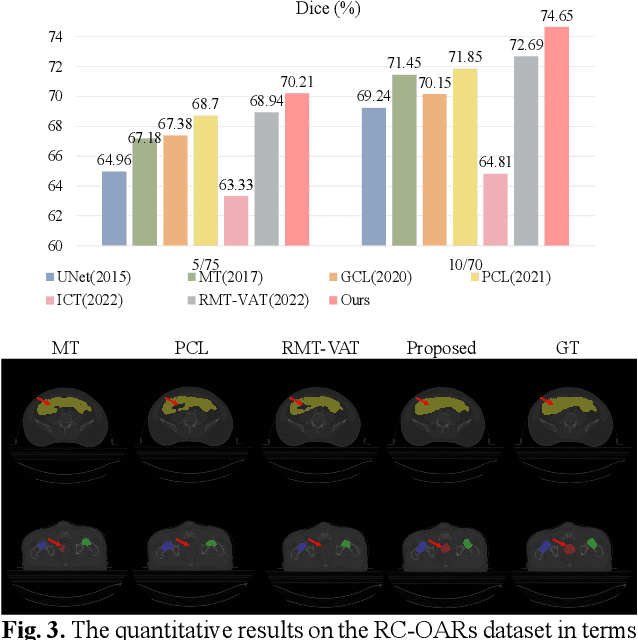
Semi-supervised learning is a sound measure to relieve the strict demand of abundant annotated datasets, especially for challenging multi-organ segmentation . However, most existing SSL methods predict pixels in a single image independently, ignoring the relations among images and categories. In this paper, we propose a two-stage Dual Contrastive Learning Network for semi-supervised MoS, which utilizes global and local contrastive learning to strengthen the relations among images and classes. Concretely, in Stage 1, we develop a similarity-guided global contrastive learning to explore the implicit continuity and similarity among images and learn global context. Then, in Stage 2, we present an organ-aware local contrastive learning to further attract the class representations. To ease the computation burden, we introduce a mask center computation algorithm to compress the category representations for local contrastive learning. Experiments conducted on the public 2017 ACDC dataset and an in-house RC-OARs dataset has demonstrated the superior performance of our method.
Assessing the Aesthetic Evaluation Capabilities of GPT-4 with Vision: Insights from Group and Individual Assessments
Mar 06, 2024Recently, it has been recognized that large language models demonstrate high performance on various intellectual tasks. However, few studies have investigated alignment with humans in behaviors that involve sensibility, such as aesthetic evaluation. This study investigates the performance of GPT-4 with Vision, a state-of-the-art language model that can handle image input, on the task of aesthetic evaluation of images. We employ two tasks, prediction of the average evaluation values of a group and an individual's evaluation values. We investigate the performance of GPT-4 with Vision by exploring prompts and analyzing prediction behaviors. Experimental results reveal GPT-4 with Vision's superior performance in predicting aesthetic evaluations and the nature of different responses to beauty and ugliness. Finally, we discuss developing an AI system for aesthetic evaluation based on scientific knowledge of the human perception of beauty, employing agent technologies that integrate traditional deep learning models with large language models.
Learned Image Compression with Text Quality Enhancement
Feb 13, 2024Learned image compression has gained widespread popularity for their efficiency in achieving ultra-low bit-rates. Yet, images containing substantial textual content, particularly screen-content images (SCI), often suffers from text distortion at such compressed levels. To address this, we propose to minimize a novel text logit loss designed to quantify the disparity in text between the original and reconstructed images, thereby improving the perceptual quality of the reconstructed text. Through rigorous experimentation across diverse datasets and employing state-of-the-art algorithms, our findings reveal significant enhancements in the quality of reconstructed text upon integration of the proposed loss function with appropriate weighting. Notably, we achieve a Bjontegaard delta (BD) rate of -32.64% for Character Error Rate (CER) and -28.03% for Word Error Rate (WER) on average by applying the text logit loss for two screenshot datasets. Additionally, we present quantitative metrics tailored for evaluating text quality in image compression tasks. Our findings underscore the efficacy and potential applicability of our proposed text logit loss function across various text-aware image compression contexts.
