 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adversarial Ensemble Training by Jointly Learning Label Dependencies and Member Models
Jul 04, 2022
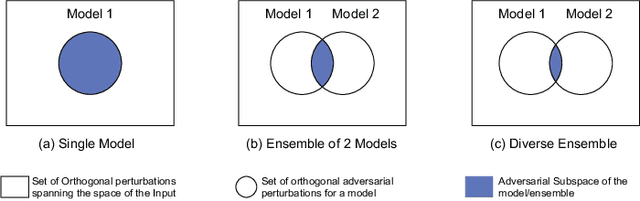
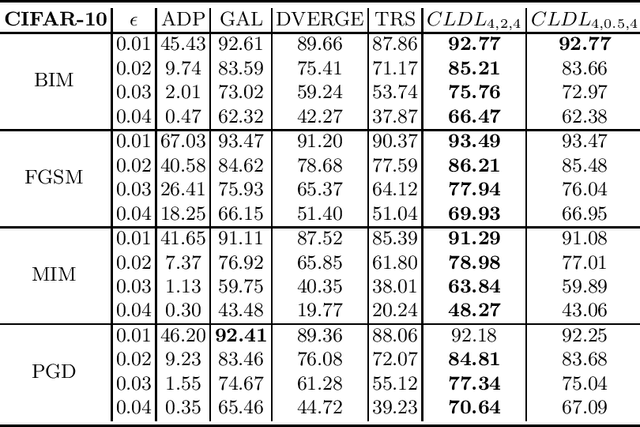
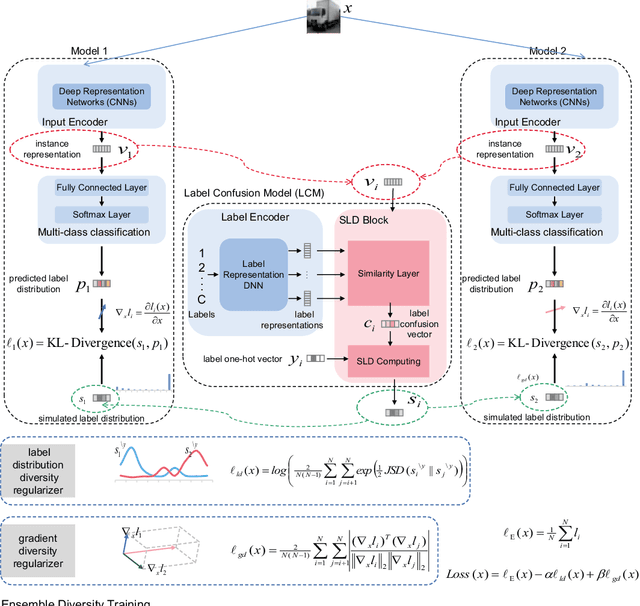
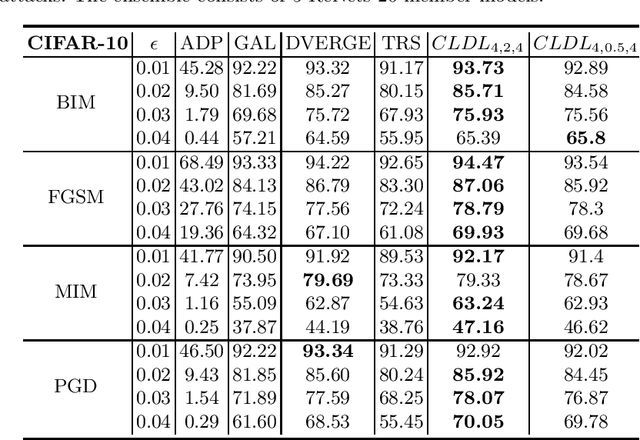
Training an ensemble of different sub-models has empirically proven to be an effective strategy to improve deep neural networks' adversarial robustness. Current ensemble training methods for image recognition usually encode the image labels by one-hot vectors, which neglect dependency relationships between the labels. Here we propose a novel adversarial ensemble training approach to jointly learn the label dependencies and the member models. Our approach adaptively exploits the learned label dependencies to promote the diversity of the member models. We test our approach on widely used datasets MNIST, FasionMNIST, and CIFAR-10. Results show that our approach is more robust against black-box attacks compared with the state-of-the-art methods. Our code is available at https://github.com/ZJLAB-AMMI/LSD.
