 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep CSI Compression for Massive MIMO: A Self-information Model-driven Neural Network
Apr 25, 2022

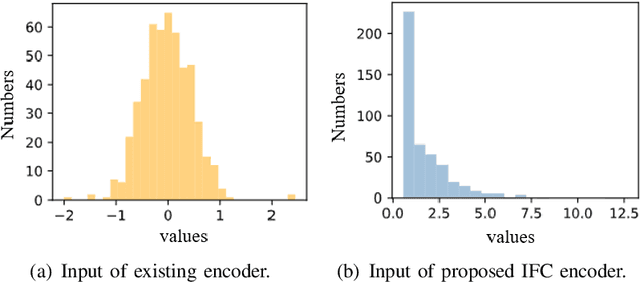
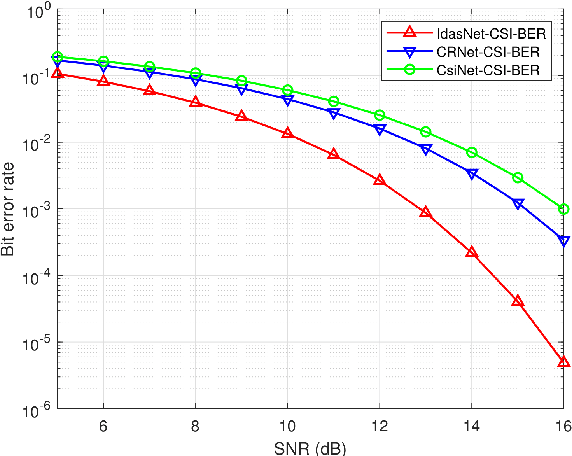
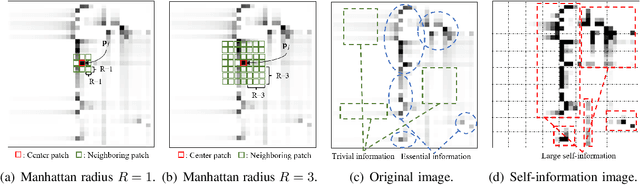
In order to fully exploit the advantages of massive multiple-input multiple-output (mMIMO), it is critical for the transmitter to accurately acquire the channel state information (CSI). Deep learning (DL)-based methods have been proposed for CSI compression and feedback to the transmitter. Although most existing DL-based methods consider the CSI matrix as an image, structural features of the CSI image are rarely exploited in neural network design. As such, we propose a model of self-information that dynamically measures the amount of information contained in each patch of a CSI image from the perspective of structural features. Then, by applying the self-information model, we propose a model-and-data-driven network for CSI compression and feedback, namely IdasNet. The IdasNet includes the design of a module of self-information deletion and selection (IDAS), an encoder of informative feature compression (IFC), and a decoder of informative feature recovery (IFR). In particular, the model-driven module of IDAS pre-compresses the CSI image by removing informative redundancy in terms of the self-information. The encoder of IFC then conducts feature compression to the pre-compressed CSI image and generates a feature codeword which contains two components, i.e., codeword values and position indices of the codeword values. Subsequently, the IFR decoder decouples the codeword values as well as position indices to recover the CSI image. Experimental results verify that the proposed IdasNet noticeably outperforms existing DL-based networks under various compression ratios while it has the number of network parameters reduced by orders-of-magnitude compared with various existing methods.
Does deep learning model calibration improve performance in class-imbalanced medical image classification?
