 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3DA: Benchmark for Unsupervised Domain Adaptation in 3D Medical Image Segmentation
Feb 24, 2025



Domain shift presents a significant challenge in applying Deep Learning to the segmentation of 3D medical images from sources like Magnetic Resonance Imaging (MRI) and Computed Tomography (CT). Although numerous Domain Adaptation methods have been developed to address this issue, they are often evaluated under impractical data shift scenarios. Specifically, the medical imaging datasets used are often either private, too small for robust training and evaluation, or limited to single or synthetic tasks. To overcome these limitations, we introduce a M3DA /"mEd@/ benchmark comprising four publicly available, multiclass segmentation datasets. We have designed eight domain pairs featuring diverse and practically relevant distribution shifts. These include inter-modality shifts between MRI and CT and intra-modality shifts among various MRI acquisition parameters, different CT radiation doses, and presence/absence of contrast enhancement in images. Within the proposed benchmark, we evaluate more than ten existing domain adaptation methods. Our results show that none of them can consistently close the performance gap between the domains. For instance, the most effective method reduces the performance gap by about 62% across the tasks. This highlights the need for developing novel domain adaptation algorithms to enhance the robustness and scalability of deep learning models in medical imaging. We made our M3DA benchmark publicly available: https://github.com/BorisShirokikh/M3DA.
The Effect of Lossy Compression on 3D Medical Images Segmentation with Deep Learning
Sep 25, 2024



Image compression is a critical tool in decreasing the cost of storage and improving the speed of transmission over the internet. While deep learning applications for natural images widely adopts the usage of lossy compression techniques, it is not widespread for 3D medical images. Using three CT datasets (17 tasks) and one MRI dataset (3 tasks) we demonstrate that lossy compression up to 20 times have no negative impact on segmentation quality with deep neural networks (DNN). In addition, we demonstrate the ability of DNN models trained on compressed data to predict on uncompressed data and vice versa with no quality deterioration.
Anatomical Positional Embeddings
Sep 16, 2024We propose a self-supervised model producing 3D anatomical positional embeddings (APE) of individual medical image voxels. APE encodes voxels' anatomical closeness, i.e., voxels of the same organ or nearby organs always have closer positional embeddings than the voxels of more distant body parts. In contrast to the existing models of anatomical positional embeddings, our method is able to efficiently produce a map of voxel-wise embeddings for a whole volumetric input image, which makes it an optimal choice for different downstream applications. We train our APE model on 8400 publicly available CT images of abdomen and chest regions. We demonstrate its superior performance compared with the existing models on anatomical landmark retrieval and weakly-supervised few-shot localization of 13 abdominal organs. As a practical application, we show how to cheaply train APE to crop raw CT images to different anatomical regions of interest with 0.99 recall, while reducing the image volume by 10-100 times. The code and the pre-trained APE model are available at https://github.com/mishgon/ape .
The impact of deep learning aid on the workload and interpretation accuracy of radiologists on chest computed tomography: a cross-over reader study
Jun 12, 2024



Interpretation of chest computed tomography (CT) is time-consuming. Previous studies have measured the time-saving effect of using a deep-learning-based aid (DLA) for CT interpretation. We evaluated the joint impact of a multi-pathology DLA on the time and accuracy of radiologists' reading. 40 radiologists were randomly split into three experimental arms: control (10), who interpret studies without assistance; informed group (10), who were briefed about DLA pathologies, but performed readings without it; and the experimental group (20), who interpreted half studies with DLA, and half without. Every arm used the same 200 CT studies retrospectively collected from BIMCV-COVID19 dataset; each radiologist provided readings for 20 CT studies. We compared interpretation time, and accuracy of participants diagnostic report with respect to 12 pathological findings. Mean reading time per study was 15.6 minutes [SD 8.5] in the control arm, 13.2 minutes [SD 8.7] in the informed arm, 14.4 [SD 10.3] in the experimental arm without DLA, and 11.4 minutes [SD 7.8] in the experimental arm with DLA. Mean sensitivity and specificity were 41.5 [SD 30.4], 86.8 [SD 28.3] in the control arm; 53.5 [SD 22.7], 92.3 [SD 9.4] in the informed non-assisted arm; 63.2 [SD 16.4], 92.3 [SD 8.2] in the experimental arm without DLA; and 91.6 [SD 7.2], 89.9 [SD 6.0] in the experimental arm with DLA. DLA speed up interpretation time per study by 2.9 minutes (CI95 [1.7, 4.3], p<0.0005), increased sensitivity by 28.4 (CI95 [23.4, 33.4], p<0.0005), and decreased specificity by 2.4 (CI95 [0.6, 4.3], p=0.13). Of 20 radiologists in the experimental arm, 16 have improved reading time and sensitivity, two improved their time with a marginal drop in sensitivity, and two participants improved sensitivity with increased time. Overall, DLA introduction decreased reading time by 20.6%.
Redesigning Out-of-Distribution Detection on 3D Medical Images
Aug 07, 2023