Continual learning benefits from multiple sleep mechanisms: NREM, REM, and Synaptic Downscaling
Sep 09, 2022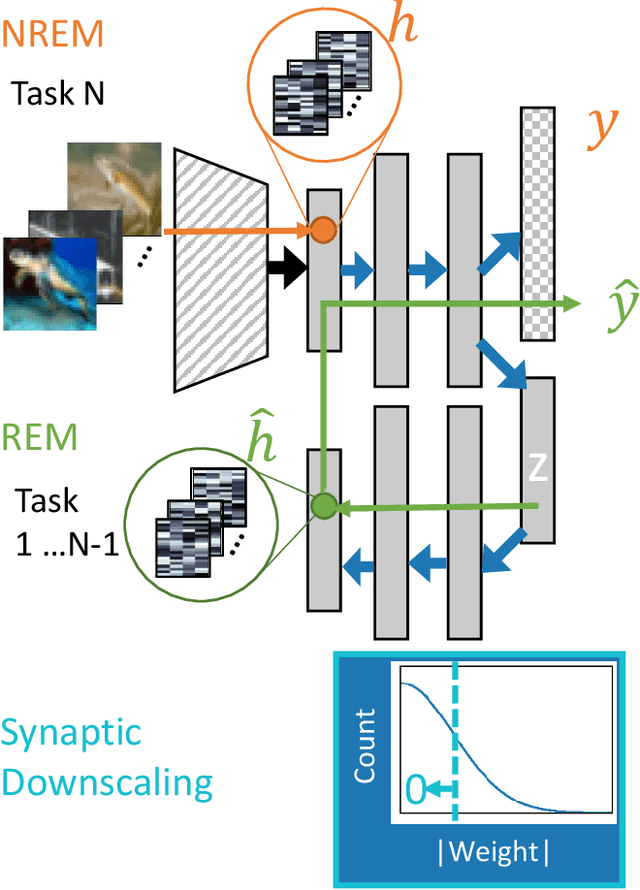
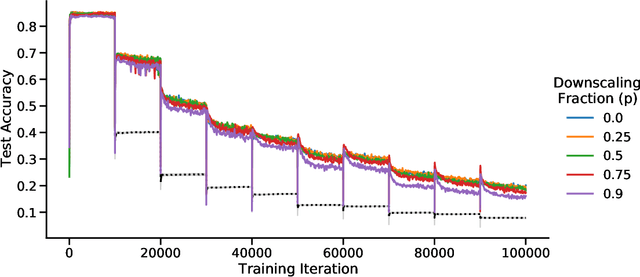
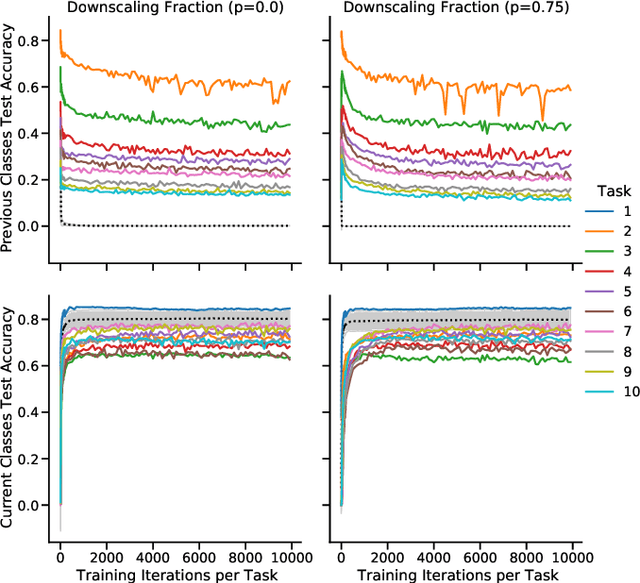
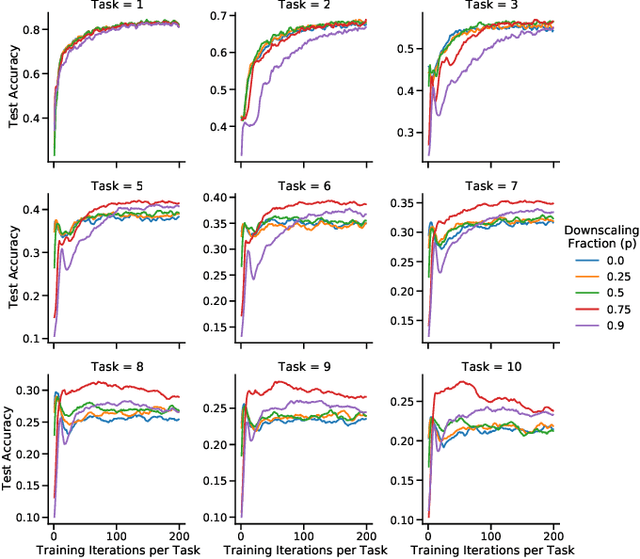
Learning new tasks and skills in succession without losing prior learning (i.e., catastrophic forgetting) is a computational challenge for both artificial and biological neural networks, yet artificial systems struggle to achieve parity with their biological analogues. Mammalian brains employ numerous neural operations in support of continual learning during sleep. These are ripe for artificial adaptation. Here, we investigate how modeling three distinct components of mammalian sleep together affects continual learning in artificial neural networks: (1) a veridical memory replay process observed during non-rapid eye movement (NREM) sleep; (2) a generative memory replay process linked to REM sleep; and (3) a synaptic downscaling process which has been proposed to tune signal-to-noise ratios and support neural upkeep. We find benefits from the inclusion of all three sleep components when evaluating performance on a continual learning CIFAR-100 image classification benchmark. Maximum accuracy improved during training and catastrophic forgetting was reduced during later tasks. While some catastrophic forgetting persisted over the course of network training, higher levels of synaptic downscaling lead to better retention of early tasks and further facilitated the recovery of early task accuracy during subsequent training. One key takeaway is that there is a trade-off at hand when considering the level of synaptic downscaling to use - more aggressive downscaling better protects early tasks, but less downscaling enhances the ability to learn new tasks. Intermediate levels can strike a balance with the highest overall accuracies during training. Overall, our results both provide insight into how to adapt sleep components to enhance artificial continual learning systems and highlight areas for future neuroscientific sleep research to further such systems.