Oct 11, 2021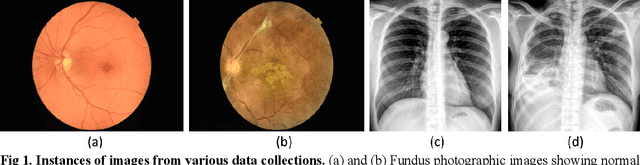
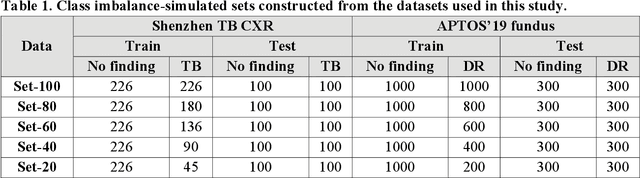
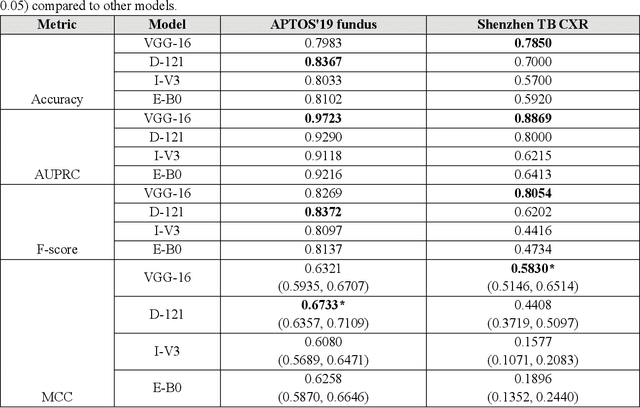
In medical image classification tasks, it is common to find that the number of normal samples far exceeds the number of abnormal samples. In such class-imbalanced situations, reliable training of deep neural networks continues to be a major challenge. Under these circumstances, the predicted class probabilities may be biased toward the majority class. Calibration has been suggested to alleviate some of these effects. However, there is insufficient analysis explaining when and whether calibrating a model would be beneficial in improving performance. In this study, we perform a systematic analysis of the effect of model calibration on its performance on two medical image modalities, namely, chest X-rays and fundus images, using various deep learning classifier backbones. For this, we study the following variations: (i) the degree of imbalances in the dataset used for training; (ii) calibration methods; and (iii) two classification thresholds, namely, default decision threshold of 0.5, and optimal threshold from precision-recall curves. Our results indicate that at the default operating threshold of 0.5, the performance achieved through calibration is significantly superior (p < 0.05) to using uncalibrated probabilities. However, at the PR-guided threshold, these gains are not significantly different (p > 0.05). This finding holds for both image modalities and at varying degrees of imbalance.
Using adversarial images to improve outcomes of federated learning for non-IID data
Jun 16, 2022

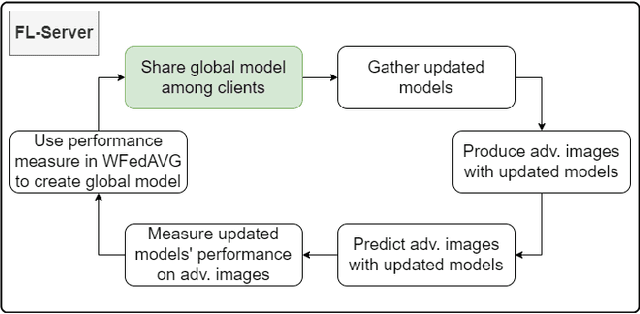
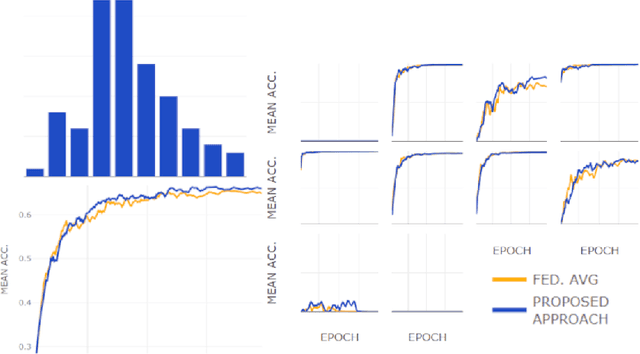
One of the important problems in federated learning is how to deal with unbalanced data. This contribution introduces a novel technique designed to deal with label skewed non-IID data, using adversarial inputs, created by the I-FGSM method. Adversarial inputs guide the training process and allow the Weighted Federated Averaging to give more importance to clients with 'selected' local label distributions. Experimental results, gathered from image classification tasks, for MNIST and CIFAR-10 datasets, are reported and analyzed.