Tracking Meets LoRA: Faster Training, Larger Model, Stronger Performance
Mar 08, 2024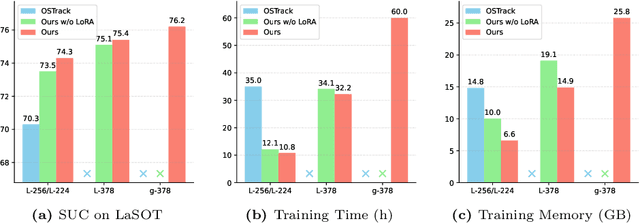
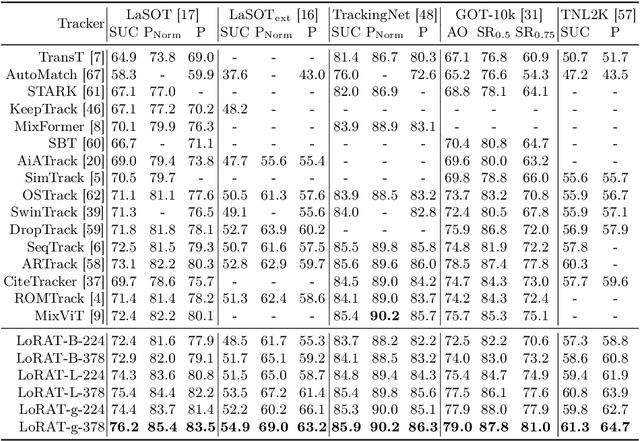
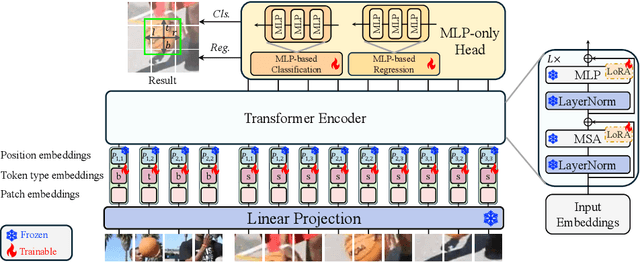
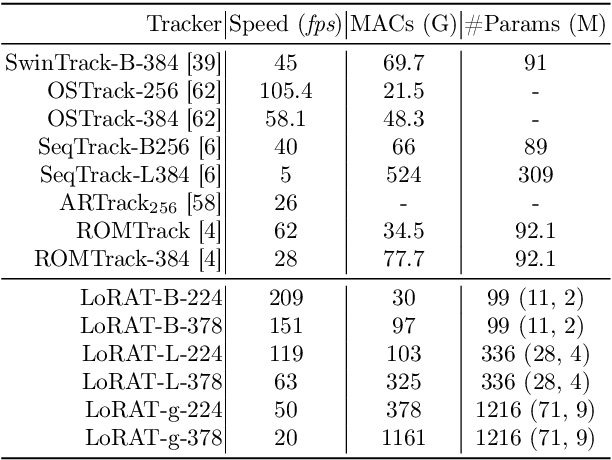
Motivated by the Parameter-Efficient Fine-Tuning (PEFT) in large language models, we propose LoRAT, a method that unveils the power of larger Vision Transformers (ViT) for tracking within laboratory-level resources. The essence of our work lies in adapting LoRA, a technique that fine-tunes a small subset of model parameters without adding inference latency, to the domain of visual tracking. However, unique challenges and potential domain gaps make this transfer not as easy as the first intuition. Firstly, a transformer-based tracker constructs unshared position embedding for template and search image. This poses a challenge for the transfer of LoRA, usually requiring consistency in the design when applied to the pre-trained backbone, to downstream tasks. Secondly, the inductive bias inherent in convolutional heads diminishes the effectiveness of parameter-efficient fine-tuning in tracking models. To overcome these limitations, we first decouple the position embeddings in transformer-based trackers into shared spatial ones and independent type ones. The shared embeddings, which describe the absolute coordinates of multi-resolution images (namely, the template and search images), are inherited from the pre-trained backbones. In contrast, the independent embeddings indicate the sources of each token and are learned from scratch. Furthermore, we design an anchor-free head solely based on a multilayer perceptron (MLP) to adapt PETR, enabling better performance with less computational overhead. With our design, 1) it becomes practical to train trackers with the ViT-g backbone on GPUs with only memory of 25.8GB (batch size of 16); 2) we reduce the training time of the L-224 variant from 35.0 to 10.8 GPU hours; 3) we improve the LaSOT SUC score from 0.703 to 0.743 with the L-224 variant; 4) we fast the inference speed of the L-224 variant from 52 to 119 FPS. Code and models will be released.