Towards Adversarial Purification using Denoising AutoEncoders
Aug 29, 2022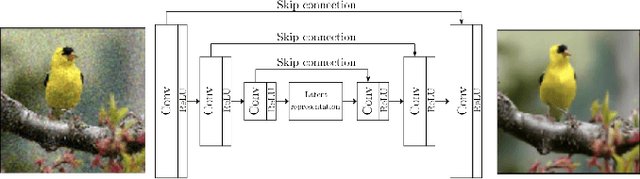
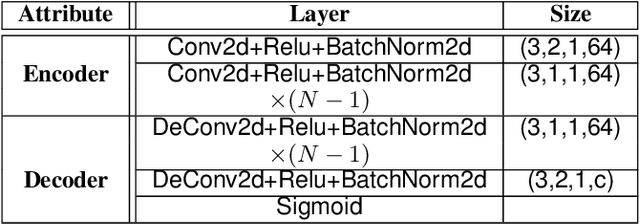
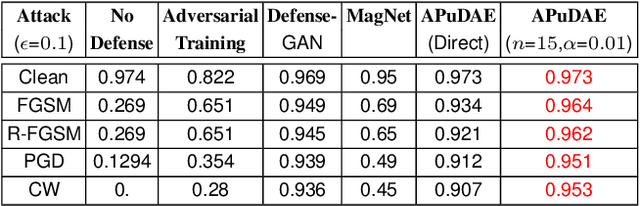

With the rapid advancement and increased use of deep learning models in image identification, security becomes a major concern to their deployment in safety-critical systems. Since the accuracy and robustness of deep learning models are primarily attributed from the purity of the training samples, therefore the deep learning architectures are often susceptible to adversarial attacks. Adversarial attacks are often obtained by making subtle perturbations to normal images, which are mostly imperceptible to humans, but can seriously confuse the state-of-the-art machine learning models. We propose a framework, named APuDAE, leveraging Denoising AutoEncoders (DAEs) to purify these samples by using them in an adaptive way and thus improve the classification accuracy of the target classifier networks that have been attacked. We also show how using DAEs adaptively instead of using them directly, improves classification accuracy further and is more robust to the possibility of designing adaptive attacks to fool them. We demonstrate our results over MNIST, CIFAR-10, ImageNet dataset and show how our framework (APuDAE) provides comparable and in most cases better performance to the baseline methods in purifying adversaries. We also design adaptive attack specifically designed to attack our purifying model and demonstrate how our defense is robust to that.