Heredity-aware Child Face Image Generation with Latent Space Disentanglement
Aug 25, 2021



Generative adversarial networks have been widely used in image synthesis in recent years and the quality of the generated image has been greatly improved. However, the flexibility to control and decouple facial attributes (e.g., eyes, nose, mouth) is still limited. In this paper, we propose a novel approach, called ChildGAN, to generate a child's image according to the images of parents with heredity prior. The main idea is to disentangle the latent space of a pre-trained generation model and precisely control the face attributes of child images with clear semantics. We use distances between face landmarks as pseudo labels to figure out the most influential semantic vectors of the corresponding face attributes by calculating the gradient of latent vectors to pseudo labels. Furthermore, we disentangle the semantic vectors by weighting irrelevant features and orthogonalizing them with Schmidt Orthogonalization. Finally, we fuse the latent vector of the parents by leveraging the disentangled semantic vectors under the guidance of biological genetic laws. Extensive experiments demonstrate that our approach outperforms the existing methods with encouraging results.
MeshMAE: Masked Autoencoders for 3D Mesh Data Analysis
Jul 20, 2022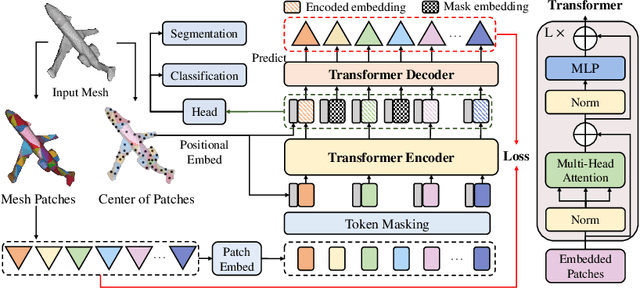
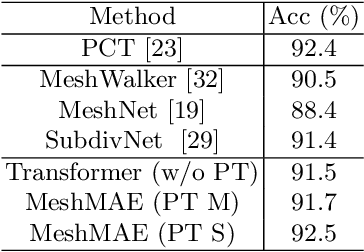
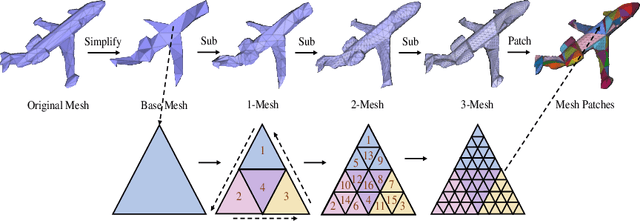
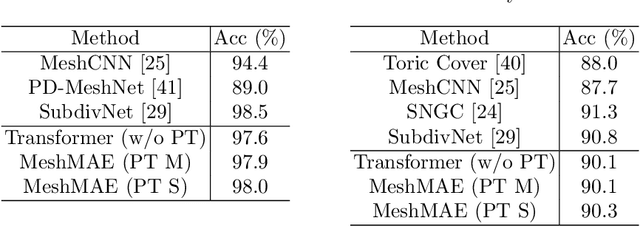
Recently, self-supervised pre-training has advanced Vision Transformers on various tasks w.r.t. different data modalities, e.g., image and 3D point cloud data. In this paper, we explore this learning paradigm for 3D mesh data analysis based on Transformers. Since applying Transformer architectures to new modalities is usually non-trivial, we first adapt Vision Transformer to 3D mesh data processing, i.e., Mesh Transformer. In specific, we divide a mesh into several non-overlapping local patches with each containing the same number of faces and use the 3D position of each patch's center point to form positional embeddings. Inspired by MAE, we explore how pre-training on 3D mesh data with the Transformer-based structure benefits downstream 3D mesh analysis tasks. We first randomly mask some patches of the mesh and feed the corrupted mesh into Mesh Transformers. Then, through reconstructing the information of masked patches, the network is capable of learning discriminative representations for mesh data. Therefore, we name our method MeshMAE, which can yield state-of-the-art or comparable performance on mesh analysis tasks, i.e., classification and segmentation. In addition, we also conduct comprehensive ablation studies to show the effectiveness of key designs in our method.