NiNformer: A Network in Network Transformer with Token Mixing Generated Gating Function
Mar 04, 2024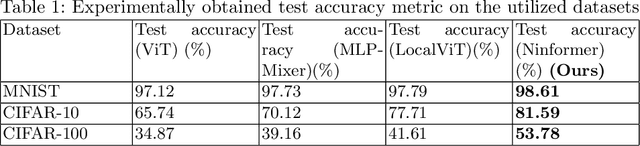
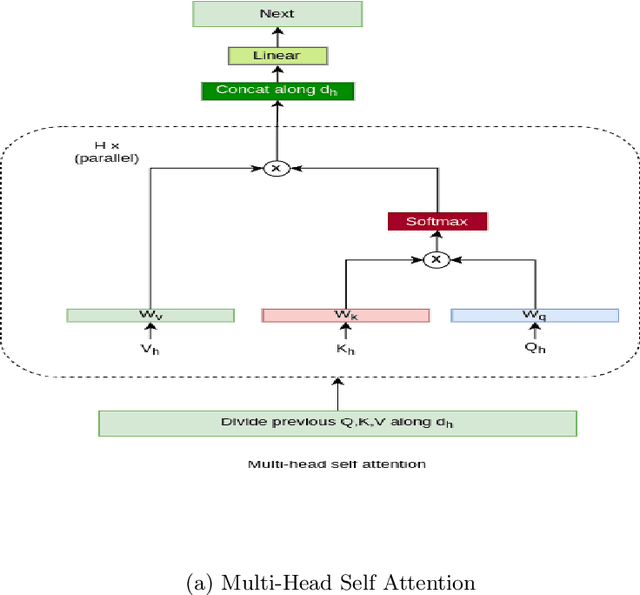
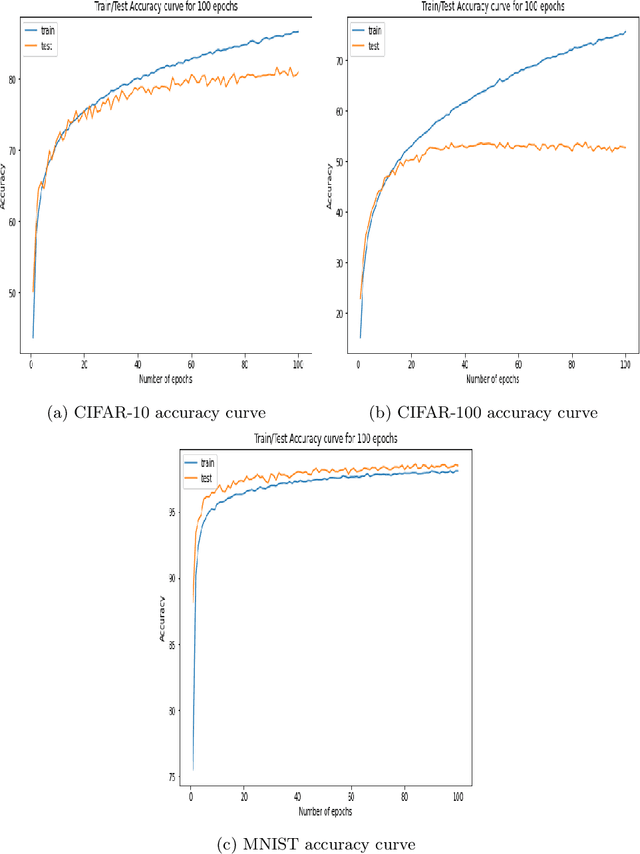
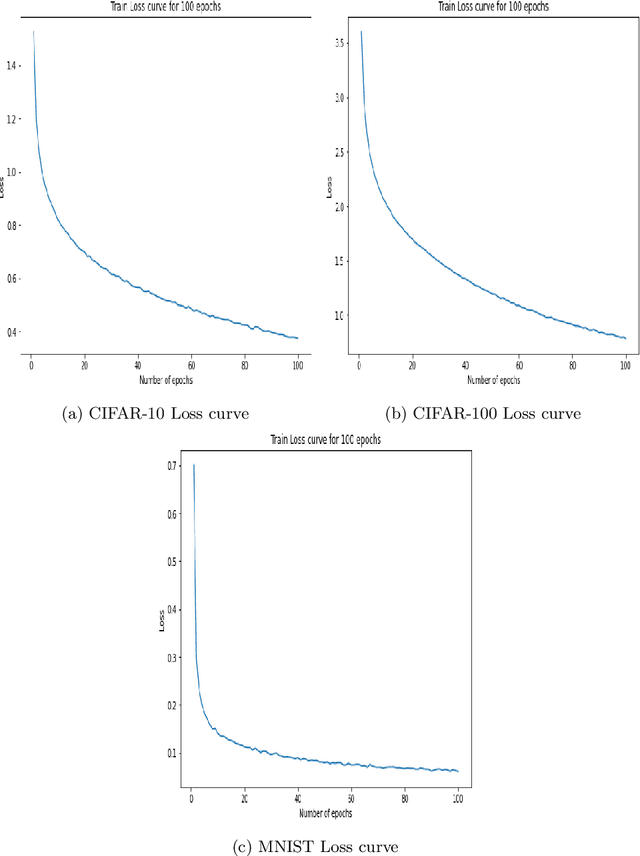
The Attention mechanism is the main component of the Transformer architecture, and since its introduction, it has led to significant advancements in Deep Learning that span many domains and multiple tasks. The Attention Mechanism was utilized in Computer Vision as the Vision Transformer ViT, and its usage has expanded into many tasks in the vision domain, such as classification, segmentation, object detection, and image generation. While this mechanism is very expressive and capable, it comes with the drawback of being computationally expensive and requiring datasets of considerable size for effective optimization. To address these shortcomings, many designs have been proposed in the literature to reduce the computational burden and alleviate the data size requirements. Examples of such attempts in the vision domain are the MLP-Mixer, the Conv-Mixer, the Perciver-IO, and many more. This paper introduces a new computational block as an alternative to the standard ViT block that reduces the compute burdens by replacing the normal Attention layers with a Network in Network structure that enhances the static approach of the MLP Mixer with a dynamic system of learning an element-wise gating function by a token mixing process. Extensive experimentation shows that the proposed design provides better performance than the baseline architectures on multiple datasets applied in the image classification task of the vision domain.
LLMs in Political Science: Heralding a New Era of Visual Analysis
Feb 29, 2024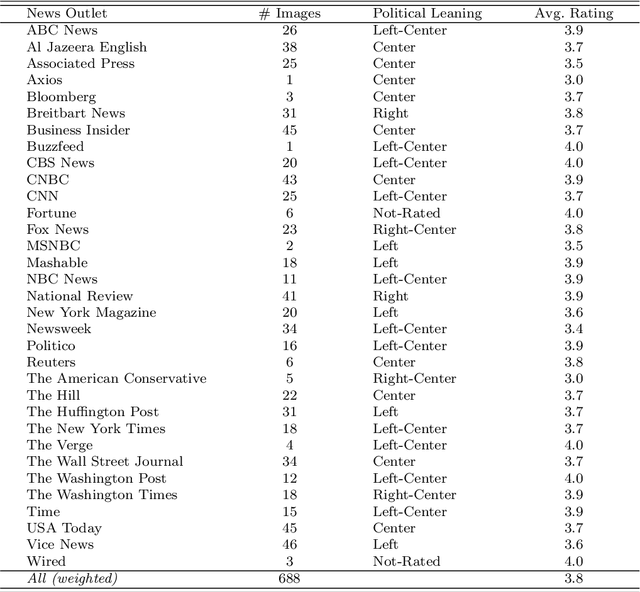

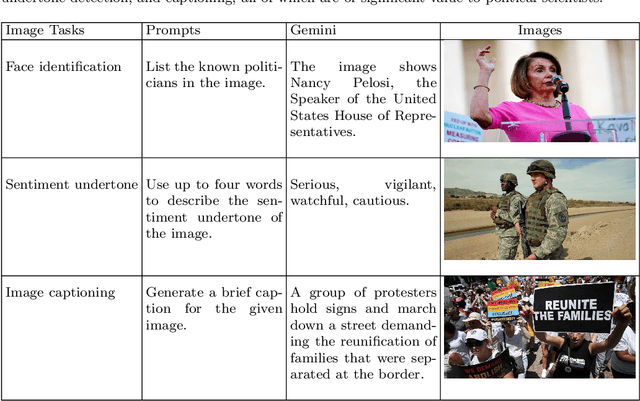
Interest is increasing among political scientists in leveraging the extensive information available in images. However, the challenge of interpreting these images lies in the need for specialized knowledge in computer vision and access to specialized hardware. As a result, image analysis has been limited to a relatively small group within the political science community. This landscape could potentially change thanks to the rise of large language models (LLMs). This paper aims to raise awareness of the feasibility of using Gemini for image content analysis. A retrospective analysis was conducted on a corpus of 688 images. Content reports were elicited from Gemini for each