Temporally Adjustable Longitudinal Fluid-Attenuated Inversion Recovery MRI Estimation / Synthesis for Multiple Sclerosis
Sep 09, 2022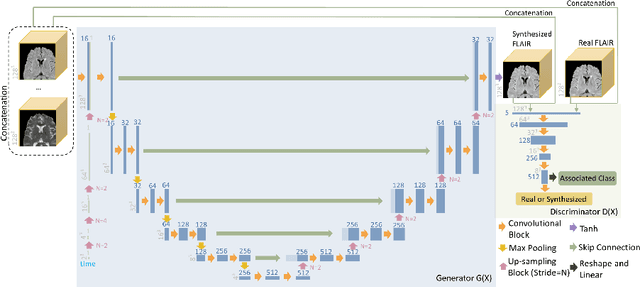
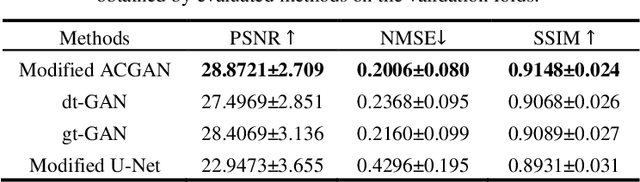
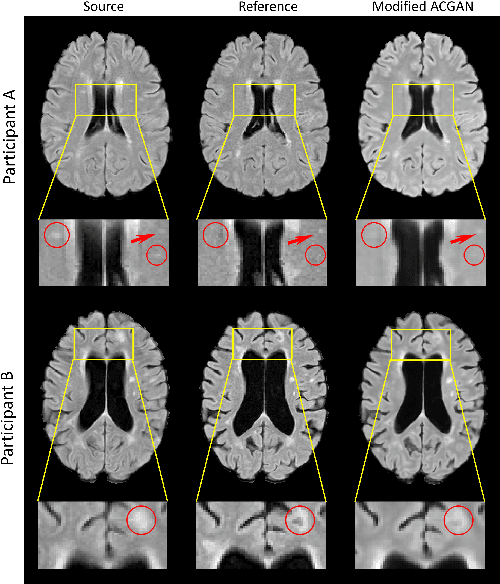
Multiple Sclerosis (MS) is a chronic progressive neurological disease characterized by the development of lesions in the white matter of the brain. T2-fluid-attenuated inversion recovery (FLAIR) brain magnetic resonance imaging (MRI) provides superior visualization and characterization of MS lesions, relative to other MRI modalities. Longitudinal brain FLAIR MRI in MS, involving repetitively imaging a patient over time, provides helpful information for clinicians towards monitoring disease progression. Predicting future whole brain MRI examinations with variable time lag has only been attempted in limited applications, such as healthy aging and structural degeneration in Alzheimer's Disease. In this article, we present novel modifications to deep learning architectures for MS FLAIR image synthesis, in order to support prediction of longitudinal images in a flexible continuous way. This is achieved with learned transposed convolutions, which support modelling time as a spatially distributed array with variable temporal properties at different spatial locations. Thus, this approach can theoretically model spatially-specific time-dependent brain development, supporting the modelling of more rapid growth at appropriate physical locations, such as the site of an MS brain lesion. This approach also supports the clinician user to define how far into the future a predicted examination should target. Accurate prediction of future rounds of imaging can inform clinicians of potentially poor patient outcomes, which may be able to contribute to earlier treatment and better prognoses. Four distinct deep learning architectures have been developed. The ISBI2015 longitudinal MS dataset was used to validate and compare our proposed approaches. Results demonstrate that a modified ACGAN achieves the best performance and reduces variability in model accuracy.
Reconstruct Face from Features Using GAN Generator as a Distribution Constraint
Jun 09, 2022
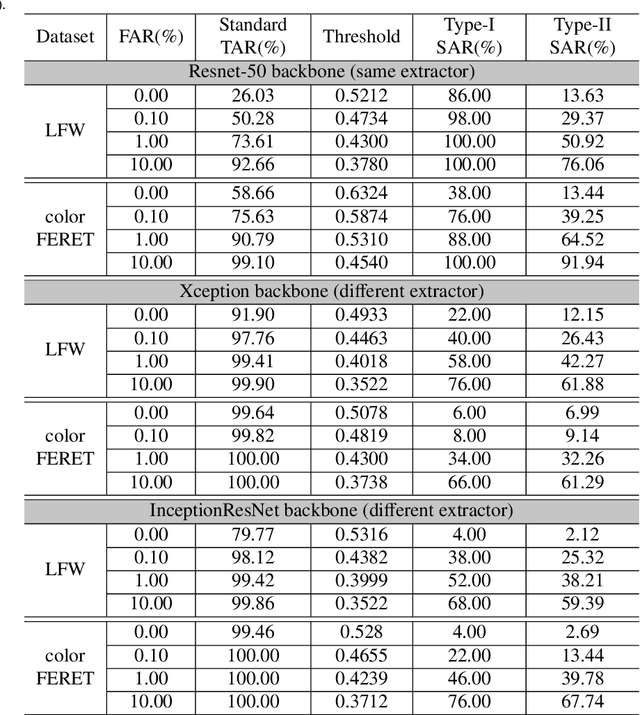
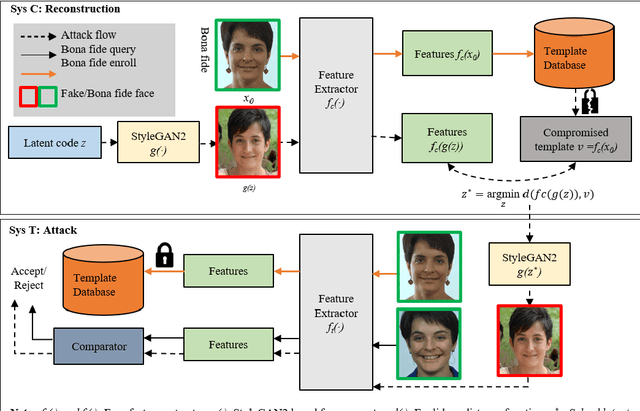
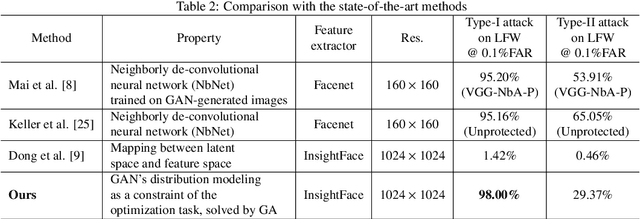