A Spatial Guided Self-supervised Clustering Network for Medical Image Segmentation
Jul 11, 2021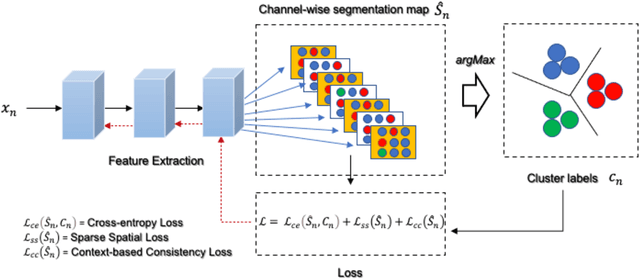
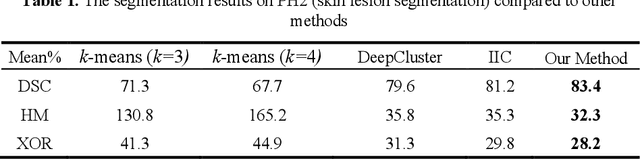
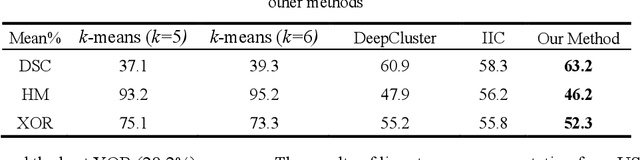

The segmentation of medical images is a fundamental step in automated clinical decision support systems. Existing medical image segmentation methods based on supervised deep learning, however, remain problematic because of their reliance on large amounts of labelled training data. Although medical imaging data repositories continue to expand, there has not been a commensurate increase in the amount of annotated data. Hence, we propose a new spatial guided self-supervised clustering network (SGSCN) for medical image segmentation, where we introduce multiple loss functions designed to aid in grouping image pixels that are spatially connected and have similar feature representations. It iteratively learns feature representations and clustering assignment of each pixel in an end-to-end fashion from a single image. We also propose a context-based consistency loss that better delineates the shape and boundaries of image regions. It enforces all the pixels belonging to a cluster to be spatially close to the cluster centre. We evaluated our method on 2 public medical image datasets and compared it to existing conventional and self-supervised clustering methods. Experimental results show that our method was most accurate for medical image segmentation.
Neglectable effect of brain MRI data prepreprocessing for tumor segmentation
Apr 11, 2022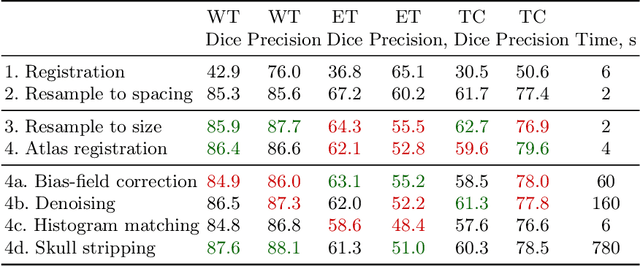
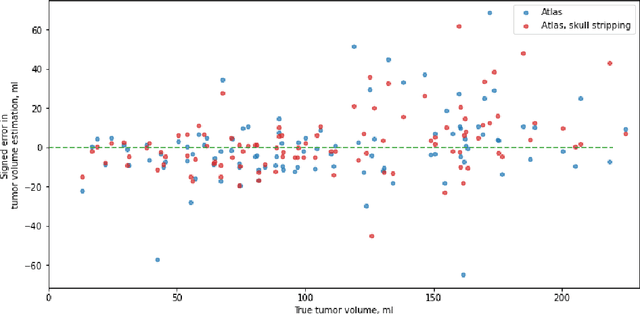

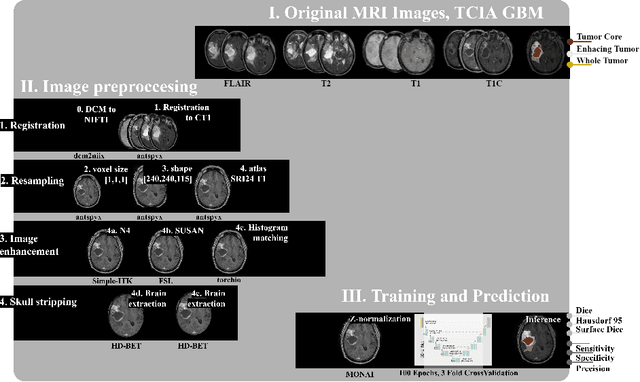
Magnetic resonance imaging (MRI) data is heterogeneous due to the differences in device manufacturers, scanning protocols, and inter-subject variability. A conventional way to mitigate MR image heterogeneity is to apply preprocessing transformations, such as anatomy alignment, voxel resampling, signal intensity equalization, image denoising, and localization of regions of interest (ROI). Although preprocessing pipeline standardizes image appearance, its influence on the quality of image segmentation and other downstream tasks on deep neural networks (DNN) has never been rigorously studied. Here we report a comprehensive study of multimodal MRI brain cancer image segmentation on TCIA-GBM open-source dataset. Our results demonstrate that most popular standardization steps add no value to artificial neural network performance; moreover, preprocessing can hamper model performance. We suggest that image intensity normalization approaches do not contribute to model accuracy because of the reduction of signal variance with image standardization. Finally, we show the contribution of scull-stripping in data preprocessing is almost negligible if measured in terms of clinically relevant metrics. We show that the only essential transformation for accurate analysis is the unification of voxel spacing across the dataset. In contrast, anatomy alignment in form of non-rigid atlas registration is not necessary and most intensity equalization steps do not improve model productiveness.