image and then manually evaluated by the authors. We find that Gemini is highly accurate in performing object detection, which is arguably the most common and fundamental task in image analysis for political scientists. Equally important, we show that it is easy to implement as the entire command consists of a single prompt in natural language; it is fast to run and should meet the time budget of most researchers; and it is free to use and does not require any specialized hardware. In addition, we illustrate how political scientists can leverage Gemini for other image understanding tasks, including face identification, sentiment analysis, and caption generation. Our findings suggest that Gemini and other similar LLMs have the potential to drastically stimulate and accelerate image research in political science and social sciences more broadly.
Unsupervised Learning of High-resolution Light Field Imaging via Beam Splitter-based Hybrid Lenses
Feb 29, 2024In this paper, we design a beam splitter-based hybrid light field imaging prototype to record 4D light field image and high-resolution 2D image simultaneously, and make a hybrid light field dataset. The 2D image could be considered as the high-resolution ground truth corresponding to the low-resolution central sub-aperture image of 4D light field image. Subsequently, we propose an unsupervised learning-based super-resolution framework with the hybrid light field dataset, which adaptively settles the light field spatial super-resolution problem with a complex degradation model. Specifically, we design two loss functions based on pre-trained models that enable the super-resolution network to learn the detailed features and light field parallax structure with only one ground truth. Extensive experiments demonstrate the same superiority of our approach with supervised learning-based state-of-the-art ones. To our knowledge, it is the first end-to-end unsupervised learning-based spatial super-resolution approach in light field imaging research, whose input is available from our beam splitter-based hybrid light field system. The hardware and software together may help promote the application of light field super-resolution to a great extent.
Universal Prompt Optimizer for Safe Text-to-Image Generation