Face recognition based on the deep convolutional neural networks (CNN) shows superior accuracy performance attributed to the high discriminative features extracted. Yet, the security and privacy of the extracted features from deep learning models (deep features) have been often overlooked. This paper proposes the reconstruction of face images from deep features without accessing the CNN network configurations as a constrained optimization problem. Such optimization minimizes the distance between the features extracted from the original face image and the reconstructed face image. Instead of directly solving the optimization problem in the image space, we innovatively reformulate the problem by looking for a latent vector of a GAN generator, then use it to generate the face image. The GAN generator serves as a dual role in this novel framework, i.e., face distribution constraint of the optimization goal and a face generator. On top of the novel optimization task, we also propose an attack pipeline to impersonate the target user based on the generated face image. Our results show that the generated face images can achieve a state-of-the-art successful attack rate of 98.0\% on LFW under type-I attack @ FAR of 0.1\%. Our work sheds light on the biometric deployment to meet the privacy-preserving and security policies.
Meta-Learning of NAS for Few-shot Learning in Medical Image Applications
Mar 16, 2022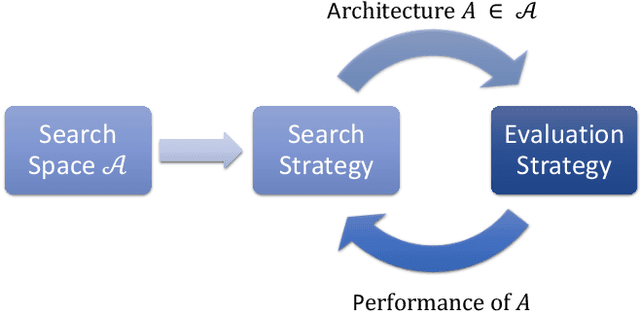
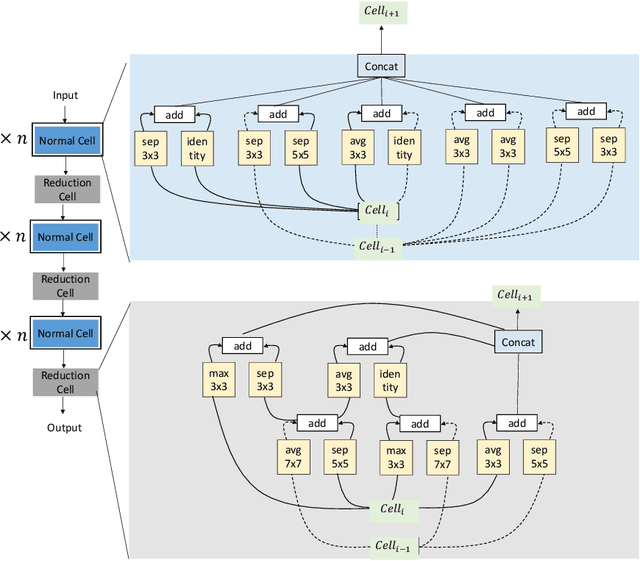
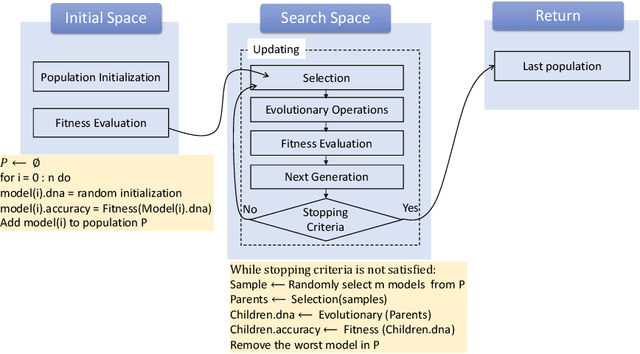
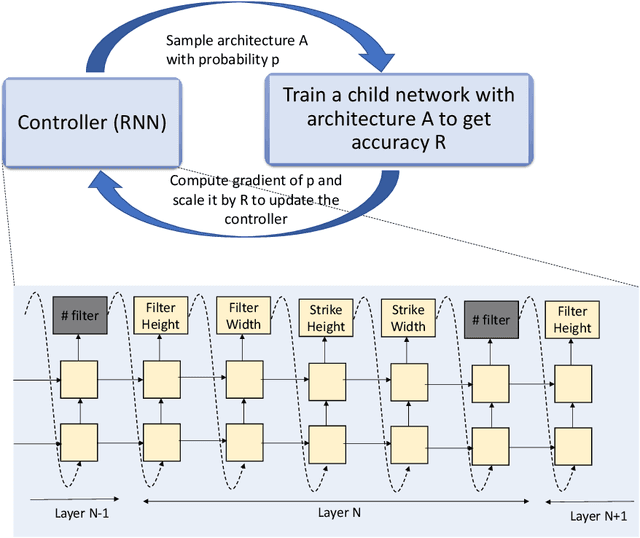
Deep learning methods have been successful in solving tasks in machine learning and have made breakthroughs in many sectors owing to their ability to automatically extract features from unstructured data. However, their performance relies on manual trial-and-error processes for selecting an appropriate network architecture, hyperparameters for training, and pre-/post-procedures. Even though it has been shown that network architecture plays a critical role in learning feature representation feature from data and the final performance, searching for the best network architecture is computationally intensive and heavily relies on researchers' experience. Automated machine learning (AutoML) and its advanced techniques i.e. Neural Architecture Search (NAS) have been promoted to address those limitations. Not only in general computer vision tasks, but NAS has also motivated various applications