Image Comes Dancing with Collaborative Parsing-Flow Video Synthesis
Oct 28, 2021
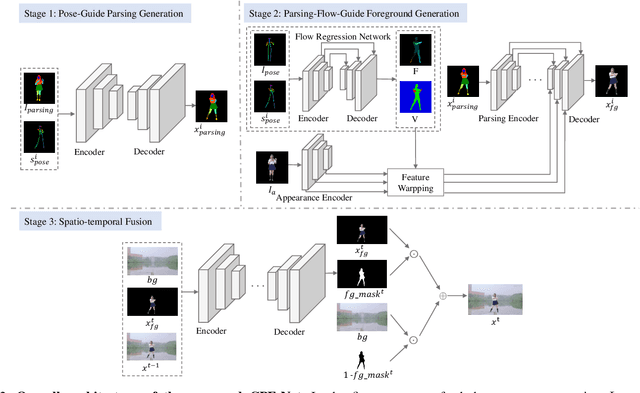


Transferring human motion from a source to a target person poses great potential in computer vision and graphics applications. A crucial step is to manipulate sequential future motion while retaining the appearance characteristic.Previous work has either relied on crafted 3D human models or trained a separate model specifically for each target person, which is not scalable in practice.This work studies a more general setting, in which we aim to learn a single model to parsimoniously transfer motion from a source video to any target person given only one image of the person, named as Collaborative Parsing-Flow Network (CPF-Net). The paucity of information regarding the target person makes the task particularly challenging to faithfully preserve the appearance in varying designated poses. To address this issue, CPF-Net integrates the structured human parsing and appearance flow to guide the realistic foreground synthesis which is merged into the background by a spatio-temporal fusion module. In particular, CPF-Net decouples the problem into stages of human parsing sequence generation, foreground sequence generation and final video generation. The human parsing generation stage captures both the pose and the body structure of the target. The appearance flow is beneficial to keep details in synthesized frames. The integration of human parsing and appearance flow effectively guides the generation of video frames with realistic appearance. Finally, the dedicated designed fusion network ensure the temporal coherence. We further collect a large set of human dancing videos to push forward this research field. Both quantitative and qualitative results show our method substantially improves over previous approaches and is able to generate appealing and photo-realistic target videos given any input person image. All source code and dataset will be released at https://github.com/xiezhy6/CPF-Net.
Scalable Kernel-Based Minimum Mean Square Error Estimator for Accelerated Image Error Concealment
May 23, 2022

Error concealment is of great importance for block-based video systems, such as DVB or video streaming services. In this paper, we propose a novel scalable spatial error concealment algorithm that aims at obtaining high quality reconstructions with reduced computational burden. The proposed technique exploits the excellent reconstructing abilities of the kernel-based minimum mean square error K-MMSE estimator. We propose to decompose this approach into a set of hierarchically stacked layers. The first layer performs the basic reconstruction that the subsequent layers can eventually refine. In addition, we design a layer management mechanism, based on profiles, that dynamically adapts the use of higher layers to the visual complexity of the area being reconstructed. The proposed technique outperforms other state-of-the-art algorithms and produces high quality reconstructions, equivalent to K-MMSE, while requiring around one tenth of its computational time.