Detecting out-of-distribution (OOD) samples for trusted medical image segmentation remains a significant challenge. The critical issue here is the lack of a strict definition of abnormal data, which often results in artificial problem settings without measurable clinical impact. In this paper, we redesign the OOD detection problem according to the specifics of volumetric medical imaging and related downstream tasks (e.g., segmentation). We propose using the downstream model's performance as a pseudometric between images to define abnormal samples. This approach enables us to weigh different samples based on their performance impact without an explicit ID/OOD distinction. We incorporate this weighting in a new metric called Expected Performance Drop (EPD). EPD is our core contribution to the new problem design, allowing us to rank methods based on their clinical impact. We demonstrate the effectiveness of EPD-based evaluation in 11 CT and MRI OOD detection challenges.
Limitations of Out-of-Distribution Detection in 3D Medical Image Segmentation
Jun 23, 2023



Deep Learning models perform unreliably when the data comes from a distribution different from the training one. In critical applications such as medical imaging, out-of-distribution (OOD) detection methods help to identify such data samples, preventing erroneous predictions. In this paper, we further investigate the OOD detection effectiveness when applied to 3D medical image segmentation. We design several OOD challenges representing clinically occurring cases and show that none of these methods achieve acceptable performance. Methods not dedicated to segmentation severely fail to perform in the designed setups; their best mean false positive rate at 95% true positive rate (FPR) is 0.59. Segmentation-dedicated ones still achieve suboptimal performance, with the best mean FPR of 0.31 (lower is better). To indicate this suboptimality, we develop a simple method called Intensity Histogram Features (IHF), which performs comparable or better in the same challenges, with a mean FPR of 0.25. Our findings highlight the limitations of the existing OOD detection methods on 3D medical images and present a promising avenue for improving them. To facilitate research in this area, we release the designed challenges as a publicly available benchmark and formulate practical criteria to test the OOD detection generalization beyond the suggested benchmark. We also propose IHF as a solid baseline to contest the emerging methods.
Solving Sample-Level Out-of-Distribution Detection on 3D Medical Images
Dec 13, 2022



Deep Learning (DL) models tend to perform poorly when the data comes from a distribution different from the training one. In critical applications such as medical imaging, out-of-distribution (OOD) detection helps to identify such data samples, increasing the model's reliability. Recent works have developed DL-based OOD detection that achieves promising results on 2D medical images. However, scaling most of these approaches on 3D images is computationally intractable. Furthermore, the current 3D solutions struggle to achieve acceptable results in detecting even synthetic OOD samples. Such limited performance might indicate that DL often inefficiently embeds large volumetric images. We argue that using the intensity histogram of the original CT or MRI scan as embedding is descriptive enough to run OOD detection. Therefore, we propose a histogram-based method that requires no DL and achieves almost perfect results in this domain. Our proposal is supported two-fold. We evaluate the performance on the publicly available datasets, where our method scores 1.0 AUROC in most setups. And we score second in the Medical Out-of-Distribution challenge without fine-tuning and exploiting task-specific knowledge. Carefully discussing the limitations, we conclude that our method solves the sample-level OOD detection on 3D medical images in the current setting.
Exploring Structure-Wise Uncertainty for 3D Medical Image Segmentation
Nov 01, 2022



When applying a Deep Learning model to medical images, it is crucial to estimate the model uncertainty. Voxel-wise uncertainty is a useful visual marker for human experts and could be used to improve the model's voxel-wise output, such as segmentation. Moreover, uncertainty provides a solid foundation for out-of-distribution (OOD) detection, improving the model performance on the image-wise level. However, one of the frequent tasks in medical imaging is the segmentation of distinct, local structures such as tumors or lesions. Here, the structure-wise uncertainty allows more precise operations than image-wise and more semantic-aware than voxel-wise. The way to produce uncertainty for individual structures remains poorly explored. We propose a framework to measure the structure-wise uncertainty and evaluate the impact of OOD data on the model performance. Thus, we identify the best UE method to improve the segmentation quality. The proposed framework is tested on three datasets with the tumor segmentation task: LIDC-IDRI, LiTS, and a private one with multiple brain metastases cases.
Neglectable effect of brain MRI data prepreprocessing for tumor segmentation
Apr 11, 2022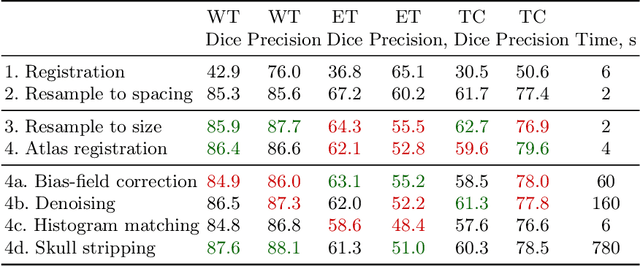
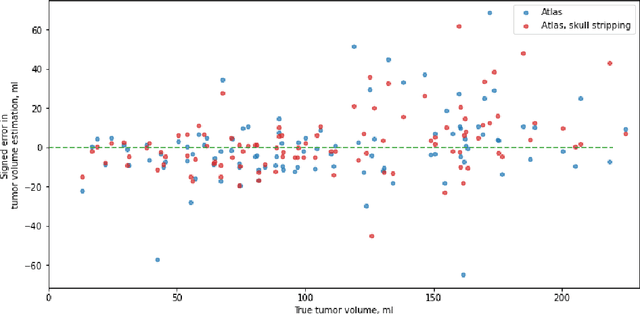