in multiple areas including medical imaging. In medical imaging, NAS has significant progress in improving the accuracy of image classification, segmentation, reconstruction, and more. However, NAS requires the availability of large annotated data, considerable computation resources, and pre-defined tasks. To address such limitations, meta-learning has been adopted in the scenarios of few-shot learning and multiple tasks. In this book chapter, we first present a brief review of NAS by discussing well-known approaches in search space, search strategy, and evaluation strategy. We then introduce various NAS approaches in medical imaging with different applications such as classification, segmentation, detection, reconstruction, etc. Meta-learning in NAS for few-shot learning and multiple tasks is then explained. Finally, we describe several open problems in NAS.
ICECAP: Information Concentrated Entity-aware Image Captioning
Aug 04, 2021
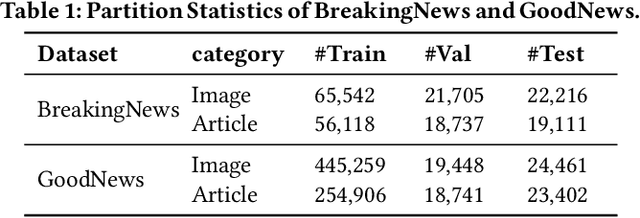
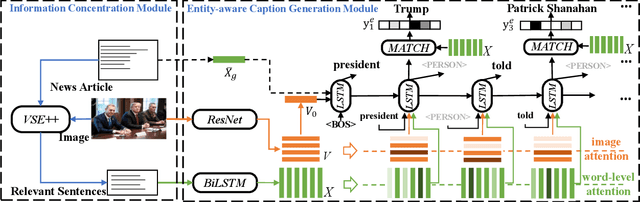
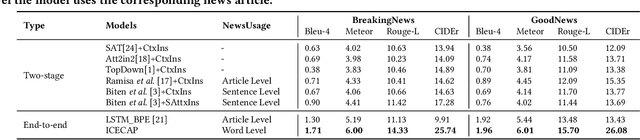
Most current image captioning systems focus on describing general image content, and lack background knowledge to deeply understand the image, such as exact named entities or concrete events. In this work, we focus on the entity-aware news image captioning task which aims to generate informative captions by leveraging the associated news articles to provide background knowledge about the target image. However, due to the length of news articles, previous works only employ news articles at the coarse article or sentence level, which are not fine-grained enough to refine relevant events and choose named entities accurately. To overcome these limitations, we propose an Information Concentrated Entity-aware news image CAPtioning (ICECAP) model, which progressively concentrates on relevant textual information within the corresponding news article from the sentence level to the word level. Our model first creates coarse concentration on relevant sentences using a cross-modality retrieval model and then generates captions by further concentrating on relevant words within the sentences. Extensive experiments on both BreakingNews and GoodNews datasets demonstrate the effectiveness of our proposed method, which outperforms other state-of-the-arts. The code of ICECAP is publicly available at https://github.com/HAWLYQ/ICECAP.