Patch2CAD: Patchwise Embedding Learning for In-the-Wild Shape Retrieval from a Single Image
Aug 20, 2021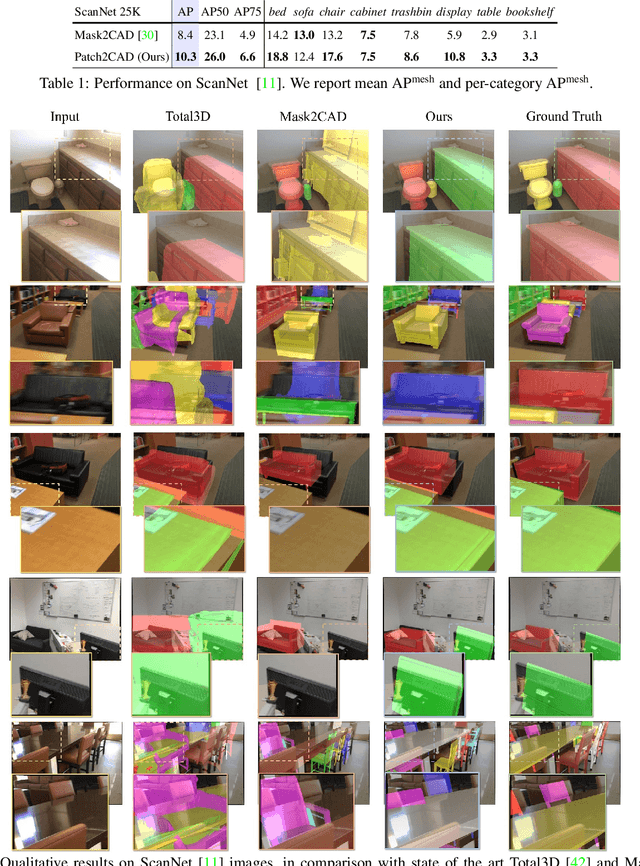
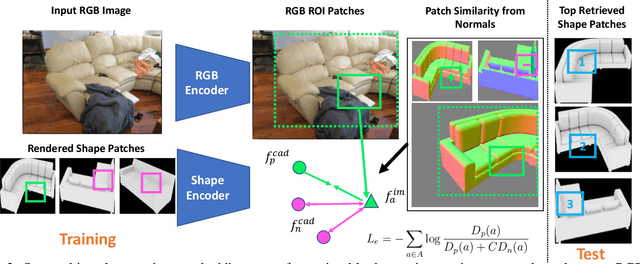
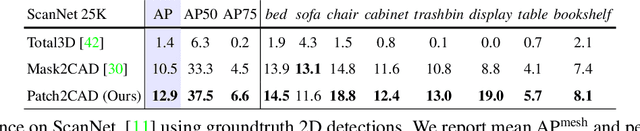
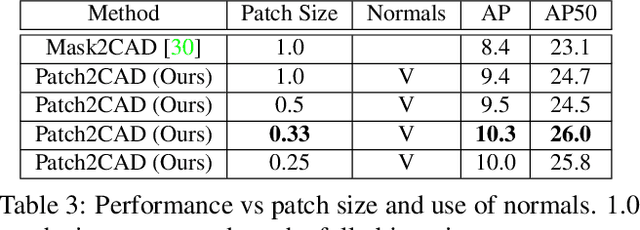
3D perception of object shapes from RGB image input is fundamental towards semantic scene understanding, grounding image-based perception in our spatially 3-dimensional real-world environments. To achieve a mapping between image views of objects and 3D shapes, we leverage CAD model priors from existing large-scale databases, and propose a novel approach towards constructing a joint embedding space between 2D images and 3D CAD models in a patch-wise fashion -- establishing correspondences between patches of an image view of an object and patches of CAD geometry. This enables part similarity reasoning for retrieving similar CADs to a new image view without exact matches in the database. Our patch embedding provides more robust CAD retrieval for shape estimation in our end-to-end estimation of CAD model shape and pose for detected objects in a single input image. Experiments on in-the-wild, complex imagery from ScanNet show that our approach is more robust than state of the art in real-world scenarios without any exact CAD matches.