Feb 16, 2024Text-to-Image (T2I) models have shown great performance in generating images based on textual prompts. However, these models are vulnerable to unsafe input to generate unsafe content like sexual, harassment and illegal-activity images. Existing studies based on image checker, model fine-tuning and embedding blocking are impractical in real-world applications. Hence, \textit{we propose the first universal prompt optimizer for safe T2I generation in black-box scenario}. We first construct a dataset consisting of toxic-clean prompt pairs by GPT-3.5 Turbo. To guide the optimizer to have the ability of converting toxic prompt to clean prompt while preserving semantic information, we design a novel reward function measuring toxicity and text alignment of generated images and train the optimizer through Proximal Policy Optimization. Experiments show that our approach can effectively reduce the likelihood of various T2I models in generating inappropriate images, with no significant impact on text alignment. It is also flexible to be combined with methods to achieve better performance.
Semi-weakly-supervised neural network training for medical image registration
Feb 16, 2024For training registration networks, weak supervision from segmented corresponding regions-of-interest (ROIs) have been proven effective for (a) supplementing unsupervised methods, and (b) being used independently in registration tasks in which unsupervised losses are unavailable or ineffective. This correspondence-informing supervision entails cost in annotation that requires significant specialised effort. This paper describes a semi-weakly-supervised registration pipeline that improves the model performance, when only a small corresponding-ROI-labelled dataset is available, by exploiting unlabelled image pairs. We examine two types of augmentation methods by perturbation on network weights and image resampling, such that consistency-based unsupervised losses can be applied on unlabelled data. The novel WarpDDF and RegCut approaches are proposed to allow commutative perturbation between an image pair and the predicted spatial transformation (i.e. respective input and output of registration networks), distinct from existing perturbation methods for classification or segmentation. Experiments using 589 male pelvic MR images, labelled with eight anatomical ROIs, show the improvement in registration performance and the ablated contributions from the individual strategies. Furthermore, this study attempts to construct one of the first computational atlases for pelvic structures, enabled by registering inter-subject MRs, and quantifies the significant differences due to the proposed semi-weak supervision with a discussion on the potential clinical use of example atlas-derived statistics.
