 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPAARS: Safer RL Policy Alignment through Abstract Exploration and Refined Exploitation of Action Space
Mar 11, 2026Offline-to-online reinforcement learning (RL) offers a promising paradigm for robotics by pre-training policies on safe, offline demonstrations and fine-tuning them via online interaction. However, a fundamental challenge remains: how to safely explore online without deviating from the behavioral support of the offline data? While recent methods leverage conditional variational autoencoders (CVAEs) to bound exploration within a latent space, they inherently suffer from an exploitation gap -- a performance ceiling imposed by the decoder's reconstruction loss. We introduce SPAARS, a curriculum learning framework that initially constrains exploration to the low-dimensional latent manifold for sample-efficient, safe behavioral improvement, then seamlessly transfers control to the raw action space, bypassing the decoder bottleneck. SPAARS has two instantiations: the CVAE-based variant requires only unordered (s,a) pairs and no trajectory segmentation; SPAARS-SUPE pairs SPAARS with OPAL temporal skill pretraining for stronger exploration structure at the cost of requiring trajectory chunks. We prove an upper bound on the exploitation gap using the Performance Difference Lemma, establish that latent-space policy gradients achieve provable variance reduction over raw-space exploration, and show that concurrent behavioral cloning during the latent phase directly controls curriculum transition stability. Empirically, SPAARS-SUPE achieves 0.825 normalized return on kitchen-mixed-v0 versus 0.75 for SUPE, with 5x better sample efficiency; standalone SPAARS achieves 92.7 and 102.9 normalized return on hopper-medium-v2 and walker2d-medium-v2 respectively, surpassing IQL baselines of 66.3 and 78.3 respectively, confirming the utility of the unordered-pair CVAE instantiation.
DiffClone: Enhanced Behaviour Cloning in Robotics with Diffusion-Driven Policy Learning
Jan 17, 2024



Robot learning tasks are extremely compute-intensive and hardware-specific. Thus the avenues of tackling these challenges, using a diverse dataset of offline demonstrations that can be used to train robot manipulation agents, is very appealing. The Train-Offline-Test-Online (TOTO) Benchmark provides a well-curated open-source dataset for offline training comprised mostly of expert data and also benchmark scores of the common offline-RL and behaviour cloning agents. In this paper, we introduce DiffClone, an offline algorithm of enhanced behaviour cloning agent with diffusion-based policy learning, and measured the efficacy of our method on real online physical robots at test time. This is also our official submission to the Train-Offline-Test-Online (TOTO) Benchmark Challenge organized at NeurIPS 2023. We experimented with both pre-trained visual representation and agent policies. In our experiments, we find that MOCO finetuned ResNet50 performs the best in comparison to other finetuned representations. Goal state conditioning and mapping to transitions resulted in a minute increase in the success rate and mean-reward. As for the agent policy, we developed DiffClone, a behaviour cloning agent improved using conditional diffusion.
Towards Adversarial Purification using Denoising AutoEncoders
Aug 29, 2022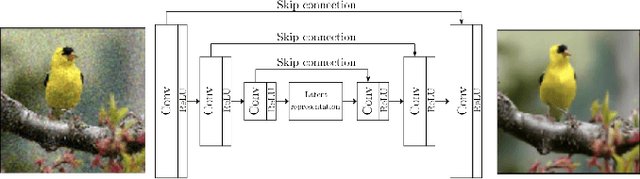
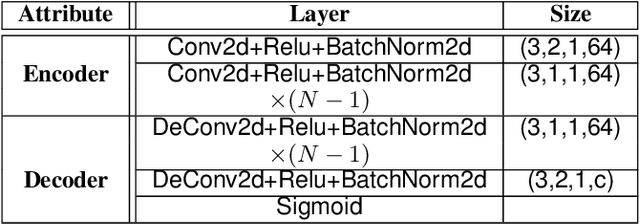
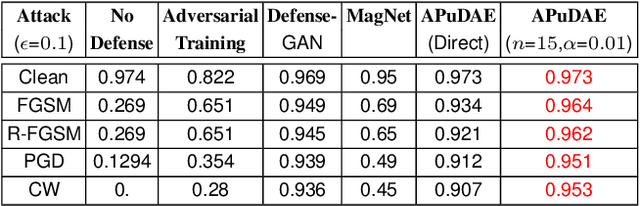

With the rapid advancement and increased use of deep learning models in image identification, security becomes a major concern to their deployment in safety-critical systems. Since the accuracy and robustness of deep learning models are primarily attributed from the purity of the training samples, therefore the deep learning architectures are often susceptible to adversarial attacks. Adversarial attacks are often obtained by making subtle perturbations to normal images, which are mostly imperceptible to humans, but can seriously confuse the state-of-the-art machine learning models. We propose a framework, named APuDAE, leveraging Denoising AutoEncoders (DAEs) to purify these samples by using them in an adaptive way and thus improve the classification accuracy of the target classifier networks that have been attacked. We also show how using DAEs adaptively instead of using them directly, improves classification accuracy further and is more robust to the possibility of designing adaptive attacks to fool them. We demonstrate our results over MNIST, CIFAR-10, ImageNet dataset and show how our framework (APuDAE) provides comparable and in most cases better performance to the baseline methods in purifying adversaries. We also design adaptive attack specifically designed to attack our purifying model and demonstrate how our defense is robust to that.