Deep-Learning-Based Single-Image Height Reconstruction from Very-High-Resolution SAR Intensity Data
Nov 03, 2021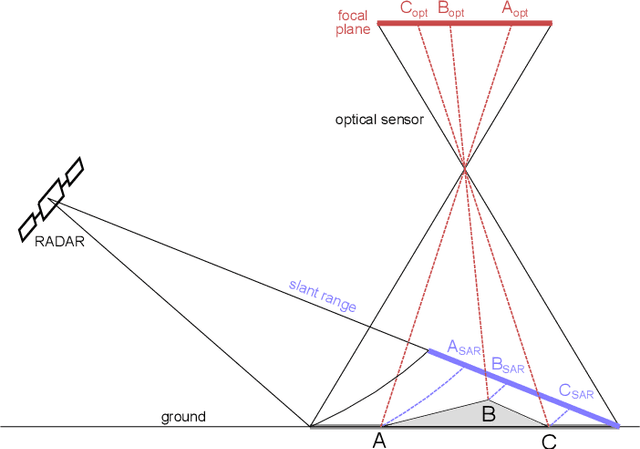
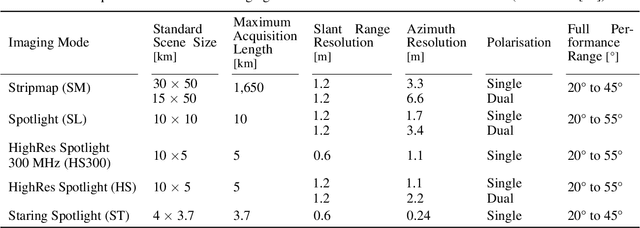
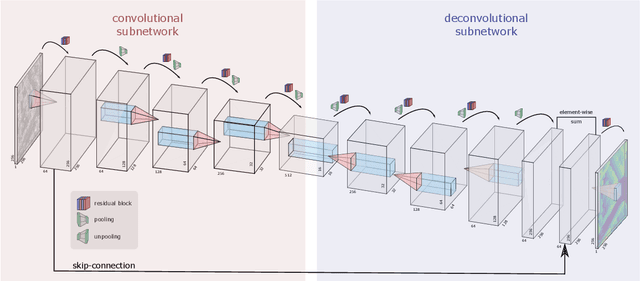
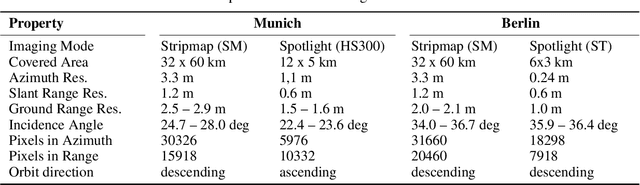
Originally developed in fields such as robotics and autonomous driving with image-based navigation in mind, deep learning-based single-image depth estimation (SIDE) has found great interest in the wider image analysis community. Remote sensing is no exception, as the possibility to estimate height maps from single aerial or satellite imagery bears great potential in the context of topographic reconstruction. A few pioneering investigations have demonstrated the general feasibility of single image height prediction from optical remote sensing images and motivate further studies in that direction. With this paper, we present the first-ever demonstration of deep learning-based single image height prediction for the other important sensor modality in remote sensing: synthetic aperture radar (SAR) data. Besides the adaptation of a convolutional neural network (CNN) architecture for SAR intensity images, we present a workflow for the generation of training data, and extensive experimental results for different SAR imaging modes and test sites. Since we put a particular emphasis on transferability, we are able to confirm that deep learning-based single-image height estimation is not only possible, but also transfers quite well to unseen data, even if acquired by different imaging modes and imaging parameters.
Towards Unbiased Label Distribution Learning for Facial Pose Estimation Using Anisotropic Spherical Gaussian
Aug 19, 2022
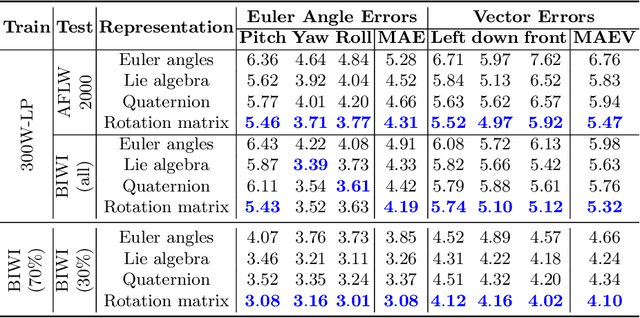
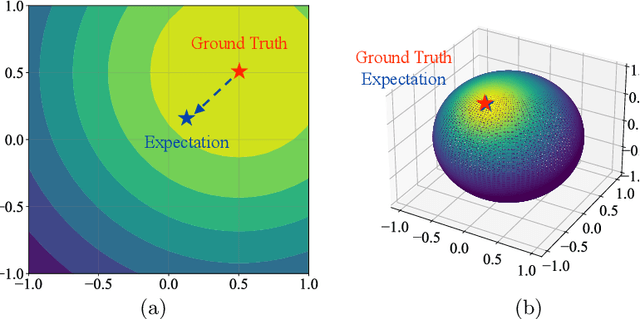
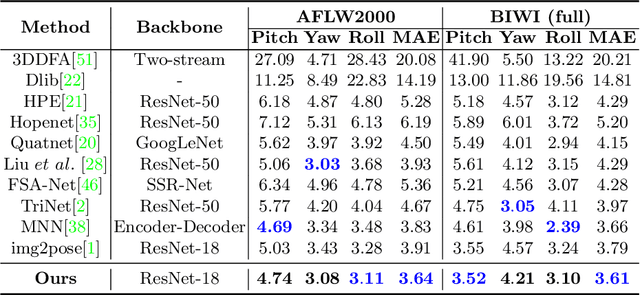
Facial pose estimation refers to the task of predicting face orientation from a single RGB image. It is an important research topic with a wide range of applications in computer vision. Label distribution learning (LDL) based methods have been recently proposed for facial pose estimation, which achieve promising results. However, there are two major issues in existing LDL methods. First, the expectations of label distributions are biased, leading to a biased pose estimation. Second, fixed distribution