Optical turbulence profiling at the Table Mountain Facility with the Laser Communication Relay Demonstration GEO downlink
Mar 07, 2024
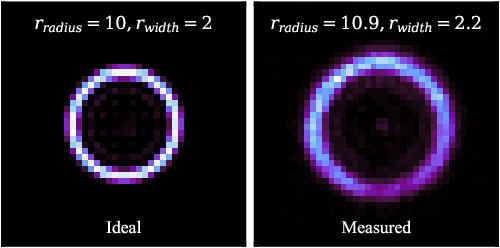
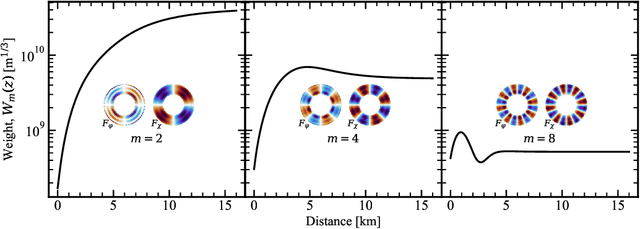
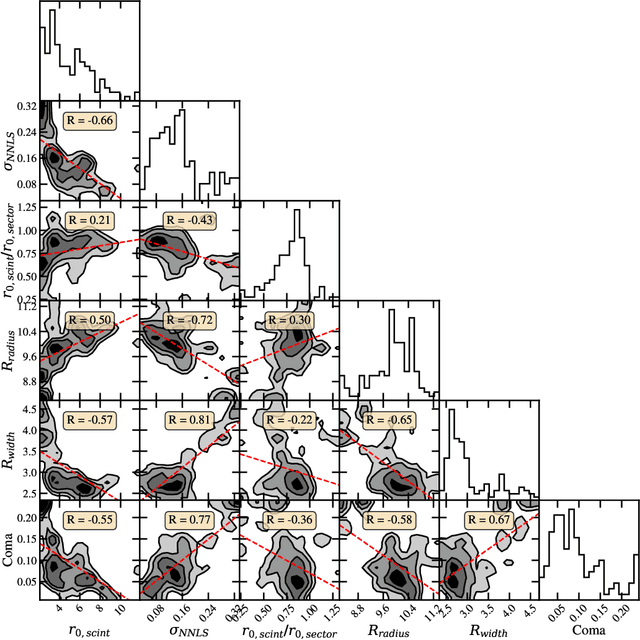
We present the first time the profile of atmospheric optical turbulence has been measured using the transmitted beam from a satellite laser communication terminal. A Ring Image Next Generation Scintillation Sensor (RINGSS) instrument for turbulence profiling, as described in Tokovinin (MNRAS, 502.1, 2021), was deployed at the NASA/Jet Propulsion Laboratory's Table Mountain Facility (TMF) in California. The optical turbulence profile was measured with the downlink optical beam from the Laser Communication Relay Demonstration (LCRD) Geostationary satellite. LCRD conducts links with the Optical Communication Telescope Laboratory ground station and the RINGSS instrument was co-located at TMF to conduct measurements. Turbulence profiles were measured at day and night and atmospheric coherence lengths were compared with other turbulence monitors such as a solar scintillometer and Polaris monitor. RINGSS sensitivity to boundary layer turbulence, a feature not provided by many profilers, is also shown to agree well with a boundary layer scintillometer at TMF. Diurnal evolution of optical turbulence and measured profiles are presented. The robust correlation of RINGSS with other turbulence monitors demonstrates the concept of free-space optical communications turbulence profiling, which could be adopted as a way to support optical ground stations in a future Geostationary feeder link network. These results also provide further evidence that RINGSS, a relatively new instrument concept, is effective even in strong daytime turbulence and with reasonable ground layer sensitivity.