Detecting Adversaries, yet Faltering to Noise? Leveraging Conditional Variational AutoEncoders for Adversary Detection in the Presence of Noisy Images
Dec 09, 2021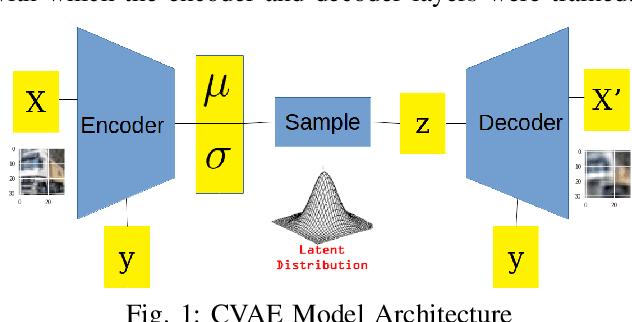
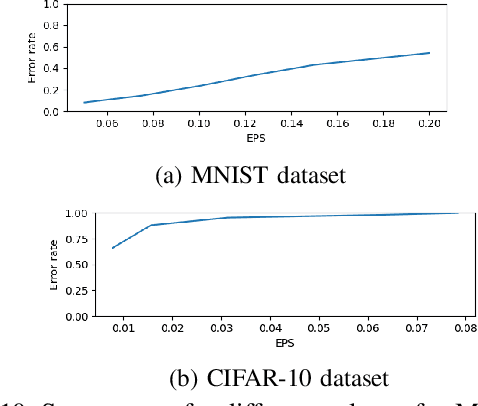
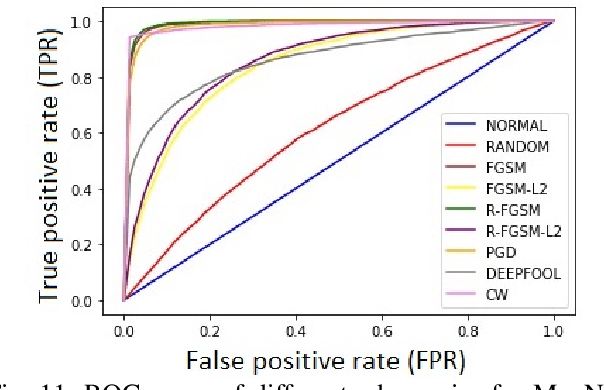
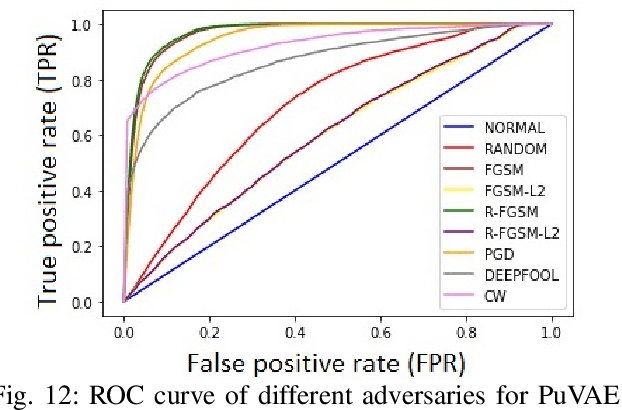
With the rapid advancement and increased use of deep learning models in image identification, security becomes a major concern to their deployment in safety-critical systems. Since the accuracy and robustness of deep learning models are primarily attributed from the purity of the training samples, therefore the deep learning architectures are often susceptible to adversarial attacks. Adversarial attacks are often obtained by making subtle perturbations to normal images, which are mostly imperceptible to humans, but can seriously confuse the state-of-the-art machine learning models. What is so special in the slightest intelligent perturbations or noise additions over normal images that it leads to catastrophic classifications by the deep neural networks? Using statistical hypothesis testing, we find that Conditional Variational AutoEncoders (CVAE) are surprisingly good at detecting imperceptible image perturbations. In this paper, we show how CVAEs can be effectively used to detect adversarial attacks on image classification networks. We demonstrate our results over MNIST, CIFAR-10 dataset and show how our method gives comparable performance to the state-of-the-art methods in detecting adversaries while not getting confused with noisy images, where most of the existing methods falter.