 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Active Inference Agents for Heterogeneous and Lifelong Federated Learning
Oct 09, 2024Handling heterogeneity and unpredictability are two core problems in pervasive computing. The challenge is to seamlessly integrate devices with varying computational resources in a dynamic environment to form a cohesive system that can fulfill the needs of all participants. Existing work on systems that adapt to changing requirements typically focuses on optimizing individual variables or low-level Service Level Objectives (SLOs), such as constraining the usage of specific resources. While low-level control mechanisms permit fine-grained control over a system, they introduce considerable complexity, particularly in dynamic environments. To this end, we propose drawing from Active Inference (AIF), a neuroscientific framework for designing adaptive agents. Specifically, we introduce a conceptual agent for heterogeneous pervasive systems that permits setting global systems constraints as high-level SLOs. Instead of manually setting low-level SLOs, the system finds an equilibrium that can adapt to environmental changes. We demonstrate the viability of AIF agents with an extensive experiment design, using heterogeneous and lifelong federated learning as an application scenario. We conduct our experiments on a physical testbed of devices with different resource types and vendor specifications. The results provide convincing evidence that an AIF agent can adapt a system to environmental changes. In particular, the AIF agent can balance competing SLOs in resource heterogeneous environments to ensure up to 98% fulfillment rate.
Introducing Federated Learning into Internet of Things ecosystems -- preliminary considerations
Jul 15, 2022
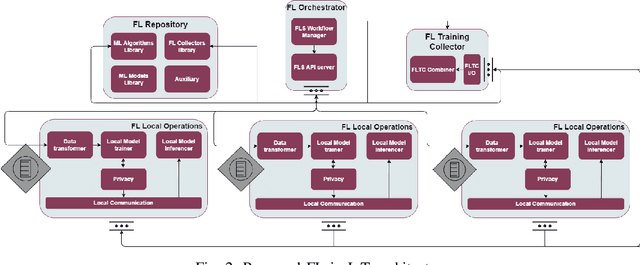
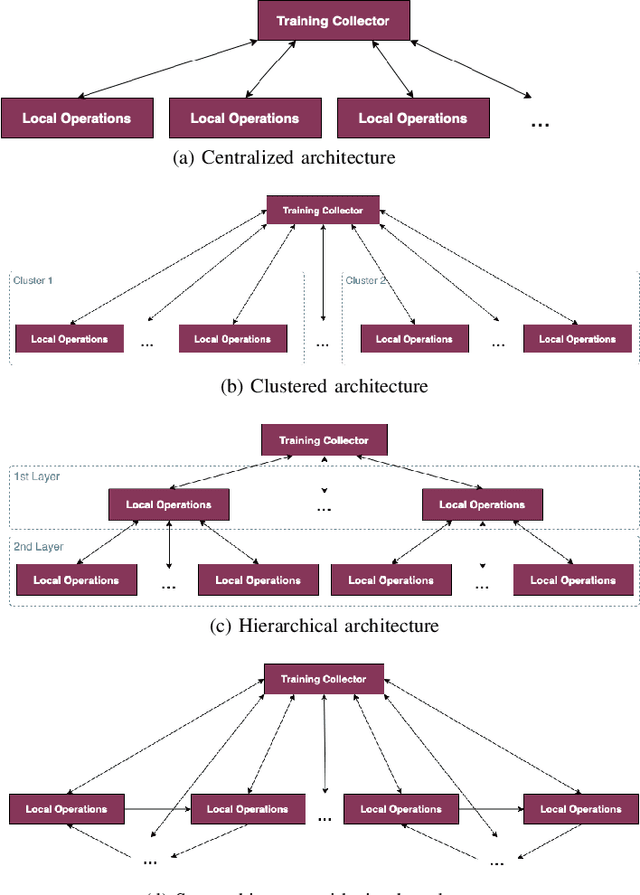
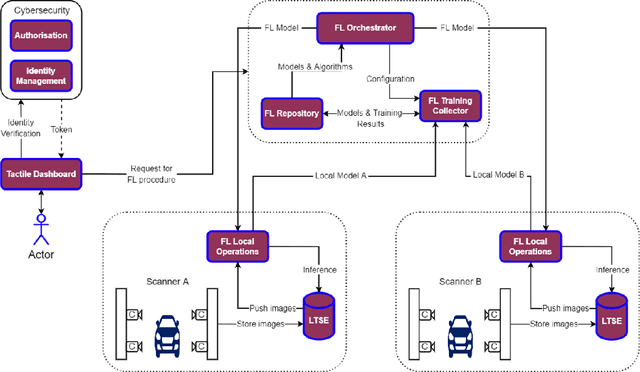
Federated learning (FL) was proposed to facilitate the training of models in a distributed environment. It supports the protection of (local) data privacy and uses local resources for model training. Until now, the majority of research has been devoted to "core issues", such as adaptation of machine learning algorithms to FL, data privacy protection, or dealing with the effects of uneven data distribution between clients. This contribution is anchored in a practical use case, where FL is to be actually deployed within an Internet of Things ecosystem. Hence, somewhat different issues that need to be considered, beyond popular considerations found in the literature, are identified. Moreover, an architecture that enables the building of flexible, and adaptable, FL solutions is introduced.
Using adversarial images to improve outcomes of federated learning for non-IID data
Jun 16, 2022

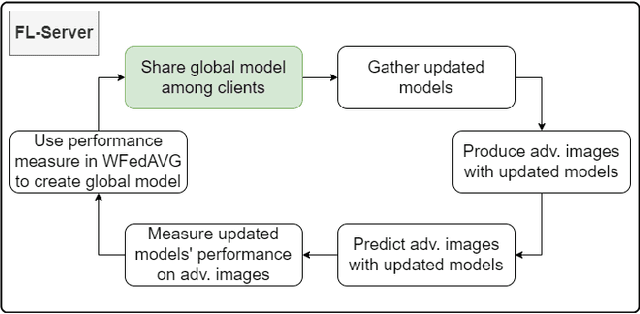
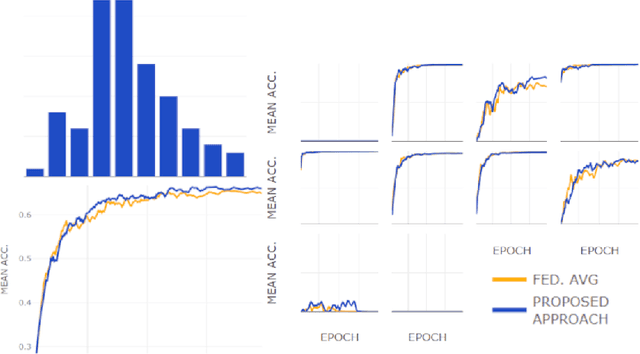
One of the important problems in federated learning is how to deal with unbalanced data. This contribution introduces a novel technique designed to deal with label skewed non-IID data, using adversarial inputs, created by the I-FGSM method. Adversarial inputs guide the training process and allow the Weighted Federated Averaging to give more importance to clients with 'selected' local label distributions. Experimental results, gathered from image classification tasks, for MNIST and CIFAR-10 datasets, are reported and analyzed.