parameters are applied for all learning samples, severely limiting the model capability. In this paper, we propose an Anisotropic Spherical Gaussian (ASG)-based LDL approach for facial pose estimation. In particular, our approach adopts the spherical Gaussian distribution on a unit sphere which constantly generates unbiased expectation. Meanwhile, we introduce a new loss function that allows the network to learn the distribution parameter for each learning sample flexibly. Extensive experimental results show that our method sets new state-of-the-art records on AFLW2000 and BIWI datasets.
SCSNet: An Efficient Paradigm for Learning Simultaneously Image Colorization and Super-Resolution
Jan 12, 2022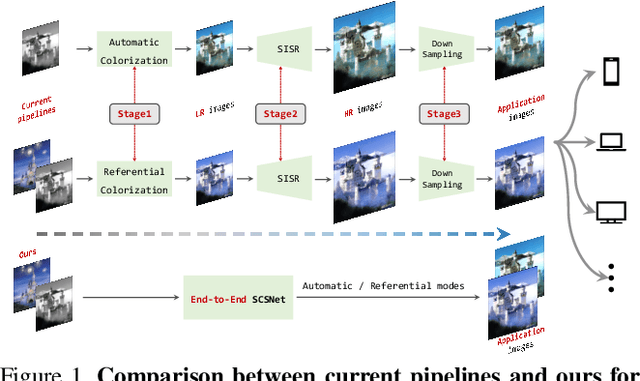
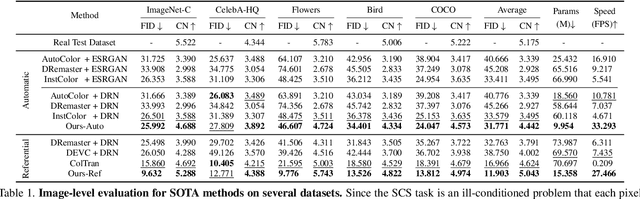

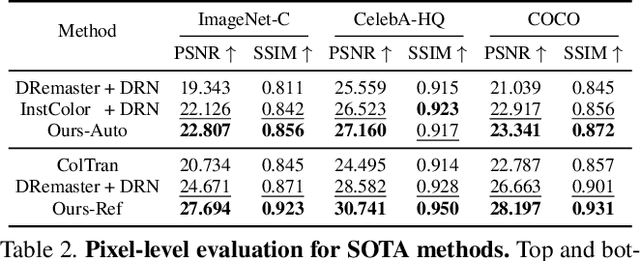
In the practical application of restoring low-resolution gray-scale images, we generally need to run three separate processes of image colorization, super-resolution, and dows-sampling operation for the target device. However, this pipeline is redundant and inefficient for the independent processes, and some inner features could have been shared. Therefore, we present an efficient paradigm to perform {S}imultaneously Image {C}olorization and {S}uper-resolution (SCS) and propose an end-to-end SCSNet to achieve this goal. The proposed method consists of two parts: colorization branch for learning color information that employs the proposed plug-and-play \emph{Pyramid Valve Cross Attention} (PVCAttn) module to aggregate feature maps between source and reference images; and super-resolution branch for integrating color and texture information to predict target images, which uses the designed \emph{Continuous Pixel Mapping} (CPM) module to predict high-resolution images at continuous magnification. Furthermore, our SCSNet supports both automatic and referential modes that is more flexible for practical application. Abundant experiments demonstrate the superiority of our method for generating authentic images over state-of-the-art methods, e.g., averagely decreasing FID by 1.8$\downarrow$ and 5.1 $\downarrow$ compared with current best scores for automatic and referential modes, respectively, while owning fewer parameters (more than $\times$2$\downarrow$) and faster running speed (more than $\times$3$\uparrow$).