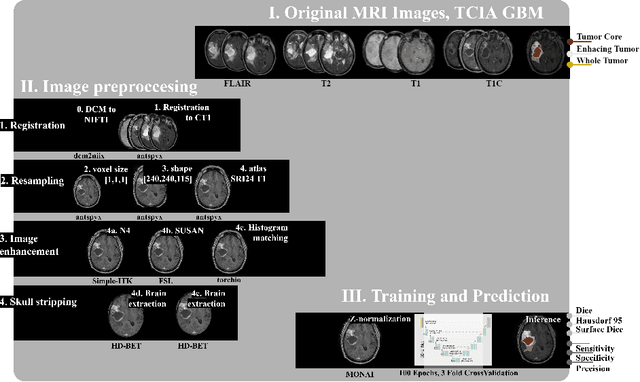
Magnetic resonance imaging (MRI) data is heterogeneous due to the differences in device manufacturers, scanning protocols, and inter-subject variability. A conventional way to mitigate MR image heterogeneity is to apply preprocessing transformations, such as anatomy alignment, voxel resampling, signal intensity equalization, image denoising, and localization of regions of interest (ROI). Although preprocessing pipeline standardizes image appearance, its influence on the quality of image segmentation and other downstream tasks on deep neural networks (DNN) has never been rigorously studied. Here we report a comprehensive study of multimodal MRI brain cancer image segmentation on TCIA-GBM open-source dataset. Our results demonstrate that most popular standardization steps add no value to artificial neural network performance; moreover, preprocessing can hamper model performance. We suggest that image intensity normalization approaches do not contribute to model accuracy because of the reduction of signal variance with image standardization. Finally, we show the contribution of scull-stripping in data preprocessing is almost negligible if measured in terms of clinically relevant metrics. We show that the only essential transformation for accurate analysis is the unification of voxel spacing across the dataset. In contrast, anatomy alignment in form of non-rigid atlas registration is not necessary and most intensity equalization steps do not improve model productiveness.
Adaptation to CT Reconstruction Kernels by Enforcing Cross-domain Feature Maps Consistency
Mar 28, 2022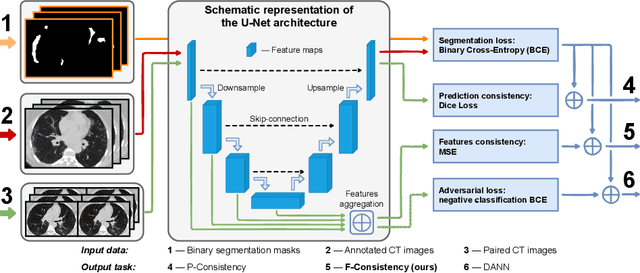
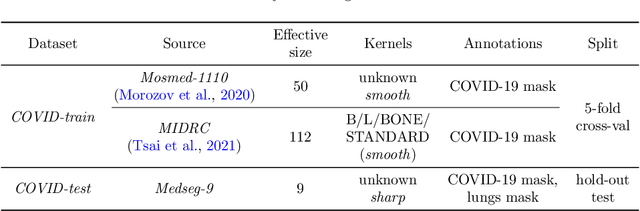


Deep learning methods provide significant assistance in analyzing coronavirus disease (COVID-19) in chest computed tomography (CT) images, including identification, severity assessment, and segmentation. Although the earlier developed methods address the lack of data and specific annotations, the current goal is to build a robust algorithm for clinical use, having a larger pool of available data. With the larger datasets, the domain shift problem arises, affecting the performance of methods on the unseen data. One of the critical sources of domain shift in CT images is the difference in reconstruction kernels used to generate images from the raw data (sinograms). In this paper, we show a decrease in the COVID-19 segmentation quality of the model trained on the smooth and tested on the sharp reconstruction kernels. Furthermore, we compare several domain adaptation approaches to tackle the problem, such as task-specific augmentation and unsupervised adversarial learning. Finally, we propose the unsupervised adaptation method, called F-Consistency, that outperforms the previous approaches. Our method exploits a set of unlabeled CT image pairs which differ only in reconstruction kernels within every pair. It enforces the similarity of the network hidden representations (feature maps) by minimizing mean squared error (MSE) between paired feature maps. We show our method achieving 0.64 Dice Score on the test dataset with unseen sharp kernels, compared to the 0.56 Dice Score of the baseline model. Moreover, F-Consistency scores 0.80 Dice Score between predictions on the paired images, which almost doubles the baseline score of 0.46 and surpasses the other methods. We also show F-Consistency to better generalize on the unseen kernels and without the specific semantic content, e.g., presence of the COVID-19 lesions.